







 本文详细介绍了Lucene的使用,包括Lucene是什么、如何建立索引库,以及核心API的讲解。内容涵盖索引结构、数据库与索引同步、Document与实体转化、索引的增删改查和分词器的使用。同时,讨论了相关度排名和高亮显示,并提供了资源下载链接。
本文详细介绍了Lucene的使用,包括Lucene是什么、如何建立索引库,以及核心API的讲解。内容涵盖索引结构、数据库与索引同步、Document与实体转化、索引的增删改查和分词器的使用。同时,讨论了相关度排名和高亮显示,并提供了资源下载链接。
问题?Lucene如何建立索引库,lucene所需要的jar包是那些 , lucene如何使用索引库,lucene的核心原理
一、Lucene是什么?
全文检索只是一个概念,而具体实现有很多框架,lucene是其中的一种方式。本文将以lucene3.0进行开发
官兵与Luncne的jar包可以去官网下载:点击打开链接,不过好像Lucene已经更新到6.1了。
二、建立索引库
1.互联网搜索全文搜索引擎结构图:
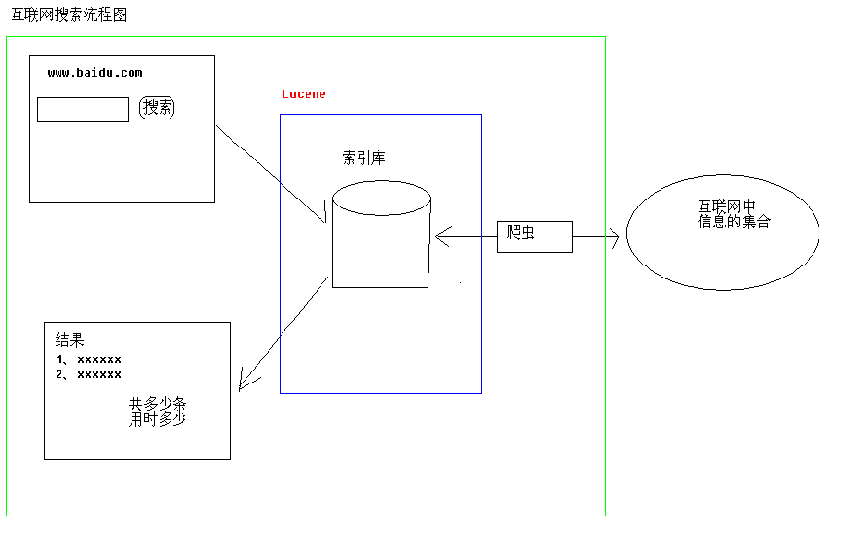
2.Lucene的结构图:
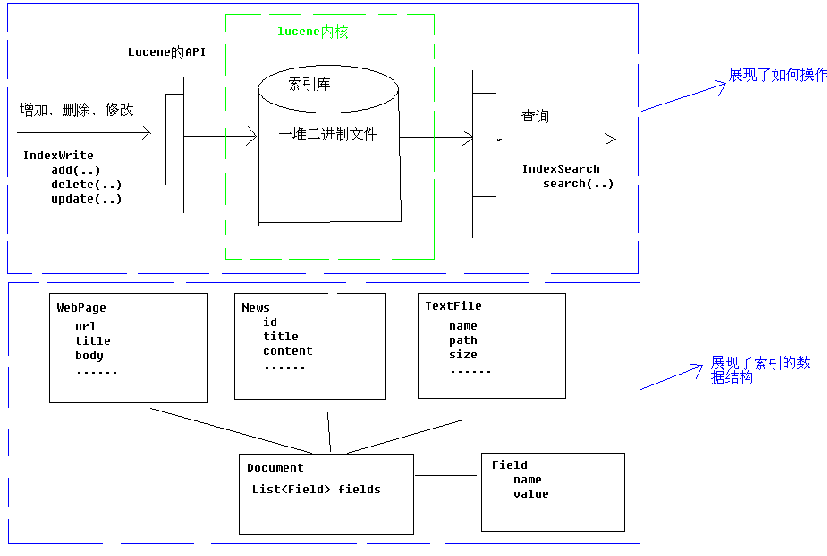
说明
:
(1)在数据库中,数据库中的数据文件存储在磁盘上。索引库也是同样,索引库中的索引数据也在磁盘上存在,我们用 Directory
这个类来描述.
(2)我们可以通过API的
IndexWrite
来实现对索引库的增、删、改、查的操作.
(3)在数据库中,各种数据形式都可以概括为一种:表。在索引库中,各种数据形式也可以抽象出一种数据格式为
Document
.
(4)Document的结构为:Document(List<Field>).
(5)Field里存放一个键值对。键值对都为字符串的形式.
(6)对索引库中索引的操作实际上也就是对Document的操作.
3.准备lucene的开发环境
在挂窝囊下载好压缩包后,至少要准备四个包:
lucene-core-3.1.0.jar(
核心包
)、
lucene-analyzers-3.1.0.jar(
分词器
)、
lucene-highlighter-3.1.0.jar(
高亮器
)、
lucene-memory-3.1.0.jar(
内存器)
4.索引结构

5.第一个索引例子:
实体类:Article
package com.itcast.ldp.domain;
import java.io.Serializable;
public class Article implements Serializable{
private Long aid;
private String title;
private String content;
public Long getAid() {
return aid;
}
public void setAid(Long aid) {
this.aid = aid;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
@Override
public String toString() {
return "Article [aid=" + aid + ", title=" + title + ", content="
+ content + "]";
}
}
(1)创建索引库
package com.itcast.ldp.lucene;
import java.io.File;
import java.util.ArrayList;
import java.util.List;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.Field.Index;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriter.MaxFieldLength;
import org.apache.lucene.queryParser.MultiFieldQueryParser;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
import org.junit.Test;
import com.itcast.ldp.domain.Article;
/**
*
* 把Article对象放入到索引库中去
* 在索引库中把Article对象拿出来
* @author Administrator
*
*/
public class CreateLucene1 {
/**
*
* 创建索引
* @throws Exception
*/
@Test
public void createIndex() throws Exception{
/**
* 创建Article对象
*/
Article article = new Article();
article.setAid(1L);
article.setTitle("lucene是一个全文检索引擎");
article.setContent("taobao");
/**
* //创建一个indexWriter对象 参数(1:索引库位置,2:分词器,3:代表文档中的属性最大长度)
*/
//1.索引库位置
Directory directory = FSDirectory.open(new File("./DirIndex"));
//2.分词器:讲一段内容分成关键词的作用
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_30);
//3.表示文档属性的最大长度 MaxFieldLength.LIMITED限制索引库汇总字段的大小,必须限制.源码中只能放10K
IndexWriter indexWriter = new IndexWriter(directory, analyzer, MaxFieldLength.LIMITED);
/**
* 把Article对象转化doucument对象
* Field.Index.*:详解如下
*Index.ANALYZED : 使用分析器将域值分解成独立的词汇单元流,并使用每个语汇单元能被搜索。该选项适用于普通文本域(正文、标题、摘要等);
*Index.NOT_ANALYZED : 对域进行索引,但不对String值进行分析。该操作实际上将域值作为单一语汇单元使之能够被搜索。该选项适用于索引那些不能被分解的域值(URL、文件路径、日期、人名、社保号码、手机号码等。)该选项尤其适用于"精确匹配"搜索;
*Index.ANALYZED_NO_NORMS : 这是Index.ANALYZED选项的一个变体,它不会在索引里面存储norms信息。norms记录了索引中的index-time boost信息,但是当你进行搜索时可能会比较耗费内存;
*Index.NOT_ANALYZED_NO_NORMS : 与Index.NOT_ANALYZED选项类似,但是也不存储norms。该选项用于搜索期间节省索引空间和减少内存消耗,因为single-token域并不需要norms信息,除非它们已被进行加权操作;
*Index.NO : 使对应的域值不被搜索;
*/
//创建文档
Document document = new Document();
//1.表示在索引库中的字段 2.存储在索引库中的值
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 740
740

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









