







这篇文章源于和实验室同学吃饭时的一次聊天,当时就觉得很有意思,就顺便写下来了——
自然语言处理的历史源远流长,不过这篇文章要讲的故事得从机器翻译说起
众所周知,谷歌的机器翻译一直是业内标杆,追求者众,但是谷歌显然欲求不满

于是在2016年上线了全新版本的神经网络翻译系统,而这个系统就是基于RNN全家桶的,毕竟RNN的优势就在于能处理变长序列并且自带序列位置信息
然而刚到2017年,Facebook的FAIR(Facebook AI Research)实验室发了篇论文,名叫《Convolutional Sequence to Sequence Learning》,这篇论文上来就说:
恕我直言,RNN无法并行处理,训练速度慢,绝非正道,而我这个基于CNN的端到端训练的新模型,完全舍弃了RNN,速度快,效果好:
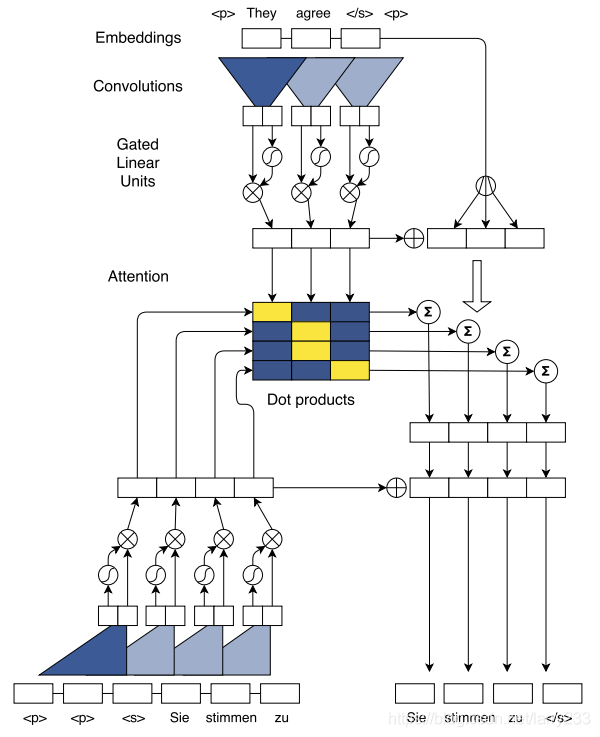
谷歌看完这篇论文寻思着不对劲啊,机器翻译啥时候轮到你这个小老弟来说话了?

于是立马就在2017年6月份在arxiv上发表了一篇非常标题党的论文,叫《Attention is All you Need》,这么狂拽炫酷的论文标题吸引了无数吃瓜群众,可谓是赚足了眼球,大家下下来一看,原来谷歌提出了一个叫Transformer的新模型,傲娇的谷歌在这篇论文里表示:
哼,就算RNN不好,我也不用你家的CNN,我有新模型啦!
这个模型长这样:
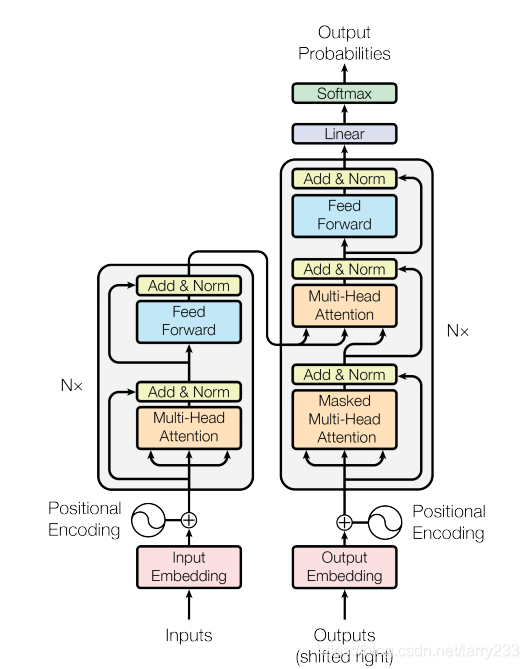
简单来说,就是用了自注意力(self-attention)+多头注意力(multi-head attention),同时由于失去了RNN的位置信息,特地加上了位置嵌入(positional encoding)
实际上谷歌和Facebook这两篇论文都用了注意力机制(attention mechanism),而他们也不是最早提出这个机制的,只不过谷歌用这个爆炸性的标题,彻底带火了注意力机制
话说回Transformer,像这样独立于RNN和CNN的主流模型之外的
妖艳贱货新品种,就注定会给NLP带来腥风血雨深刻的变革。而谷歌在多年之后也绝不会想到,这个曾经在和Facebook的较量之中提出的模型,会把战火蔓延到NLP的各个领域…
时间来到2018年,最初,OpenAI发表了一篇名为《Improving Language Understanding by Generative Pre-Training》的论文,这篇论文提出的模型叫GPT,用了Transformer提取特征,跑了12项NLP任务,在9个任务中都达到了最佳:

结果8月份AllenAI在NAACL发表了一篇论文,名为《Deep contextualized word representations》,这篇论文喜提NAACL最佳论文奖,提出的模型名为ELMo,ELMo表示:
GPT用的是单向语言模型,不如我这个双向LSTM语言模型,并且我在6个NLP任务中都达到了最佳效果
然而人家ELMo还没笑够,10月份的时候谷歌就又发了一篇论文,名为《Pre-training of Deep Bidirectional Transformers for Language Understanding》,这篇论文跳出来说:
ELMo其实是浅层的双向LSTM语言模型,提取特征的能力不行,不如我这个用Transformer来提取特征的模型BERT,顺带证明了双向模型比单向的更好。BERT的效果很好,好到刷新了11项NLP任务的记录,被称为史上最强の模型:


本来呢,AllenAI提出ELMo大家也没觉得有啥,结果谷歌非得碰瓷,把新模型叫BERT,为啥说碰瓷呢,因为ELMo和BERT是美国一部家喻户晓的动画《芝麻街》里的人物(我小时候好像还看过):

而BERT前脚刚落地,百度立马就带着自己的模型ERNIE跟上来了,这个模型以词为单位在海量数据上进行训练,解决了中文里很多单独的字没有语义的问题,因此在中文数据集上表现优越,有的甚至比BERT还好。
这个模型全称叫“Enhanced Representation through Knowledge Integration”,大伙还在困惑这特么是怎么缩写成ERNIE的呢,这时八卦星人一语道破:
ERNIE是上图那个头发炸毛的圆脸憨蛋,也是《芝麻街》里的人物。。。
wtf,又是一个碰瓷的。
芝麻街:

(论取名的重要性)
BERT一出,可怜的ELMo立马被埋没了,但是前面被他俩混合双打的OpenAI不服啊,到2019年2月份就提出了GPT2.0,这次的2.0版本模型更深,训练数据更多,参数高达15亿,尽管BERT说双向模型更好,但是死傲娇GPT2.0说不听不听我不听,仍然坚持用单向语言模型,而且在9项NLP任务上都刷新了前面的记录,GPT2.0表示:
前面说单向模型不好的出来挨打,我偏要用单向模型,我堆参数上去照样比你们好



(上图出自李宏毅对上述几个模型的讲解视频,OpenAI没有开源GPT2.0,暗示GPT2.0是NLPers得不到的女人:D)
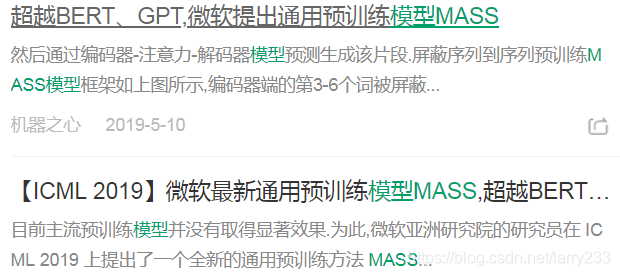
言归正传,眼见各路神仙打架,在一旁吃瓜的微软微微一笑,默默掏出了手中的模型MASS(Masked Sequence to Sequence Pre-training),不仅超过了BERT和GPT,而且还是在机器翻译领域效果显著:
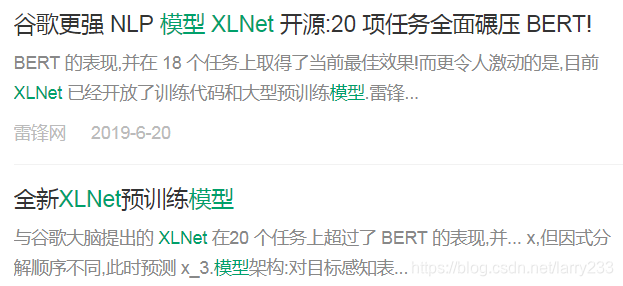
谷歌那个气啊,6月份立马放出新模型XLNet,这个新模型好到在20项NLP任务上都达到了最优,这次公众号小编们终于明白了一个道理:
没有最强,只有更强…
吃瓜群众们心想,他们这么刷记录,总有一天会刷到天花板的吧,Facebook听到后表示:
没错,天花板是有的,but, not today
然后转身告诉谷歌,我们帮你重新训练了下BERT,效果更好了…
于是吃瓜群众发现2019年7月26日这天,arxiv上多了一篇论文《RoBERTa: A Robustly Optimized BERT Pretraining Approach》,BERT再入神坛,FB事了拂衣去,深藏功与名

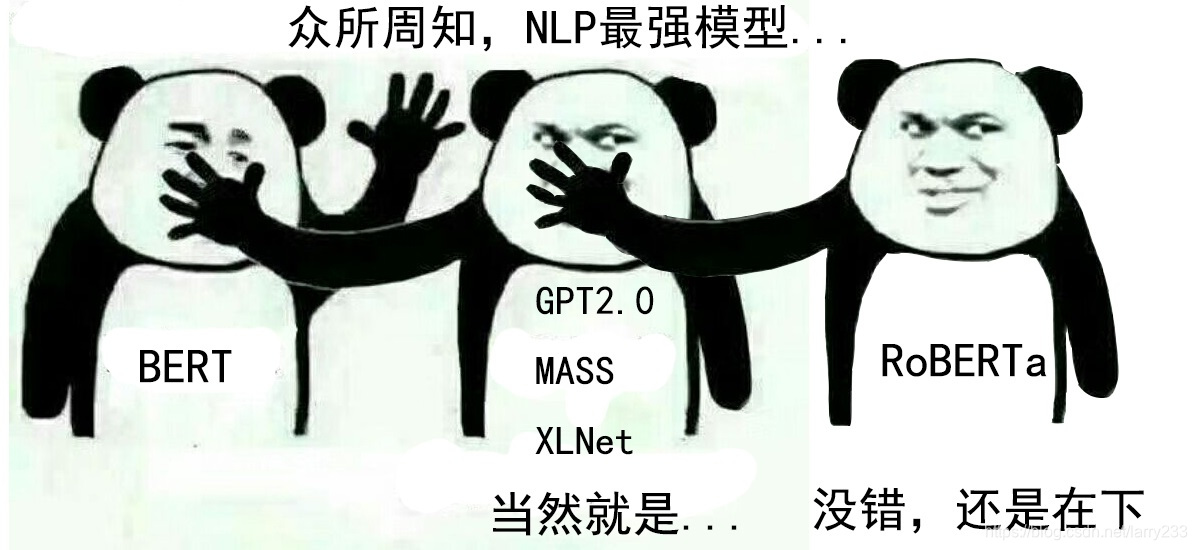
真的是相爱相杀。。。

总结
最后谈下个人看法吧,从18年以来,NLP真的是光速发展,整个领域可以说是日新月异,看了一些大佬的文章,觉得未来Transformer会比RNN和CNN有更广泛的应用前景,毕竟RNN不能并行训练是个硬伤。
另一方面,个人觉得现在的NLP领域是点歪技能树了。。。最新的NLP模型都在朝通用、大一统的模型发展,然后用通用的语言模型去做各种各样的NLP任务,这个趋势没问题,但是现在的新模型都在堆更深的网络、用更大的训练数据(高达数十亿),也导致了更多的参数量(也有十几二十亿)和更长的训练时间。氪金玩家(大误) 大公司们这么玩也没问题,毕竟无脑堆TPU集群增加算力就能缩短时间,但是平民玩家 我们普通人真的是肝不动啊。。。
但愿以后能有小而精的模型出现,并且能有自己特定的应用场景,现在光是活着就已经竭尽全力了啊。。。














 3261
3261











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









