







爬厦门大学官网(http://www.xmu.edu.cn)页面上厦大新闻栏目下的标题。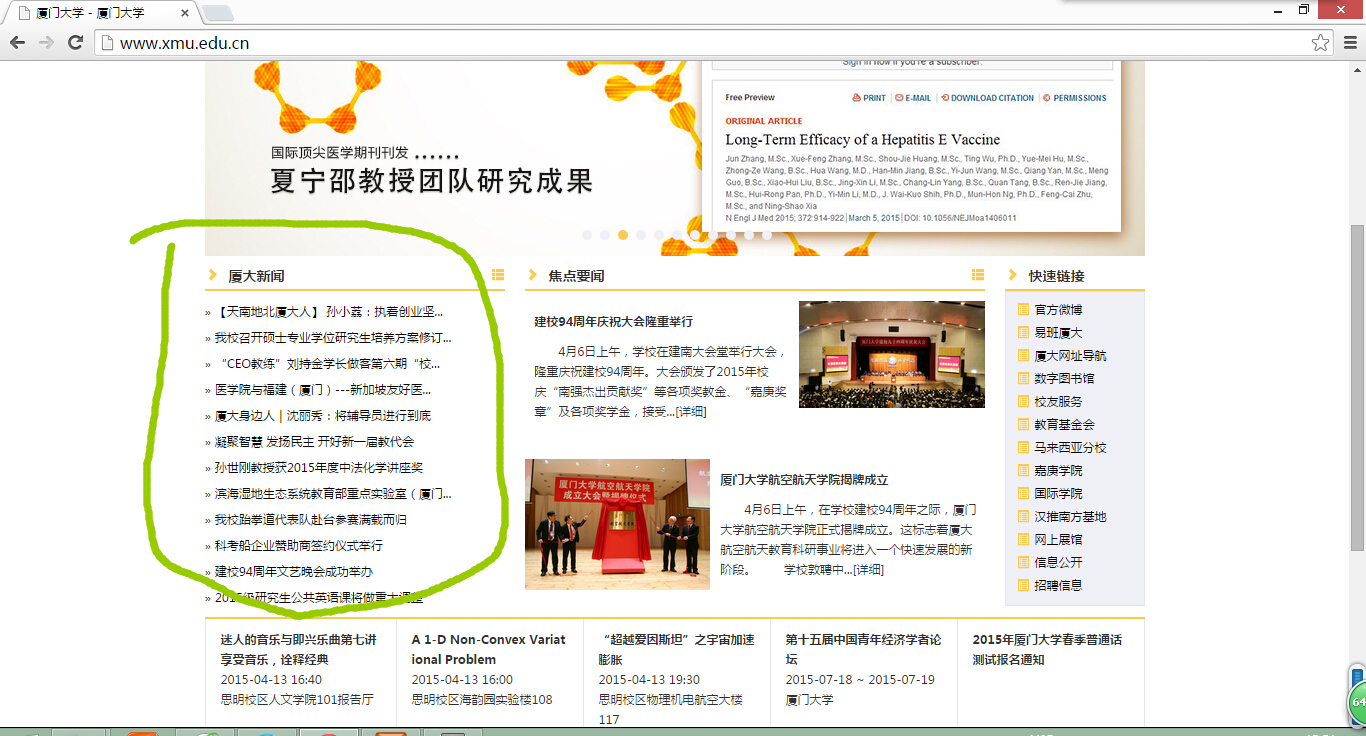
接下来单击鼠标右键->审查元素->Network->√preserve log->刷新页面,重载网页。
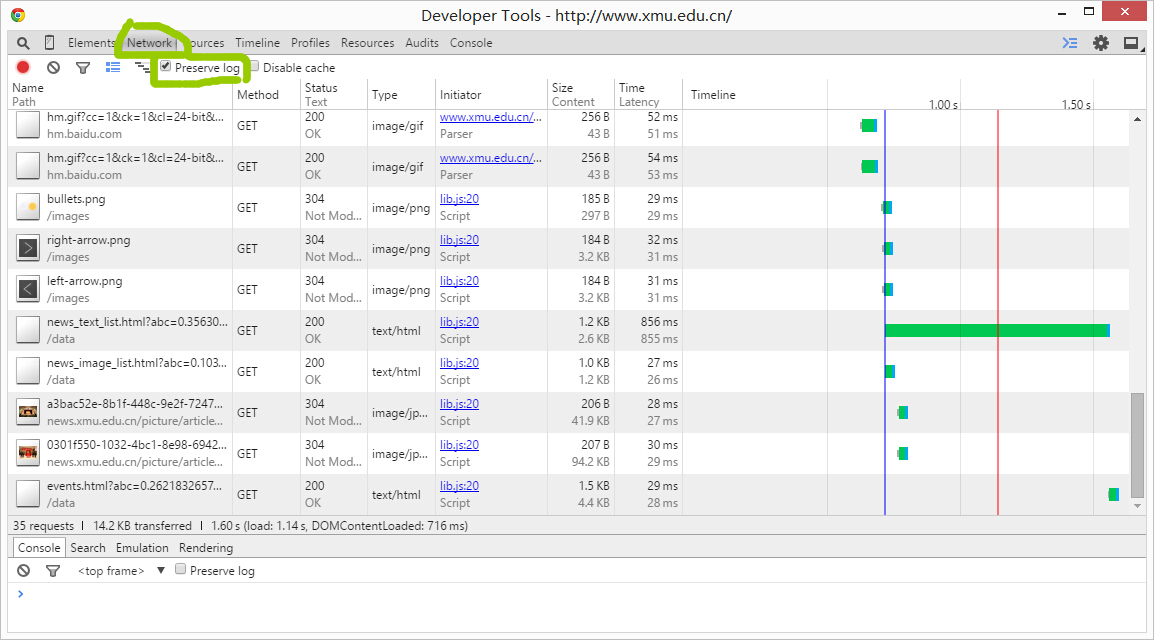
滚动条拉到最上面,www.xmu.edu.cn->preview,找到厦大新闻的标签下,发现并没有具体的新闻条目,故看其他Path。往下翻翻翻,哈哈~找到了一个名字是news_text_list.html的文件,听着名字就像是新闻列表,点击进入response,
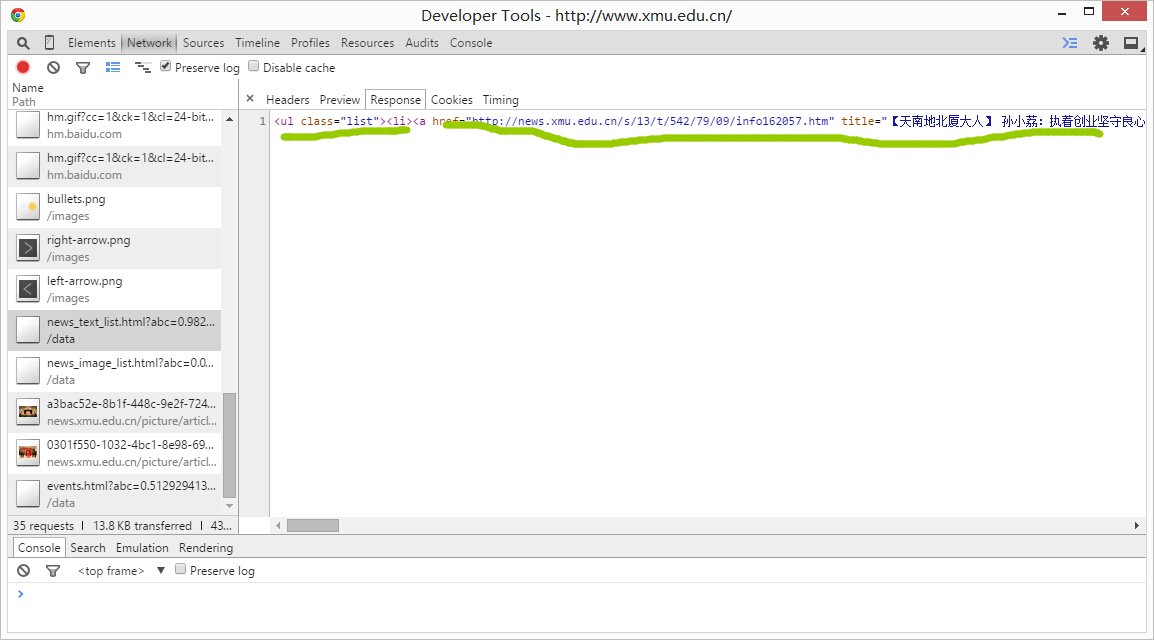
发现里面的数据确实是厦大新闻的内容,所以我们找对啦~
点击headers看下具体信息
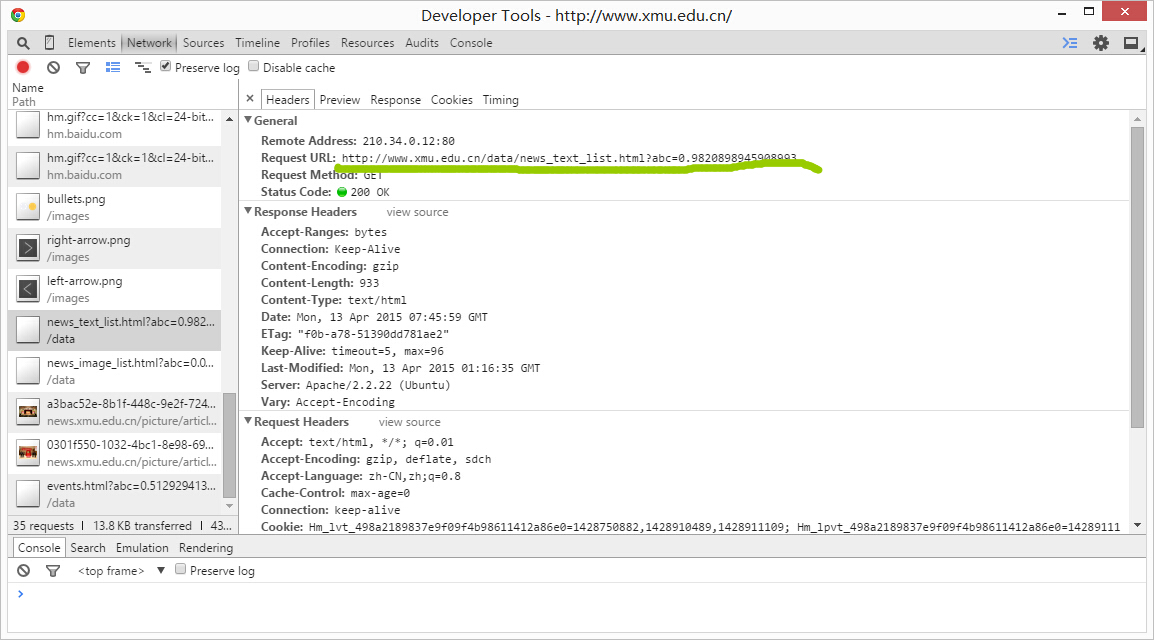
找到requestURL,复制下,一会儿用~
接下来就是代码代码啦~
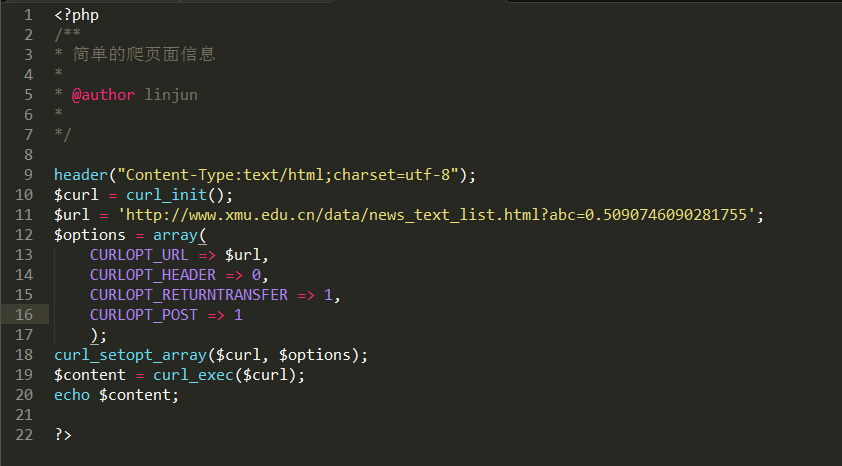
第一步看看自己curl得到的网页信息:
下面是运行php之后的页面
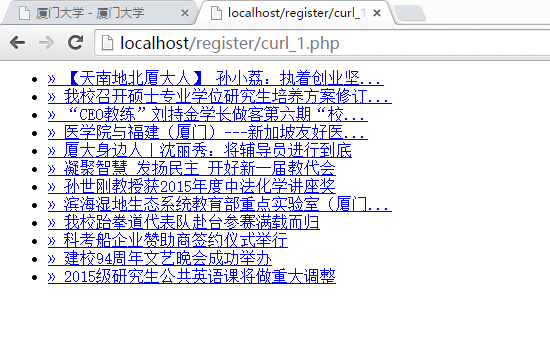
完美的得到了新闻的信息。
接下来就是要对立面的信息信息用explode()函数进行切割,取出需要的信息~
先分析一下信息:
每一个标题都是一个标签。
<a href="http://news.xmu.edu.cn/s/13/t/542/79/42/info162114.htm" title="中化集团原副总裁罗东江畅谈国企市场化改革" target="_blank">» 中化集团原副总裁罗东江畅谈国企市场化改革</a>而我们要取得信息是title=”这里的内容”,所以我们分两步进行切割。
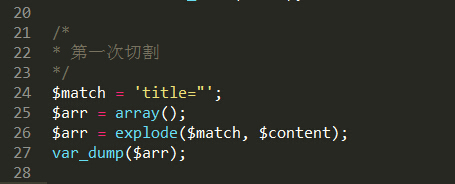
第一步:以title=“为切割点。
运行php得到
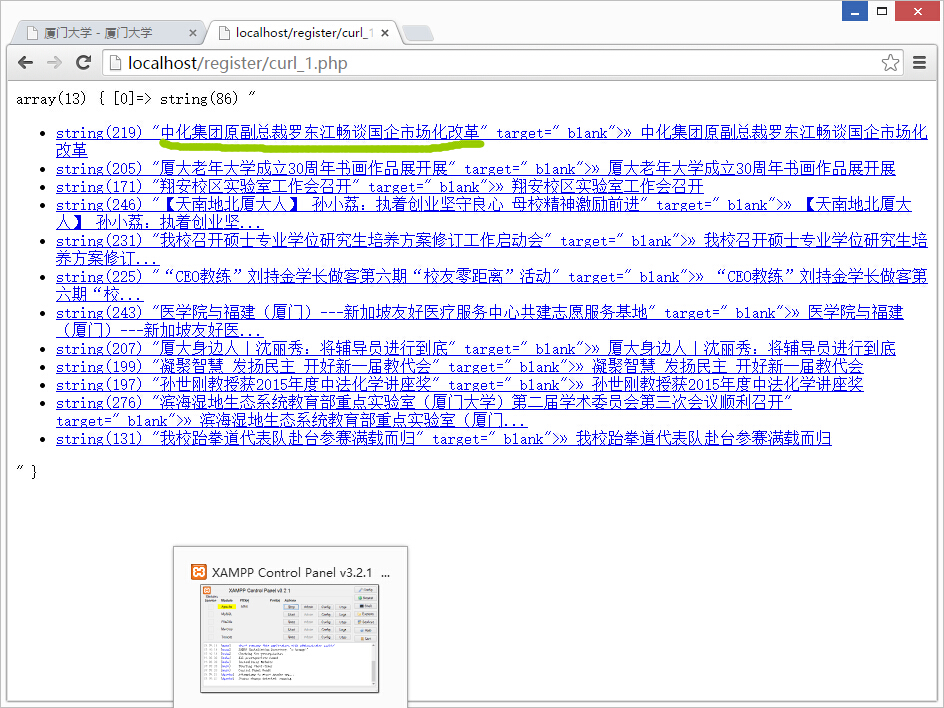
接下来进行第二次切割。
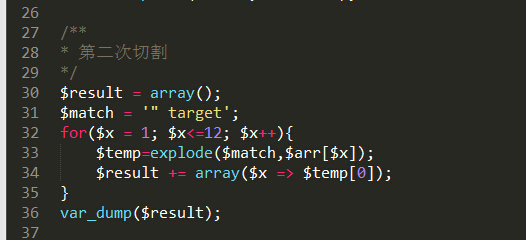
运行之后
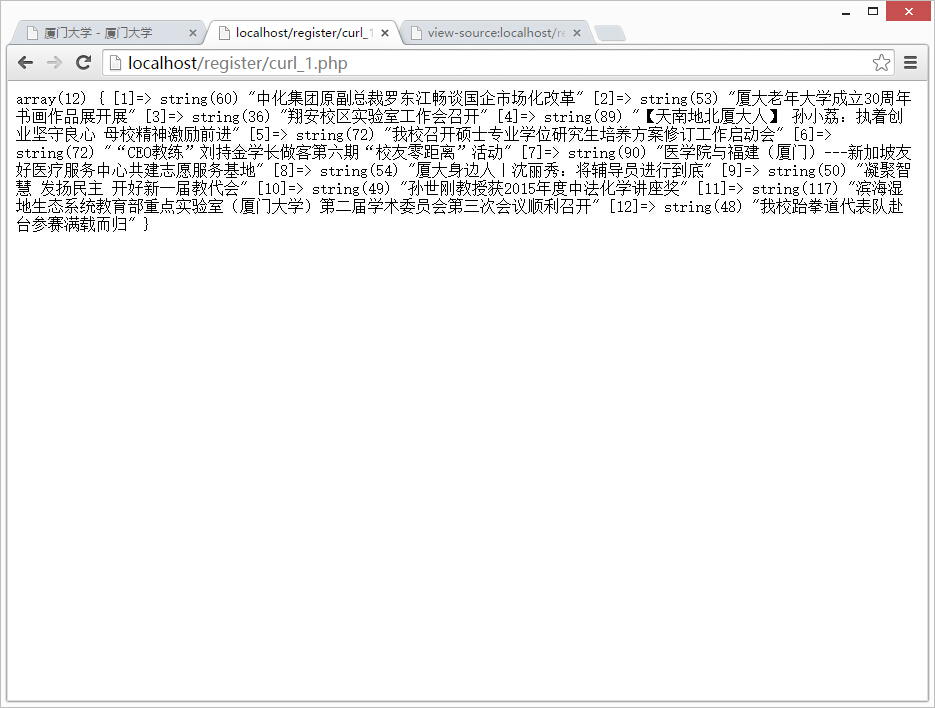
点击右键->查看网页源代码
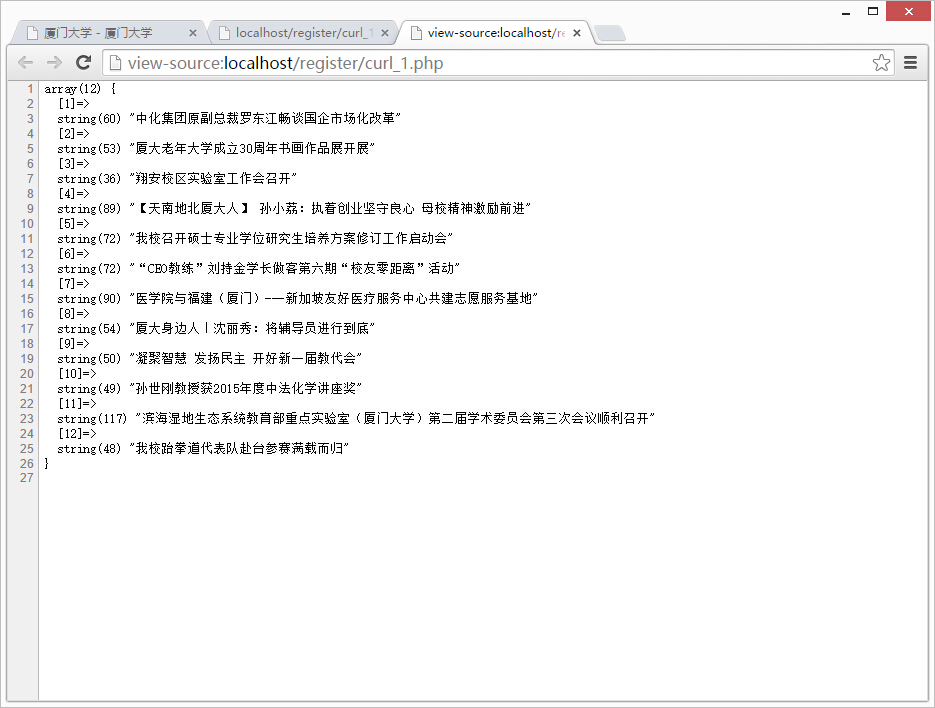
这样我们就把需要的信息提取出来啦~
大功告成~















 2117
2117











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









