







由于 Mixtral 的发布,混合专家(MoE) 架构在最近几个月变得流行起来。这种架构提供了一个有趣的权衡:更高的性能是以增加 VRAM 使用为代价的。虽然 Mixtral 和其他 MoE 架构都是从头开始预训练的,但最近出现了另一种创建 MoE 的方法。得益于 Arcee 的MergeKit库,我们现在有了一种通过组合多个预训练模型来创建 MoE 的新方法。这些通常被称为frankenMoE或MoErges,以将它们与预训练的 MoE 区分开来。
在本文中,我们将详细介绍 MoE 架构的工作原理以及如何创建 frankenMoE。最后,我们将使用 MergeKit 制作自己的 frankenMoE ,并在多个基准上对其进行评估。该代码可在 Google Colab 上的一个名为LazyMergeKit的包装器中找到。
🔀 MoE 简介
混合专家是一种旨在提高效率和性能的架构。它使用多个专门的子网络,称为“** 专家** ”。与整个网络都被激活的密集模型不同,混合专家仅根据输入激活相关专家。这可以加快训练速度并提高推理效率。MoE 模型的核心有两个组成部分:
- 稀疏 MoE 层:这些层取代了 Transformer 架构中的密集前馈网络层。每个 MoE 层包含多个专家,并且只有这些专家中的一小部分参与给定的输入。
- 门网络或路由器:此组件确定哪些令牌由哪些专家处理,确保输入的每个部分都由最合适的专家处理。
在以下示例中,我们展示了如何将 Mistral-7B 块转换为具有稀疏 MoE 层(前馈网络 1、2 和 3)和路由器的 MoE 块。此示例表示具有三个专家的 MoE,其中两个当前正在参与(FFN 1 和 FFN 3)。
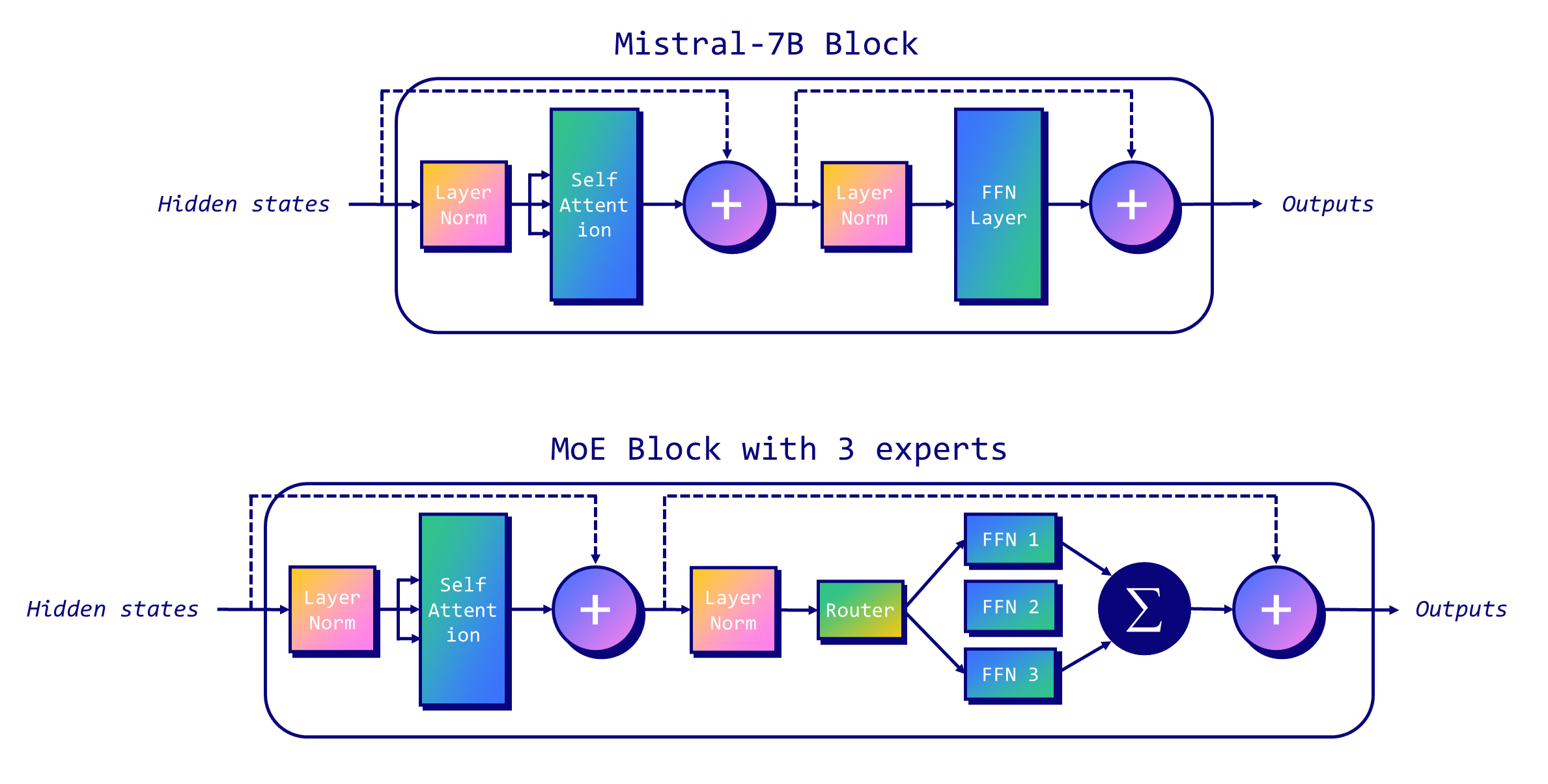
MoE 也面临一系列挑战,尤其是在微调和内存要求方面。由于模型的复杂性,微调过程可能很困难,需要在训练期间平衡专家的使用情况,以正确训练门控权重以选择最相关的权重。在内存方面,即使在推理过程中只使用总参数的一小部分,整个模型(包括所有专家)都需要加载到内存中,这需要很高的 VRAM 容量。
更具体地说,对于 MoE 来说,有两个基本参数:
- 专家数量(num_local_experts):这决定了架构中的专家总数(例如,Mixtral 为 8)。专家数量越多,VRAM 使用率越高。
- 每令牌的专家数量(num_experts_per_tok):这决定了每个令牌和每层参与的专家数量(例如,Mixtral 为 2)。每令牌的专家数量越多,准确性越高(但收益递减),而专家数量越少,训练和推理速度越快,两者之间存在权衡。
从历史上看,MoE 的表现不如密集模型。然而,2023 年 12 月发布的Mixtral-8x7B震惊了业界,并展示了与其规模相称的出色性能。此外,据传 GPT-4 也是 MoE,这很有道理,因为与密集模型相比,OpenAI 运行和训练它的成本要低得多。除了这些最近的出色 MoE 之外,我们现在还有一种使用 MergeKit 创建 MoE 的新方法:frankenMoE,也称为 MoErges。
🧟♂️ 真正的 MoE 与 FrankenMoE
真正的 MoE 和 frankenMoE 之间的主要区别在于训练方式。对于真正的 MoE,专家和路由器是联合训练的。对于 frankenMoE,我们升级现有模型,然后初始化路由器。换句话说,我们从基础模型中复制层规范和自注意力层的权重,然后复制每个专家中找到的 FFN 层的权重。这意味着除了 FFN 之外,所有其他参数都是共享的。这解释了为什么拥有八个专家的 Mixtral-8x7B 没有 8*7 = 56B 个参数,而是大约 45B。这也是为什么每个 token 使用两个专家会给出 12B 密集模型的推理速度(FLOPs)而不是 14B。
FrankenMoE 旨在选择最相关的专家并对其进行适当的初始化。MergeKit 目前实现了三种初始化路由器的方式:
- 随机:随机权重。使用时要小心,因为每次都可能选择相同的专家(这需要进一步微调或
num_local_experts = num_experts_per_tok,这意味着您不需要任何路由)。 - 廉价嵌入:它直接使用输入标记的原始嵌入,并在所有层上应用相同的转换。此方法计算成本低,适合在性能较差的硬件上执行。
- 隐藏:它通过从 LLM 的最后一层提取正向和负向提示列表来创建隐藏表示。对它们进行平均和标准化以初始化门。有关它的更多信息,请参阅Charles Goddard 的博客。
正如您所猜测的,“隐藏”初始化是将 token 正确路由到最相关专家的最有效方法。在下一节中,我们将使用此技术创建自己的 frankenMoE。
💻 创造一个 frankenMoE
要创建我们的 frankenMoE,我们需要选择` n` 专家。在这种情况下,我们将依靠 Mistral-7B,因为它很受欢迎并且规模相对较小。但是,像 Mixtral 中那样,八个专家是相当多的,因为我们需要将它们全部装入内存中。为了提高效率,我在这个例子中只使用四个专家,每个 token 和每个层使用两个专家。在这种情况下,我们最终会得到一个具有 24.2B 参数的模型,而不是 4*7 = 28B 参数。在这里,我们的目标是创建一个全面的模型,它可以做几乎所有的事情:写故事、解释文章、用 Python 编写代码等。我们可以将这个需求分解为四个任务,并为每个任务选择最佳专家。这是我的分解方式:
- 聊天模型:通用模型,在大部分交互中都会用到。我使用了mlabonne/AlphaMonarch-7B,完全满足需求。
- 代码模型:能够生成良好代码的模型。我对基于 Mistral-7B 的代码模型没有太多经验,但我发现beowolx/CodeNinja-1.0-OpenChat-7B与其他模型相比特别好。
- 数学模型:数学对于 LLM 来说比较难,因此我们需要一个专门研究数学的模型。由于其较高的 MMLU 和 GMS8K 分数,我为此选择了mlabonne/NeuralDaredevil-7B 。
- 角色扮演模型:该模型的目标是编写高质量的故事和对话。我选择了SanjiWatsuki/Kunoichi-DPO-v2-7B,因为它的声誉很好,MT-Bench 得分也很高(8.51,而 Mixtral 为 8.30)。
现在我们已经确定了要使用的专家,我们可以创建 MergeKit 将用来创建 frankenMoE 的 YAML 配置。这使用了 MergeKit 的 mixtral 分支。您可以在此页面上找到有关如何编写配置的更多信息。这是我们的版本:
base_model: mlabonne/AlphaMonarch-7B
experts:
- source_model: mlabonne/AlphaMonarch-7B
positive_prompts:
- "chat"
- "assistant"
- "tell me"
- "explain"
- "I want"
- source_model: beowolx/CodeNinja-1.0-OpenChat-7B
positive_prompts:
- "code"
- "python"
- "javascript"
- "programming"
- "algorithm"
- source_model: SanjiWatsuki/Kunoichi-DPO-v2-7B
positive_prompts:
- "storywriting"
- "write"
- "scene"
- "story"
- "character"
- source_model: mlabonne/NeuralDaredevil-7B
positive_prompts:
- "reason"
- "math"
- "mathematics"
- "solve"
- "count"
对于每位专家,我提供了五个基本的积极提示。如果你愿意,你可以更花哨一点,写出完整的句子。最好的策略是使用应该触发特定专家的真实提示。你也可以添加负面提示来做相反的事情。
准备就绪后,您可以将配置另存为config.yaml。在同一个文件夹中,我们将下载并安装mergekit库(mixtral分支)。
git clone -b mixtral https://github.com/arcee-ai/mergekit.git
cd mergekit && pip install -e .
pip install -U transformers
如果您的计算机有足够的 RAM(大约 24-32 GB 的 RAM),您可以运行以下命令:
mergekit-moe config.yaml merge --copy-tokenizer
如果您没有足够的 RAM,您可以按如下方式对模型进行分片(这将花费更长时间):
mergekit-moe config.yaml merge --copy-tokenizer --allow-crimes --out-shard-size 1B --lazy-unpickle
此命令会自动下载专家并在目录中创建 frankenMoE。
或者,您可以将配置复制到LazyMergekit中,这是我为简化模型合并而制作的包装器。在此 Colab 笔记本中,您可以输入模型名称、选择分支mixtral、指定 Hugging Face 用户名/令牌并运行单元。创建 frankenMoE 后,它还会将其与格式良好的模型卡一起上传到 Hugging Face Hub。
我将我的模型命名为Beyonder-4x7B-v3,并使用AutoGGUF创建了它的GGUF 版本。如果您无法在本地机器上运行 GGUF 版本,您也可以使用此Colab 笔记本进行推理。
为了全面了解其功能,我们根据三个不同的基准对其进行了评估:Nous 的基准套件、EQ-Bench 和 Open LLM Leaderboard。该模型并非旨在在传统基准测试中脱颖而出,因为代码和角色扮演模型通常不适用于这些环境。尽管如此,由于强大的通用专家,它的表现仍然非常出色。
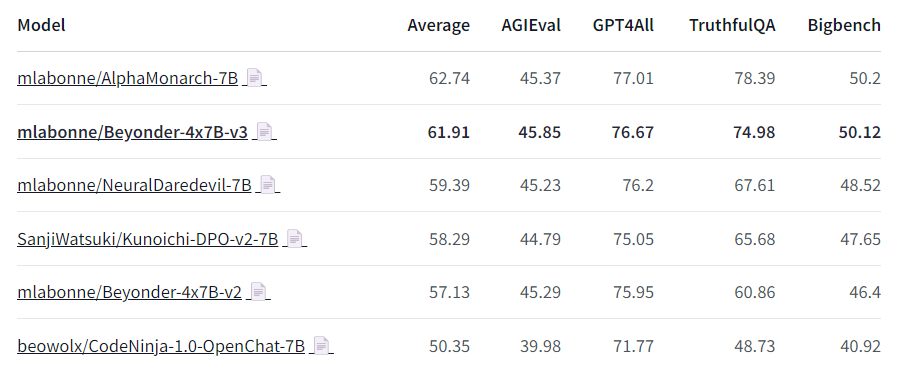
Nous:Beyonder-4x7B-v3 是 Nous 基准测试套件中最好的模型之一(使用LLM AutoEval进行评估),并且性能明显优于 v2。在此处查看整个排行榜。
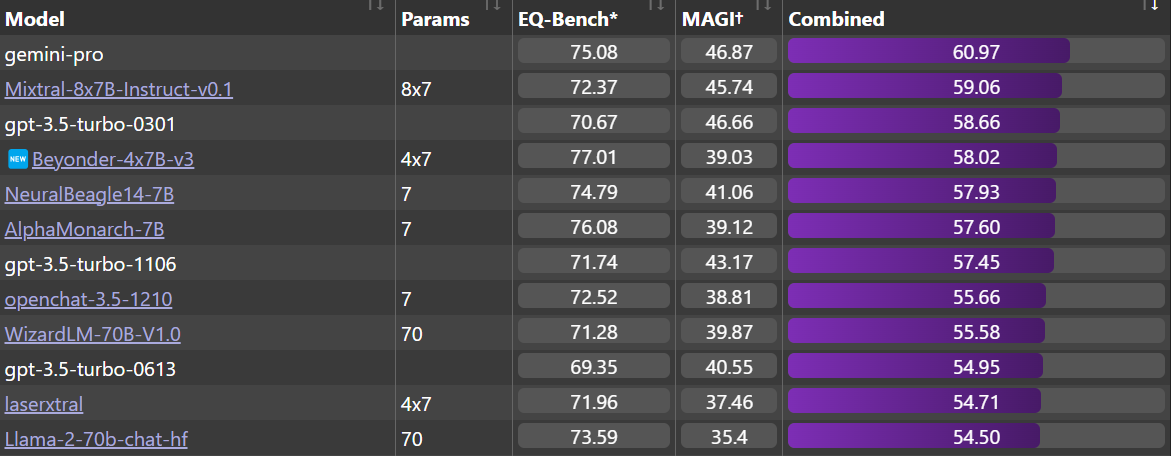
EQ-Bench:它也是EQ-Bench 排行榜上最好的 4x7B 模型,表现优于旧版本的 ChatGPT 和 Llama-2-70b-chat。Beyonder 与 Mixtral-8x7B-Instruct-v0.1 和 Gemini Pro 非常接近,而后两者(据称)是更大的模型。
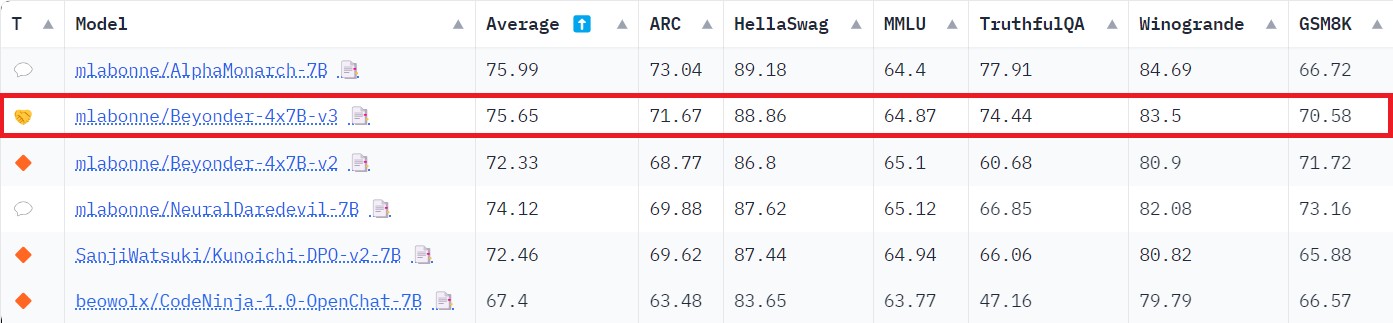
开放 LLM 排行榜:最后,它在开放 LLM 排行榜上也表现强劲,明显优于 v2 模型。
除了这些定量评估之外,我建议使用LM Studio上的 GGUF 版本以更定性的方式检查模型的输出。测试这些模型的一种常见方法是收集一组私人问题并检查其输出。通过这种策略,我发现与其他模型(包括 AlphaMonarch-7B)相比,Beyonder-4x7B-v3 对用户和系统提示的变化具有相当强的鲁棒性。这非常酷,因为它总体上提高了模型的实用性。
FrankenMoE 是一种很有前途但仍处于试验阶段的方法。其缺点包括更高的 VRAM 需求和更慢的推理速度,因此很难看出它们相对于 SLERP 或 DARE TIES 等更简单的合并技术的优势。尤其是当您仅与两位专家一起使用 frankenMoE 时,它们的性能可能不如您简单地合并这两个模型时那么好。然而,frankenMoE 在保存知识方面表现出色,这可以产生更强大的模型,正如 Beyonder-4x7B-v3 所展示的那样。有了合适的硬件,这些缺点可以得到有效缓解。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









