







正文
K-邻近算法(K-NearestNeighbor)简称KNN,我觉得这个真的是分类器中最好理解、最好实现的分类器,它最实用于数值型特征数据,下面让我们看看它的基本思想。
样本数据是由N维特征向量所组成,所有样本数据就是在这个N维空间中的离散点,当然每个离散点都对应这自己的类别。已知特征向量要预测它的类别,我们把这个已知向量放入样本空间中,去K个离它最近的点,这些点中,出现类别次数最多就是此向量对应的类别。
再精简一点说就是:筛选最近的K个点,在K中找类别频次。
为什么要这样做呢?
首先,“最近”就说明了我所找的这些点是与我所有求解的特征最相似,其次“少数服从多数”,谁出现的概率大,就选择谁。是不是很好理解?
接下来就是求两点之间的距离,这里采用欧氏空间距离公式(这应该是高中的内容了):
一直向量a(x1,y1,z1和b(x2,y2,z2),求a与b之间的距离d
根据维度自行调整里面的内容
根据KNN算法的基本原理,整理一下步骤:
- 求出指定向量到样本中每个向量的距离
- 找出离指定向量最近的K个向量
- 在K个向量中找出出现次数最多的类别,作为输出结果
是不是很简单?如果你说很简单那就错了,这里有一个坑,让我们举个例子,例子能说明一切
Example:市场需求总量、市场供应总量、市场集中三个因素(x,y,z)影响着企业决策类型,
假设向量a=(100000,250000,0.11),b=(120000,280000,0.55),求ab的距离d
根据业务来看,三个影响因素的应该是等权重的也就是同样重要。但是在上面的计算当中,市场集中度即使差距很大,也很难对最终结果造成影响,这很明显不符合业务的标准。
在处理不同范围特征值时,为了将数据等权重,消除因为取值范围的差异而导致结果倾斜,我们将数据归一化,把数据的取值范围控制在0到1之间
newValue=(oldValue-minValue)/(maxValue-minValue)
maxValue和minValue分别表示最大特征值,最小特征值,是这一特征当中的最值,并不是整个集合中的最值。
虽然归一化处理增加了分类器的复杂度,但是为了得到准确的结果,只能这样做。这样就把样本特征等权重了。
KNN分类器我们得到了,接下来让我们看一下KNN算法的扩展
上述的方式,最终得到的类别是一个标称型数据,如果针对结果是数值型的数据,我们该如何处理呢?
我们知道,KNN算法,提取了离指定点最近的K个点,这K个点就是与指定向量最相似的点,特征最相似,结果也是最相似的,所以针对数值型结果的数据,我们可以对这K个最相似的结果进行处理,得到最终结果,最常见的就是对K个数值型结果进行求均值来确定指定向量的结果,当然也可以根据自己的业务做加权平均。这是一个很好的扩展,使KNN算法可以不进适用于标称型结果的分类,还可以适应数值型结果的预测。

代码实现
先给出通用的代码:
结果信息类,实现了Compareable接口,根据距离进行排序,为的是找到K个最近的点
package moon.ml.knearestneighbor; /** * @ClassName ResultMapper * @Description 结果信息 * @author "liumingxin" * @Date 2017年5月22日 下午4:30:04 * @version 1.0.0 */ public class ResultInfo implements Comparable<ResultInfo>{ private Object classify; private Integer frequency = 0;//频次 private Double totalDistance = 0d; public Object getClassify() { return classify; } public void setClassify(Object classify) { this.classify = classify; } public Integer getFrequency() { return frequency; } public void setFrequency(Integer frequency) { this.frequency = frequency; } public Double getTotalDistance() { return totalDistance; } public void setTotalDistance(Double totalDistance) { this.totalDistance = totalDistance; } public int compareTo(ResultInfo that) { if(this.getFrequency() == this.getFrequency()){ return this.getTotalDistance().compareTo(that.getTotalDistance()); } return this.getFrequency().compareTo(that.getFrequency()); } }归一化的方法类
package moon.ml.util;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import moon.ml.record.RecordWithFeaturesDouble;
/**
* @ClassName Uniformization
* @Description 归一化计算类
* @author "liumingxin"
* @Date 2017年5月22日 下午1:47:30
* @version 1.0.0
*/
public class Uniformization {
/**
* @Title: getUniformizationResult
* @Description: 归一化结果
* @param list
* @return
* @return List<List<Double>>
*/
public static List<List<Double>> getUniformizationResult(List<List<Double>> list){
if(list == null){
return null;
}
List<List<Double>> results = new ArrayList<List<Double>>();
for(int i=0;i<list.size();i++){
results.add(new ArrayList<Double>());
}
int colSize = list.get(0).size();
int rowSize = list.size();
for(int i=0;i<colSize;i++){
Double maxElement = list.get(0).get(i);
Double minElement = list.get(0).get(i);
//获取每一列的最大值最小值
for(List<Double> strs : list){
Double element = strs.get(i);
if(element > maxElement){
maxElement = element;
}
if(element < minElement){
minElement = element;
}
}
//归一化
for(int j=0;j<rowSize;j++){
List<Double> result = results.get(j);
if(result == null){
result = new ArrayList<Double>();
results.add(result);
}
Double element = list.get(j).get(i);
element = (element - minElement)/(maxElement - minElement);
result.add(element);
}
}
return results;
}
}
KNN算法的主要算法,但是这里抽象了分类策略,这样可以针对不同结果类型,进行具体实现
标称型结果的策略实现和测试package moon.ml.knearestneighbor; import java.util.ArrayList; import java.util.Collections; import java.util.List; import moon.ml.record.DistanceMapperDouble; import moon.ml.record.RecordWithFeaturesDouble; import moon.ml.util.Uniformization; /** * @ClassName KNearestNeighbor * @Description 分类预测 * 优点:精度高、对异常数据不敏感、无数据输入假定 * 缺点:计算复杂度高、空间复杂度高 * @author "liumingxin" * @Date 2017年5月23日 上午9:55:10 * @version 1.0.0 */ public abstract class KNearestNeighbor { /** * @Title: normalization * @Description: 数据集的归一化处理 * @param dataSet * @return * @return List<RecordWithFeaturesDouble> */ public List<RecordWithFeaturesDouble> normalization(List<RecordWithFeaturesDouble> dataSet){ List<RecordWithFeaturesDouble> result = new ArrayList<RecordWithFeaturesDouble>(); List<List<Double>> doubleList = new ArrayList<List<Double>>(); for(RecordWithFeaturesDouble r : dataSet){ doubleList.add(r.getFeatures()); } List<List<Double>> normalResults = Uniformization.getUniformizationResult(doubleList); for(int i=0;i<normalResults.size();i++){ RecordWithFeaturesDouble r = new RecordWithFeaturesDouble(); r.setCategory(dataSet.get(i).getCategory()); r.setFeatures(normalResults.get(i)); result.add(r); } return result; } /** * @Title: getResult * @Description: 得出结果 * @param dataSet 数据集 * @param test 测试数据 * @param K K值 * @return * @return Object */ public Object getResult(List<RecordWithFeaturesDouble> dataSet, List<Double> test, Integer K){ //将测试数据,加入到dataset中,然后归一化处理,再分离测试数据 RecordWithFeaturesDouble testRecord = new RecordWithFeaturesDouble(); testRecord.setFeatures(test); dataSet.add(testRecord); dataSet = normalization(dataSet); testRecord = dataSet.get(dataSet.size()-1); dataSet = dataSet.subList(0, dataSet.size()-1); List<DistanceMapperDouble> mappers = new ArrayList<DistanceMapperDouble>(); for(RecordWithFeaturesDouble data : dataSet){ //计算两个向量的距离 Double distance = data.featuresList2RealVector().getDistance(testRecord.featuresList2RealVector()); DistanceMapperDouble mapper = new DistanceMapperDouble(); mapper.setData(data); mapper.setDistance(distance); mappers.add(mapper); } //根据聚类升序排序 Collections.sort(mappers); //截取前K个,这就是所有的K邻近中的K的作用 mappers = mappers.subList(0, K); return getCategory(mappers); } /** * @Title: getCategory * @Description: 自定义策略 * @param mappers * @return * @return Object */ public abstract Object getCategory(List<DistanceMapperDouble> mappers); }package moon.ml.knearestneighbor;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import moon.ml.record.DistanceMapperDouble;
import moon.ml.record.RecordWithFeaturesDouble;
/**
* @ClassName CategoryForecastKNN
* @Description 类别预测KNN方法类
* @author "liumingxin"
* @Date 2017年6月20日 下午3:56:18
* @version 1.0.0
*/
public class CategoryForecastKNN extends KNearestNeighbor{
@Override
public Object getCategory(List<DistanceMapperDouble> mappers) {
Map<Object,ResultInfo> resultInfoMap = new HashMap<Object,ResultInfo>();
for(DistanceMapperDouble mapper : mappers){
RecordWithFeaturesDouble data = mapper.getData();
Object classify = data.getCategory();
//种类为KEY
ResultInfo resultInfo = resultInfoMap.get(classify);
if(resultInfo == null){
resultInfo = new ResultInfo();
}
resultInfo.setClassify(classify);
//频次+1
resultInfo.setFrequency(resultInfo.getFrequency()+1);
//总距离相加
resultInfo.setTotalDistance(resultInfo.getTotalDistance()+mapper.getDistance());
resultInfoMap.put(classify, resultInfo);
}
List<ResultInfo> resultInfos = new ArrayList<ResultInfo>();
for(Object key :resultInfoMap.keySet()){
resultInfos.add(resultInfoMap.get(key));
}
Collections.sort(resultInfos);
return resultInfos.get(0).getClassify();
}
public static void main(String[] args) {
List<List<String>> trains = new ArrayList<List<String>>();
trains.add(Arrays.asList("2", "357", "9888", "0.54", "no"));
trains.add(Arrays.asList("3", "452", "8888", "0.35", "no"));
trains.add(Arrays.asList("1", "335", "7894", "0.13", "yes"));
trains.add(Arrays.asList("7", "645", "5648", "0.97", "yes"));
trains.add(Arrays.asList("6", "255", "6794", "0.65", "yes"));
trains.add(Arrays.asList("8", "388", "8015", "0.34", "no"));
trains.add(Arrays.asList("4", "458", "6798", "0.66", "yes"));
trains.add(Arrays.asList("6", "687", "8764", "0.79", "no"));
trains.add(Arrays.asList("8", "388", "8754", "0.68", "yes"));
trains.add(Arrays.asList("1", "546", "9768", "0.67", "yes"));
trains.add(Arrays.asList("8", "488", "9537", "0.35", "yes"));
trains.add(Arrays.asList("3", "612", "5491", "0.97", "yes"));
trains.add(Arrays.asList("8", "548", "6724", "0.64", "yes"));
trains.add(Arrays.asList("4", "356", "9768", "0.88", "no"));
List<RecordWithFeaturesDouble> trainList = new ArrayList<RecordWithFeaturesDouble>();
for(List<String> l : trains){
List<Double> ds = new ArrayList<Double>();
for(int i=0;i<l.size()-1;i++){
ds.add(Double.parseDouble(l.get(i)));
}
RecordWithFeaturesDouble r = new RecordWithFeaturesDouble();
r.setCategory(l.get(l.size()-1));
r.setFeatures(ds);
trainList.add(r);
}
List<Double> testList = new ArrayList<Double>();
testList.add(4d);
testList.add(488d);
testList.add(7564d);
testList.add(0.66d);
CategoryForecastKNN knn = new CategoryForecastKNN();
String result = knn.getResult(trainList, testList, 3).toString();
System.out.println(result);
}
}
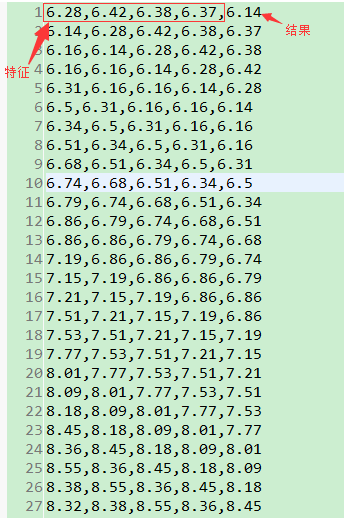
数值型结果的策略实现和测试先看一下数据长什么样
业务背景是这样的:我们认为前几天的股票走势,是影响接下来股票价格的因素,所以把前四天股票的收盘价格定为四个特征,当天收盘价作为结果,这样,我们就可以根据最近四天的收盘价,预测接下来一天的收盘价
下面是具体实现
代码我已经放在了github上了 https://github.com/moonLazy/MoonML.gitpackage moon.ml.knearestneighbor; import java.io.BufferedReader; import java.io.File; import java.io.FileReader; import java.util.ArrayList; import java.util.List; import moon.ml.record.DistanceMapperDouble; import moon.ml.record.RecordWithFeaturesDouble; /** * @ClassName FigureForecastKNN * @Description 数字预测KNN方法类 * @author "liumingxin" * @Date 2017年6月20日 下午3:56:39 * @version 1.0.0 */ public class FigureForecastKNN extends KNearestNeighbor{ /* (非 Javadoc) * <p>Title: getCategory</p> * <p>Description: 求K个结果的平均值,作为预测结果</p> * @param mappers * @return * @see moon.ml.knearestneighbor.KNearestNeighbor#getCategory(java.util.List) */ @Override public Object getCategory(List<DistanceMapperDouble> mappers) { Double result = 0d; for (DistanceMapperDouble mapper : mappers) { result += Double.parseDouble(mapper.getData().getCategory().toString()); } result = result / mappers.size(); return result; } /** * 读取测试文档 */ private static List<RecordWithFeaturesDouble> readTest(String fileIn) { List<RecordWithFeaturesDouble> outList = new ArrayList<RecordWithFeaturesDouble>(); try { File file = new File(fileIn); FileReader reader = new FileReader(file); BufferedReader in = new BufferedReader(reader); String line = null; while ((line = in.readLine()) != null) { RecordWithFeaturesDouble record = new RecordWithFeaturesDouble(); List<Double> list = new ArrayList<Double>(); String[] mArray = line.split(","); for (Integer i = 0; i < mArray.length - 1; i++) { list.add(Double.parseDouble(mArray[i])); } record.setFeatures(list); record.setCategory(mArray[mArray.length - 1]); outList.add(record); } in.close(); reader.close(); } catch (Exception e) { System.out.println("读取出错"); e.printStackTrace(); } return outList; } public static void main(String[] args) { //K值 Integer K = 10; List<RecordWithFeaturesDouble> trainList = readTest("data/knn/knn.txt"); List<Double> testList = new ArrayList<Double>(); testList.add(6.14); testList.add(6.28); testList.add(6.42); testList.add(6.38); FigureForecastKNN knn = new FigureForecastKNN(); Object theoretical = knn.getResult(trainList, testList, K); System.out.println(theoretical); } }















 6983
6983











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









