






 研究揭示处方类鸦片使用可能与抑郁症和焦虑症存在因果关系,利用孟德尔随机化和大规模数据进行分析。另一方面,大脑衰老的评估方法——大脑预测年龄(brain age)在没有长期影像数据的情况下不应被视为加速老化。此外,通过RSA技术发现大脑不同区域对名人和地点语义信息的表征。最后,探讨了生命期中亚皮质结构体积随年龄变化的非线性模式,并强调了统计方法在神经影像学研究中的重要性。
研究揭示处方类鸦片使用可能与抑郁症和焦虑症存在因果关系,利用孟德尔随机化和大规模数据进行分析。另一方面,大脑衰老的评估方法——大脑预测年龄(brain age)在没有长期影像数据的情况下不应被视为加速老化。此外,通过RSA技术发现大脑不同区域对名人和地点语义信息的表征。最后,探讨了生命期中亚皮质结构体积随年龄变化的非线性模式,并强调了统计方法在神经影像学研究中的重要性。

Jama Psychiatry; 2020(Nov); MDD; Prescription Opioid Use; 2-sample MR; PHEnome Scan; NIAAA Falk;
Preprint; 2021; UKB; Longitudinal; Brain age; XGB;
JN; 2021(Feb); Semantic representation; RSA; wiki2use;
HBM; 2021(Feb); Subcortial volume; ENIGMA; Lifespan; Fractional Polynomials regression;
01

处方类鸦片使用有可能引起抑郁和焦虑症?比如某些止痛药/针就含有鸦片类的成分。在开出处方之前需要对潜在的风险和收益有全面的了解。之前的研究发现,和其他类型的病人相比,有psychiatric disorder的人报告了更多的long-term opiod use。文章使用了孟德尔随机化结合来自UKB和Lundbeck Foundation Initiative for Integrative Psychiatric Research(N=737,473),揭示了它们的因果关系。
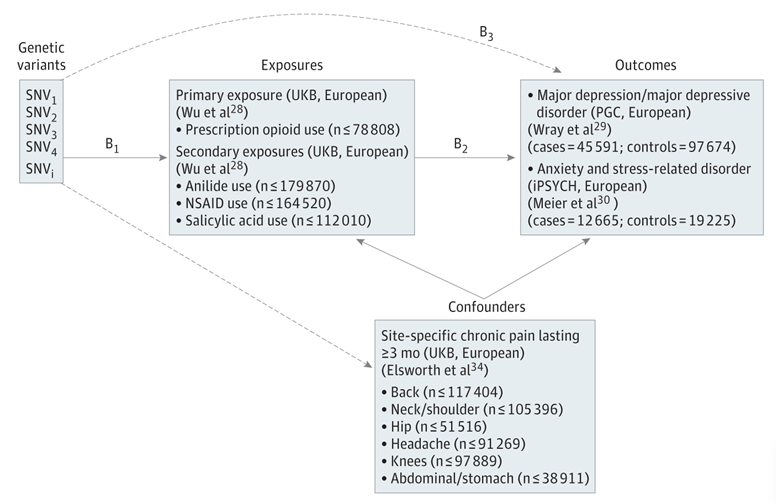
图中所有的数据都是来自其他研究的summary-level data。其中B2就是分析关注的点,处方类鸦片使用对MDD和ASRD的关系。B2=B1/B3,B1和B3分别是相应的GWAS结果。主要用的就是TwoSampleMR,具体方法细节很多,需要参考原文。
值得一提的是,他们使用的一个表型扫描工具,PHEnome Scan Analysis Tool。平时做GWAS的时候是成千上万的基因数据和行为的某一个指标(Phenotype)做相关。而这个工具是反过来的,用成千上万个行为/问卷的指标和某一基因做相关。UKB确实存在成千上万的phenotype,而且数据的类型不一。简书有一份简易教程:
https://www.jianshu.com/p/9812bc8a3c78
文章是在twitter上看到的,读了一半才意识到Daniel和Falk还来组会上报告了他们在做的另一个project,也是类似的思路和同样水平的研究。一作Daniel走的是NIH和牛津剑桥的合作项目,后两年的博士还要到牛津和剑桥接受训练 ~
~
02
Brain age已经成为一种研究范式。首先在训练brain和chronological age的模型,然后在新的被试上使用模型得到brain predicted age。chronological age和brain predicted age之间的差别 [可以称之为brain-pad],被认为一定程度上反应了brain aging。一般的研究套路是对比病人组和控制组的brain-pad,发现病人组出现更多的brain-pad。意味着和正常人相比,病人大脑看起来比实际年龄更老,比如2020年ENIGMA-MDD发在Molecular psychiatry上的文章。严格的来说Brain-Pad就是模型的prediction error。
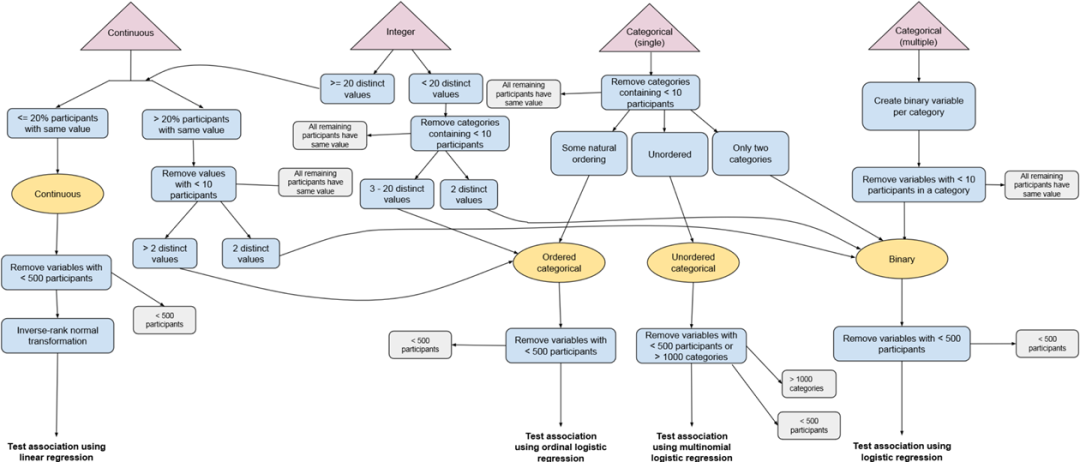
这篇文章主要使用了UKB的数据,研究了brain-pad是否真正反应的是brain aging,使用了LifeBrain数据对发现进行了验证。首先使用训练集n=38682👇e)和提取的结构像ROI训练模型,参照的是Cole的方法【链接:https://james-cole.github.io/UKBiobank-Brain-Age/ 非常详细的notebook】。使用了generalized additive models(GAM)矫正了brain-age bias:brain age is underestimated in older ages and vice versa.
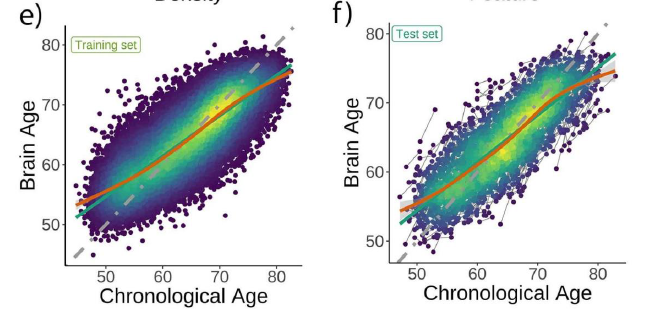
测试集👆f)用的是UKB有longitudinal数据的被试n=1372,使用模型预测每个被试的brain age。
假如一个被试在40岁和44岁分别扫描了一次MRI,那么这个被试根据MRI的结果可以算出两个brain age,假设为46岁和49岁。计算该名被试:
1)mean brain age delta
也就是brain-Pad的平均,((46-40)+(49-44))/2 =5.5
这里可能需要在除以4,文章似乎没有说清楚这一点。
2) yearly rate of brain age changes
(49-46)/4=0.75
对所有被试计算这两个指标,然后使用线性模型+covariates看这两个指标是否相关。
结果如👇图,横轴是指标1),纵轴是指标2)。逻辑是,如果brain-pad可以反应brain aging的话,这两个指标应该是相关的,结果表明不相关。
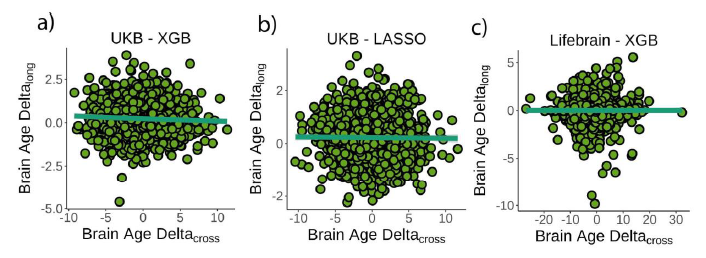
随后探究了birth weight,PGS-brainPad和这两个指标的关系。结果发现常用的brain-pad和这些两个因素相关。值得注意的是他们使用了最近2019年提出的的PGS-CS计算polygenetic score,这个方法似乎正在成为主流。
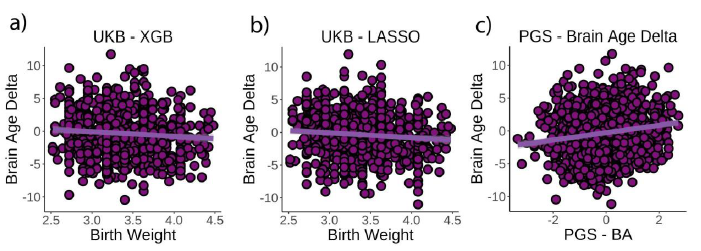
这个研究工作量不小,用了两个machine learning的模型【xgb都用了 ,调参应该值得看一下】,除了UKB还用了Lifebrain,而且做了Birth Weight和PGS的相关。说是全套代码都分享在了GitHub,然而点开后是404
,调参应该值得看一下】,除了UKB还用了Lifebrain,而且做了Birth Weight和PGS的相关。说是全套代码都分享在了GitHub,然而点开后是404 。 意义在于:Without longitudinal imaging, one should thus not interpret brain age as accelerated aging.
。 意义在于:Without longitudinal imaging, one should thus not interpret brain age as accelerated aging.
研究birth weight的原因,看起来还挺有道理的:

文章使用了非常让人困惑的terms ,如果使用之前常用的brain-pad可能更容易理解。比如brain age delta,change in brain age delta,这两个delta意思似乎不一样。如果没猜错的话,brain age delta应该是指标1),也就是mean of brain-pad ,通过cross-sectional方法计算出的。而change in brain age delta是指标2),通过longitudinal方法计算出的yearly changes in brain-predicted age。
,如果使用之前常用的brain-pad可能更容易理解。比如brain age delta,change in brain age delta,这两个delta意思似乎不一样。如果没猜错的话,brain age delta应该是指标1),也就是mean of brain-pad ,通过cross-sectional方法计算出的。而change in brain age delta是指标2),通过longitudinal方法计算出的yearly changes in brain-predicted age。
03

JN 2021二月的文章,使用RSA发现不同皮层区域的表征名人和地点的语义信息。RSA的思路是算刺激的相似性,随后在大脑的数据中搜索具有同样相似性的区域。如何量化语义知识的相似性?作者使用了自然语言模型wiki2use,编码维基百科的名人/地点的文字信息,随后估计其相似性。应该都是一些常规NLP操作随后计算相似性。wiki2use已经开源,可用于量化名人或地点的语义相似性。

为了证明wiki2use模型计算出的语义相似性代表了主观的相似性【人脑中储存的语义】,他们收集了对名人/地点相似性评分的行为数据。比如,在一堆名人中,大家倾向于认为周杰伦和陈奕迅有更高的相似性,同时使用wiki2use模型计算出的相似性高,则表明wiki2use模型在一定程度上反应了主观的相似性。

使用PyMVPA做RSA,结果:
1) anterior temporal face area and lateral prefrontal areas represented semantic knowledge of famous people.
2) posterior medial areas represented semantic knowledge of famous places
3) Hippocampus represented both people and places
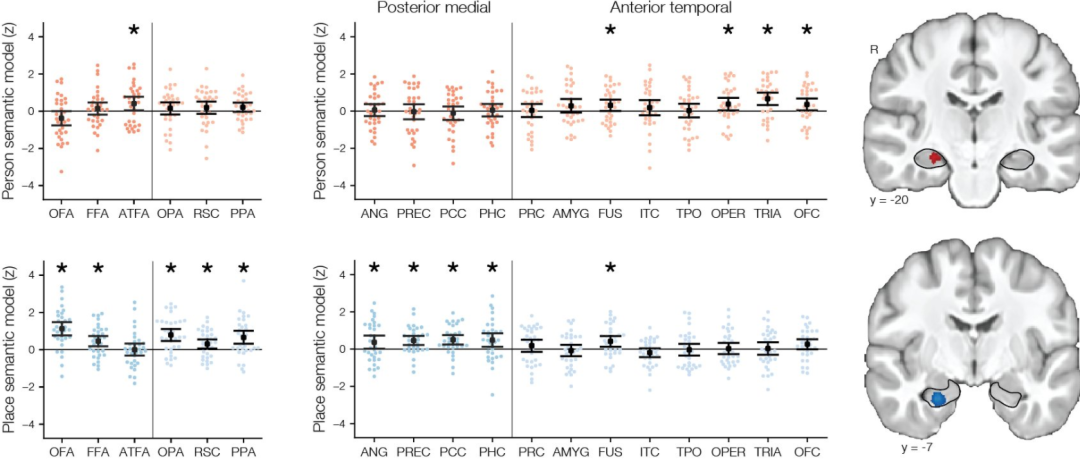
之前的一些研究表明无论什么类别的信息,语义总是存在在一些Hub区域中,而另一些研究表明posterior medial and antierior temporal 网络编码了上下文信息和具体的条目。该研究的结果表明:语义表征可能是有层级的,首先不同的网络表征人物和地点有关的知识,而更具体的差别将在各自相应的网络中表征。
文章的代码分享在了githubhttps://github.com/prestonlab/wikisim
有jupyter notebook,了解RSA不错的资源。
btw,刚好看到中国传媒大学的媒体融合与传播国家重点实验室团队建立了一个中文版概念语义特征数据库(2021年2月),共采集了1410个概念及其语义特征【传送门->中文说明】。虽与这篇JN略有不同,但是如果筛选一部分类别出来作为fMRI的刺激,然后做RSA分析中文语义表征的区域,而且还可以对比同一个概念中英文语义表征的脑区的差异,都应该都是不错的idea。不太了解这个领域,那么容易想到的idea一般都是已经被人做过了 ,不过既然是新的语义特征数据库,还是可以blah出一堆novelty的理由。
,不过既然是新的语义特征数据库,还是可以blah出一堆novelty的理由。
04

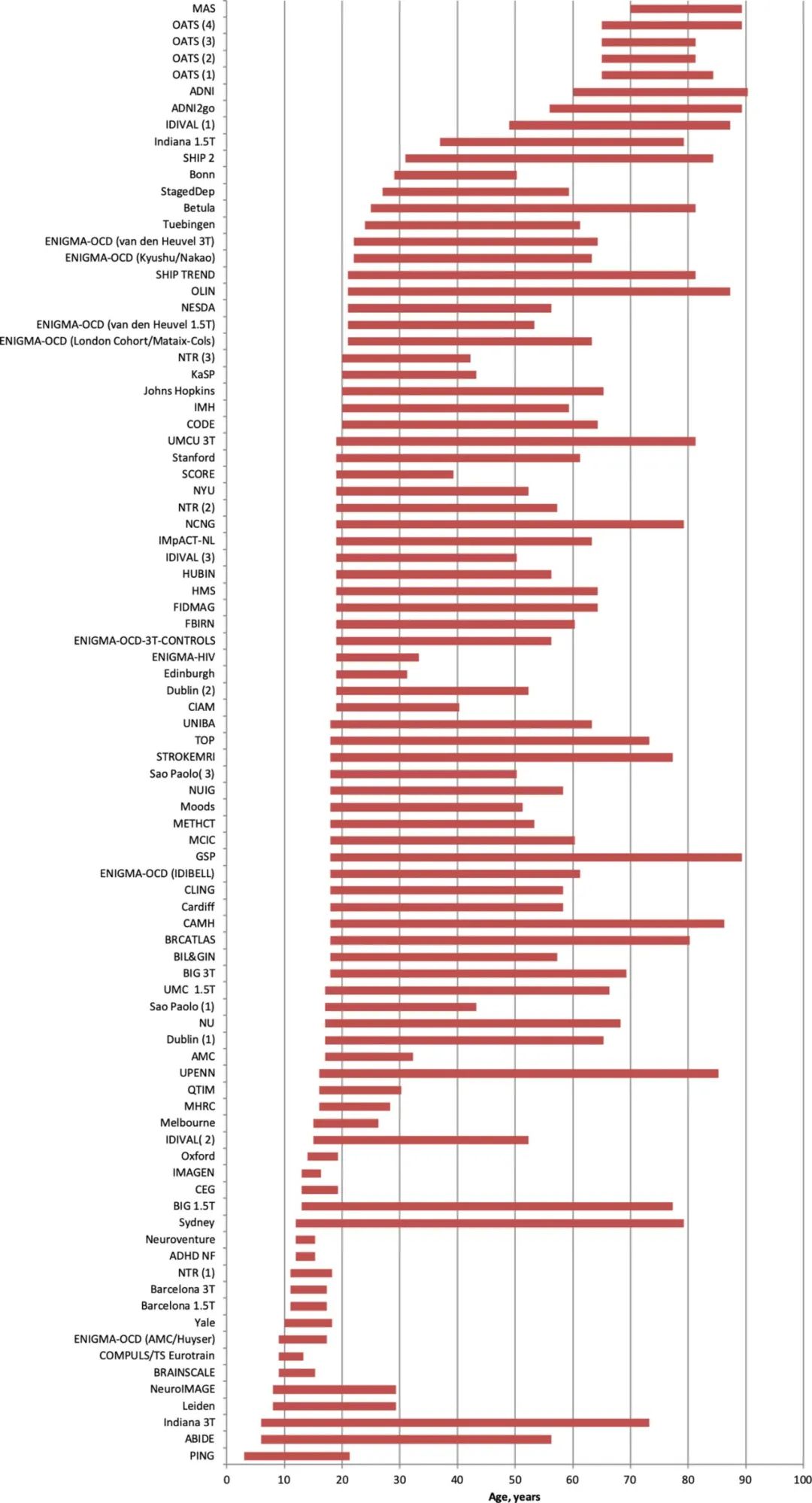
Neuroiamging最后都变成了统计/机器学习/生信。18,605个subcortial的数据【数据来源见下图👇】不算新鲜,因为都是csv里的数据,通过email就可以分享那种。重点是Lifespan/trajectory研究的统计方法。用了combat做多中心/不同freesurfer版本的Harmonization【传送门->combat】。
非参数回归,之前提到过LOWESS和Spline,这个研究用的是多项式回归Fractional Polynomials regression,是由Royston等人提出的,可以简单理解成多项式回归的扩展版。
However, low order polynomials offer a limited family of shapes, and high order polynomials may fit poorly at the extreme values of the covariates. We propose an extended family of curves, which we call fractional polynomials, whose power terms are restricted to a small predefined set of integer and non‐integer values.
Royston, P., & Altman, D. G. (1994)
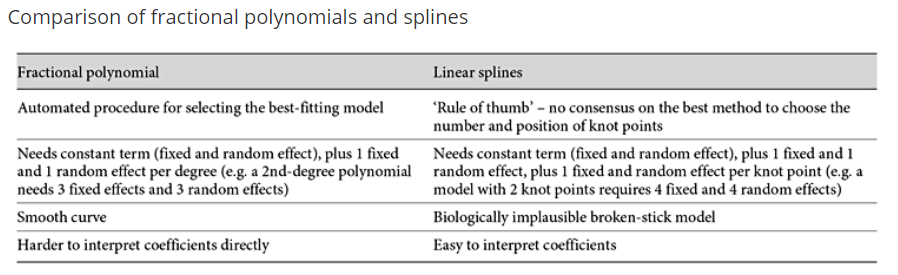
和线性Spline的区别(Tilling, K., et, al. 2014)
The fractional polynomial model assumes a smooth, monotonic curve,whereas the linear spline model assumes a biologically implausible (but more interpretable) piecewise linear relationship.
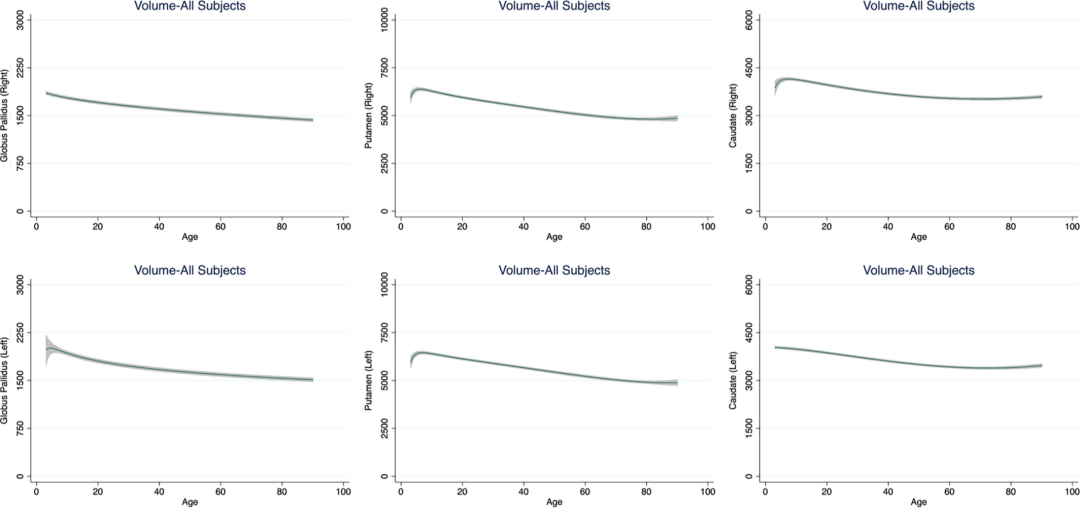
对每个ROI做多项式回归后得到类似如下结果
结果基于回归的曲线和年龄组进行报告, early (6–29 years), middle (30–59 years), and late‐life (60–90 years) age‐group。分组基于conventional notions regarding periods of development, midlife and aging。这么一说第一组6-29岁勉强还行。此外还计算了年龄组的inter-individual variability,使用GAMLSS估计了centile curves下图👇。
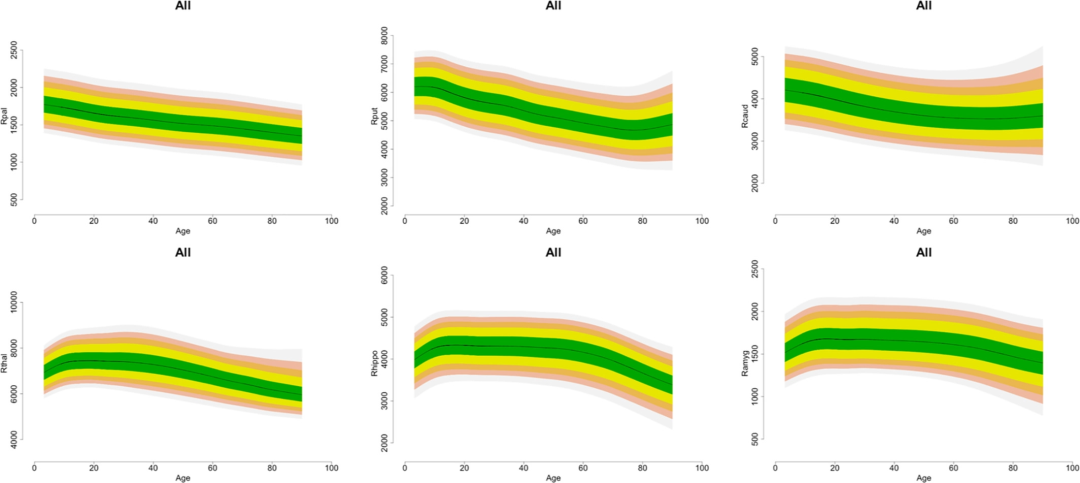
文章brain plot都没有,centile curve的配色有点扎眼,可能是使用绿色导致的【见配色原则】,或者是颜色的梯度不对。坐标轴的标签和刻度也是小得非常不直观。
主要结果:
All subcortical structure volumes were at their maximum value early in life.
The volume of the basal ganglia showed a monotonic negative association with age thereafter
there was no significant association between age and the volumes of the thalamus, amygdala and the hippocampus (with some degree of decline in thalamus) until the sixth decade of life after which they also showed a steep negative association with age
The lateral ventricles showed continuous enlargement throughout the lifespan.
Age was positively associated with inter‐individual variability in the hippocampus and amygdala and the lateral ventricles.
意义?

—END—




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









