






简介
分层聚类算法试图建立一个聚类的层次结构,有两类:聚合型(agglomerative)和分裂型(divisive)。聚合法最初将每个数据点作为一个单独的聚类,然后迭代合并,直到最后的聚类中包含所有的数据点。它也被称为自下而上的方法。分裂聚类遵循自上而下的流程,从一个拥有所有数据点的单一聚类开始,迭代地将该聚类分割成更小的聚类,直到每个聚类包含一个数据点。
下图展示的便是聚合法的示意图。
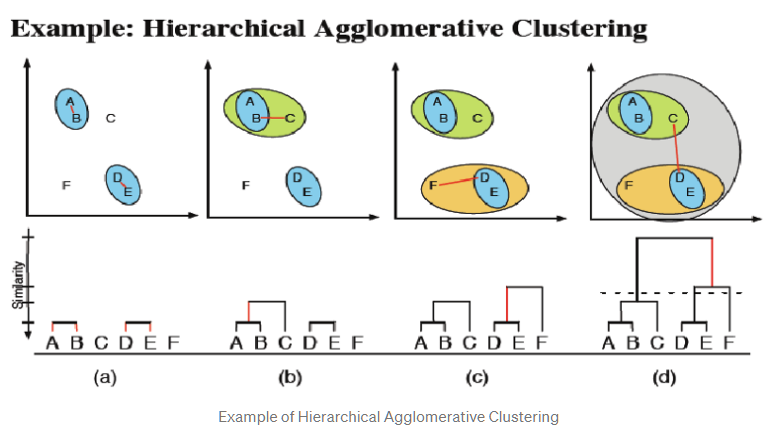
-
流程
-
聚合分层聚类算法包括以下步骤:
-
计算各聚类之间的距离(初始时,每个数据点作为一个单独的聚类)。
-
根据距离函数,将相似的聚类合并成一个聚类。
-
重复上述两步,直到所有的数据点被合并成最后一个聚类。
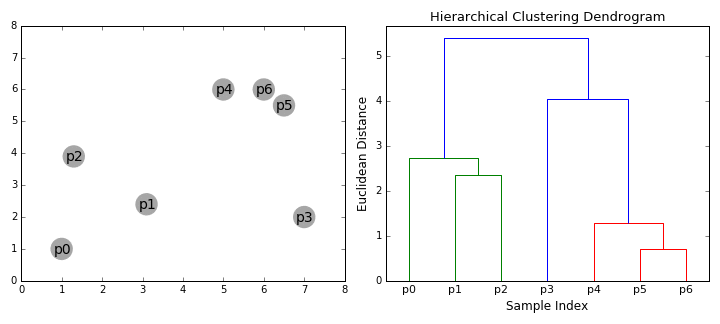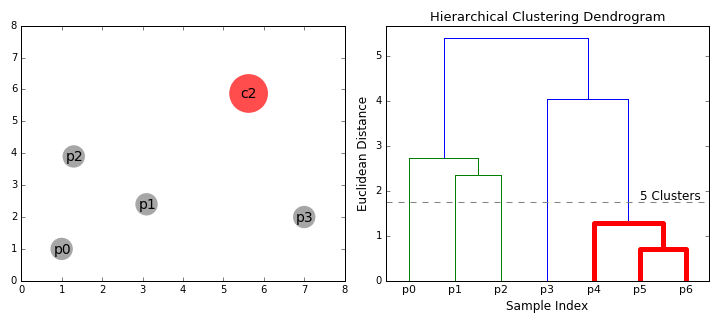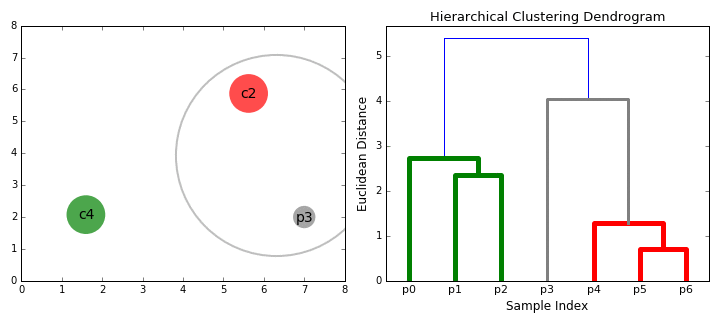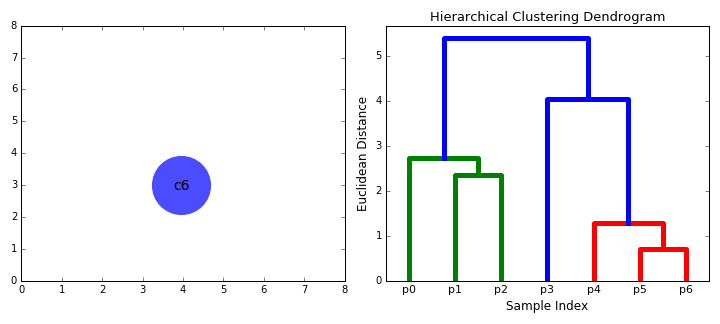
-
常用的距离函数:
-
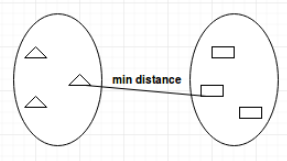
单联动(single-linkage): 一个类中的点和另一个类中的点的最小距离
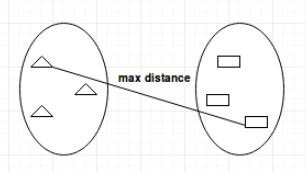
全联动(complete-linkage): 一个类中的点和另一个类中的点的最大距离
-
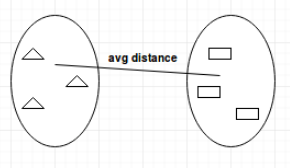
平均联动(average-linkage): 一个类中的点和另一个类中的点的平均距离
-
Ward法(ward): 和平均类似,只不过计算的是两个类之间的平方和。
质心(controid): 两类中质心之间的距离,对单个变量来说,就是变量的值
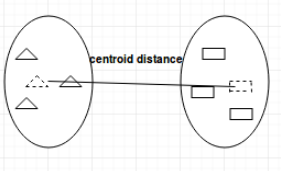
聚类数目
-
生成树形图之后,下一步便是决定多少个类别合适。可以考虑像Silhouette plot、Scree Plot,或一些指标如Gap stat, Dunn's index、Hubert's gamma等。
使用factoextra包直接画出WSS/silhouetee/gap stat。使用hclust的时候,factorextra包似乎会替你计算距离,因此输入数据为原始数据,而hclust函数需要自己算距离(参见fpc包自带的例子)。
p1=fviz_nbclust(df2cluster, hcut, method = "wss",hc_metric = "euclidean", hc_method = "ward.D2")
p2=fviz_nbclust(df2cluster, hcut, method = "silhouette",hc_metric = "euclidean", hc_method = "ward.D2")
p3=fviz_nbclust(df2cluster, hcut, method = "gap_stat",hc_metric = "euclidean", hc_method = "ward.D2")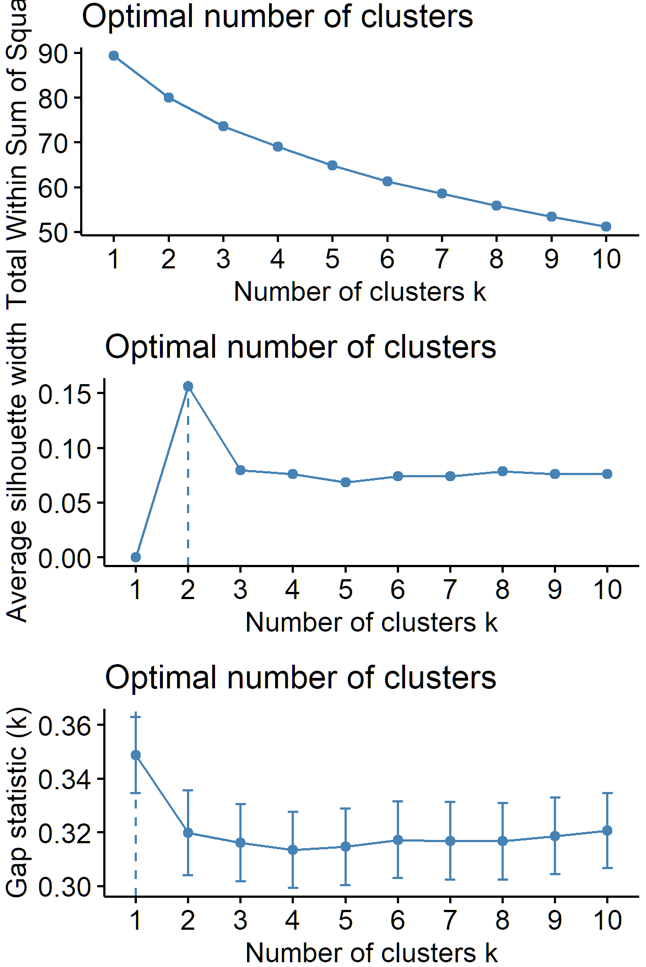
在决定好k值后,还可以画出相应的分类,比如k=5
hc.res <- eclust(df2cluster, "hclust", k = 5, hc_method = "ward.D2", graph = FALSE)
p1=fviz_dend(hc.res, show_labels = FALSE, palette = "jco", as.ggplot = TRUE)
p2=fviz_cluster(hc.res)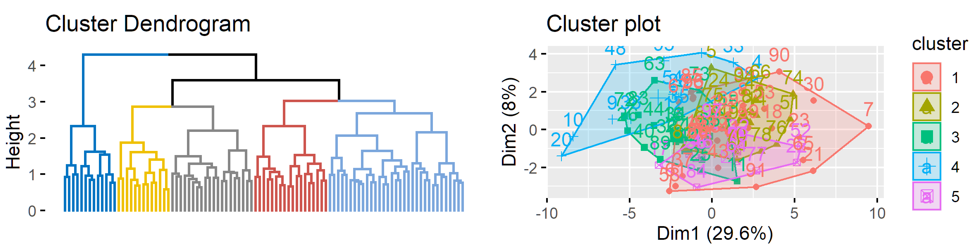
-
Dunn's index可以用fpc中的cluster.stats()计算,因为基于hclust,这里需要自己计算距离。
set.seed(20000)
options(digits=3)
face <- rFace(200,dMoNo=2,dNoEy=0,p=2)
dface <- dist(face) # 自己计算 dist
complete3 <- cutree(hclust(dface),3)
cluster.stats(dface,complete3,
alt.clustering=as.integer(attr(face,"grouping")))顺便用这个例子验证一下factoextra的输入到底是不是原数据。
set.seed(20000)
options(digits=3)
face <- rFace(200,dMoNo=2,dNoEy=0,p=2)
dface <- dist(face) # 自己计算 dist
#输入为dface
res1=hclust(dface,method = "ward.D2")
p1=fviz_dend(res1, k=3, show_labels = FALSE, palette = "jco", as.ggplot = TRUE)+ggtitle('hclust输入为距离')
#输入为 face
res2 <- eclust(face, "hclust", hc_method = "ward.D2", graph = FALSE)
p2=fviz_dend(res2, k=3, show_labels = FALSE, palette = "jco", as.ggplot = TRUE)+ggtitle('factoextra输入为原数据')
grid.arrange(p1,p2,ncol=1)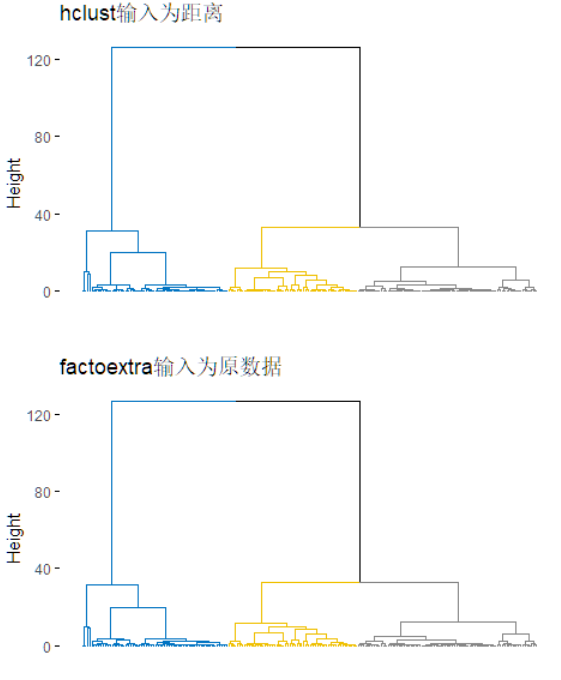
其它
优点
-
不一定需要指定聚类的数量。
-
像k-means一样,分层聚类算法很容易实现。
-
它可以输出聚类树(dendrogram)的层次结构,这可以帮助决定聚类的数量。
缺点
-
分层聚类的主要缺点是其时间复杂性。与其他算法相比,它的复杂度相对较高,为O(n² logn),n为数据点的数量。
-
一个聚类被创建,成员数据点就不能被移动。(与此相对的是一批soft clustering算法)
-
根据距离矩阵的选择,它可能对噪音和异常值很敏感。
hclust最常见的运用可能还是在各种heatmap中展示聚类的情况。
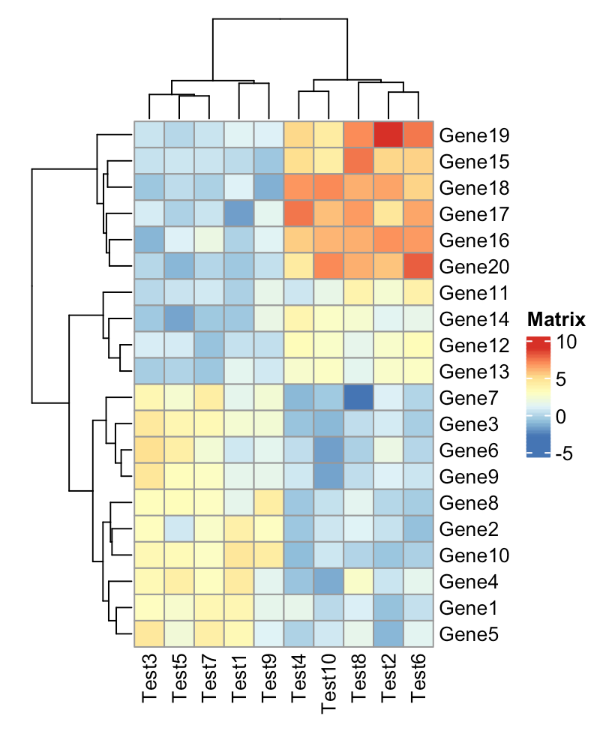
heatmap/pheatmap/aheatmap等自带聚类的作图工具都使用了hclust的聚类方法,比如aheatmap和pheatmap中的complete指的就是hclust中的complete-linkage

参考
https://medium.com/geekculture/hierarchical-clustering-simply-explained-f86b9ed96db7
https://www.datacamp.com/tutorial/hierarchical-clustering-R

















 1774
1774

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









