









Pandas 是一个强大的 Python 数据处理库,它提供了高性能、易于使用的数据结构和数据分析工具。以下是 Pandas 的主要应用场景和作用:
-
数据清洗与预处理:Pandas 提供了丰富的数据清洗和预处理功能,可以帮助用户处理缺失值、异常值、重复值等数据质量问题,并进行数据转换、格式化、重塑等操作。
-
数据探索与分析:Pandas 提供了灵活的数据结构(如 Series 和 DataFrame),使得数据的索引、切片、筛选、聚合等操作变得简单高效。通过 Pandas,用户可以快速进行数据探索、统计分析、数据可视化等任务。
-
数据合并与连接:Pandas 可以方便地将多个数据源进行合并、连接、拼接,支持不同形式的数据(如 CSV、Excel、数据库等)之间的数据交互与整合。
-
时间序列数据处理:Pandas 提供了专门的时间序列数据结构和函数,可以轻松处理时间序列数据,如日期范围生成、频率转换、滞后计算、移动窗口统计等。
-
缺失值处理:Pandas 提供了对缺失值的灵活处理方式,包括填充缺失值、删除缺失值、插值等方法,使得用户能够更好地处理数据中的缺失信息。
总而言之,Pandas 在数据处理、数据分析和数据探索等方面发挥着重要作用,成为 Python 生态系统中不可或缺的数据处理工具之一。
目录
6. label_opts=opts.LabelOpts(position="right")
导入excel,别的文档格式同理
import pandas as pd
df = pd.read_excel()同理:
- pd.read_csv() - 读取csv文件。
- pd.DataFrame() - 创建数据框。
下面这个选取行数就有意思了
df.head(20)
df.tail(20)选取函数的规则如下
| head | 读取前n行 |
| tail | 读取倒数n行 |
选取条件数据
date = df[df["列下属"] > 10]下面跟条件判断一样
(温馨提示)== 如果没有,什么也不会输出
date执行后,会自动转存为列表
下面是pandas的一系列旁支末节的工具
df.info() - 显示数据框的基本信息(列名、数据类型、非空值的数量等)。
df.describe() - 显示数据框的描述性统计信息(如平均值、最大值、最小值等)。
df.shape() - 显示数据框的形状(行数和列数)。
df.columns() - 显示数据框的列名。
df.set_index() - 将某一列设置为索引。
df.reset_index() - 重置索引。
df.dropna() - 删除含有缺失值的行。
df.fillna() - 将缺失值填充为指定值。
df.drop_duplicates() - 删除重复行。
df.groupby() - 按指定列进行分组。
df.sort_values() - 按指定列进行排序。
df.merge() - 合并两个数据框。
df.pivot_table() - 创建数据透视表。
df.apply() - 对每一列或每一行应用指定函数。
df.plot() - 绘制数据框中的图表。下面,我们进入关键部分
from pyrcharts.charts import Rader
c = Rader()导入pyrcharts.charts,import后面加模板
下面无论怎么样。都要初始化
以雷达图作为模板,我们先上
from pyecharts.charts import Radar
# 初始化
c = Radar()
#添加数据——设置维度
schema = [
{"name": "颜值", "max":100},
{"name": "智商”, "max":100},
{"name": "体力", "max":100},
{"name": "耐心", "max":100},
{"name": "代码能力", "max":100},
]
# =====================================
# 添加数据
# 设置数值,要注意:1.二维列表 2.元素个数需要和维度个数一致
count = [[50,55,75,90,100]]
c.add_schema(schema)
#修改下列代码,设置图例名称和文件名称
c.add("能力图", count)
c.render("能力图.html")重点通用功能介绍:将图标封装为html文件
c.render()我的一个大胆猜想:
除了html后缀,是不是还可以填入".png",".jpg"......
一、pyecharts库
库的名称:pyecharts
作用:python中数据可视化工具,可以将数据处理成漂亮的图表。
导入模块:
from pyecharts.charts import Bar
from pyecharts.charts import line
from pyecharts.charts import Pie
二、柱状图功能总结
1. Bar()
作用:柱状图初始化
格式:bar = Bar()
2. add_xaxis()
作用:增加x轴数据
格式:bar.add_xaxis(["青山","明月","春风"])
表示x轴有三个类型,分别是青山、明月、绿水。
3. add_yaxis()
作用:增加y轴数据
格式:bar.add_yaxis("出现次数",[11,12,10])
表示y轴表示出现次数,分别是青山11次、明月12次、绿水10次。
4. render()
作用:表示生成文件
格式:bar.render("唐诗中的意境.html")
表示生成 唐诗中的意境.html 文件,可以直接用浏览器打开
from pyecharts.charts import Bar
bar = Bar()
bar.add_xaxis(["青山","明月","春风"])
bar.add_yaxis("出现次数",[11,12,10])
bar.render("唐诗中的意境.html")

5. reversal_axis()
作用:翻转x轴和y轴
格式:bar.reversal_axis()
翻转之后x轴的内容竖直显示,y轴的内容横行显示
6. label_opts=opts.LabelOpts(position="right")
作用:设置标签值在柱状图的右侧显示
格式:bar.add_yaxis("出现次数",count,label_opts=opts.LabelOpts(position="right"))
import pandas as pd
from pyecharts.charts import Bar
from pyecharts import options as opts
df = pd.read_excel("热门景点.xlsx")
data = df.sort_values(by="销售量",ascending="False")
name = list(data.head(10)["景点名称"])
count = list(data.head(10)["销售量"])
bar = Bar()
bar.add_xaxis(name)
bar.add_yaxis("出现次数",count,label_opts=opts.LabelOpts(position="right"))
bar.reversal_axis()
bar.render("唐诗中的意境.html")
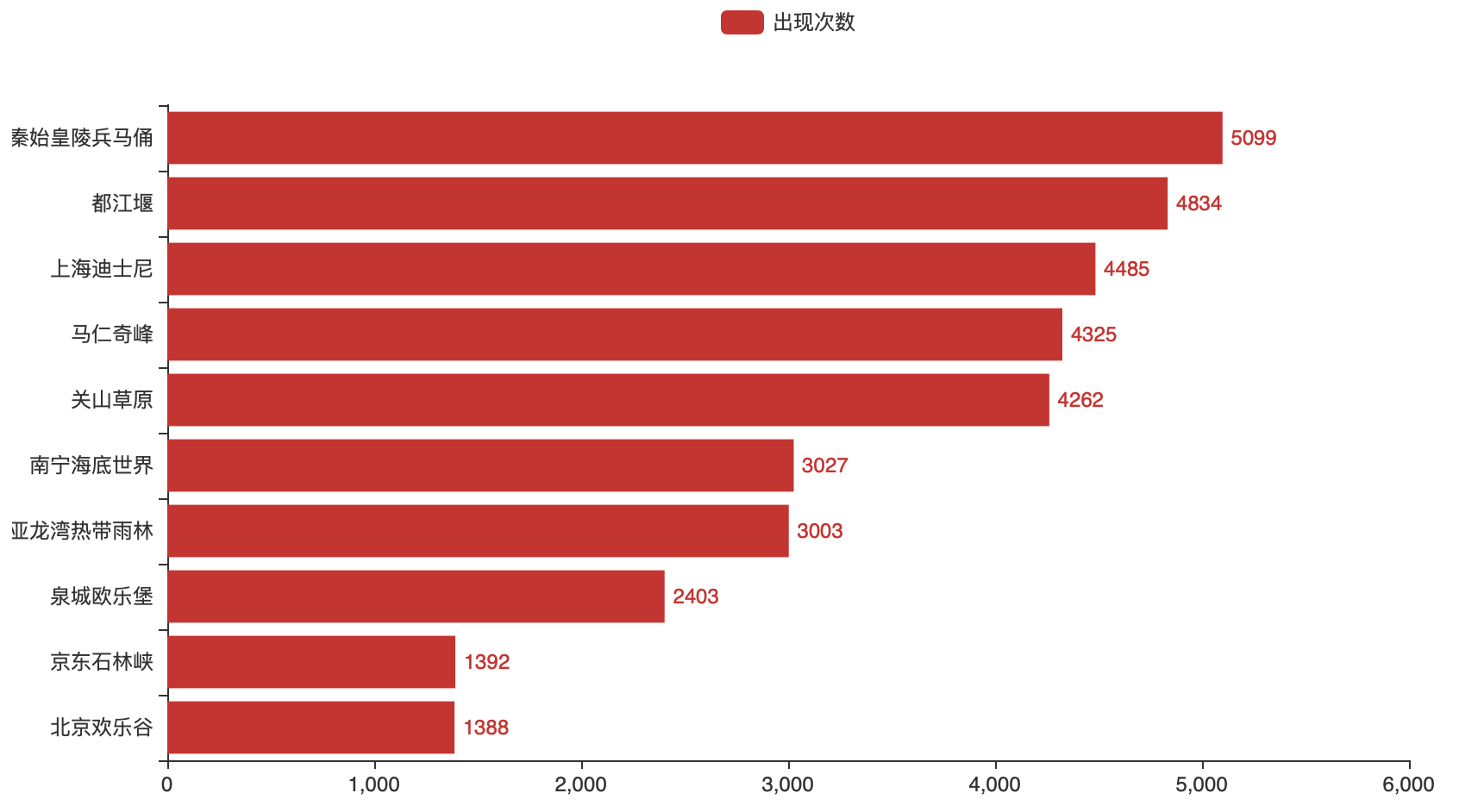
7.set_global_opts()
作用:设置x轴标签倾斜度
格式:bar.set_global_opts(xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15)))
参数为-15表示顺时针旋转15度
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import Bar
from xes.tool import *
xopen() #打开文件夹
df = pd.read_excel("热门景点.xlsx")
data = df.sort_values(by="门票销售量", ascending=False)
name = list(data.head(10)["景点名称"])
count = list(data.head(10)["门票销售量"])
# 绘制柱狀图
bar = Bar()
bar.add_xaxis(name)
bar.add_yaxis("门票销售量", count)
bar.set_global_opts(
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15))
)
bar.render("全国景点门票销量TOP10.html")

三、折线图功能总结
1. Line()
作用:线性图初始化
格式:c = Line()
2. add_xaxis()
作用:增加x轴数据
格式:
c.add_xaxis(list(df["年份"]))
表示x轴表示年份。
3. add_yaxis()
作用:增加y轴数据
绘制多个折线图的方法就是添加多个y轴数据
格式:bar.add_yaxis("名称",数据)
第一个参数表示折现表示的类别名称,第二个参数表示传入的数据
c.add_yaxis("各行平均工资", list(df["各行平均工资"]))
c.add_yaxis("制造业", list(df["制造业"]))
c.add_yaxis("计算机和软件业", list(df["计算机和软件业"]))
c.add_yaxis("金融", list(df["金融"]))
c.add_yaxis("房地产业", list(df["房地产业"]))
c.add_yaxis("教育", list(df["教育"]))
4. render()
作用:表示生成文件
格式:c.render("各行业平均工资分析.html")
表示生成 各行业平均工资分析.html 文件,可以直接用浏览器打开
import pandas as pd
from pyecharts.charts import Line
df = pd.read_excel("各行业平均工资.xlsx")
print(df.columns)
c = Line()
c.add_xaxis(list(df["年份"]))
c.add_yaxis("各行平均工资", list(df["各行平均工资"]))
c.add_yaxis("制造业", list(df["制造业"]))
c.add_yaxis("计算机和软件业", list(df["计算机和软件业"]))
c.add_yaxis("金融", list(df["金融"]))
c.add_yaxis("房地产业", list(df["房地产业"]))
c.add_yaxis("教育", list(df["教育"]))
c.render("各行业平均工资分析.html")
运行结果:

5. 数据的比较分析法
纵向比较:上升还是下降
横向比较:哪个整体更高、哪个增速更快、哪个更接近均值
import pandas as pd
from pyecharts.charts import Line
# 分析就业人数
df = pd.read_excel("各行就业人数.xlsx")
print(df.columns)
c = Line()
c.add_xaxis(list(df["年份"]))
c.add_yaxis("总人数", list(df["总人数"]))
c.add_yaxis("制造业", list(df["制造业"]))
c.add_yaxis("计算机和软件业", list(df["计算机和软件业"]))
c.add_yaxis("金融", list(df["金融"]))
c.add_yaxis("房地产业", list(df["房地产业"]))
c.add_yaxis("教育", list(df["教育"]))
c.render("各行业就业人数分析.html")
运行结果:
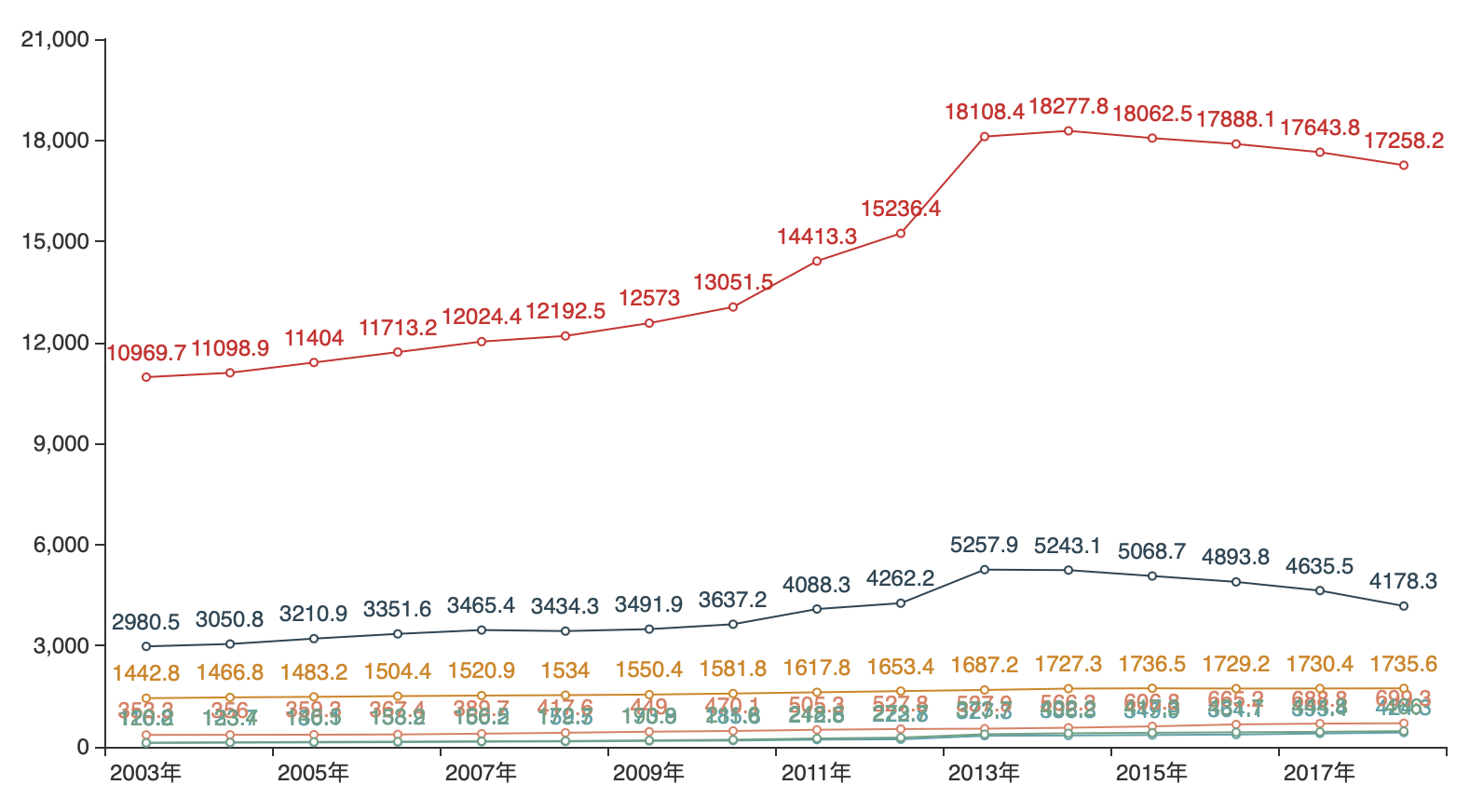
四、饼图功能总结
1. Pie()
作用:创建饼图对象
格式:c = Pie()
2. add()
作用:增加数据
格式:c.add(系列名称,data,radius=[内圆半径,外圆半径])
系列名称参数为字符串格式,鼠标滑过饼图,显示系列名称。
data参数是一个元组,表示系列数据,是分组统计的结果。
radius参数用百分数表示,radius=["20%","80%"]就是一个内圆半径是百分之二十,外圆半径是百分之八十的饼图。
3. render()
作用:表示生成饼图
格式:c.render("学生打分结果.html")
表示生成 学生打分结果.html 文件,可以直接用浏览器打开
from pyecharts.charts import Pie
import pandas as pd
from xes.tool import *
xopen()
# --------数据分析---------------------------------------
df = pd.read_excel("动漫评分.xlsx")
print(df.columns)
print(df["学生打分"].max()) # 最高成绩
print(df["学生打分"].min()) # 最低成绩
scoreLab = pd.cut(df["学生打分"], bins = [0, 20, 40, 60, 80, 100],
labels=["超级不喜欢", "不喜欢", "一般般", "喜欢", "超喜欢"])
print(scoreLab)
result = df["学生打分"].groupby(by=scoreLab).count()
print(result)
# --------数据可视化---------------------------------------
data = [("超级不喜欢", 19), ("不喜欢", 29), ("一般般", 44), ("喜欢", 33), ("超喜欢", 129)]
c = Pie()
c.add("分数分布", data, radius=["40%", "80%"])
c.set_colors(["blue", "green", "yellow", "red", "pink"])
c.render("学生打分结果.html")
















 1196
1196











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









