







免责声明
-
版权声明
本着互联网的开放精神,本项目采用开放的[GPL]协议进行许可,转载请保留本声明及作者信息,禁止用于任何商业用途 -
关于作者
Hollis ,阿里巴巴技术专家,51CTO 专栏作家,CSDN 博客专家,掘金优秀作者,《程序员的三门课》联合作者,《Java 工程师成神之路》系列文章作者;热衷于分享计算机编程相关技术,博文全网阅读量数千万
基础篇
面向对象
-
面向对象与面向过程
- 什么是面向过程
- 概述: 自顶而下的编程模式
- 详解:把问题分解成一个一个步骤,每个步骤用函数实现,依次调用即可。就是说,在进行面向过程编程的时候,不需要考虑那么多,上来先定义一个函数,然后使用各种诸如 if-else、for-each 等方式进行代码执行。最典型的用法就是实现一个简单的算法,比如实现冒泡排序
- 什么是面向对象
- 概述: 将事务高度抽象化的编程模式
- 详解:将问题分解成一个一个步骤,对每个步骤进行相应的抽象,形成对象,通过不同对象之间的调用,组合解决问题。就是说,在进行面向对象进行编程的时候,要把属性、行为等封装成对象,然后基于这些对象及对象的能力进行业务逻辑的实现。比如:想要造一辆车,上来要先把车的各种属性定义出来,然后抽象成一个 Car 类
- 举例说明区别
- 场景:同样一个象棋设计
- 面向对象:创建黑白双方的对象负责演算,棋盘的对象负责画布,规则的对象负责判断,例子可以看出,面向对象更重视不重复造轮子,即创建一次,重复使用
- 面向过程:开始—黑走—棋盘—判断—白走—棋盘—判断—循环。只需要关注每一步怎么实现即可
- 优劣对比
- 面向对象:占用资源相对高,速度相对慢
- 面向过程:占用资源相对低,速度相对快
- 什么是面向过程
-
面向对象的三大基本特征和五大基本原则
- 面向对象的三大基本特征
- 封装(Encapsulation)
- 所谓封装,也就是把客观事物封装成抽象的类,并且类可以把自己的数据和方法只让可信的类或者对象操作,对不可信的进行信息隐藏
- 封装是面向对象的特征之一,是对象和类概念的主要特性。简单的说,一个类就是一个封装了数据以及操作这些数据的代码的逻辑实体。在一个对象内部,某些代码或某些数据可以是私有的,不能被外界访问,通过这种方式,对象对内部数据提供了不同级别的保护,以防止程序中无关的部分意外的改变或错误的使用了对象的私有部分
- 继承(Inheritance)
- 继承是指这样一种能力:它可以使用现有类的所有功能,并在无需重新编写原来的类的情况下对这些功能进行扩展
- 通过继承创建的新类称为"子类”或“派生类”,被继承的类称为“基类”、“父类”或“超类”,继承的过程,就是从一般到特殊的过程
- 继承概念的实现方式有二类:实现继承与接口继承
- 实现继承是指直接使用基类的属性和方法而无需额外编码的能力
- 接口继承是指仅使用属性和方法的名称、但是子类必须提供实现的能力
- 多态(Polymorphism)
- 所谓多态就是指一个类实例的相同方法在不同情形有不同表现形式
- 多态机制使具有不同内部结构的对象可以共享相同的外部接口。这意味着,虽然针对不同对象的具体操作不同,但通过一个公共的类,它们(那些操作)可以通过相同的方式予以调用
- 最常见的多态就是将子类传入父类参数中,运行时调用父类方法时通过传入的子类决定具体的内部结构或行为
- 封装(Encapsulation)
- 面向对象五大基本原则
- 单一职责原则(Single-Responsibility Principle)
- 核心思想是:一个类,最好只做一件事,只有一个引起它的变化
- 单一职责原则可以看做是低耦合、高内聚在面向对象原则上的引申,将职责定义为引起变化的原因,以提高内聚性来减少引起变化的原因
- 通常意义下的单一职责,就是指只有一种单一功能,不要为类实现过多的功能点,以保证实体只有一个引起它变化的原因
- 开放封闭原则(Open-Closed principle)
- 核心思想是:软件实体应该是可扩展的,而不可修改的。也就是,对扩展开放,对修改封闭
- 开放封闭原则主要体现在两个方面:1、对扩展开放,意味着有新的需求或变化时,可以对现有代码进行扩展,以适应新的情况。2、对修改封闭,意味着类一旦设计完成,就可以独立完成其工作,而不要对其进行任何尝试的修改
- 实现开放封闭原则的核心思想就是对抽象编程,而不对具体编程,因为抽象相对稳定。让类依赖于固定的抽象,所以修改就是封闭的;而通过面向对象的继承和多态机制,又可实现对抽象类的继承,通过覆写其方法来改变固有行为,实现新的拓展方法,所以就是开放的
- Liskov 替换原则(Liskov-Substitution Principle)
- 核心思想是:子类必须能够替换其基类
- 这一思想体现为对继承机制的约束规范,只有子类能够替换基类时,才能保证系统在运行期内识别子类,这是保证继承复用的基础。在父类和子类的具体行为中,必须严格把握继承层次中的关系和特征,将基类替换为子类,程序的行为不会发生任何变化。同时,这一约束反过来则是不成立的,子类可以替换基类,但是基类不一定能替换子类
- Liskov 替换原则,主要着眼于对抽象和多态建立在继承的基础上,因此只有遵循 Liskov 替换原则,才能保证继承复用是可靠地
- 实现的方法是面向接口编程:将公共部分抽象为基类接口或抽象类,通过 ExtractAbstract Class,在子类中通过覆写父类的方法实现新的方式支持同样的职责。 Liskov 替换原则是关于继承机制的设计原则,违反了 Liskov 替换原则就必然导致违反开放封闭原则。Liskov 替换原则能够保证系统具有良好的拓展性,同时实现基于多态的抽象机制,能够减少代码冗余,避免运行期的类型判别
- 依赖倒置原则(Dependecy-Inversion Principle)
- 其核心思想是:依赖于抽象
- 具体而言就是高层模块不依赖于底层模块,二者都同依赖于抽象;抽象不依赖于具体,具体依赖于抽象
- 我们知道,依赖一定会存在于类与类、模块与模块之间。当两个模块之间存在紧密的耦合关系时,最好的方法就是分离接口和实现:在依赖之间定义一个抽象的接口使得高层模块调用接口,而底层模块实现接口的定义,以此来有效控制耦合关系,达到依赖于抽象的设计目标。抽象的稳定性决定了系统的稳定性,因为抽象是不变的,依赖于抽象是面向对象设计的精髓,也是依赖倒置原则的核心。依赖于抽象是一个通用的原则,而某些时候依赖于细节则是在所难免的,必须权衡在抽象和具体之间的取舍,方法不是一层不变的。依赖于抽象,就是对接口编程,不要对实现编程
- 接口隔离原则(Interface-Segregation Principle)
- 其核心思想是:使用多个小的专门的接口,而不要使用一个大的总接口
- 具体而言,接口隔离原则体现在:接口应该是内聚的,应该避免“胖”接口。一个类对另外一个类的依赖应该建立在最小的接口上,不要强迫依赖不用的方法,这是一种接口污染。接口有效地将细节和抽象隔离,体现了对抽象编程的一切好处,接口隔离强调接口的单一性。而胖接口存在明显的弊端,会导致实现的类型必须完全实现接口的所有方法、属性等;而某些时候,实现类型并非需要所有的接口定义,在设计上这是“浪费”,而且在实施上这会带来潜在的问题,对胖接口的修改将导致一连串的客户端程序需要修改,有时候这是一种灾难。在这种情况下,将胖接口分解为多个特点的定制化方法,使得客户端仅仅依赖于它们的实际调用的方法,从而解除了客户端不会依赖于它们不用的方法
- 分离的手段主要有以下两种:1、委托分离,通过增加一个新的类型来委托客户的请求,隔离客户和接口的直接依赖,但是会增加系统的开销。2、多重继承分离,通过接口多继承来实现客户的需求,这种方式是较好的
- 总结
- 以上就是 5 个基本的面向对象设计原则,它们就像面向对象程序设计中的金科玉律,遵守它们可以使我们的代码更加鲜活,易于复用,易于拓展,灵活优雅。不同的设计模式对应不同的需求,而设计原则则代表永恒的灵魂,需要在实践中时时刻刻地遵守。就如 ARTHUR J.RIEL 在那边《OOD 启示录》中所说的:“你并不必严格遵守这些原则,违背它们也不会被处以宗教刑罚。但你应当把这些原则看做警铃,若违背了其中的一条,那么警铃就会响起。”
- 单一职责原则(Single-Responsibility Principle)
- 面向对象的三大基本特征
-
Java中的封装、继承、多态
- 多态
- 什么是多态
- 多态的概念比较简单,就是同一操作作用于不同的对象,可以有不同的解释,产生不同的执行结果。如果按照这个概念来定义的话,那么多态应该是一种运行期的状态
- 多态的必要条件
- 为了实现运行期的多态,或者说是动态绑定,需要满足三个条件。即有类继承或者接口实现、子类要重写父类的方法、父类的引用指向子类的对象。简单来一段代码解释下
public class Parent{ public void call(){ sout("im Parent"); } } // 1.有类继承或者接口实现 public class Son extends Parent{ // 2.子类要重写父类的方法 public void call(){ sout("im Son"); } } // 1.有类继承或者接口实现 public class Daughter extends Parent{ // 2.子类要重写父类的方法 public void call(){ sout("im Daughter"); } } public class Test{ public static void main(String[] args){ // 3.父类的引用指向子类的对象 Parent p = new Son(); // 3.父类的引用指向子类的对象 Parent p1 = new Daughter(); } }- 这样,就实现了多态,同样是 Parent 类的实例,p.call 调用的是 Son 类的实现、p1.call 调用的是 Daughter 的实现
- 什么是多态
- 重载和重写
- 定义
- 重载:简单说,就是函数或者方法有同样的名称,但是参数列表不相同的情形,这样的同名不同参数的函数或者方法之间,互相称之为重载函数或者方法
- 重写:重写指的是在 Java 的子类与父类中有两个名称、参数列表都相同的方法的情况。由于他们具有相同的方法签名,所以子类中的新方法将覆盖父类中原有的方法
- 重载 VS 重写
- 重载是一个编译期概念,重写是一个运行期间概念
- 重载遵循所谓“编译期绑定”,即在编译时根据参数变量的类型判断应该调用哪个方法
- 重写遵循所谓“运行期绑定”,即在运行的时候,根据引用变量所指向的实际对象的类型来调用方法
- 因为在编译期已经确定调用哪个方法,所以重载并不是多态。而重写是多态。重载只是一种语言特性,是一种语法规则,与多态无关,与面向对象也无关。(注:严格来说,重载是编译时多态,即静态多态。但是,Java 中提到的多态,在不特别说明的情况下都指动态多态)
- 重写的例子
class Dog{ public void bark(){ System.out.println("woof "); } } class Hound extends Dog{ public void sniff(){ System.out.println("sniff "); } public void bark(){ System.out.println("bowl"); } } public class OverridingTest{ public static void main(String [] args){ Dog dog = new Hound(); dog.bark(); } } // 输出结果 // bowl- 上面的例子中,dog 对象被定义为 Dog 类型。在编译期,编译器会检查 Dog 类中是否有可访问的 bark()方法,只要其中包含 bark()方法,那么就可以编译通过。在运行期,Hound 对象被 new 出来,并赋值给 dog 变量,这时,JVM 是明确的知道 dog 变量指向的其实是 Hound 对象的引用。所以,当 dog 调用 bark()方法的时候,就会调用 Hound 类中定义的 bark()方法。这就是所谓的动态多态性
- 重写的条件
- 参数列表必须完全与被重写方法的相同
- 返回类型必须完全与被重写方法的返回类型相同
- 访问级别的限制性一定不能比被重写方法的强
- 访问级别的限制性可以比被重写方法的弱
- 重写方法一定不能抛出新的检查异常或比被重写的方法声明的检查异常更广泛的检查异常
- 重写的方法能够抛出更少或更有限的异常(也就是说,被重写的方法声明了异常,但重写的方法可以什么也不声明)
- 不能重写被标示为 final 的方法
- 如果不能继承一个方法,则不能重写这个方法
- 重载的例子
class Dog{ public void bark(){ System.out.println("woof "); } //overloading method public void bark(int num){ for(int i=0; i<num; i++){ System.out.println("woof "); } } }- 上面的代码中,定义了两个 bark 方法,一个是没有参数的 bark 方法,另外一个是包含一个 int 类型参数的 bark 方法。在编译期,编译期可以根据方法签名(方法名和参数情况)情况确定哪个方法被调用
- 重载的条件
- 被重载的方法必须改变参数列表
- 被重载的方法可以改变返回类型
- 被重载的方法可以改变访问修饰符
- 被重载的方法可以声明新的或更广的检查异常
- 方法能够在同一个类中或者在一个子类中被重载
- 参考资料
- 定义
- Java 的继承与实现
- 封装和继承概述:
- 面向对象有三个特征:封装、继承、多态。其中继承和实现都体现了传递性
- 继承:如果多个类的某个部分的功能相同,那么可以抽象出一个类出来,把他们的相同部分都放到父类里,让他们都继承这个类
- 实现:如果多个类处理的目标是一样的,但是处理的方法方式不同,那么就定义一个接口,也就是一个标准,让他们的实现这个接口,各自实现自己具体的处理方法来处理那个目标
- 所以,继承的根本原因是因为要复用,而实现的根本原因是需要定义一个标准。在 Java 中,继承使用 extends 关键字实现,而实现通过 implements 关键字。Java 中支持一个类同时实现多个接口,但是不支持同时继承多个类。简单点说,就是同样是一台汽车,既可以是电动车,也可以是汽油车,也可以是油电混合的,只要实现不同的标准就行了,但是一台车只能属于一个品牌,一个厂商
class Car extends Benz implements GasolineCar, ElectroCar{ } - 在接口中只能定义全局常量(static final)和无实现的方法(Java 8 以后可以有 defult 方法);而在继承中可以定义属性方法,变量,常量等
- Java 的继承与组合
- 面向对象的复用技术
- 复用性是面向对象技术带来的很棒的潜在好处之一。Java 代码的复用有继承,组合以及代理三种具体的表现形式。本文将重点介绍继承复用和组合复用
- 继承
- 继承(Inheritance)是一种联结类与类的层次模型。指的是一个类(称为子类、子接口)继承另外的一个类(称为父类、父接口)的功能,并可以增加它自己的新功能的能力,继承是类与类或者接口与接口之间最常见的关系;继承是一种 is-a 关系

- 继承(Inheritance)是一种联结类与类的层次模型。指的是一个类(称为子类、子接口)继承另外的一个类(称为父类、父接口)的功能,并可以增加它自己的新功能的能力,继承是类与类或者接口与接口之间最常见的关系;继承是一种 is-a 关系
- 组合
- 组合(Composition)体现的是整体与部分、拥有的关系,即 has-a 的关系

- 组合(Composition)体现的是整体与部分、拥有的关系,即 has-a 的关系
- 组合与继承的区别和联系
- 在继承结构中,父类的内部细节对于子类是可见的。所以我们通常也可以说通过继承的代码复用是一种白盒式代码复用。(如果基类的实现发生改变,那么派生类的实现也将随之改变。这样就导致了子类行为的不可预知性。)
- 组合是通过对现有的对象进行拼装(组合)产生新的、更复杂的功能。因为在对象之间,各自的内部细节是不可见的,所以我们也说这种方式的代码复用是黑盒式代码复用。(因为组合中一般都定义一个类型,所以在编译期根本不知道具体会调用哪个实现类的方法)
- 继承,在写代码的时候就要指名具体继承哪个类,所以,在编译期就确定了关系。(从基类继承来的实现是无法在运行期动态改变的,因此降低了应用的灵活性。)
- 组合,在写代码的时候可以采用面向接口编程。所以,类的组合关系一般在运行期确定
- 组合和继承的优缺点对比
组合关系 继承关系 优点:不破坏封装,整体类与局部类之间松耦合,彼此相对独立 缺点:破坏封装,子类与父类之间紧密耦合,子类依赖于父类的实现,子类缺乏独立性 优点:具有较好的可扩展性 缺点:支持扩展,但是往往以增加系统结构的复杂度为代价 优点:支持动态组合。在运行时,整体对象可以选择不同类型的局部对象 缺点:不支持动态继承。在运行时,子类无法选择不同的父类 优点:整体类可以对局部类进行包装,封装局部类的接口,提供新的接口 缺点:子类不能改变父类的接口 缺点:整体类不能自动获得和局部类同样的接口 优点:子类能自动继承父类的接口 缺点:创建整体类的对象时,需要创建所有局部类的对象 优点:创建子类的对象时,无须创建父类的对象 - 如何选择
- 相信很多人都知道面向对象中有一个比较重要的原则『多用组合、少用继承』或者说『组合优于继承』。从前面的介绍已经优缺点对比中也可以看出,组合确实比继承更加灵活,也更有助于代码维护
- 所以,建议在同样可行的情况下,优先使用组合而不是继承。因为组合更安全,更简单,更灵活,更高效
- 注意,并不是说继承就一点用都没有了,前面说的是【在同样可行的情况下】。有一些场景还是需要使用继承的,或者是更适合使用继承。继承要慎用,其使用场合仅限于你确信使用该技术有效的情况。一个判断方法是,问一问自己是否需要从新类向基类进行向上转型。如果是必须的,则继承是必要的。反之则应该好好考虑是否需要继承。只有当子类真正是超类的子类型时,才适合用继承。换句话说,对于两个类 A 和 B,只有当两者之间确实存在 is-a 关系的时候,类 B 才应该继承类 A
- 面向对象的复用技术
- 封装和继承概述:
- 构造函数与默认构造函数
- 构造函数,是一种特殊的方法。主要用来在创建对象时初始化对象,即为对象成员变量赋初始值,总与 new 运算符一起使用在创建对象的语句中。特别的一个类可以有多个构造函数,可根据其参数个数的不同或参数类型的不同来区分它们即构造函数的重载
- 构造函数跟一般的实例方法十分相似;但是与其它方法不同,构造器没有返回类型,不会被继承,且可以有范围修饰符。构造器的函数名称必须和它所属的类的名称相同。它承担着初始化对象数据成员的任务
- 如果在编写一个可实例化的类时没有专门编写构造函数,多数编程语言会自动生成缺省构造器(默认构造函数)。默认构造函数一般会把成员变量的值初始化为默认值,如 int -> 0,Integer -> null
- 类变量、成员变量和局部变量
- Java 中共有三种变量,分别是类变量、成员变量和局部变量。他们分别存放在 JVM 的方法区、堆内存和栈内存中
/** * @author Hollis */ public class Variables { /** * 类变量 */ private static int a; /** * 成员变量 */ private int b; /** * 局部变量 */ public void test(int c){ int d; } }
- Java 中共有三种变量,分别是类变量、成员变量和局部变量。他们分别存放在 JVM 的方法区、堆内存和栈内存中
- 成员变量和方法作用域
- 对于成员变量和方法的作用域,public,protected,private 以及不写之间的区别:
- public:表明该成员变量或者方法是对所有类或者对象都是可见的,所有类或者对象都可以直接访问
- private:表明该成员变量或者方法是私有的,只有当前类对其具有访问权限,除此之外,其他类或者对象都没有访问权限,子类也没有访问权限
- protected: 表明成员变量或者方法对类自身,与同在一个包中的其他类可见,其他包下的类不可访问,除非是他的子类
- default:表明该成员变量或者方法只有自己和其位于同一个包的内可见,其他包内的类不能访问,即便是它的子类
- 对于成员变量和方法的作用域,public,protected,private 以及不写之间的区别:
- 多态
-
什么是平台无关性
- Java 如何实现的平台无关性的
- 什么是平台无关性
- 平台无关性就是一种语言在计算机上的运行不受平台的约束,一次编译,到处执行(Write Once ,Run Anywhere)。也就是说,用 Java 创建的可执行二进制程序,能够不加改变的运行于多个平台
- 平台无关性好处
- 作为一门平台无关性语言,无论是在自身发展,还是对开发者的友好度上都是很突出的。因为其平台无关性,所以 Java 程序可以运行在各种各样的设备上,尤其是一些嵌入式设备,如打印机、扫描仪、传真机等。随着 5G 时代的来临,也会有更多的终端接入网络,相信平台无关性的 Java 也能做出一些贡献。对于 Java 开发者来说,Java 减少了开发和部署到多个平台的成本和时间。真正的做到一次编译,到处运行
- 平台无关性的实现
- 对于 Java 的平台无关性的支持,就像对安全性和网络移动性的支持一样,是分布在整个 Java 体系结构中的。其中扮演者重要的角色的有 Java 语言规范、Class 文件、Java 虚拟机(JVM)等
- 编译原理基础
- 讲到 Java 语言规范、Class 文件、Java 虚拟机就不得不提 Java 到底是是如何运行起来的
- 我们在 Java 代码的编译与反编译那些事儿中介绍过,在计算机世界中,计算机只认识 0 和 1,所以,真正被计算机执行的其实是由 0 和 1 组成的二进制文件
- 但是,我们日常开发使用的 C、C++、Java、Python 等都属于高级语言,而非二进制语言。所以,想要让计算机认识我们写出来的 Java 代码,那就需要把他"翻译"成由 0 和1 组成的二进制文件。这个过程就叫做编译。负责这一过程的处理的工具叫做编译器
- 在 深入分析 Java 的编译原理中我们介绍过,在 Java 平台中,想要把 Java 文件,编译成二进制文件,需要经过两步编译,前端编译和后端编译:

- 前端编译主要指与源语言有关但与目标机无关的部分。Java 中,我们所熟知的 javac 的编译就是前端编译。除了这种以外,我们使用的很多 IDE,如 eclipse,idea 等,都内置了前端编译器。主要功能就是把.java 代码转换成.class 代码。这里提到的.class 代码,其实就是 Class 文件
- 后端编译主要是将中间代码再翻译成机器语言。Java 中,这一步骤就是 Java 虚拟机来执行的

- 所以,我们说的,Java 的平台无关性实现主要作用于以上阶段。如下图所示:

- 我们从后往前介绍一下这三位主演:Java 虚拟机、Class 文件、Java 语言规范
- Java 虚拟机
- 所谓平台无关性,就是说要能够做到可以在多个平台上都能无缝对接。但是,对于不同的平台,硬件和操作系统肯定都是不一样的。对于不同的硬件和操作系统,最主要的区别就是指令不同。比如同样执行 a+b,A 操作系统对应的二进制指令可能是 10001000,而 B 操作系统对应的指令可能是 11101110。那么,想要做到跨平台,最重要的就是可以根据对应的硬件和操作系统生成对应的二进制指令。而这一工作,主要由我们的 Java 虚拟机完成。虽然 Java 语言是平台无关的,但 JVM 却是平台有关的,不同的操作系统上面要安装对应的 JVM ,有了 Java 虚拟机,想要执行 a+b 操作,A 操作系统上面的虚拟机就会把指令翻译成 10001000,B 操作系统上面的虚拟机就会把指令翻译成 11101110,所以,Java 之所以可以做到跨平台,是因为 Java 虚拟机充当了桥梁。他扮演了运行时 Java 程序与其下的硬件和操作系统之间的缓冲角色

- 所谓平台无关性,就是说要能够做到可以在多个平台上都能无缝对接。但是,对于不同的平台,硬件和操作系统肯定都是不一样的。对于不同的硬件和操作系统,最主要的区别就是指令不同。比如同样执行 a+b,A 操作系统对应的二进制指令可能是 10001000,而 B 操作系统对应的指令可能是 11101110。那么,想要做到跨平台,最重要的就是可以根据对应的硬件和操作系统生成对应的二进制指令。而这一工作,主要由我们的 Java 虚拟机完成。虽然 Java 语言是平台无关的,但 JVM 却是平台有关的,不同的操作系统上面要安装对应的 JVM ,有了 Java 虚拟机,想要执行 a+b 操作,A 操作系统上面的虚拟机就会把指令翻译成 10001000,B 操作系统上面的虚拟机就会把指令翻译成 11101110,所以,Java 之所以可以做到跨平台,是因为 Java 虚拟机充当了桥梁。他扮演了运行时 Java 程序与其下的硬件和操作系统之间的缓冲角色
- 字节码
- 各种不同的平台的虚拟机都使用统一的程序存储格式——字节码(ByteCode)是构成平台无关性的另一个基石。Java 虚拟机只与由字节码组成的 Class 文件进行交互。我们说 Java 语言可以 Write Once ,Run Anywhere。这里的 Write 其实指的就是生成 Class 文件的过程。因为 Java Class 文件可以在任何平台创建,也可以被任何平台的 Java 虚拟机装载并执行,所以才有了 Java 的平台无关性
- Java 语言规范
- 已经有了统一的 Class 文件,以及可以在不同平台上将 Class 文件翻译成对应的二进制文件的 Java 虚拟机,Java 就可以彻底实现跨平台了吗?其实并不是的,Java 语言在跨平台方面也是做了一些努力的,这些努力被定义 Java 语言规范中。比如,Java 中基本数据类型的值域和行为都是由其自己定义的。而 C/C++ 中,基本数据类型是由它的占位宽度决定的,占位宽度则是由所在平台决定的。所以,在不同的平台中,对于同一个 C++ 程序的编译结果会出现不同的行为。举一个简单的例子,对于 int 类型,在 Java 中,int 占 4 个字节,这是固定的。但是在 C++ 中却不是固定的了。在 16 位计算机上,int 类型的长度可能为两字节;在 32 位计算机上,可能为 4 字节;当 64 位计算机流行起来后,int 类型的长度可能会达到 8字节。(这里说的都是可能哦!)通过保证基本数据类型在所有平台的一致性,Java 语言为平台无关性提供强了有力的支持
- 小结
- 对于 Java 的平台无关性的支持是分布在整个 Java 体系结构中的。其中扮演着重要角色的有 Java 语言规范、Class 文件、Java 虚拟机等
- Java 语言规范:通过规定 Java 语言中基本数据类型的取值范围和行为
- Class 文件:所有 Java 文件要编译成统一的 Class 文件
- Java 虚拟机:通过 Java 虚拟机将 Class 文件转成对应平台的二进制文件等
- Java 的平台无关性是建立在 Java 虚拟机的平台有关性基础之上的,是因为 Java 虚拟机屏蔽了底层操作系统和硬件的差异
- 对于 Java 的平台无关性的支持是分布在整个 Java 体系结构中的。其中扮演着重要角色的有 Java 语言规范、Class 文件、Java 虚拟机等
- 语言无关性
- 其实,Java 的无关性不仅仅体现在平台无关性上面,向外扩展一下,Java 还具有语言无关性。前面我们提到过。JVM 其实并不是和 Java 文件进行交互的,而是和 Class 文件,也就是说,其实 JVM 运行的时候,并不依赖于 Java 语言。时至今日,商业机构和开源机构已经在 Java 语言之外发展出一大批可以在 JVM 上运行的语言了,如 Groovy、Scala、Jython 等。之所以可以支持,就是因为这些语言也可以被编译成字节码(Class 文件)。而虚拟机并不关心字节码是有哪种语言编译而来的。详见牛逼了,教你用九种语言在 JVM 上输出 HelloWorld
- 什么是平台无关性
- JVM 还支持哪些语言
- 目前 Java 虚拟机已经可以支持很多除 Java 语言以外的语言了,如 Kotlin、Groovy、JRuby、Jython、Scala 等。之所以可以支持,就是因为这些语言也可以被编译成字节码。而虚拟机并不关心字节码是有哪种语言编译而来的
- Kotlin
- Kotlin 是一种在 Java 虚拟机上运行的静态类型编程语言,它也可以被编译成为 Java Script 源代码。Kotlin 的设计初衷就是用来生产高性能要求的程序的,所以运行起来和Java 也是不相上下。Kotlin 可以从 JetBrains InteilliJ Idea IDE 这个开发工具以插件形式使用
- Groovy
- Apache 的 Groovy 是 Java 平台上设计的面向对象编程语言。它的语法风格与 Java 很像,Java 程序员能够很快的熟练使用 Groovy,实际上,Groovy 编译器是可以接受完全纯粹的 Java 语法格式的。使用 Groovy 的一个重要特点就是使用类型推断,即能够让编译器能够在程序员没有明确说明的时候推断出变量的类型。Groovy 可以使用其他 Java 语言编写的库。Groovy 的语法与 Java 非常相似,大多数 Java 代码也匹配 Groovy 的语法规则,尽管可能语义不同
- Scala
- Scala 是一门多范式的编程语言,设计初衷是要集成面向对象编程和函数式编程的各种特性。Scala 经常被我们描述为多模式的编程语言,因为它混合了来自很多编程语言的元素的特征。但无论如何它本质上还是一个纯粹的面向对象语言。它相比传统编 程语言最大的优势就是提供了很好并行编程基础框架措施了。Scala 代码能很好的被优化成字节码,运行起来和原生 Java 一样快
- Jruby
- JRuby 是用来桥接 Java 与 Ruby 的,它是使用比 Groovy 更加简短的语法来编写代码,能够让每行代码执行更多的任务。就和 Ruby 一样,JRuby 不仅仅只提供了高级的语法格式。它同样提供了纯粹的面向对象的实现,闭包等等,而且 JRuby 跟 Ruby 自身相比多了很多基于 Java 类库 可以调用,虽然 Ruby 也有很多类库,但是在数量以及广泛性上是无法跟 Java 标准类库相比的
- Jython
- Jython,是一个用 Java 语言写的 Python 解释器。Jython 能够用 Python 语言来高效生成动态编译的 Java 字节码
- Fantom
- Fantom 是一种通用的面向对象编程语言,由 Brian 和 Andy Frank 创建,运行在 Java Runtime Environment,JavaScript 和.NET Common Language Runtime 上。其主要设计目标是提供标准库 API,以抽象出代码是否最终将在 JRE 或 CLR 上运行的问题。Fantom 是与 Groovy 以及 JRuby 差不多的一样面向对象的编程语言,但是悲剧的是 Fantom 无法使用 Java 类库,而是使用它自己扩展的类库
- Clojure
- Clojure 是 Lisp 编程语言在 Java 平台上的现代、函数式及动态方言。 与其他 Lisp 一样,Clojure 视代码为数据且拥有一套 Lisp 宏系统。虽然 Clojure 也能被直接编译成 Java 字节码,但是无法使用动态语言特性以及直接调用 Java 类库。与其他的 JVM 脚本语言不一样,Clojure 并不算是面向对象的
- Rhino
- Rhino 是一个完全以 Java 编写的 JavaScript 引擎,目前由 Mozilla 基金会所管理。Rhino 的特点是为 JavaScript 加了个壳,然后嵌入到 Java 中,这样能够让 Java 程序员直接使用。其中 Rhino 的 JavaAdapters 能够让 JavaScript 通过调用 Java 的类来实现特定的功能
- Ceylon
- Ceylon 是一种面向对象,强烈静态类型的编程语言,强调不变性,由 Red Hat 创建。Ceylon 程序在 Java 虚拟机上运行, 可以编译为 JavaScript。 语言设计侧重于源代码可读性,可预测性,可扩展性,模块性和元编程性
- 总结
- 以上就是目前主流的可以在 JVM 上面运行的 9 种语言。加上 Java 正好 10 种。如果你是一个 Java 开发,那么有必要掌握以上 9 中的一种,这样可以在一些有特殊需求的场景中有更多的选择。推荐在 Groovy、Scala、Kotlin 中选一个
- Kotlin
- 目前 Java 虚拟机已经可以支持很多除 Java 语言以外的语言了,如 Kotlin、Groovy、JRuby、Jython、Scala 等。之所以可以支持,就是因为这些语言也可以被编译成字节码。而虚拟机并不关心字节码是有哪种语言编译而来的
- Java 如何实现的平台无关性的
-
Java 中的值传递
- 值传递、引用传递
- 实参与形参
- 我们都知道,在 Java 中定义方法的时候是可以定义参数的。比如 Java 中的 main 方法,args 就是参数
- 参数在程序语言中分为形式参数和实际参数
- 形式参数:是在定义函数名和函数体的时候使用的参数,目的是用来接收调用该函数时传入的参数
- 实际参数:在调用有参函数时,主调函数和被调函数之间有数据传递关。在主调函数中调用一个函数时,函数名后面括号中的参数称为“实际参数”
- 简单举个例子:
public static void main(String[] args) { ParamTest pt = new ParamTest(); pt.sout("Hollis");//实际参数为 Hollis } public void sout(String name) { //形式参数为 name System.out.println(name); } - 实际参数是调用有参方法的时候真正传递的内容,而形式参数是用于接收实参内容的参数
- 值传递与引用传递
- 定义
- 值传递(pass by value)是指在调用函数时将实际参数复制一份传递到函数中,这样在函数中如果对参数进行修改,将不会影响到实际参数
- 引用传递(pass by reference)是指在调用函数时将实际参数的地址直接传递到函数中,那么在函数中对参数所进行的修改,将影响到实际参数
- 区别
- 根本区别:值传递会创建副本(Copy),引用传递不会创建副本
- 结果:值传递-函数中无法改变原始对象,引用传递-函数中可以改变原始对象
- 定义
- 实参与形参
- 为什么说 Java 中只有值传递
- 错误理解
- 错误理解一:值传递和引用传递,区分的条件是传递的内容,如果是个值,就是值传递;如果是个引用,就是引用传递
- 错误理解二:Java 是引用传递
- 错误理解三:传递的参数如果是普通类型,那就是值传递,如果是对象,那就是引用传递
- 实参与形参
- 我们都知道,在 Java 中定义方法的时候是可以定义参数的。比如 Java 中的 main 方法,public static void main(String[] args),这里面的 args 就是参数。参数在程序语言中分为形式参数和实际参数
- 形式参数:是在定义函数名和函数体的时候使用的参数,目的是用来接收调用该函数时传入的参数
- 实际参数:在调用有参函数时,主调函数和被调函数之间有数据传递关系。在主调函数中调用一个函数时,函数名后面括号中的参数称为“实际参数”
- 简单举个例子
public static void main(String[] args){ ParamTest pt = new ParamTest(); // 实际参数为 Hollis pt.sout("Hollis"); } public void sout(String name) { // 形式参数为 name System.out.println(name); } - 实际参数是调用有参方法的时候真正传递的内容,而形式参数是用于接收实参内容的参数
- 我们都知道,在 Java 中定义方法的时候是可以定义参数的。比如 Java 中的 main 方法,public static void main(String[] args),这里面的 args 就是参数。参数在程序语言中分为形式参数和实际参数
- 求值策略
- 我们说当进行方法调用的时候,需要把实际参数传递给形式参数,那么传递的过程中到底传递的是什么东西呢?
- 这其实是程序设计中求值策略(Evaluation strategies)的概念
- 在计算机科学中,求值策略是确定编程语言中表达式的求值的一组(通常确定性的)规则。求值策略定义何时和以何种顺序求值给函数的实际参数、什么时候把它们代换入函数、和代换以何种形式发生
- 求值策略分为两大基本类,基于如何处理给函数的实际参数,分为严格的和非严格的
- 严格求值
- 在“严格求值”中,函数调用过程中,给函数的实际参数总是在应用这个函数之前求值。多数现存编程语言对函数都使用严格求值。所以,我们本文只关注严格求值
- 在严格求值中有几个关键的求值策略是我们比较关心的,那就是传值调用(Call by value)、传引用调用(Call by reference)以及传共享对象调用(Call by sharing)
- 传值调用(值传递):在传值调用中,实际参数先被求值,然后其值通过复制,被传递给被调函数的形式参数。因为形式参数拿到的只是一个"局部拷贝",所以如果在被调函数中改变了形式参数的值,并不会改变实际参数的值
- 传引用调用(引用传递):在传引用调用中,传递给函数的是它的实际参数的隐式引用而不是实参的拷贝。因为传递的是引用,所以,如果在被调函数中改变了形式参数的值,改变对于调用者来说是可见的
- 传共享对象调用(共享对象传递):传共享对象调用中,先获取到实际参数的地址,然后将其复制,并把该地址的拷贝传递给被调函数的形式参数。因为参数的地址都指向同一个对象,所以我们也称之为" 传共享对象",所以,如果在被调函数中改变了形式参数的值,调用者是可以看到这种变化的
- 不知道大家有没有发现,其实传共享对象调用和传值调用的过程几乎是一样的,都是进行"求值"、“拷贝”、“传递”。但是,传共享对象调用和内传引用调用的结果又是一样的,都是在被调函数中如果改变参数的内容,那么这种改变也会对调用者有影响。那么,共享对象传递和值传递以及引用传递之间到底有什么关系呢?对于这个问题,我们应该关注过程,而不是结果,因为传共享对象调用的过程和传值调用的过程是一样的,而且都有一步关键的操作,那就是"复制",所以,通常我们认为传共享对象调用是传值调用的特例,我们先把传共享对象调用放在一边,我们再来回顾下传值调用和传引用调用的主要区别:传值调用是指在调用函数时将实际参数复制一份传递到函数中,传引用调用是指在调用函数时将实际参数的引用直接传递到函数中。所以,两者的最主要区别就是是直接传递的,还是传递的是一个副本
- Java 的求值策略
public static void main(String[] args) { Test pt = new Test(); User hollis = new User(); hollis.setName("Hollis"); hollis.setGender("Male"); pt.pass(hollis); System.out.println("print in main , user is " + hollis); } public void pass(User user) { user.setName("hollischuang"); System.out.println("print in pass , user is " + user); } // 输出 // print in pass , user is User{name='hollischuang', gender='Male'} // print in main , user is User{name='hollischuang', gender='Male'} - Java 中的对象传递
- 共享对象传递
- 其实在 《The Java™ Tutorials》中,是有关于这部分内容的说明的。首先是关于基本类型描述如下
- 关于基本类型描述:原始参数通过值传递给方法。这意味着对参数值的任何更改都只存在于方法的范围内。当方法返回时,参数将消失,对它们的任何更改都将丢失
- 关于引用类型描述:引用数据类型参数(如对象)也按值传递给方法。这意味着,当方法返回时,传入的引用仍然引用与以前相同的对象。但是,如果对象字段具有适当的访问级别,则可以在方法中更改这些字段的值
- 其实 Java 中使用的求值策略就是传共享对象调用,也就是说,Java 会将对象的地址的拷贝传递给被调函数的形式参数。只不过"传共享对象调用"这个词并不常用,所以 Java 社区的人通常说"Java 是传值调用",这么说也没错,因为传共享对象调用其实是传值调用的一个特例
- 值传递和共享对象传递的现象冲突吗?

- 在参数传递的过程中,实际参数的地址 0X1213456 被拷贝给了形参。这个过程其实就是值传递,只不过传递的值得内容是对象的应用
- 那为什么我们改了 user 中的属性的值,却对原来的 user 产生了影响呢?其实,这个过程就好像是:你复制了一把你家里的钥匙给到你的朋友,他拿到钥匙以后,并没有在这把钥匙上做任何改动,而是通过钥匙打开了你家里的房门,进到屋里,把你家的电视给砸了。这个过程,对你手里的钥匙来说,是没有影响的,但是你的钥匙对应的房子里面的内容却是被人改动了。也就是说,Java 对象的传递,是通过复制的方式把引用关系传递了,如果我们没有改引用关系,而是找到引用的地址,把里面的内容改了,是会对调用方有影响的,因为大家指向的是同一个共享对象
- 修改下上边的例子
public void pass(User user) { user = new User(); user.setName("hollischuang"); System.out.println("print in pass , user is " + user); } // 输出 // print in pass , user is User{name='hollischuang', gender='Male'} // print in main , user is User{name='Hollis', gender='Male'}
- 这个过程,就好像你复制了一把钥匙给到你的朋友,你的朋友拿到你给他的钥匙之后,找个锁匠把他修改了一下,他手里的那把钥匙变成了开他家锁的钥匙。这时候,他打开自己家,就算是把房子点了,对你手里的钥匙,和你家的房子来说都是没有任何影响的。所以,Java 中的对象传递,如果是修改引用,是不会对原来的对象有任何影响的,但是如果直接修改共享对象的属性的值,是会对原来的对象有影响的
- 错误理解
- 总结
- 编程语言中需要进行方法间的参数传递,这个传递的策略叫做求值策略
- 在程序设计中,求值策略有很多种,比较常见的就是值传递和引用传递。还有一种值传递的特例——共享对象传递
- 值传递和引用传递最大的区别是传递的过程中有没有复制出一个副本来,如果是传递副本,那就是值传递,否则就是引用传递
- 在 Java 中,其实是通过值传递实现的参数传递,只不过对于 Java 对象的传递,传递的内容是对象的引用。我们可以总结说,Java 中的求值策略是共享对象传递
- 我们说 Java 中只有值传递,只不过传递的内容是对象的引用。这也是没毛病的。但是,绝对不能认为 Java 中有引用传递
- 值传递、引用传递
java语言基础
-
基本数据类型
- 八种基本数据类型
- 字符型:char
- 布尔型:boolean
- 数值型:整型(byte,short,int,long),浮点型(float,double)
- 注意:String 不是基本数据类型,是引用类型
- 整型中 byte、short、int、long 的取值范围
-
科普
- 1 字节=8 位(bit)
- java 中的整型属于有符号数
- Java中,为什么byte类型的取值范围为-128~127?
整型 字节 范围 默认值 byte 1个字节 -128(-2^7) 到 127(2^7-1) 0 short 2个字节 -32,768 (-2^15) 到 32,767 (2^15-1) 0 int 4个字节 -2,147,483,648 (-2^31) 到 2,147,483,647 (2^31-1) 0 long 8个字节 -9,223,372,036,854,775,808 (-2^63) 到 9,223,372,036, 854,775,807 (2^63-1) 0L,0l,0 -
整型中,每个类型都有一定的表示范围,但是,在程序中有些计算会导致超出表示范围,即溢出。计算时候一定要注意这点
-
- 什么是浮点型?
- 在计算机科学中,浮点是一种对于实数的近似值数值表现法,由一个有效数字(即尾数)加上幂数来表示,通常是乘以某个基数的整数次指数得到。以这种表示法表示的数值,称为浮点数(floating-point number)
- 一个浮点数 a 由两个数 m 和 e 来表示:a = m × be。在任意一个这样的系统中,我们选择一个基数 b(记数系统的基)和精度 p(即使用多少位来存储)。m(即尾数)是形如±d.ddd…ddd 的 p 位数(每一位是一个介于 0 到 b-1 之间的整数,包括 0 和 b-1)。如果 m 的第一位是非 0 整数,m 称作正规化的。有一些描述使用一个单独的符号位(s 代表+或者-)来表示正负,这样 m 必须是正的。e 是指数。位(bit)是衡量浮点数所需存储空间的单位,通常为 32 位或 64 位,分别被叫作单精度和双精度
- 什么是单精度和双精度?
- 单精度浮点数在计算机存储器中占用 4 个字节(32 bits),利用“浮点”(浮动小数点)的方法,可以表示一个范围很大的数值
- 双精度浮点数(double)使用 64 位(8 字节) 来存储一个浮点数
- 为什么不能用浮点型表示金额?
- 由于计算机中保存的小数其实是十进制的小数的近似值,并不是准确值,所以,千万不要在代码中使用浮点数来表示金额等重要的指标
- 建议使用 BigDecimal 或者 Long(单位为分)来表示金额
- 八种基本数据类型
-
Java中的关键字
- transient
- 在关于 java 的集合类的学习中,我们发现 ArrayList 类和 Vector 类都是使用数组实现的,但是在定义数组 elementData 这个属性时稍有不同,那就是 ArrayList 使用 transient 关键字
private transient Object[] elementData; protected Object[] elementData; - Java 语言的关键字,变量修饰符,如果用 transient 声明一个实例变量,当对象存储时,它的值不需要维持。这里的对象存储是指,Java 的 serialization 提供的一种持久化对象实例的机制。当一个对象被序列化的时候,transient 型变量的值不包括在序列化的表示中,然而非 transient 型的变量是被包括进去的
- 使用情况是:当持久化对象时,可能有一个特殊的对象数据成员,我们不想用 serialization 机制来保存它。为了在一个特定对象的一个域上关闭 serialization,可以在这个域前加上关键字 transient。简单点说,就是被 transient 修饰的成员变量,在序列化的时候其值会被忽略,在被反序列化后, transient 变量的值被设为初始值, 如 int 型的是 0,对象型的是 null
- 在关于 java 的集合类的学习中,我们发现 ArrayList 类和 Vector 类都是使用数组实现的,但是在定义数组 elementData 这个属性时稍有不同,那就是 ArrayList 使用 transient 关键字
- instanceof
- instanceof 是 Java 的一个二元操作符,类似于 ==,>,< 等操作符。instanceof 是 Java 的保留关键字。它的作用是测试它左边的对象是否是它右边的类的实例,返回 boolean 的数据类型
- 以下实例创建 displayObjectClass() 方法来演示 Java instanceof 关键字用法:
public static void displayObjectClass(Object o){ if (o instanceof Vector) System.out.println("对象是 java.util.Vector 类的实例"); else if (o instanceof ArrayList) System.out.println("对象是 java.util.ArrayList 类的实例"); Else System.out.println("对象是 " + o.getClass() + " 类的实例"); }
- volatile(注释:个人建议-关于volatile和synchronize两个关键字,建议去看《java并发编程的艺术》那本书)
- 介绍
- 再有人问你Java内存模型是什么,就把这篇文章发给他。
- JVM内存结构 VS Java内存模型 VS Java对象模型
- Java 语言为了解决并发编程中存在的原子性、可见性和有序性问题,提供了一系列和并发处理相关的关键字,比如 synchronized、volatile、final、concurren 包等
- volatile 这个关键字,不仅仅在 Java 语言中有,在很多语言中都有的,而且其用法和语义也都是不尽相同的。尤其在 C 语言、C++以及 Java 中,都有 volatile 关键字。都可以用来声明变量或者对象
- volatile 的用法
- volatile 通常被比喻成"轻量级的 synchronized",也是 Java 并发编程中比较重要的一个关键字。和 synchronized 不同,volatile 是一个变量修饰符,只能用来修饰变量。无法修饰方法及代码块等
- volatile 的用法比较简单,只需要在声明一个可能被多线程同时访问的变量时,使用volatile 修饰就可以了
public class Singleton{ private volatile static Singleton singleton; private Singleton (){} public static Singleton getSingleton() { if (singleton == null) { synchronized (Singleton.class) { if (singleton == null) { singleton = new Singleton(); } } } return singleton; } }
- volatile 的原理
- 对于 volatile 变量,当对 volatile 变量进行写操作的时候,JVM 会向处理器发送一条 lock 前缀的指令,将这个缓存中的变量回写到系统主存中。但是就算写回到内存,如果其他处理器缓存的值还是旧的,再执行计算操作就会有问题,所以在多处理器下,为了保证各个处理器的缓存是一致的,就会实现缓存一致性协议
- 缓存一致性协议:每个处理器通过嗅探在总线上传播的数据来检查自己缓存的值是不是过期了,当处理器发现自己缓存行对应的内存地址被修改,就会将当前处理器的缓存行设置成无效状态,当处理器要对这个数据进行修改操作的时候,会强制重新从系统内存里把数据读到处理器缓存里
- 所以,如果一个变量被 volatile 所修饰的话,在每次数据变化之后,其值都会被强制刷入主存。而其他处理器的缓存由于遵守了缓存一致性协议,也会把这个变量的值从主存加载到自己的缓存中。这就保证了一个 volatile 在并发编程中,其值在多个缓存中是可见的
- volatile 与可见性
- 可见性是指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值
- Java 内存模型规定了所有的变量都存储在主内存中,每条线程还有自己的工作内存,线程的工作内存中保存了该线程中是用到的变量的主内存副本拷贝,线程对变量的所有操作都必须在工作内存中进行,而不能直接读写主内存。不同的线程之间也无法直接访问对方工作内存中的变量,线程间变量的传递均需要自己的工作内存和主存之间进行数据同步进行。所以,就可能出现线程 1 改了某个变量的值,但是线程 2 不可见的情况。
- 前面的关于 volatile 的原理中介绍过了,Java 中的 volatile 关键字提供了一个功能,那就是被其修饰的变量在被修改后可以立即同步到主内存,被其修饰的变量在每次是用之前都从主内存刷新。因此,可以使用 volatile 来保证多线程操作时变量的可见性
- volatile 与有序性
- 除了引入了时间片以外,由于处理器优化和指令重排等,CPU 还可能对输入代码进行乱序执行,比如 load->add->save 有可能被优化成 load->save->add 。这就是可能存在有序性问题
- 而 volatile 除了可以保证数据的可见性之外,还有一个强大的功能,那就是他可以禁止指令重排优化等。普通的变量仅仅会保证在该方法的执行过程中所依赖的赋值结果的地方都能获得正确的结果,而不能保证变量的赋值操作的顺序与程序代码中的执行顺序一致
- volatile 可以禁止指令重排,这就保证了代码的程序会严格按照代码的先后顺序执行。这就保证了有序性。被 volati le 修饰的变量的操作,会严格按照代码顺序执行,load->add->save 的执行顺序就是:load、add、save
- volatile 与原子性
- 原子性是指一个操作是不可中断的,要全部执行完成,要不就都不执行
- 线程是 CPU 调度的基本单位。CPU 有时间片的概念,会根据不同的调度算法进行线程调度。当一个线程获得时间片之后开始执行,在时间片耗尽之后,就会失去 CPU 使用权。所以在多线程场景下,由于时间片在线程间轮换,就会发生原子性问题
- synchronized 为了保证原子性,需要通过字节码指令 monitorenter 和 monitorexit,但是 volatile 和这两个指令之间是没有任何关系的,所以,volatile 是不能保证原子性的
- 在以下两个场景中可以使用 volatile 来代替 synchronized:
- 运算结果并不依赖变量的当前值,或者能够确保只有单一的线程会修改变量的值
- 变量不需要与其他状态变量共同参与不变约束
- 介绍
- synchronized
- 介绍
- synchronized 关键字在需要原子性、可见性和有序性这三种特性的时候都可以作为其中一种解决方案
- synchronized 的用法
- 主要有两种用法,分别是同步方法和同步代码块。也就是说,synchronized 既可以修饰方法也可以修饰代码块。被 synchronized 修饰的代码块及方法,在同一时间,只能被单个线程访问
/ ** * @author Hollis 18/08/04. */ public class SynchronizedDemo { //同步方法 public synchronized void doSth(){ System.out.println("Hello World"); } //同步代码块 public void doSth1(){ synchronized (SynchronizedDemo.class){ System.out.println("Hello World"); } } } - synchronized 的实现原理
- 原理
- 对于同步方法,JVM 采用 ACC_SYNCHRONIZED 标记符来实现同步
- 对于同步代码块。JVM 采用 monitorenter、monitorexit 两个指令来实现同步
- 介绍
- 方法级的同步是隐式的
- 同步方法的常量池中会有一个 ACC_SYNCHRONIZED 标志。当某个线程要访问某个方法的时候,会检查是否有 ACC_SYNCHRONIZED,如果有设置,则需要先获得监视器锁,然后开始执行方法,方法执行之后再释放监视器锁。这时如果其他线程来请求执行方法,会因为无法获得监视器锁而被阻断住。值得注意的是,如果在方法执行过程中,发生了异常,并且方法内部并没有处理该异常,那么在异常被抛到方法外面之前监视器锁会被自动释放
- 同步代码块使用 monitorenter 和 monitorexit 两个指令实现。可以把执行monitorenter 指令理解为加锁,执行 monitorexit 理解为释放锁。 每个对象维护着一个记录着被锁次数的计数器。未被锁定的对象的该计数器为 0,当一个线程获得锁(执行monitorenter)后,该计数器自增变为 1 ,当同一个线程再次获得该对象的锁的时候,计数器再次自增。当同一个线程释放锁(执行 monitorexit 指令)的时候,计数器再自减。当计数器为 0 的时候。锁将被释放,其他线程便可以获得锁
- 无论是 ACC_SYNCHRONIZED 还是 monitorenter、monitorexit 都是基于 Monitor 实现的,在 Java 虚拟机(HotSpot)中,Monitor 是基于 C++ 实现的,由 ObjectMonitor 实现。ObjectMonitor 类中提供了几个方法,如 enter、exit、wait、notify、notifyAll 等。sychronized 加锁的时候,会调用 objectMonitor 的 enter 方法,解锁的时候会调用 exit方法
- 原理
- synchronized 与原子性
- 原子性是指一个操作是不可中断的,要全部执行完成,要不就都不执行
- 线程是 CPU 调度的基本单位。CPU 有时间片的概念,会根据不同的调度算法进行线程调度。当一个线程获得时间片之后开始执行,在时间片耗尽之后,就会失去 CPU 使用权。所以在多线程场景下,由于时间片在线程间轮换,就会发生原子性问题。在 Java 中,为了保证原子性,提供了两个高级的字节码指令 monitorenter 和 monitorexit。前面中,介绍过,这两个字节码指令,在 Java 中对应的关键字就是 synchronized
- 通过 monitorenter 和 monitorexit 指令,可以保证被 synchronized 修饰的代码在同一时间只能被一个线程访问,在锁未释放之前,无法被其他线程访问到。因此,在 Java 中可以使用 synchronized 来保证方法和代码块内的操作是原子性的。线程 1 在执行 monitorenter 指令的时候,会对 Monitor 进行加锁,加锁后其他线程无法获得锁,除非线程 1 主动解锁。即使在执行过程中,由于某种原因,比如 CPU 时间片用完,线程 1 放弃了 CPU,但是,他并没有进行解锁。而由于 synchronized 的锁是可重入的,下一个时间片还是只能被他自己获取到,还是会继续执行代码。直到所有代码执行完。这就保证了原子性
- synchronized 与可见性
- 可见性是指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值
- Java 内存模型规定了所有的变量都存储在主内存中,每条线程还有自己的工作内存,线程的工作内存中保存了该线程中是用到的变量的主内存副本拷贝,线程对变量的所有操作都必须在工作内存中进行,而不能直接读写主内存。不同的线程之间也无法直接访问对方工作内存中的变量,线程间变量的传递均需要自己的工作内存和主存之间进行数据同步进行。所以,就可能出现线程 1 改了某个变量的值,但是线程 2 不可见的情况。前面我们介绍过,被 synchronized 修饰的代码,在开始执行时会加锁,执行完成后会进行解锁。而为了保证可见性,有一条规则是这样的:对一个变量解锁之前,必须先把此变量同步回主存中。这样解锁后,后续线程就可以访问到被修改后的值。所以,synchronized 关键字锁住的对象,其值是具有可见性的
- synchronized 与有序性
- 有序性即程序执行的顺序按照代码的先后顺序执行
- 除了引入了时间片以外,由于处理器优化和指令重排等,CPU 还可能对输入代码进行乱序执行,比如 load->add->save 有可能被优化成 load->save->add 。这就是可能存在有序性问题。这里需要注意的是,synchronized 是无法禁止指令重排和处理器优化的。也就是说,synchronized 无法避免上述提到的问题。那么,为什么还说 synchronized 也提供了有序性保证呢?这就要再把有序性的概念扩展一下了。Java 程序中天然的有序性可以总结为一句话:如果在本线程内观察,所有操作都是天然有序的。如果在一个线程中观察另一个线程,所有操作都是无序的
- as-if-serial 语义的意思指:不管怎么重排序(编译器和处理器为了提高并行度),单线程程序的执行结果都不能被改变。编译器和处理器无论如何优化,都必须遵守as-if-serial 语义。这里不对 as-if-serial 语义详细展开了,简单说就是,as-if-serial 语义保证了单线程中,指令重排是有一定的限制的,而只要编译器和处理器都遵守了这个语义,那么就可以认为单线程程序是按照顺序执行的。当然,实际上还是有重排的,只不过我们无须关心这种重排的干扰。所以呢,由于 synchronized 修饰的代码,同一时间只能被同一线程访问。那么也就是单线程执行的。所以,可以保证其有序性
- synchronized 与锁优化
- synchronized 其实是借助 Monitor 实现的,在加锁时会调用 objectMonitor 的enter 方法,解锁的时候会调用 exit 方法。事实上,只有在 JDK1.6 之前,synchronized 的实现才会直接调用 ObjectMonitor 的 enter 和 exit,这种锁被称之为重量级锁。所以,在 JDK1.6 中出现对锁进行了很多的优化,进而出现轻量级锁,偏向锁,锁消除,适应性自旋锁,锁粗化(自旋锁在 1.4 就有,只不过默认的是关闭的,jdk1.6 是默认开启的),这些操作都是为了在线程之间更高效的共享数据 ,解决竞争问题
- 介绍
- final
- 介绍
- final 是 Java 中的一个关键字,它所表示的是“这部分是无法修改的”。使用 final 可以定义 :变量、方法、类
- fianl 介绍
- 如果将变量设置为 final,则不能更改 final 变量的值(它将是常量)
- 如果任何方法声明为 final,则不能覆盖它
- 如果把任何一个类声明为 final,则不能继承它
- 介绍
- static
- 介绍
- static 表示“静态”的意思,用来修饰成员变量和成员方法,也可以形成静态 static 代码块
- 静态变量
- 我们用 static 表示变量的级别,一个类中的静态变量,不属于类的对象或者实例。因为静态变量与所有的对象实例共享,因此他们不具线程安全性。通常,静态变量常用 final 关键来修饰,表示通用资源或可以被所有的对象所使用。如果静态变量未被私有化,可以用“类名.变量名”的方式来使用
- 静态方法
- 静态方法与静态变量一样,静态方法是属于类而不是实例。一个静态方法只能使用静态变量和调用静态方法。通常静态方法通常用于想给其他的类使用而不需要创建实例。例如:Collections class(类集合)。Java 的包装类和实用类包含许多静态方法。main() 方法就是 Java 程序入口点,是静态方法
- 静态代码块
- Java 的静态块是一组指令在类装载的时候在内存中由 Java ClassLoader 执行。静态块常用于初始化类的静态变量。大多时候还用于在类装载时候创建静态资源。Java 不允许在静态块中使用非静态变量。一个类中可以有多个静态块,尽管这似乎没有什么用。静态块只在类装载入内存时,执行一次
- 静态类
- Java 可以嵌套使用静态类,但是静态类不能用于嵌套的顶层。静态嵌套类的使用与其他顶层类一样,嵌套只是为了便于项目打包
- 介绍
- const
- const 是 Java 预留关键字,用于后期扩展用,用法跟 final 相似,不常用
- transient
-
String
- 字符串的不可变性
- 定义一个字符串,s 中保存了 string 对象的引用。下面的箭头可以理解为“存储他的引用”
String s = "abcd"; ```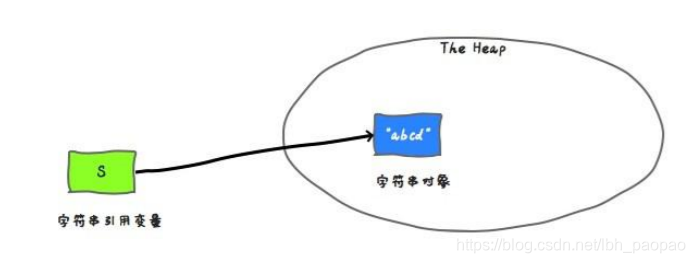 - 使用变量来赋值变量,s2 保存了相同的引用值,因为他们代表同一个对象
String s2 = s; ```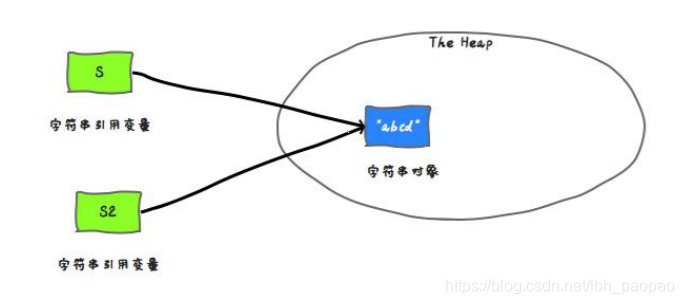 - 字符串连接,s 中保存的是一个重新创建出来的 string 对象的引用
s = s.concat("ef"); ```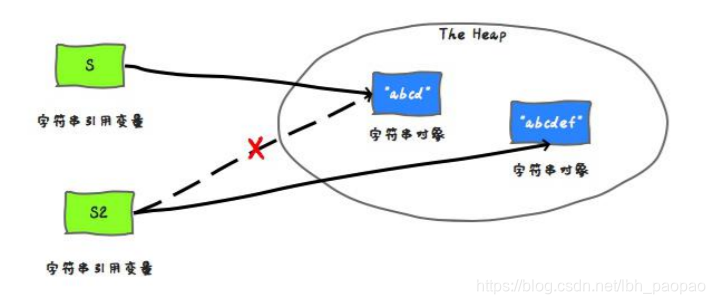 - 总结:一旦一个 string 对象在内存(堆)中被创建出来,他就无法被修改。特别要注意的是,String 类的所有方法都没有改变字符串本身的值,都是返回了一个新的对象。如果你需要一个可修改的字符串,应该使用 StringBuffer 或者 StringBuilder。否则会有大量时间浪费在垃圾回收上,因为每次试图修改都有新的 string 对象被创建出来
- 定义一个字符串,s 中保存了 string 对象的引用。下面的箭头可以理解为“存储他的引用”
- JDK 6 和 JDK 7 中 substring 的原理及区别
- substring(int beginIndex, int endIndex) 方法在不同版本的 JDK 中的实现是不同的。了解他们的区别可以帮助你更好的使用他。为简单起见,后文中用 substring() 代表 substring(int beginIndex, int endIndex) 方法
- substring(int beginIndex, int endIndex) 方法截取字符串并返回其 [beginIndex, endIndex-1] 范围内的内容,当使用 x.substring(1,3)对 x 赋值的时候,它会指向一个全新的字符串
- String是通过字符数组实现的
- jdk 6
- 在 jdk 6 中,String 类包含三个成员变量:char value[], int offset,int count。他们分别用来存储真正的字符数组,数组的第一个位置索引以及字符串中包含的字符个数,当调用 substring 方法的时候,会创建一个新的 string 对象,但是这个 string 的值仍然指向堆中的同一个字符数组。这两个对象中只有 count 和 offset 的值是不同的
- 如果你有一个很长很长的字符串,但是当你使用 substring 进行切割的时候你只需要很短的一段。这可能导致性能问题,因为你需要的只是一小段字符序列,但是你却引用了整个字符串(因为这个非常长的字符数组一直在被引用,所以无法被回收,就可能导致内存泄露)
- jdk 7
- 在 jdk 7 中,substring 方法会在堆内存中创建一个新的数组,其使用 new String 创建了一个新字符串,避免对老字符串的引用。从而解决了内存泄露问题


- 在 jdk 7 中,substring 方法会在堆内存中创建一个新的数组,其使用 new String 创建了一个新字符串,避免对老字符串的引用。从而解决了内存泄露问题
- jdk 6
- replaceFirst、replaceAll、replace 区别
- replace(CharSequence target, CharSequence replacement) ,用 replacement 替换所有的 target,两个参数都是字符串
- replaceAll(String regex, String replacement) ,用 replacement 替换所有的 regex 匹配项,regex 很明显是个正则表达式,replacement 是字符串
- replaceFirst(String regex, String replacement) ,基本和 replaceAll 相同,区别是只替换第一个匹配项
- 可以看到,其中 replaceAll 以及 replaceFirst 是和正则表达式有关的,而 replace 和正则表达式无关
- String 对“+”的重载
- String s = “a” + “b”,编译器会进行常量折叠(因为两个都是编译期常量,编译期可知),即变成 String s = “ab”
- 对于能够进行优化的(String s = “a” + 变量 等)用 StringBuilder 的 append() 方法替代,最后调用 toString() 方法 (底层就是一个 new String())
- 字符串拼接的几种方式和区别
- 字符串不变性与字符串拼接
String s = "abcd"; s = s.concat("ef"); ```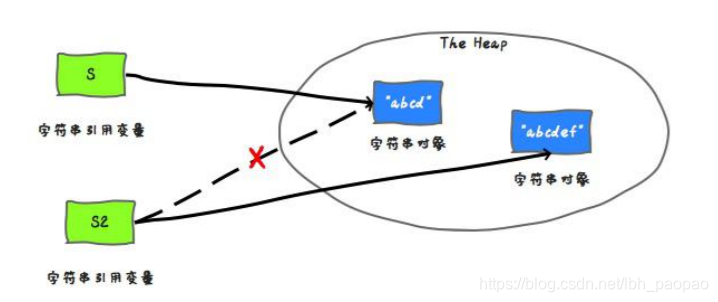 - 使用+拼接字符串
- 有人把 Java 中使用+拼接字符串的功能理解为运算符重载。其实并不是,Java 是不支持运算符重载的。这其实只是 Java 提供的一个语法糖
- 运算符重载:在计算机程序设计中,运算符重载(英语:operator overloading)是多态的一种。运算符重载,就是对已有的运算符重新进行定义,赋予其另一种功能,以适应不同的数据类型
- 语法糖:语法糖(Syntactic sugar),也译为糖衣语法,是由英国计算机科学家彼得·兰丁发明的一个术语,指计算机语言中添加的某种语法,这种语法对语言的功能没有影响,但是更方便程序员使用。语法糖让程序更加简洁,有更高的可读性
- Java中的+对字符串的拼接,其实现原理是使用StringBuilder.append
String wechat = "Hollis"; String introduce = "每日更新 Java 相关技术文章"; String hollis = wechat + "," + introduce; - 有人把 Java 中使用+拼接字符串的功能理解为运算符重载。其实并不是,Java 是不支持运算符重载的。这其实只是 Java 提供的一个语法糖
- Concat
- 首先创建了一个字符数组,长度是已有字符串和待拼接字符串的长度之和,再把两个字符串的值复制到新的字符数组中,并使用这个字符数组创建一个新的 String 对象并返回
- StringBuffer 是线程安全的,而 StringBuilder 则不是线程安全的
String wechat = "Hollis"; String introduce = "每日更新 Java 相关技术文章"; String hollis = wechat.concat(",").concat(introduce); - StringBuffer
- StringBuffer 和 StringBuilder 类也封装了一个字符数组,与 String 不同的是,它并不是 final 的,所以他是可以修改的
StringBuffer wechat = new StringBuffer("Hollis"); String introduce = "每日更新 Java 相关技术文章"; StringBuffer hollis = wechat.append(",").append(introduce); - StringBuilder
StringBuilder wechat = new StringBuilder("Hollis"); String introduce = "每日更新 Java 相关技术文章"; StringBuilder hollis = wechat.append(",").append(introduce); - StringUtils.join
- 其实他也是通过 StringBuilder来实现的
String wechat = "Hollis"; String introduce = "每日更新 Java 相关技术文章"; System.out.println(StringUtils.join(wechat, ",", introduce)); - 效率
- StringBuilder < StringBuffer < concat < + < StringUtils.join
- 建议
- 如果不是在循环体中进行字符串拼接的话,直接使用 + 就好了
- 如果在并发场景中进行字符串拼接的话,要使用 StringBuffer 来代替 StringBuilder
- 字符串不变性与字符串拼接
- String.valueOf 和 Integer.toString 的区别
- 第三行和第四行没有任何区别,因为 String.valueOf(i) 也是调用 Integer.toString(i)来实现的
- 第二行代码其实是 String i1 = (new StringBuilder()).append(i).toString();,首先创建一个 StringBuilder 对象,然后再调用
1.int i = 5; 2.String i1 = "" + i; 3.String i2 = String.valueOf(i); 4.String i3 = Integer.toString(i); - switch 对 String 的支持
- 到目前为止 switch 支持这样几种数据类型:byte、short、int、char、String
- 对 int 类型的比较是直接比较整数的值
- 对 char 类型的比较实际上比较的是 ascii 码,编译器会把 char 型变量转换成对应的 int 型变量
- 对 String 类型的比较是通过 equals()和 hashCode()方法来实现的
- 所以 switch 中只能使用整型比较
- 字符串池
- 介绍
- 在 JVM 中,为了减少相同的字符串的重复创建,为了达到节省内存的目的。会单独开辟一块内存,用于保存字符串常量,这个内存区域被叫做字符串常量池
- 当代码中出现双引号形式(字面量)创建字符串对象时,JVM 会先对这个字符串进行检查,如果字符串常量池中存在相同内容的字符串对象的引用,则将这个引用返回;否则,创建新的字符串对象,然后将这个引用放入字符串常量池,并返回该引用。这种机制,就是字符串驻留或池化
- 字符串常量池的位置
- 在 JDK 7 以前的版本中,字符串常量池是放在永久代中的
- 在 JDK 7 中,将字符串常量池先从永久代中移出,暂时放到了堆内存中
- 在 JDK 8 中,彻底移除了永久代,使用元空间替代了永久代,但字符串常量池池还在堆中,运行时常量池在元空间(方法区)
- 介绍
- Class 常量池
- 什么是 Class 文件
- Java 语言中负责编译出字节码的编译器是一个命令是 javac。javac 是收录于 JDK 中的 Java 语言编译器。该工具可以将后缀名为.java 的源文件编译为后缀名为.class 的可以运行于 Java 虚拟机的字节码
- HelloWorld.class 文件中的前八个字母是 cafe babe,这就是 Class 文件的魔数(Java 中的”魔数”)。我们需要知道的是,在 Class 文件的 4 个字节的魔数后面的分别是 4 个字节的 Class 文件的版本号(第 5、6 个字节是次版本号,第 7、8 个字节是主版本号,我生成的 Class 文件的版本号是 52,这时 Java 8 对应的版本。也就是说,这个版本的字节码,在 JDK 1.8 以下的版本中无法运行)在版本号后面的,就是 Class 常量池入口了
- Class 常量池
- Class 常量池可以理解为是 Class 文件中的资源仓库。Class 文件中除了包含类的版本、字段、方法、接口等描述信息外,还有一项信息就是常量池(constant pool table),用于存放编译器生成的各种字面量(Literal)和符号引用(Symbolic References)。由于不同的 Class 文件中包含的常量的个数是不固定的,所以在 Class 文件的常量池入口处会设置两个字节的常量池容量计数器,记录了常量池中常量的个数

- 还有一种比较简单的查看 Class 文件中常量池的方法,那就是通过 javap 命令
- Class 常量池可以理解为是 Class 文件中的资源仓库。Class 文件中除了包含类的版本、字段、方法、接口等描述信息外,还有一项信息就是常量池(constant pool table),用于存放编译器生成的各种字面量(Literal)和符号引用(Symbolic References)。由于不同的 Class 文件中包含的常量的个数是不固定的,所以在 Class 文件的常量池入口处会设置两个字节的常量池容量计数器,记录了常量池中常量的个数
- 常量池中有什么
- 常量池中主要存放两大类常量:字面量(literal)和符号引用(symbolic references)
- 字面量
- 字面量就是指由字母、数字等构成的字符串或者数值
- 字面量只可以右值出现,所谓右值是指等号右边的值,如:int a=123 这里的 a 为左值,123 为右值。在这个例子中 123 就是字面量
- 符号引用
- 符号引用是编译原理中的概念,是相对于直接引用来说的。主要包括了以下三类常量:(1):类和接口的全限定名;(2):字段的名称和描述符;(3):方法的名称和描述符
- 这也就可以印证前面的常量池中还包含一些 com/hollis/HelloWorld、main、([Ljava/lang/String;)V 等常量的原因了
- Class 常量池有什么用
- 可以明确的是,Class 常量池是 Class 文件中的资源仓库,其中保存了各种常量。而这些常量都是开发者定义出来,需要在程序的运行期使用的
- 什么是 Class 文件
- 运行时常量池
- 介绍
- 运行时常量池( Runtime Constant Pool)是每一个类或接口的常量池(Constant_Pool)的运行时表示形式
- 它包括了若干种不同的常量:从编译期可知的数值字面量到必须运行期解析后才能获得的方法或字段引用。运行时常量池扮演了类似传统语言中符号表( SymbolTable)的角色,不过它存储数据范围比通常意义上的符号表要更为广泛。每一个运行时常量池都分配在 Java 虚拟机的方法区之中,在类和接口被加载到虚拟机后,对应的运行时常量池就被创建出来
- 运行时常量池在 JDK 各个版本中的实现
- 在 JDK 1.7 之前,方法区位于堆内存的永久代中,运行时常量池作为方法区的一部分,也处于永久代中
- 在 JDK 1.7 中,将原本位于永久代中的运行时常量池移动到堆内存中
- 在 JDK 1.8 中,彻底移除了永久代,方法区通过元空间的方式实现。随之,运行时常量池也在元空间中实现
- 运行时常量池中常量的来源
- 运行时常量池中包含了若干种不同的常量:编译期可知的字面量和符号引用(来自 Class 常量池)以及运行期解析后可获得的常量(如String 的 intern 方法)
- 运行时常量池中的内容包含:Class 常量池中的常量、字符串常量池中的内容
- 运行时常量池、Class 常量池、字符串常量池的区别与联系
- 虚拟机启动过程中,会将各个 Class 文件中的常量池载入到运行时常量池中。所以, Class 常量池只是一个媒介场所。在 JVM 真的运行时,需要把常量池中的常量加载到内存中,进入到运行时常量池。字符串常量池可以理解为运行时常量池分出来的部分。加载时,对于 class 的静态常量池,如果字符串会被装到字符串常量池中
- 介绍
- intern
- 在 JVM 中,为了减少相同的字符串的重复创建,为了达到节省内存的目的。会单独开辟一块内存,用于保存字符串常量,这个内存区域被叫做字符串常量池。当代码中出现双引号形式(字面量)创建字符串对象时,JVM 会先对这个字符串进行检查,如果字符串常量池中存在相同内容的字符串对象的引用,则将这个引用返回;否则,创建新的字符串对象,然后将这个引用放入字符串常量池,并返回该引用。除了以上方式之外,还有一种可以在运行期将字符串内容放置到字符串常量池的办法,那就是使用 intern
- intern 的功能很简单:在每次赋值的时候使用 String 的 intern 方法,如果常量池中有相同值,就会重复使用该对象,返回对象引用
- String 有没有长度限制
- String 类中有很多重载的构造函数,其中有几个是支持用户传入 length 来执行长度的。可以发现,这里面的参数 length 是使用 int 类型定义的,那么也就是说,String 定义的时候,最大支持的长度就是 int 的最大范围值。根据 Integer 类的定义,java.lang.Integer#MAX_VALUE 的最大值是 2^31 - 1。但这个值只是在运行期的
- 如 String s = “xxx”;定义 String 的时候,xxx 被我们称之为字面量,这种字面量在编译之后会以常量的形式进入到 Class 常量池。那么问题就来了,因为要进入常量池,就要遵守常量池的有关规定。也就是说,对象 Class 文件中常量池的格式规定了,其字符串常量的长度不能超过 65535
- 运行期限制:很多人会有疑惑,编译的时候最大长度都要求小于 65535 了,运行期怎么会出现大于 65535 的情况呢?
String s = ""; for (int i = 0; i <100000 ; i++) { s+="i"; }
- 字符串的不可变性
-
自动拆/装箱的实现
- 自动拆装箱
- 基本数据类型
- 基本类型,或者叫做内置类型,是 Java 中不同于类(Class)的特殊类型。它们是我们编程中使用最频繁的类型。Java 是一种强类型语言,第一次申明变量必须说明数据类型,第一次变量赋值称为变量的初始化
- Java 基本类型共有八种,基本类型可以分为三类:
- 字符类型:char
- 布尔类型:boolean
- 数值类型:
- 整数类型:byte、short、int、long
- 浮点数类型:float、double
- Java 中的数值类型不存在无符号的,它们的取值范围是固定的,不会随着机器硬件环境或者操作系统的改变而改变。实际上,Java中还存在另外一种基本类型void,它也有对应的包装类 java.lang.Void,不过我们无法直接对它们进行操作
- 基本数据类型有什么好处
- 我们都知道在 Java 语言中,new 一个对象是存储在堆里的,我们通过栈中的引用来使用这些对象;所以,对象本身来说是比较消耗资源的。对于经常用到的类型,如 int 等,如果我们每次使用这种变量的时候都需要 new 一个 Java 对象的话,就会比较笨重。所以,和 C++一样,Java 提供了基本数据类型,这种数据的变量不需要使用 new 创建,他们不会在堆上创建,而是直接在栈内存中存储,因此会更加高效
- 整型的取值范围
- Java 中的整型主要包含 byte、short、int 和 long 这四种,表示的数字范围也是从小到大的,之所以表示范围不同主要和他们存储数据时所占的字节数有关
- byte:byte 用 1 个字节来存储,范围为-128(-2^7)到 127(2^7-1),在变量初始化的时候,byte 类型的默认值为 0
- short:short 用 2 个字节存储,范围为-32,768 (-2^15)到 32,767 (2^15-1),在变量初始化的时候,short 类型的默认值为 0,一般情况下,因为 Java 本身转型的原因,可以直接写为 0
- int:int 用 4 个字节存储,范围为-2,147,483,648 (-2^31)到 2,147,483,647 (2^31 -1),在变量初始化的时候,int 类型的默认值为 0
- long:long 用 8 个字节存储,范围为-9,223,372,036,854,775,808 (-2^63)到 9, 223,372,036, 854,775,807 (2^63-1),在变量初始化的时候,long 类型的默认值为 0L 或 0l,也可直接写为 0
- 超出范围怎么办
- 溢出的时候并不会抛异常,也没有任何提示
- 包装类型
- 基本数据类型:byte、boolean、short、char、int、long、float、double
- 包装类:Byte、Boolean、Short、Character、Integer、Long、Float、Double
- 在这八个类名中,除了 Integer 和 Character 类以后,其它六个类的类名和基本数据类型一致,只是类名的第一个字母大写即可
- 为什么需要包装类
- 因为 Java 是一种面向对象语言,很多地方都需要使用对象而不是基本数据类型。比如,在集合类中,我们是无法将 int 、double 等类型放进去的。因为集合的容器要求元素是 Object 类型。为了让基本类型也具有对象的特征,就出现了包装类型,它相当于将基本类型“包装起来”,使得它具有了对象的性质,并且为其添加了属性和方法,丰富了基本类型的操作
- 拆箱与装箱
- 包装类是对基本类型的包装,所以,把基本数据类型转换成包装类的过程就是打包装,英文对应于 boxing,中文翻译为装箱
- 把包装类转换成基本数据类型的过程就是拆包装,英文对应于 unboxing,中文翻译为拆箱
- 在 Java SE5 之前,要进行装箱,可以通过以下代码:Integer i = new Integer(10)
- 自动拆箱与自动装箱
- 自动装箱: 就是将基本数据类型自动转换成对应的包装类
- 自动拆箱:就是将包装类自动转换成对应的基本数据类型
- 自动装箱与自动拆箱的实现原理
- 我们有以下自动拆装箱的代码
public static void main(String[] args) { Integer integer=1; //装箱 int i=integer; //拆箱 } - 对以上代码进行反编译后可以得到以下代码:
public static void main(String[] args) { Integer integer=Integer.valueOf(1); int i=integer.intValue(); } - 自动装箱都是通过包装类的 valueOf() 方法来实现的
- 自动拆箱都是通过包装类对象的 xxxValue() 来实现的
- 我们有以下自动拆装箱的代码
- 哪些地方会自动拆装箱
- 将基本数据类型放入包装类型的集合类
- 包装类型和基本类型的大小比较
- 包装类型的运算
- 三目运算符的使用
- 函数参数与返回值
- 自动拆装箱与缓存
- 整型对象通过使用相同的对象引用实现了缓存和重用,适用于整数值区间-128 至 +127,只适用于自动装箱。使用构造函数创建对象不适用
- 最大值 127 可以通过可以通过-XX:AutoBoxCacheMax=size 修改
- 在 Java6 中,可以通过 java.lang.Integer.IntegerCache.high 设置最大值
- 自动拆装箱带来的问题
- 包装对象的数值比较,不能简单的使用==,虽然-128 到 127 之间的数字可以,但是这个范围之外还是需要使用 equals 比较
- 如果一个 for 循环中有大量拆装箱操作,会浪费很多资源
- 基本数据类型
- Integer 的缓存机制
- 介绍
- javadoc 详细的说明了缓存支持 -128 到 127 之间的自动装箱过程。最大值 127 可以通过-XX:AutoBoxCacheMax=size 修改。 缓存通过一个 for 循环实现。从低到高并创建尽可能多的整数并存储在一个整数数组中。这个缓存会在 Integer 类第一次被使用的时候被初始化出来。以后,就可以使用缓存中包含的实例对象,而不是创建一个新的实例(在自动装箱的情况下)
- 实际上这个功能在 Java 5 中引入的时候,范围是固定的-128 至 +127。后来在 Java 6 中,可以通过 java.lang.Integer.IntegerCache.high 设置最大值
- Java 语言规范中的缓存行为
- 在 Boxing Conversion 部分的 Java 语言规范(JLS)规定如下:如果一个变量 p 的值是:-128 至 127 之间的整数(§3.10.1),true 和 false 的布尔值 (§3.10.3),‘\u0000’至 ‘\u007f’之间的字符(§3.10.4)中时,将 p 包装成 a 和 b 两个对象时,可以直接使用 a==b 判断 a 和 b 的值是否相等
- 其他缓存的对象
- 这种缓存行为不仅适用于 Integer 对象。我们针对所有的整数类型的类都有类似的缓存机制
- 有 ByteCache 用于缓存 Byte 对象
- 有 ShortCache 用于缓存 Short 对象
- 有 LongCache 用于缓存 Long 对象
- 有 CharacterCache 用于缓存 Character 对象
- Byte, Short, Long 有固定范围: -128 到 127。对于 Character, 范围是 0 到 127。除了 Integer 以外,这个范围都不能改变
- 这种缓存行为不仅适用于 Integer 对象。我们针对所有的整数类型的类都有类似的缓存机制
- 介绍
- 如何正确定义接口的返回值(boolean/Boolean)类型及命名(success/isSuccess)
- 一般情况下,我们可以有以下四种方式来定义一个布尔类型的成员变量
boolean success boolean isSuccess Boolean success Boolean isSuccess - 在 Java 开发手册中关于这一点,有过一个『强制性』规定
- 【强制】POJO 类中的任何布尔类型的变量,都不要加 is 前缀,否则部分框架解析会引起序列化错误
- 说明:在本文 MySQL 规约中的建表约定第一条,表达是与否的变量采用 is_xxx 的命名方式,所以,需要在 resultMap 设置从 is_xxx 到 xxx 的映射关系
- 反例:定义为基本数据类型 Boolean isDeleted 的属性,它的方法也是 isDeleted(),框架在反向解析的时候,“误以为”对应的属性名称是 deleted,导致属性获取不到,进而抛出异常
- 测试
- 基本类型自动生成的 getter 和 setter 方法,名称都是 isXXX() 和 setXXX() 形式的
- 包装类型自动生成的 getter 和 setter 方法,名称都是 getXXX() 和 setXXX() 形式的
- Java Bean 中关于 setter/getter 的规范
- 关于 Java Bean 中的 getter/setter 方法的定义其实是有明确的规定的,根据 JavaBeans™ Specification 规定,如果是普通的参数 propertyName,要以下方式定义其 setter/getter:
public <PropertyType> get<PropertyName>(); public void set<PropertyName>(<PropertyType> a); - 但是,布尔类型的变量 propertyName 则是单独定义的:
public boolean is<PropertyName>(); public void set<PropertyName>(boolean m); - 但是很多 IDE 都会默认生成为 isSuccess
- 关于 Java Bean 中的 getter/setter 方法的定义其实是有明确的规定的,根据 JavaBeans™ Specification 规定,如果是普通的参数 propertyName,要以下方式定义其 setter/getter:
- 序列化带来的影响
- 示例
public class BooleanMainTest { public static void main(String[] args) throws IOException { //定一个 Model3 类型 Model3 model3 = new Model3(); model3.setSuccess(true); //使用 fastjson(1.2.16)序列化 model3 成字符串并输出 System.out.println("Serializable Result With fastjson :" + JSON.toJSONString(model3)); //使用 Gson(2.8.5)序列化 model3 成字符串并输出 Gson gson =new Gson(); System.out.println("Serializable Result With Gson :" +gson.toJson(model3)); //使用 jackson(2.9.7)序列化 model3 成字符串并输出 ObjectMapper om = new ObjectMapper(); System.out.println("Serializable Result With jackson :" +om.writeValueAsString(model3)); } } class Model3 implements Serializable { private static final long serialVersionUID = 1836697963736227954L; private boolean isSuccess; public boolean isSuccess() { return isSuccess; } public void setSuccess(boolean success) { isSuccess = success; } public String getHollis(){ return "hollischuang"; } } // Serializable Result With fastjson :{"hollis":"hollischuang","success":true} // Serializable Result With Gson :{"isSuccess":true} // Serializable Result With jackson :{"success":true,"hollis":"hollischuang"} - 结果分析
- fastjson 和 jackson 在把对象序列化成 json 字符串的时候,是通过反射遍历出该类中的所有 getter 方法,得到 getHollis 和 isSuccess,然后根据 JavaBeans 规则,他会认为这是两个属性 hollis 和 success 的值。直接序列化成 json:{“hollis”:“hollischuang”,“success”:true}。但是 Gson 并不是这么做的,他是通过反射遍历该类中的所有属性,并把其值序列化成 json:{“isSuccess”:true}
- 前面提到的关于对 getHollis 的序列化只是为了说明 fastjson、jackson 和 Gson 之间的序列化策略的不同,我们暂且把他放到一边,我们把他从 Model3 中删除后,重新执行下以上代码,得到结果:
// Serializable Result With fastjson :{"success":true} // Serializable Result With Gson :{"isSuccess":true} // Serializable Result With jackson :{"success":true}
- 如果对于同一个对象,我使用 fastjson 进行序列化,再使用 Gson 反序列化会发生什么
public class BooleanMainTest { public static void main(String[] args) throws IOException { Model3 model3 = new Model3(); model3.setSuccess(true); Gson gson =new Gson(); System.out.println(gson.fromJson(JSON.toJSONString(model3),Model3.class)); } } class Model3 implements Serializable { private static final long serialVersionUID = 1836697963736227954L; private boolean isSuccess; public boolean isSuccess() { return isSuccess; } public void setSuccess(boolean success) { isSuccess = success; } @Override public String toString() { return new StringJoiner(", ", Model3.class.getSimpleName() + "[", "]").add("isSuccess=" + isSuccess).toString(); } } // Model3[isSuccess=false] - 原因是因为 JSON 框架通过扫描所有的 getter 后发现有一个 isSuccess 方法,然后根据 JavaBeans 的规范,解析出变量名为 success,把 model 对象序列化城字符串后内容为"success":true}。根据{“success”:true}这个 json 串,Gson 框架在通过解析后,通过反射寻找 Model 类中的 success 属性,但是 Model 类中只有 isSuccess 属性,所以,最终反序列化后的Model 类的对象中,isSuccess 则会使用默认值 false
- 示例
- 结论一
- 所以,在定义 POJO 中的布尔类型的变量时,不要使用 isSuccess 这种形式,而要直接使用 success
- Boolean 还是 boolean
- 两种不同
- Boolean 类型的变量会设置默认值为 null,而 boolean 类型的变量会设置默认值为 false
- Java开发规范
- 关于基本数据类型与包装数据类型的使用标准如下:
- 【强制】所有的 POJO 类属性必须使用包装数据类型
- 【强制】RPC 方法的返回值和参数必须使用包装数据类型
- 【推荐】所有的局部变量使用基本数据类型
- 说明:POJO 类属性没有初值是提醒使用者在需要使用时,必须自己显式地进行赋值,任何 NPE 问题,或者入库检查,都由使用者来保证
- 正例:数据库的查询结果可能是 null,因为自动拆箱,用基本数据类型接收有 NPE 风险
- 反例:某业务的交易报表上显示成交总额涨跌情况,即正负 x%,x 为基本数据类型,调用的 RPC 服务,调用不成功时,返回的是默认值,页面显示为 0%,这是不合理的,应该显示成中划线-。所以包装数据类型的 null 值,能够表示额外的信息,如:远程调用失败,异常退出
- 举一个扣费的例子,我们做一个扣费系统,扣费时需要从外部的定价系统中读取一个费率的值,我们预期该接口的返回值中会包含一个浮点型的费率字段。当我们取到这个值得时候就使用公式:金额*费率=费用 进行计算,计算结果进行划扣。如果由于计费系统异常,他可能会返回个默认值,如果这个字段是 Double 类型的话,该默认值为 null,如果该字段是 double 类型的话,该默认值为 0.0。如果扣费系统对于该费率返回值没做特殊处理的话,拿到 null 值进行计算会直接报错,阻断程序。拿到 0.0 可能就直接进行计算,得出接口为 0 后进行扣费了。这种异常情况就无法被感知
- 两种不同
- 一般情况下,我们可以有以下四种方式来定义一个布尔类型的成员变量
- 自动拆装箱
-
异常处理
- Error 和 Exception
- 介绍
- Exception 和 Error,⼆者都是 Java 异常处理的重要⼦类,各⾃都包含⼤量⼦类。均继承自 Throwable 类
- Error 表⽰系统级的错误,是 java 运⾏环境内部错误或者硬件问题,不能指望程序来处理这样的问题,除了退出运⾏外别⽆选择,它是 Java 虚拟机抛出的
- Exception 表⽰程序需要捕捉、需要处理的常,是由与程序设计的不完善⽽出现的问题,程序必须处理的问题
- 介绍
- 异常类型
- 介绍
- Java 中的异常,主要可以分为两⼤类,即受检异常(checked exception)和非受检异常(unchecked exception)
- 受检异常
- 对于受检异常来说,如果⼀个⽅法在声明的过程中证明了其要有受检异常抛出,那么,当我们在程序中调⽤他的时候,⼀定要对该异常进⾏处理(捕获或者向上抛出),否则是⽆法编译通过的。 这是⼀种强制规范
public void test() throw new Exception{ }
- 对于受检异常来说,如果⼀个⽅法在声明的过程中证明了其要有受检异常抛出,那么,当我们在程序中调⽤他的时候,⼀定要对该异常进⾏处理(捕获或者向上抛出),否则是⽆法编译通过的。 这是⼀种强制规范
- 非受检异常
- 对于⾮受检异常来说,⼀般是运⾏时异常,继承⾃RuntimeException。在编写代码的时候,不需要显⽰的捕获,但是如果不捕获,在运⾏期如果发⽣异常就会中断程序的执⾏。
- 这种异常⼀般可以理解为是代码原因导致的。⽐如发⽣空指针、数组越界等。所以,只要代码写的没问题,这些异常都是可以避免的。也就不需要我们显⽰的进⾏处理
- 介绍
- 异常相关关键字
- throws、 throw、 try、 catch、 finally
- try ⽤来指定⼀块预防所有异常的程序
- catch ⼦句紧跟在 try 块后⾯, ⽤来指定你想要捕获的异常的类型
- finally 为确保⼀段代码不管发⽣什么异常状况都要被执⾏
- throw 语句⽤来明确地抛出⼀个异常
- throws ⽤来声明⼀个⽅法可能抛出的各种异常
- 正确处理异常
- 异常的处理⽅式有两种
- ⾃⼰处理
- 向上抛,交给调⽤者处理
- 异常,千万不能捕获了之后什么也不做。或者只是使⽤ e.printStacktrace
- 具体的处理⽅式的选择其实原则⽐较简明:自己明确的知道如何处理的,就要处理掉。不知道如何处理的,就交给调⽤者处理
- 异常的处理⽅式有两种
- 自定义异常
- ⾃定义异常就是开发人员⾃⼰定义的异常,⼀般通过继承 Exception 的⼦类的⽅式实现
- 编写⾃定义异常类实际上是继承⼀个 API 标准异常类,⽤新定义的异常处理信息覆盖原有信息的过程
- 这种⽤法在 Web 开发中也⽐较常见,一般可以⽤来⾃定义业务异常。如余额不⾜、重复提交等。这种⾃定义异常有业务含义,更容易让上层理解和处理
- 异常链
- “异常链”是 Java 中⾮常流⾏的异常处理概念,是指在进⾏⼀个异常处理时抛出了另外⼀个异常,由此产⽣了⼀个异常链条
- 该技术⼤多⽤于将“受检查异常”(checked exception)封装成为“⾮受检查异常”(unchecked exception) 或者 RuntimeException。顺便说⼀下,如果因为因为异常你决定抛出⼀个新的异常,你⼀定要包含原有的异常,这样,处理程序才可以通过 getCause()和 initCause() ⽅法来访问异常最终的根源
- 从 Java 1.4 版本开始,几乎所有的异常都支持异常链。以下是 Throwable 中支持异常链的方法和构造函数
// initCause 和 Throwable 构造函数的 Throwable 参数是导致当前异常的异常。getCause 返回导致当前异常的异常,initCause 设置当前异常的原因 Throwable getCause() Throwable initCause(Throwable) Throwable(String, Throwable) Throwable(Throwable) try { } catch (IOException e) { // 当捕获到 IOException 时,将创建一个新的 SampleException 异常,并附加原始的异常原因,并将异常链抛出到下一个更高级别的异常处理程序 throw new SampleException("Other IOException", e); }
- try-with-resources
- 关闭资源的常用方式就是在 finally 块里是释放,即调用 close 方法
public static void main(String[] args) { BufferedReader br = null; try { String line; br = new BufferedReader(new FileReader("d:\\hollischuang.xml")); while ((line = br.readLine()) != null) { System.out.println(line); } } catch (IOException e) { // handle exception } finally { try { if (br != null) { br.close(); } } catch (IOException ex) { // handle exception } } } - 从 Java 7 开始,jdk 提供了一种更好的方式关闭资源,使用 try-with-resources 语句,改写一下上面的代码
public static void main(String... args) { try (BufferedReader br = new BufferedReader(new FileReader("d:\\ hollischuang.xml"))) { String line; while ((line = br.readLine()) != null) { System.out.println(line); } } catch (IOException e) { // handle exception } } - 原理
public static transient void main(String args[]){ BufferedReader br; Throwable throwable; br = new BufferedReader(new FileReader("d:\\ hollischuang.xml")); throwable = null; String line; try{ while((line = br.readLine()) != null) System.out.println(line); }catch(Throwable throwable2){ throwable = throwable2; throw throwable2; } if(br != null) if(throwable != null) try{ br.close(); }catch(Throwable throwable1){ throwable.addSuppressed(throwable1); } else br.close(); break MISSING_BLOCK_LABEL_113; Exception exception; exception; if(br != null) if(throwable != null) Try{ br.close(); } catch(Throwable throwable3){ throwable.addSuppressed(throwable3); } else br.close(); throw exception; IOException ioexception; ioexception; }
- 关闭资源的常用方式就是在 finally 块里是释放,即调用 close 方法
- finally 和 return 的执行顺序
- 如果 try 中有 return 语句, 那么 finally 中的代码还是会执⾏。因为 return 表⽰的是要整个⽅法体返回, 所以,finally 中的语句会在 return 之前执⾏。但是 return 前执行的 finally 块内,对数据的修改效果对于引用类型和值类型会不同
//测试 修改值类型 static int f() { int ret = 0; try { return ret; // 返回 0,finally 内的修改效果不起作用 } finally { ret++; System.out.println("finally 执行"); } } // 测试 修改引用类型 static int[] f2(){ int[] ret = new int[]{0}; try { return ret; // 返回 [1],finally 内的修改效果起了作用 } finally { ret[0]++; System.out.println("finally 执行"); } }
- 如果 try 中有 return 语句, 那么 finally 中的代码还是会执⾏。因为 return 表⽰的是要整个⽅法体返回, 所以,finally 中的语句会在 return 之前执⾏。但是 return 前执行的 finally 块内,对数据的修改效果对于引用类型和值类型会不同
- Error 和 Exception
-
集合类
- Collection 和 Collections 区别
- Collection 是一个集合接口。它提供了对集合对象进行基本操作的通用接口方法。Collection 接口在 Java 类库中有很多具体的实现。是 list,set 等的父接口
- Collections 是一个包装类。它包含有各种有关集合操作的静态多态方法。此类不能实例化,就像一个工具类,服务于 Java 的 Collection 框架
- Set 和 List 区别?
- List,Set 都是继承自 Collection 接口。都是用来存储一组相同类型的元素的
- List 特点:元素有放入顺序,元素可重复。有顺序,即先放入的元素排在前面
- Set 特点:元素无放入顺序,元素不可重复。无顺序,即先放入的元素不一定排在前面。不可重复,即相同元素在 set 中只会保留一份。所以,有些场景下,set 可以用来去重
- ArrayList 和 LinkedList 和 Vector 的区别
- List 主要有 ArrayList、LinkedList 与 Vector 几种实现。这三者都实现了 List 接口,使用方式也很相似,主要区别在于因为实现方式的不同,所以对不同的操作具有不同的效率
- ArrayList 是一个可改变大小的数组。当更多的元素加入到 ArrayList 中时,其大小将会动态地增长。内部的元素可以直接通过 get 与 set 方法进行访问,因为 ArrayList 本质上就是一个数组
- LinkedList 是一个双链表,在添加和删除元素时具有比 ArrayList 更好的性能。但在get 与 set 方面弱于 ArrayList。当然,这些对比都是指数据量很大或者操作很频繁的情况下的对比
- Vector 和 ArrayList 类似,但属于强同步类。如果你的程序本身是线程安全的(thread-safe,没有在多个线程之间共享同一个集合/对象),那么使用 ArrayList 是更好的选择。Vector 和 ArrayList 在更多元素添加进来时会请求更大的空间。Vector 每次请求其大小的双倍空间,而 ArrayList 每次对 size 增长 50%。而 LinkedList 还实现了 Queue 接口,该接口比 List 提供了更多的方法,包括 offer(), peek(),poll()等
- 注意: 默认情况下 ArrayList 的初始容量非常小,所以如果可以预估数据量的话,分配一个较大的初始值属于最佳实践,这样可以减少调整大小的开销
- ArrayList 使用了 transient 关键字进行存储优化,而 Vector 没有,为什么?
- ArrayList 实现了 writeObject 方法,可以看到只保存了非 null 的数组位置上的数据。即 list 的 size 个数的 elementData。需要额外注意的一点是,ArrayList 的实现,提供了fast-fail 机制,可以提供弱一致性
- Vector 也实现了 writeObject 方法,但方法并没有像 ArrayList 一样进行优化存储。clone() 的时候会把 null 值也拷贝。所以保存相同内容的 Vector 与 ArrayList,Vector 的占用的字节比 ArrayList 要多
- ArrayList 是非同步实现的一个单线程下较为高效的数据结构(相比 Vector 来说)。ArrayList 只通过一个修改记录字段提供弱一致性,主要用在迭代器里。没有同步方法。即上面提到的 Fast-fail 机制。ArrayList 的存储结构定义为 transient,重写 writeObject来实现自定义的序列化,优化了存储。Vector 是多线程环境下更为可靠的数据结构,所有方法都实现了同步
- 同步处理:Vector 同步,ArrayList 非同步。Vector 缺省情况下增长原来一倍的数组长度,ArrayList 是 0.5 倍
- ArrayList: int newCapacity = oldCapacity +(oldCapacity >> 1); ArrayList 自动扩大容量为原来的 1.5 倍(实现的时候,方法会传入一个期望的最小容量,若扩容后容量仍然小于最小容量,那么容量就为传入的最小容量。扩容的时候使用的 Arrays.copyOf 方法最终调用 native 方法进行新数组创建和数据拷贝)
- Vector: int newCapacity = oldCapacity + ((capacityIncrement > 0) ?capacityIncrement : oldCapacity); Vector 指定了 initialCapacity,capacityIncrement 来初始化的时候,每次增长 capacityIncrement
- SynchronizedList 和 Vector 的区别
- Vector 是 java.util 包中的一个类。SynchronizedList 是 java.util.Collections 中的一个静态内部类。在多线程的场景中可以直接使用Vector类,也可以使Collections. synchronizedList(List list) 方法来返回一个线程安全的 List
- SynchronizedList 和 Vector 的比较明显区别
- 一个使用了同步代码块(SynchronizedList),一个使用了同步方法(Vector)
- 如果使用 add 方法,那么他们的扩容机制不一样
- SynchronizedList 可以指定锁定的对象
- 同步代码块和同步方法的区别
- 同步代码块在锁定的范围上可能比同步方法要小,一般来说锁的范围大小和性能是成反比的
- 同步块可以更加精确的控制锁的作用域(锁的作用域就是从锁被获取到其被释放的时间),同步方法的锁的作用域就是整个方法
- 静态代码块可以选择对哪个对象加锁,但是静态方法只能给 this 对象加锁
- 总结
- SynchronizedList 有很好的扩展和兼容功能。他可以将所有的 List 的子类转成线程安全的类
- 使用SynchronizedList 的时候,进行遍历时要手动进行同步处理
- SynchronizedList 可以指定锁定的对象
- Set 如何保证元素不重复?
- 在 Java 的 Set 体系中,根据实现方式不同主要分为两大类。HashSet 和 TreeSet
- TreeSet 是二叉树实现的,Treeset 中的数据是自动排好序的,不允许放入 null 值。TreeSet 的底层是 TreeMap 的 keySet(),而 TreeMap 是基于红黑树实现的,红黑树是一种平衡二叉查找树,它能保证任何一个节点的左右子树的高度差不会超过较矮的那棵的一倍。TreeMap 是按 key 排序的,元素在插入 TreeSet 时 compareTo()方法要被调用,所以 TreeSet 中的元素要实现 Comparable 接口。TreeSet 作为一种 Set,它不允许出现重复元素。TreeSet 是用 compareTo()来判断重复元素的
- HashSet 是哈希表实现的,HashSet 中的数据是无序的,可以放入 null,但只能放入一个 null,两者中的值都不能重复,就如数据库中唯一约束。在 HashSet 中,基本的操作都是有 HashMap 底层实现的,因为 HashSet 底层是用HashMap 存储数据的。当向 HashSet 中添加元素的时候,首先计算元素的 hashcode 值,然后通过扰动计算和按位与的方式计算出这个元素的存储位置,如果这个位置位空,就将元素添加进去;如果不为空,则用 equals 方法比较元素是否相等,相等就不添加,否则找一个空位添加
- 在 Java 的 Set 体系中,根据实现方式不同主要分为两大类。HashSet 和 TreeSet
- HashMap、HashTable、ConcurrentHashMap 区别
- HashMap 和 HashTable 有何不同?
- 线程安全:HashTable 中的方法是同步的,而 HashMap 中的方法在默认情况下是非同步的。在多线程并发的环境下,可以直接使用 HashTable,但是要使用 HashMap 的话就要自己增加同步处理了
- 继承关系:HashTable 是基于陈旧的 Dictionary 类继承来的。 HashMap 继承的抽象类 AbstractMap 实现了 Map 接口
- 允不允许 null 值:HashTable 中,key 和 value 都不允许出现 null 值,否则会抛出NullPointerException 异常。HashMap 中,null 可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为 null
- 默认初始容量和扩容机制:HashTable 中的 hash 数组初始大小是 11,增加的方式是 old*2+1。HashMap 中 hash 数组的默认大小是 16,而且一定是 2 的指数
- 哈希值的使用不同:HashTable 直接使用对象的 hashCode。 HashMap 重新计算 hash 值
- 遍历方式的内部实现上不同:Hashtable、HashMap 都使用了 Iterator。而由于历史原因,Hashtable 还使用了 Enumeration 的方式。HashMap 实现 Iterator,支持 fast-fail,Hashtable 的 Iterator 遍历支持 fast-fail,用 Enumeration 不支持 fast -fail
- HashMap 和 ConcurrentHashMap 的区别?
- ConcurrentHashMap 和 HashMap 的实现方式不一样,虽然都是使用桶数组实现的,但是还是有区别,ConcurrentHashMap 对桶数组进行了分段,而 HashMap 并没有。ConcurrentHashMap 在每一个分段上都用锁进行了保护。HashMap 没有锁机制。所以,前者线程安全的,后者不是线程安全的
- PS:以上区别基于 jdk1.8 以前的版本
- HashMap 和 HashTable 有何不同?
- HashMap 的容量、扩容
- HashMap 类中有以下主要成员变量
- transient int size:记录了 Map 中 KV 对的个数
- loadFactor:装载因子,用来衡量 HashMap 满的程度。loadFactor 的默认值为 0.75f(static final float DEFAULT_LOAD_FACTOR = 0.75f;)
- int threshold:临界值,当实际 KV 个数超过 threshold 时,HashMap 会将容量扩容,threshold=容量*装载因子
- 除了以上这些重要成员变量外,HashMap 中还有一个和他们紧密相关的概念:
- capacity:容量,如果不指定,默认容量是 16(static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;)
- size 和 capacity
- HashMap 就像一个“桶”,那么 capacity 就是这个桶“当前”最多可以装多少元素,而 size 表示这个桶已经装了多少元素
- 默认情况下 HashMap 的容量是 16,但是,如果用户通过构造函数指定了一个数字作为容量,那么 Hash 会选择大于该数字的第一个 2 的幂作为容量。(1->1、7->8、9->16)
- loadFactor 和 threshold
- 扩容条件
- 扩容条件:HashMap 的扩容条件就是当 HashMap 中的元素个数(size)超过临界值(threshold)时就会自动扩容。在 HashMap 中,threshold = loadFactor * capacity
- loadFactor 是装载因子,表示 HashMap 满的程度,默认值为 0.75f,设置成 0.75有一个好处,那就是 0.75 正好是 3/4,而 capacity 又是 2 的幂。所以,两个数的乘积都是整数。对于一个默认的 HashMap 来说,默认情况下,当其 size 大于 12(16*0.75) 时就会触发扩容
- 扩容条件
- HashMap 类中有以下主要成员变量
- HashMap 中 hash 方法的原理
- 哈希
- Hash,一般翻译做“散列”,也有直接音译为“哈希”的,就是把任意长度的输入,通过散列算法,变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来唯一的确定输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数
- 所有散列函数都有如下一个基本特性:根据同一散列函数计算出的散列值如果不同,那么输入值肯定也不同。但是,根据同一散列函数计算出的散列值如果相同,输入值不一定相同。两个不同的输入值,根据同一散列函数计算出的散列值相同的现象叫做碰撞
- 常见的 Hash 函数有以下几个
- 直接定址法:直接以关键字 k 或者 k 加上某个常数(k+c)作为哈希地址
- 数字分析法:提取关键字中取值比较均匀的数字作为哈希地址
- 除留余数法:用关键字 k 除以某个不大于哈希表长度 m 的数 p,将所得余数作为哈希表地址
- 分段叠加法:按照哈希表地址位数将关键字分成位数相等的几部分,其中最后一部分可以比较短。然后将这几部分相加,舍弃最高进位后的结果就是该关键字的哈希地址
- 平方取中法:如果关键字各个部分分布都不均匀的话,可以先求出它的平方值,然后按照需求取中间的几位作为哈希地址
- 伪随机数法:采用一个伪随机数当作哈希函数
- 任何哈希函数基本都无法彻底避免碰撞,常见的解决碰撞的方法有以下几种
- 开放定址法:开放定址法就是一旦发生了冲突,就去寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找到,并将记录存入
- 链地址法:将哈希表的每个单元作为链表的头结点,所有哈希地址为 i 的元素构成一个同义词链表。即发生冲突时就把该关键字链在以该单元为头结点的链表的尾部
- 再哈希法:当哈希地址发生冲突用其他的函数计算另一个哈希函数地址,直到冲突不再产生为止
- 建立公共溢出区:将哈希表分为基本表和溢出表两部分,发生冲突的元素都放入溢出表中
- HashMap 的数据结构
- 介绍
- 在 Java 中,保存数据有两种比较简单的数据结构:数组和链表。数组的特点是:寻址容易,插入和删除困难;而链表的特点是:寻址困难,插入和删除容易。上面我们提到过,常用的哈希函数的冲突解决办法中有一种方法叫做链地址法,其实就是将数组和链表组合在一起,发挥了两者的优势,我们可以将其理解为链表的数组

- 在 Java 中,保存数据有两种比较简单的数据结构:数组和链表。数组的特点是:寻址容易,插入和删除困难;而链表的特点是:寻址困难,插入和删除容易。上面我们提到过,常用的哈希函数的冲突解决办法中有一种方法叫做链地址法,其实就是将数组和链表组合在一起,发挥了两者的优势,我们可以将其理解为链表的数组
- hash 方法
- hash() 方法的功能就是根据 Key 来定位其在 HashMap 中的位置
- 源码解析
- 我们先来做个简单分析。我们知道,hash 方法的功能是根据 Key 来定位这个 K-V 在链表数组中的位置的。也就是 hash 方法的输入应该是个 Object 类型的 Key,输出应该是个 int 类型的数组下标。如果让你设计这个方法,你会怎么做?其实简单,我们只要调用 Object 对象的 hashCode()方法,该方法会返回一个整数,然后用这个数对 HashMap 或者 HashTable 的容量进行取模就行了。没错,其实基本原理就是这个,只不过,在具体实现上,由两个方法 int hash(Objectk) 和 int indexFor(int h, int length) 来实现。但是考虑到效率等问题,HashMap 的实现会稍微复杂一点
- hash:该方法主要是将 Object 转换成一个整型
- indexFor:该方法主要是将 hash 生成的整型转换成链表数组中的下标
- 我们先来做个简单分析。我们知道,hash 方法的功能是根据 Key 来定位这个 K-V 在链表数组中的位置的。也就是 hash 方法的输入应该是个 Object 类型的 Key,输出应该是个 int 类型的数组下标。如果让你设计这个方法,你会怎么做?其实简单,我们只要调用 Object 对象的 hashCode()方法,该方法会返回一个整数,然后用这个数对 HashMap 或者 HashTable 的容量进行取模就行了。没错,其实基本原理就是这个,只不过,在具体实现上,由两个方法 int hash(Objectk) 和 int indexFor(int h, int length) 来实现。但是考虑到效率等问题,HashMap 的实现会稍微复杂一点
- HashMap In Java 7
final int hash(Object k) { int h = hashSeed; if (0 != h && k instanceof String) { return sun.misc.Hashing.stringHash32((String) k); } h ^= k.hashCode(); h ^= (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4); } static int indexFor(int h, int length) { return h & (length-1); }- indexFor 方法其实主要是将 hash 生成的整型转换成链表数组中的下标
- 那么 return h & (length-1);是什么意思呢?其实,他就是取模。Java 之所有使用位运算(&)来代替取模运算(%),最主要的考虑就是效率。位运算(&)效率要比代替取模运算(%)高很多,主要原因是位运算直接对内存数据进行操作,不需要转成十进制,因此处理速度非常快
- 这实现的原理如下:X % 2^n = X & (2^n - 1)。2^n 表示 2 的 n 次方,也就是说,一个数对 2^n 取模 == 一个数和 (2^n - 1) 做按位与运算

- 所以,return h & (length-1);只要保证 length 的长度是 2^n 的话,就可以实现取模运算了。而 HashMap 中的 length 也确实是 2 的倍数,初始值是 16,之后每次扩充为原来的 2 倍
- HashTable In Java 7
- Java 7 中 HashTable 的 hash 方法的实现
private int hash(Object k) { // hashSeed will be zero if alternative hashing is disabled. return hashSeed ^ k.hashCode(); }- 相当于只是对 k 做了个简单的 hash,取了一下其 hashCode。而 HashTable 中也没有 indexOf 方法,取而代之的是这段代码:
int index = (hash & 0x7FFFFFFF) % tab.length;- 也就是说,HashMap 和 HashTable 对于计算数组下标这件事,采用了两种方法。HashMap 采用的是位运算,而 HashTable 采用的是直接取模
- 为啥要把 hash 值和 0x7FFFFFFF 做一次按位与操作呢,主要是为了保证得到的index 的第一位为 0,也就是为了得到一个正数。因为有符号数第一位 0 代表正数,1 代表负数
- 至于为什么要取正数:HashTable 默认的初始大小为 11,之后每次扩充为原来的 2n+1。也就是说,HashTable 的链表数组的默认大小是一个素数、奇数。之后的每次扩充结果也都是奇数。由于 HashTable 会尽量使用素数、奇数作为容量的大小。当哈希表的大小为素数时,简单的取模哈希的结果会更加均匀。原理
- 关于 HashMap 和 HashTable 中对于 hash 的实现总结
- HashMap 默认的初始化大小为 16,之后每次扩充为原来的 2 倍
- HashTable 默认的初始大小为 11,之后每次扩充为原来的 2n+1
- 当哈希表的大小为素数时,简单的取模哈希的结果会更加均匀,所以单从这一点上看,HashTable 的哈希表大小选择,似乎更高明些。因为 hash 结果越分散效果越好
- 在取模计算时,如果模数是 2 的幂,那么我们可以直接使用位运算来得到结果,效率要大大高于做除法。所以从 hash 计算的效率上,又是 HashMap 更胜一筹
- 但是,HashMap 为了提高效率使用位运算代替哈希,这又引入了哈希分布不均匀的问题,所以 HashMap 为解决这问题,又对 hash 算法做了一些改进,进行了扰动计算
- Java 7 中 HashTable 的 hash 方法的实现
- ConcurrentHashMap In Java 7
- ConcurrentHashMap 的 hash
private int hash(Object k) { int h = hashSeed; if ((0 != h) && (k instanceof String)) { return sun.misc.Hashing.stringHash32((String) k); } h ^= k.hashCode(); // Spread bits to regularize both segment and index locations, // using variant of single-word Wang/Jenkins hash. h += (h << 15) ^ 0xffffcd7d; h ^= (h >>> 10); h += (h << 3); h ^= (h >>> 6); h += (h << 2) + (h << 14); return h ^ (h >>> 16); } int j = (hash >>> segmentShift) & segmentMask;- ConcurrentHashMap 的 hash 实现其实和 HashMap 如出一辙。都是通过位运算代替取模,然后再对hashcode进行扰动。区别在于,ConcurrentHashMap 使用了一种变种的 Wang/Jenkins 哈希算法,其主要目的也是为了把高位和低位组合在一起,避免发生冲突
- ConcurrentHashMap 的 hash
- HashMap In Java 8
- 介绍
- 在 Java 8 之前,HashMap 和其他基于 map 的类都是通过链地址法解决冲突,它们使用单向链表来存储相同索引值的元素。在最坏的情况下,这种方式会将 HashMap 的get 方法的性能从 O(1)降低到 O(n)。为了解决在频繁冲突时 hashmap 性能降低的问题,Java 8 中使用平衡树来替代链表存储冲突的元素。这意味着我们可以将最坏情况下的性能从 O(n)提高到 O(logn)。如果恶意程序知道我们用的是 Hash 算法,则在纯链表情况下,它能够发送大量请求导致哈希碰撞,然后不停访问这些 key 导致 HashMap 忙于进行线性查找,最终陷入瘫痪,即形成了拒绝服务攻击(DoS)
- hash
- 关于 Java 8 中的 hash 函数,原理和 Java 7 中基本类似。Java 8 中这一步做了优化,只做一次 16 位右位移异或混合,而不是四次,但原理是不变的
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }
- 关于 Java 8 中的 hash 函数,原理和 Java 7 中基本类似。Java 8 中这一步做了优化,只做一次 16 位右位移异或混合,而不是四次,但原理是不变的
- 介绍
- HashTable In Java 8
- 在 Java 8 的 HashTable 中,已经不在有 hash 方法了。但是哈希的操作还是在的
int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF) % tab.length;
- 在 Java 8 的 HashTable 中,已经不在有 hash 方法了。但是哈希的操作还是在的
- ConcurrentHashMap In Java 8
- Java 8 里面的求 hash 的方法从 hash 改为了 spread
static final int spread(int h) { return (h ^ (h >>> 16)) & HASH_BITS; } - Java 8 的 ConcurrentHashMap 同样是通过 Key 的哈希值与数组长度取模确定该 Key 在数组中的索引。同样为了避免不太好的 Key 的 hashCode 设计,它通过如下方法计算得到 Key 的最终哈希值。不同的是,Java 8 的 ConcurrentHashMap 作者认为引入红黑树后,即使哈希冲突比较严重,寻址效率也足够高,所以作者并未在哈希值的计算上做过多设计,只是将 Key 的 hashCode 值与其高 16 位作异或并保证最高位为 0(从而保证最终结果为正整数)
- Java 8 里面的求 hash 的方法从 hash 改为了 spread
- 相关好文
- 介绍
- 哈希
- 为什么 HashMap 的默认容量设置成 16
- 什么是容量
- 在 Java 中,保存数据有两种比较简单的数据结构:数组和链表。数组的特点是:寻址容易,插入和删除困难;而链表的特点是:寻址困难,插入和删除容易。HashMap 就是将数组和链表组合在一起,发挥了两者的优势,我们可以将其理解为链表的数组。在 HashMap 中,有两个比较容易混淆的关键字段:size 和 capacity ,这其中capacity 就是 Map 的容量,而 size 我们称之为 Map 中的元素个数。简单打个比方你就更容易理解了:HashMap 就是一个“桶”,那么容量(capacity)就是这个桶当前最多可以装多少元素,而元素个数(size)表示这个桶已经装了多少元素

- 在 Java 中,保存数据有两种比较简单的数据结构:数组和链表。数组的特点是:寻址容易,插入和删除困难;而链表的特点是:寻址困难,插入和删除容易。HashMap 就是将数组和链表组合在一起,发挥了两者的优势,我们可以将其理解为链表的数组。在 HashMap 中,有两个比较容易混淆的关键字段:size 和 capacity ,这其中capacity 就是 Map 的容量,而 size 我们称之为 Map 中的元素个数。简单打个比方你就更容易理解了:HashMap 就是一个“桶”,那么容量(capacity)就是这个桶当前最多可以装多少元素,而元素个数(size)表示这个桶已经装了多少元素
- 容量与哈希
- 容量就是一个 HashMap 中"桶"的个数,那么,当我们想要往一个 HashMap 中 put 一个元素的时候,需要通过一定的算法计算出应该把他放到哪个桶中,这个过程就叫做哈希(hash)

- 容量就是一个 HashMap 中"桶"的个数,那么,当我们想要往一个 HashMap 中 put 一个元素的时候,需要通过一定的算法计算出应该把他放到哪个桶中,这个过程就叫做哈希(hash)
- hash 的实现
- 参考 全网把 Map 中的 hash() 分析的最透彻的文章,别无二家。
- 具体实现上,由两个方法 int hash(Object k) 和 int indexFor(int h, int length) 来实现
- hash:该方法主要是将 Object 转换成一个整型
- indexFor:该方法主要是将 hash 生成的整型转换成链表数组中的下标
- indexFor 方法
static int indexFor(int h, int length) { return h & (length-1); }- indexFor 方法其实主要是将 hashcode 换成链表数组中的下标。其中的两个参数 h 表示元素的 hashcode 值,length 表示 HashMap 的容量
- return h & (length-1) 就是取模。Java 之所有使用位运算(&)来代替取模运算(%),最主要的考虑就是效率。位运算(&)效率要比代替取模运算(%)高很多,主要原因是位运算直接对内存数据进行操作,不需要转成十进制,因此处理速度非常快
- 为什么可以使用位运算(&)来实现取模运算(%)呢?这实现的原理如下:X % 2^n = X & (2^n – 1)
- 假设 n 为 3,则 2^3 = 8,表示成 2 进制就是 1000。2^3 -1 = 7 ,即 0111。此时 X & (2^3 – 1) 就相当于取 X 的 2 进制的最后三位数。从 2 进制角度来看,X / 8 相当于 X >> 3,即把 X 右移 3 位,此时得到了 X / 8 的商,而被移掉的部分(后三位),则是 X % 8,也就是余数。上面的解释不知道你有没有看懂,没看懂的话其实也没关系,你只需要记住这个技巧就可以了

- 假设 n 为 3,则 2^3 = 8,表示成 2 进制就是 1000。2^3 -1 = 7 ,即 0111。此时 X & (2^3 – 1) 就相当于取 X 的 2 进制的最后三位数。从 2 进制角度来看,X / 8 相当于 X >> 3,即把 X 右移 3 位,此时得到了 X / 8 的商,而被移掉的部分(后三位),则是 X % 8,也就是余数。上面的解释不知道你有没有看懂,没看懂的话其实也没关系,你只需要记住这个技巧就可以了
- 所以,return h & (length-1);只要保证 length 的长度是 2^n 的话,就可以实现取模运算了
- 指定容量初始化
- 当我们通过 HashMap(int initialCapacity) 设置初始容量的时候,HashMap 并不一定会直接采用我们传入的数值,而是经过计算,得到一个新值,目的是提高 hash 的效率。(1->1、3->4、7->8、9->16)
- 在 JDK 1.7 和 JDK 1.8 中,HashMap 初始化这个容量的时机不同。JDK 1.8 中,在调用 HashMap 的构造函数定义 HashMap 的时候,就会进行容量的设定。而在 JDK 1.7 中,要等到第一次 put 操作时才进行这一操作
- 扩容
- 除了初始化的时候回指定 HashMap 的容量,在进行扩容的时候,其容量也可能会改变。HashMap 有扩容机制,就是当达到扩容条件时会进行扩容。HashMap 的扩容条件就是当 HashMap 中的元素个数(size)超过临界值(threshold)时就会自动扩容
- 在 HashMap 中,threshold = loadFactor * capacity。loadFactor 是装载因子,表示 HashMap 满的程度,默认值为 0.75f,设置成 0.75 有一个好处,那就是 0.75 正好是 3/4,而 capacity 又是 2 的幂。所以,两个数的乘积都是整数。对于一个默认的 HashMap 来说,默认情况下,当其 size 大于 12(16*0.75) 时就会触发扩容
- 下面是 HashMap 中的扩容方法(resize)中的一段:
if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) newThr = oldThr << 1; // double threshold } - 从上面代码可以看出,扩容后的 table 大小变为原来的两倍,这一步执行之后,就会进行扩容后 table 的调整,这部分非本文重点,省略。可见,当 HashMap 中的元素个数(size)超过临界值(threshold)时就会自动扩容,扩容成原容量的 2 倍,即从 16 扩容到 32、64、128 … 所以,通过保证初始化容量均为 2 的幂,并且扩容时也是扩容到之前容量的 2 倍,所以,保证了 HashMap 的容量永远都是 2 的幂
- 总结
- HashMap 作为一种数据结构,元素在 put 的过程中需要进行 hash 运算,目的是计算出该元素存放在 hashMap 中的具体位置
- hash 运算的过程其实就是对目标元素的 Key 进行 hashcode,再对 Map 的容量进行取模,而 JDK 的工程师为了提升取模的效率,使用位运算代替了取模运算,这就要求Map 的容量一定得是 2 的幂。而作为默认容量,太大和太小都不合适,所以 16 就作为一个比较合适的经验值被采用了
- 为了保证任何情况下 Map 的容量都是 2 的幂,HashMap 在两个地方都做了限制。首先是,如果用户制定了初始容量,那么 HashMap 会计算出比该数大的第一个 2 的幂作为初始容量。另外,在扩容的时候,也是进行成倍的扩容,即 4 变成 8,8 变成 16
- 什么是容量
- 为什么建议设置 HashMap 的初始容量,设置多少合适
return (int) ((float) expectedSize / 0.75F + 1.0F); - Java 8 中 stream 相关用法
- Stream 介绍
- Stream 使用一种类似用 SQL 语句从数据库查询数据的直观方式来提供一种对 Java 集合运算和表达的高阶抽象
- Stream 有以下特性及优点:
- 无存储。Stream 不是一种数据结构,它只是某种数据源的一个视图,数据源可以是一个数组,Java 容器或 I/O channel 等
- 为函数式编程而生。对 Stream 的任何修改都不会修改背后的数据源,比如对 Stream 执行过滤操作并不会删除被过滤的元素,而是会产生一个不包含被过滤元素的新 Stream
- 惰式执行。Stream 上的操作并不会立即执行,只有等到用户真正需要结果的时候才会执行
- 可消费性。Stream 只能被“消费”一次,一旦遍历过就会失效,就像容器的迭代器那样,想要再次遍历必须重新生成
- 对于流的处理,主要有三种关键性操作:分别是流的创建、中间操作(intermediate operation)以及最终操作(terminal operation)
- Stream 的创建
- 通过已有的集合来创建流
List<String> strings = Arrays.asList("Hollis", "HollisChuang", "hollis", "Hello", "HelloWorld", "Hollis"); Stream<String> stream = strings.stream(); - 通过 Stream 创建流
Stream<String> stream = Stream.of("Hollis", "HollisChuang", "hollis", "Hello", "HelloWorld", "Hollis");
- 通过已有的集合来创建流
- Stream 中间操作
- filter:filter 方法用于通过设置的条件过滤出元素
List<String> strings = Arrays.asList("Hollis", "", "HollisChuang", "H", "hollis"); strings.stream().filter(string -> !string.isEmpty()).forEach(System.out::println); // 输出:Hollis, , HollisChuang, H, hollis - map:map 方法用于映射每个元素到对应的结果
List<Integer> numbers = Arrays.asList(3, 2, 2, 3, 7, 3, 5); numbers.stream().map( i -> i*i).forEach(System.out::println); // 输出:9,4,4,9,49,9,25 - limit/skip:limit 返回 Stream 的前面 n 个元素;skip 则是扔掉前 n 个元素
List<Integer> numbers = Arrays.asList(3, 2, 2, 3, 7, 3, 5); numbers.stream().limit(4).forEach(System.out::println); // 输出:3,2,2,3 - sorted:sorted 方法用于对流进行排序
List<Integer> numbers = Arrays.asList(3, 2, 2, 3, 7, 3, 5); numbers.stream().sorted().forEach(System.out::println); // 输出:2,2,3,3,3,5,7 - distinct:distinct 主要用来去重
List<Integer> numbers = Arrays.asList(3, 2, 2, 3, 7, 3, 5); numbers.stream().distinct().forEach(System.out::println); // 输出:3,2,7,5 - 综合
List<String> strings = Arrays.asList("Hollis", "HollisChuang", "hollis", "Hello", "HelloWorld", "Hollis"); Stream s = strings.stream().filter(string -> string.length()<= 6).map(String::length).sorted().limit(3).distinct(); ```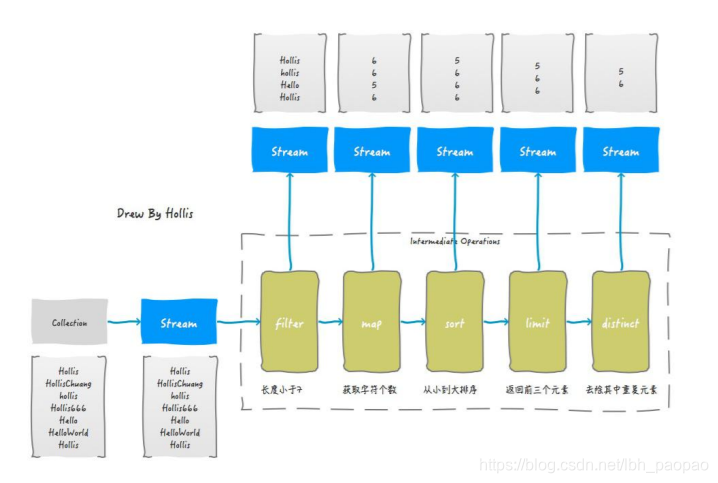
- filter:filter 方法用于通过设置的条件过滤出元素
- Stream 最终操作
- forEach:Stream 提供了方法 ‘forEach’ 来迭代流中的每个数据
Random random = new Random(); random.ints().limit(10).forEach(System.out::println); - count:count 用来统计流中的元素个数
List<String> strings = Arrays.asList("Hollis", "HollisChuang", "hollis","Hollis666", "Hello", "HelloWorld", "Hollis"); System.out.println(strings.stream().count()); // 输出:7 - collect:collect 就是一个归约操作,可以接受各种做法作为参数,将流中的元素累积成一个汇总结果
List<String> strings = Arrays.asList("Hollis", "HollisChuang", "hollis","Hollis666", "Hello", "HelloWorld", "Hollis"); strings = strings.stream().filter(string -> string.startsWith("Hollis")).collect(Collectors.toList()); System.out.println(strings); // 输出:Hollis, HollisChuang, Hollis666, Hollis ``` 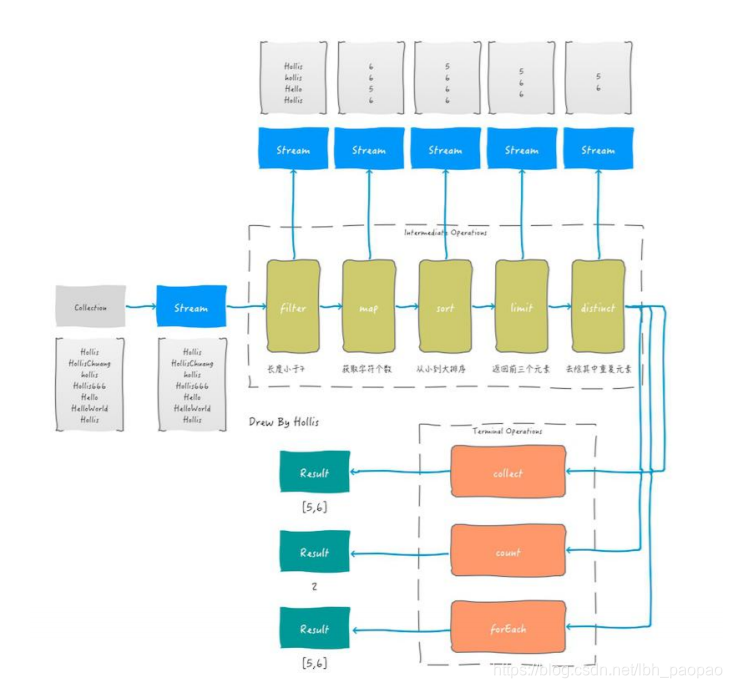
- forEach:Stream 提供了方法 ‘forEach’ 来迭代流中的每个数据
- 总结
- Stream 的创建有两种方式,分别是通过集合类的 stream 方法、通过 Stream 的 of 方法
- Stream 的中间操作可以用来处理 Stream,中间操作的输入和输出都是 Stream,中间操作可以是过滤、转换、排序等
- Stream 的最终操作可以将 Stream 转成其他形式,如计算出流中元素的个数、将流装换成集合、以及元素的遍历等
- Stream 介绍
- Apache 集合处理工具类的使用
- 介绍
- Commons Collections 增强了 Java Collections Framework。 它提供了几个功能,使收集处理变得容易。 它提供了许多新的接口,实现和实用程序。 Commons Collections 的主要功能如下
- Bag - Bag 界面简化了每个对象具有多个副本的集合
- BidiMap - BidiMap 接口提供双向映射,可用于使用值使用键或键查找值
- MapIterator - MapIterator 接口提供简单而容易的迭代迭代
- Transforming Decorators - 转换装饰器可以在将集合添加到集合时更改集合的每个对象
- Composite Collections - 在需要统一处理多个集合的情况下使用复合集合
- Ordered Map - 有序地图保留添加元素的顺序
- Ordered Set - 有序集保留了添加元素的顺序
- Reference map - 参考图允许在密切控制下对键/值进行垃圾收集
- Comparator implementations - 可以使用许多 Comparator 实现
- Iterator implementations - 许多 Iterator 实现都可用
- Adapter Classes - 适配器类可用于将数组和枚举转换为集合
- Utilities - 实用程序可用于测试测试或创建集合的典型集合论属性,例如 union,intersection。 支持关闭
- Commons Collections 增强了 Java Collections Framework。 它提供了几个功能,使收集处理变得容易。 它提供了许多新的接口,实现和实用程序。 Commons Collections 的主要功能如下
- 具体使用略: Commons Collections - 教程
- 介绍
- Arrays.asList 获得的 List 使用时需要注意什么
- asList 得到的只是一个 Arrays 的内部类,一个原来数组的视图 List,因此如果对它进行增删操作会报错
- 用 ArrayList 的构造器可以将其转变成真正的 ArrayList
- Collection 如何迭代
List<String> list = ImmutableList.of("Hollis", "hollischuang"); // 普通 for 循环遍历 for (int i = 0; i < list.size(); i++) { System.out.println(list.get(i)); } //增强 for 循环遍历 for (String s : list) { System.out.println(s); } //Iterator 遍历 Iterator it = list.iterator(); while (it.hasNext()) { System.out.println(it.next()); } //Stream 遍历 list.forEach(System.out::println); list.stream().forEach(System.out::println); - Enumeration 和 Iterator 区别
- 函数接口不同
- Enumeration 只有 2 个函数接口。通过 Enumeration,我们只能读取集合的数据,而不能对数据进行修改
- Iterator 只有 3 个函数接口。Iterator 除了能读取集合的数据之外,也能数据进行删除操作
- Iterator 支持 fail-fast 机制,而 Enumeration 不支持
- Enumeration 是 JDK 1.0 添加的接口。使用到它的函数包括 Vector、Hashtable 等类,这些类都是 JDK 1.0 中加入的,Enumeration 存在的目的就是为它们提供遍历接口。Enumeration 本身并没有支持同步,而在 Vector、Hashtable 实现 Enumeration 时,添加了同步
- Iterator 是 JDK 1.2 才添加的接口,它也是为了 HashMap、ArrayList 等集合提供遍历接口。Iterator 是支持 fail-fast 机制的:当多个线程对同一个集合的内容进行操作时,就可能会产生 fail-fast 事件
- Enumeration 迭代器只能遍历 Vector、Hashtable 这种古老的集合,因此通常不要使用它,除非在某些极端情况下,不得不使用 Enumeration,否则都应该选择 Iterator 迭代器
- 函数接口不同
- fail-fast 和 fail-safe
- 什么是 fail-fast
- 在系统设计中,快速失效系统一种可以立即报告任何可能表明故障的情况的系统。快速失效系统通常设计用于停止正常操作,而不是试图继续可能存在缺陷的过程。这种设计通常会在操作中的多个点检查系统的状态,因此可以及早检测到任何故障。快速失败模块的职责是检测错误,然后让系统的下一个最高级别处理错误
public int divide(int divisor,int dividend){ if(dividend == 0){ throw new RuntimeException("dividend can't be null"); } return divisor/dividend; } - 集合类中的 fail-fast
- 当多个线程对部分集合进行结构上的改变的操作时,有可能会产生 fail-fast 机制,这个时候就会抛出 ConcurrentModificationException(后文用 CME 代替)
- CMException,当方法检测到对象的并发修改,但不允许这种修改时就抛出该异常
- 异常复现
- 在 Java 中, 如果在 foreach 循环里对某些集合元素进行元素的 remove/add 操作的时候,就会触发 fail-fast 机制,进而抛出 CMException
List<String> userNames = new ArrayList<String>() { { add("Hollis"); add("hollis"); add("HollisChuang"); add("H"); } }; for (String userName : userNames) { if (userName.equals("Hollis")) { userNames.remove(userName); } } System.out.println(userNames); - 以上代码,使用增强 for 循环遍历元素,并尝试删除其中的 Hollis 字符串元素。运行以上代码,会抛出以下异常
Exception in thread "main" java.util.ConcurrentModificationException at java.util.ArrayList$Itr.checkForComodification(ArrayList.java:909) at java.util.ArrayList$Itr.next(ArrayList.java:859) at com.hollis.ForEach.main(ForEach.java:22) - foreach:我们使用 jad 工具,对编译后的 class 进行反编译,可以发现,foreach 其实是依赖了 while 循环和 Iterator 实现的
public static void main(String[] args) { // 使用 ImmutableList 初始化一个 List List<String> userNames = new ArrayList<String>() {{ add("Hollis"); add("hollis"); add("HollisChuang"); add("H"); }}; Iterator iterator = userNames.iterator(); do { if(!iterator.hasNext()) break; String userName = (String)iterator.next(); if(userName.equals("Hollis")) userNames.remove(userName); } while(true); System.out.println(userNames); } - 异常原理
- 通过以上代码的异常堆栈,我们可以跟踪到真正抛出异常的代码是:
java.util.ArrayList$Itr.checkForComodification(ArrayList.java:909) - 该方法是在 iterator.next()方法中调用的。我们看下该方法的实现:
final void checkForComodification() { if (modCount != expectedModCount) throw new ConcurrentModificationException(); } - modCount 是 ArrayList 中的一个成员变量,它表示该集合实际被修改的次数。expectedModCount 表示这个迭代器预期该集合被修改的次数。其值随着 Itr 被创建而初始化。只有通过迭代器对集合进行操作,该值才会改变
- remove 方法核心逻辑如下
private void fastRemove(int index) { modCount++; int numMoved = size - index - 1; if (numMoved > 0) System.arraycopy(elementData, index+1, elementData, index, numMoved); elementData[--size] = null; // clear to let GC do its work } ```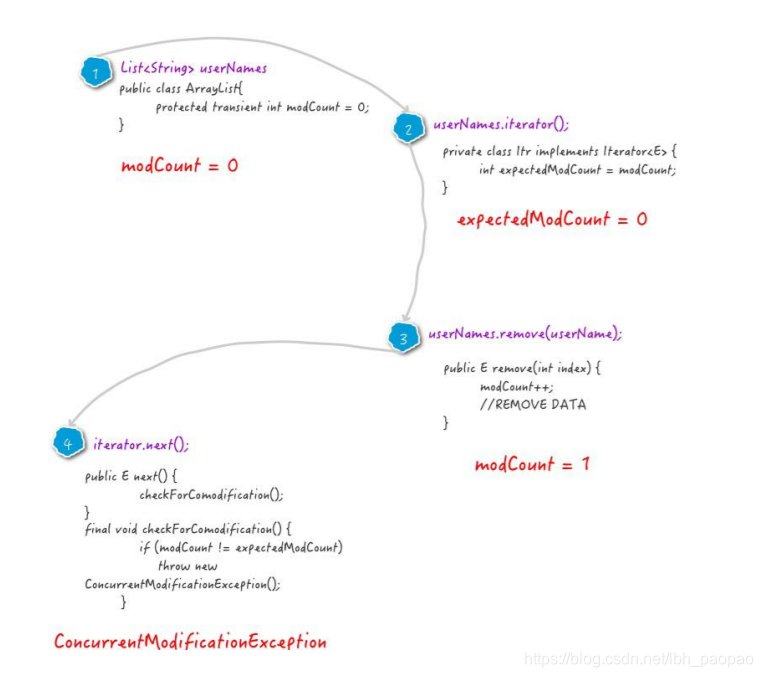
- 通过以上代码的异常堆栈,我们可以跟踪到真正抛出异常的代码是:
- 在 Java 中, 如果在 foreach 循环里对某些集合元素进行元素的 remove/add 操作的时候,就会触发 fail-fast 机制,进而抛出 CMException
- fail-safe
- 为了避免触发 fail-fast 机制,导致异常,我们可以使用 Java 中提供的一些采用了 fail-safe 机制的集合类。这样的集合容器在遍历时不是直接在集合内容上访问的,而是先复制原有集合内容,在拷贝的集合上进行遍历
- java.util.concurrent 包下的容器都是 fail-safe 的,可以在多线程下并发使用,并发修改。同时也可以在 foreach 中进行 add/remove
- fail-safe 集合的所有对集合的修改都是先拷贝一份副本,然后在副本集合上进行的,并不是直接对原集合进行修改。并且这些修改方法,如 add/remove 都是通过加锁来控制并发的。所以,CopyOnWriteArrayList 中的迭代器在迭代的过程中不需要做 fail-fast 的并发检测。(因为 fail-fast 的主要目的就是识别并发,然后通过异常的方式通知用户)但是,虽然基于拷贝内容的优点是避免了 ConcurrentModificationException,但同样地,迭代器并不能访问到修改后的内容
- Copy-On-Write
- Copy-On-Write 简称 COW,是一种用于程序设计中的优化策略。其基本思路是,从一开始大家都在共享同一个内容,当某个人想要修改这个内容的时候,才会真正把内容 Copy 出去形成一个新的内容然后再改,这是一种延时懒惰策略
- CopyOnWrite 容器即写时复制的容器。通俗的理解是当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行 Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器
- CopyOnWriteArrayList 中 add/remove 等写方法是需要加锁的,目的是为了避免 Copy 出 N 个副本出来,导致并发写。但是,CopyOnWriteArrayList 中的读方法是没有加锁的
- 这样做的好处是我们可以对 CopyOnWrite 容器进行并发的读,当然,这里读到的数据可能不是最新的。因为写时复制的思想是通过延时更新的策略来实现数据的最终一致性的,并非强一致性。所以 CopyOnWrite 容器是一种读写分离的思想,读和写不同的容器。而 Vector 在读写的时候使用同一个容器,读写互斥,同时只能做一件事儿
- CopyOnWrite 并发容器用于读多写少的并发场景。比如白名单,黑名单,商品类目的访问和更新场景
- 什么是 fail-fast
- 如何在遍历的同时删除 ArrayList 中的元素
- 直接使用普通 for 循环进行操作
- 普通 for 循环并没有用到 Iterator 的遍历,所以压根就没有进行 fail-fast 的检验,但是这种方案其实存在一个问题,那就是 remove 操作会改变 List 中元素的下标,可能存在漏删的情况
- 直接使用 Iterator 进行操作
- 如果直接使用Iterator提供的remove方法,那么就可以修改到 expectedModCount 的值。那么就不会再抛出异常了
- 使用 Java 8 中提供的 filter 过滤
- Java 8 中可以把集合转换成流,对于流有一种 filter 操作, 可以对原始 Stream 进行某项测试,通过测试的元素被留下来生成一个新 Stream
- 使用增强 for 循环其实也可以
- 如果,我们非常确定在一个集合中,某个即将删除的元素只包含一个的话, 比如对 Set 进行操作,那么其实也是可以使用增强 for 循环的,只要在删除之后,立刻结束循环体,不要再继续进行遍历就可以了
- 直接使用 fail-safe 的集合类
- 直接使用普通 for 循环进行操作
- ConcurrentSkipListMap
- ConcurrentSkipListMap 是一个内部使用跳表,并且支持排序和并发的一个 Map,是线程安全的
- ConcurrentSkipListMap 和 ConcurrentHashMap 的主要区别:
- 底层实现方式不同。ConcurrentSkipListMap 底层基于跳表。ConcurrentHashMap 底层基于 Hash 桶和红黑树
- ConcurrentHashMap 不支持排序。ConcurrentSkipListMap 支持排序
- Collection 和 Collections 区别
-
I/O流
- 字符流、字节流
- 字节与字符
- Bit 最小的二进制单位,是计算机的操作部分。取值 0 或者 1 Byte(字节)是计算机操作数据的最小单位由 8 位 bit 组成。取值为(-128-127)
- Char(字符)是用户的可读写的最小单位,在 Java 里面由 16 位 bit 组成。取值为(0-65535)
- 字节流
- 操作 byte 类型数据,主要操作类是 OutputStream、InputStream 的子类;不用缓冲区,直接对文件本身操作
- 字符流
- 操作字符类型数据,主要操作类是 Reader、Writer 的子类;使用缓冲区缓冲字符,不关闭流就不会输出任何内容
- 互相转换
- 整个 IO 包实际上分为字节流和字符流,但是除了这两个流之外,还存在一组字节流- 字符流的转换类
- OutputStreamWriter:是 Writer 的子类,将输出的字符流变为字节流,即将一个字符流的输出对象变为字节流输出对象
- InputStreamReader:是 Reader 的子类,将输入的字节流变为字符流,即将一个字节流的输入对象变为字符流的输入对象
- 整个 IO 包实际上分为字节流和字符流,但是除了这两个流之外,还存在一组字节流- 字符流的转换类
- 字节与字符
- 输入流、输出流
- 输入、输出,有一个参照物,参照物就是存储数据的介质。如果是把对象读入到介质中,这就是输入。从介质中向外读数据,这就是输出。所以,输入流是把数据写入存储介质的。输出流是从存储介质中把数据读取出来
- 字节流和字符流之间的相互转换
- 介绍
- 想要实现字符流和字节流之间的相互转换需要用到两个类
- OutputStreamWriter 是字符流通向字节流的桥梁
- InputStreamReader 是字节流通向字符流的桥梁
- 想要实现字符流和字节流之间的相互转换需要用到两个类
- 字符流转成字节流
public static void main(String[] args) throws IOException { File f = new File("test.txt"); // OutputStreamWriter 是字符流通向字节流的桥梁,创建了一个字符流通向字节流的对象 OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream(f), "UTF-8"); osw.write("我是字符流转换成字节流输出的"); osw.close(); } - 字节流转成字符流
public static void main(String[] args) throws IOException { File f = new File("test.txt"); InputStreamReader inr = new InputStreamReader(new FileInputStream(f), "UTF-8"); char[] buf = new char[1024]; int len = inr.read(buf); System.out.println(new String(buf,0,len)); inr.close(); }
- 介绍
- 同步、异步
- 同步与异步描述的是被调用者的
- 如 A 调用 B
- 如果是同步,B 在接到 A 的调用后,会立即执行要做的事。A 的本次调用可以得到结果
- 如果是异步,B 在接到 A 的调用后,不保证会立即执行要做的事,但是保证会去做,B 在做好了之后会通知 A。A 的本次调用得不到结果,但是 B 执行完之后会通知 A
- 阻塞、非阻塞
- 阻塞与非阻塞描述的是调用者的
- 如 A 调用 B
- 如果是阻塞,A 在发出调用后,要一直等待,等着 B 返回结果
- 如果是非阻塞,A 在发出调用后,不需要等待,可以去做自己的事情
- 同步,异步 和 阻塞,非阻塞之间的区别
- 同步、异步,是描述被调用方的
- 阻塞,非阻塞,是描述调用方的
- 同步不一定阻塞,异步也不一定非阻塞。没有必然关系
- 举个简单的例子,老张烧水
- 老张把水壶放到火上,一直在水壶旁等着水开。(同步阻塞)
- 老张把水壶放到火上,去客厅看电视,时不时去厨房看看水开没有。(同步非阻塞)
- 老张把响水壶放到火上,一直在水壶旁等着水开。(异步阻塞)
- 老张把响水壶放到火上,去客厅看电视,水壶响之前不再去看它了,响了再去拿壶。(异步非阻塞)
- Linux 5 种 IO 模型
- 阻塞式 IO 模型
- 最传统的一种 IO 模型,即在读写数据过程中会发生阻塞现象。当用户线程发出 IO 请求之后,内核会去查看数据是否就绪,如果没有就绪就会等待数据就绪,而用户线程就会处于阻塞状态,用户线程交出 CPU。当数据就绪之后,内核会将数据拷贝到用户线程,并返回结果给用户线程,用户线程才解除 block 状态
- 典型的阻塞 IO 模型的例子为
data = socket.read(); - 如果数据没有就绪,就会一直阻塞在 read 方法
- 非阻塞 IO 模型
- 当用户线程发起一个 read 操作后,并不需要等待,而是马上就得到了一个结果。如果结果是一个 error 时,它就知道数据还没有准备好,于是它可以再次发送 read 操作。一旦内核中的数据准备好了,并且又再次收到了用户线程的请求,那么它马上就将数据拷贝到了用户线程,然后返回。所以事实上,在非阻塞 IO 模型中,用户线程需要不断地询问内核数据是否就绪,也就说非阻塞 IO 不会交出 CPU,而会一直占用 CPU
- 典型的非阻塞 IO 模型一般如下
while(true){ data = socket.read(); if(data!= error){ 处理数据 break; } } - 但是对于非阻塞 IO 就有一个非常严重的问题,在 while 循环中需要不断地去询问内核数据是否就绪,这样会导致 CPU 占用率非常高,因此一般情况下很少使用 while 循环这种方式来读取数据
- IO 复用模型
- 多路复用 IO 模型是目前使用得比较多的模型。Java NIO 实际上就是多路复用 IO。在多路复用 IO 模型中,会有一个线程不断去轮询多个 socket 的状态,只有当socket 真正有读写事件时,才真正调用实际的 IO 读写操作。因为在多路复用 IO 模型中,只需要使用一个线程就可以管理多个 socket,系统不需要建立新的进程或者线程,也不必维护这些线程和进程,并且只有在真正有 socket 读写事件进行时,才会使用 IO 资源,所以它大大减少了资源占用
- 在 Java NIO 中,是通过 selector.select() 去查询每个通道是否有到达事件,如果没有事件,则一直阻塞在那里,因此这种方式会导致用户线程的阻塞。也许有朋友会说,我可以采用多线程 + 阻塞 IO 达到类似的效果,但是由于在多线程 + 阻塞 IO 中,每个 socket 对应一个线程,这样会造成很大的资源占用,并且尤其是对于长连接来说,线程的资源一直不会释放,如果后面陆续有很多连接的话,就会造成性能上的瓶颈
- 而多路复用 IO 模式,通过一个线程就可以管理多个 socket,只有当 socket 真正有读写事件发生才会占用资源来进行实际的读写操作。因此,多路复用 IO 比较适合连接数比较多的情况。另外多路复用 IO 为何比非阻塞 IO 模型的效率高是因为,在非阻塞 IO 中,不断地询问 socket 状态时通过用户线程去进行的,而在多路复用 IO 中,轮询每个 socket 状态是内核在进行的,这个效率要比用户线程要高的多
- 不过要注意的是,多路复用 IO 模型是通过轮询的方式来检测是否有事件到达,并且对到达的事件逐一进行响应。因此对于多路复用 IO 模型来说,一旦事件响应体很大,那么就会导致后续的事件迟迟得不到处理,并且会影响新的事件轮询
- 信号驱动 IO 模型
- 在信号驱动 IO 模型中,当用户线程发起一个 IO 请求操作,会给对应的 socket 注册一个信号函数,然后用户线程会继续执行,当内核数据就绪时会发送一个信号给用户线程,用户线程接收到信号之后,便在信号函数中调用 IO 读写操作来进行实际的 IO 请求操作
- 异步 IO 模型
- 异步 IO 模型是比较理想的 IO 模型,在异步 IO 模型中,当用户线程发起 read 操作之后,立刻就可以开始去做其它的事。而另一方面,从内核的角度,当它受到一个 asynchronous read 之后,它会立刻返回,说明 read 请求已经成功发起了,因此不会对用户线程产生任何 block。然后,内核会等待数据准备完成,然后将数据拷贝到用户线程,当这一切都完成之后,内核会给用户线程发送一个信号,告诉它 read 操作完成了
- 也就说用户线程完全不需要实际的整个 IO 操作是如何进行的,只需要先发起一个请求,当接收内核返回的成功信号时表示 IO 操作已经完成,可以直接去使用数据了。也就说在异步 IO 模型中,IO 操作的两个阶段都不会阻塞用户线程,这两个阶段都是由内核自动完成,然后发送一个信号告知用户线程操作已完成。用户线程中不需要再次调用 IO 函数进行具体的读写。这点是和信号驱动模型有所不同的,在信号驱动模型中,当用户线程接收到信号表示数据已经就绪,然后需要用户线程调用 IO 函数进行实际的读写操作;而在异步 IO 模型中,收到信号表示 IO 操作已经完成,不需要再在用户线程中调用 iO 函数进行实际的读写操作。注意,异步 IO 是需要操作系统的底层支持,在 Java 7 中,提供了 Asynchronous IO
- 前面四种 IO 模型实际上都属于同步 IO,只有最后一种是真正的异步 IO,因为无论是多路复用 IO 还是信号驱动模型,IO 操作的第 2 个阶段都会引起用户线程阻塞,也就是内核进行数据拷贝的过程都会让用户线程阻塞
- 阻塞式 IO 模型
- BIO、NIO 和 AIO 的区别、三种 IO 的用法与原理
- IO
- 什么是 IO? 它是指计算机与外部世界或者一个程序与计算机的其余部分的之间的接口。它对于任何计算机系统都非常关键,因而所有 I/O 的主体实际上是内置在操作系统中的。单独的程序一般是让系统为它们完成大部分的工作。在 Java 编程中,直到最近一直使用 流 的方式完成 I/O。所有 I/O 都被视为单个的字节的移动,通过一个称为 Stream 的对象一次移动一个字节。流 I/O 用于与外部世界接触。它也在内部使用,用于将对象转换为字节,然后再转换回对象
- BIO
- Java BIO 即 Block I/O,同步并阻塞的 IO。BIO 就是传统的 java.io 包下面的代码实现
- NIO
- 什么是NIO? NIO 与原来的 I/O 有同样的作用和目的,他们之间最重要的区别是数据打包和传输的方式。原来的 I/O 以流的方式处理数据,而 NIO 以块的方式处理数据。面向流 的 I/O 系统一次一个字节地处理数据。一个输入流产生一个字节的数据,一个输出流消费一个字节的数据。为流式数据创建过滤器非常容易。链接几个过滤器,以便每个过滤器只负责单个复杂处理机制的一部分,这样也是相对简单的。不利的一面是,面向流的I/O 通常相当慢。一个 面向块 的 I/O 系统以块的形式处理数据。每一个操作都在一步中产生或者消费一个数据块。按块处理数据比按(流式的)字节处理数据要快得多。但是面向块的 I/O 缺少一些面向流的 I/O 所具有的优雅性和简单性
- AIO
- Java AIO 即 Async 非阻塞,是异步非阻塞的 IO
- 区别及联系
- BIO (Blocking I/O):同步阻塞 I/O 模式,数据的读取写入必须阻塞在一个线程内等待其完成。这里假设一个烧开水的场景,有一排水壶在烧开水,BIO 的工作模式就是,叫一个线程停留在一个水壶那,直到这个水壶烧开,才去处理下一个水壶。但是实际上线程在等待水壶烧开的时间段什么都没有做
- NIO (New I/O):同时支持阻塞与非阻塞模式,但这里我们以其同步非阻塞 I/O 模式来说明,那么什么叫做同步非阻塞?如果还拿烧开水来说,NIO 的做法是叫一个线程不断的轮询每个水壶的状态,看看是否有水壶的状态发生了改变,从而进行下一步的操作
- AIO ( Asynchronous I/O):异步非阻塞 I/O 模型。异步非阻塞与同步非阻塞的区别在哪里?异步非阻塞无需一个线程去轮询所有 IO 操作的状态改变,在相应的状态改变后,系统会通知对应的线程来处理。对应到烧开水中就是,为每个水壶上面装了一个开关,水烧开之后,水壶会自动通知我水烧开了
- 各自适用场景
- BIO 方式适用于连接数目比较小且固定的架构,这种方式对服务器资源要求比较高,并发局限于应用中,JDK1.4 以前的唯一选择,但程序直观简单易理解
- NIO 方式适用于连接数目多且连接比较短(轻操作)的架构,比如聊天服务器,并发局限于应用中,编程比较复杂,JDK1.4 开始支持
- AIO 方式适用于连接数目多且连接比较长(重操作)的架构,比如相册服务器,充分调用 OS 参与并发操作,编程比较复杂,JDK7 开始支持
- 使用方式
- 使用 BIO 实现文件的读取和写入
// Initializes The Object User1 user = new User1(); user.setName("hollis"); user.setAge(23); System.out.println(user); // Write Obj to File ObjectOutputStream oos = null; try { oos = new ObjectOutputStream(new FileOutputStream("tempFile")); oos.writeObject(user); } catch (IOException e) { e.printStackTrace(); } finally { IOUtils.closeQuietly(oos); } // Read Obj from File File file = new File("tempFile"); ObjectInputStream ois = null; try { ois = new ObjectInputStream(new FileInputStream(file)); User1 newUser = (User1) ois.readObject(); System.out.println(newUser); } catch (IOException e) { e.printStackTrace(); } catch (ClassNotFoundException e) { e.printStackTrace(); } finally { IOUtils.closeQuietly(ois); try { FileUtils.forceDelete(file); } catch (IOException e) { e.printStackTrace(); } } - 使用 NIO 实现文件的读取和写入
static void readNIO() { String pathname = "C:\\Users\\adew\\Desktop\\jd-gui.cfg"; FileInputStream fin = null; try { fin = new FileInputStream(new File(pathname)); FileChannel channel = fin.getChannel(); int capacity = 100;// 字节 ByteBuffer bf = ByteBuffer.allocate(capacity); System.out.println("限制是:" + bf.limit() + "容量是:" + bf.capacity() + "位置是:" + bf.position()); int length = -1; while ((length = channel.read(bf)) != -1) { /* * 注意,读取后,将位置置为 0,将 limit 置为容量, 以备下次读入到字节缓冲中, 从 0 开始存储 */ bf.clear(); byte[] bytes = bf.array(); System.out.write(bytes, 0, length); System.out.println(); System.out.println("限制是:" + bf.limit() + "容量是:" + bf.capacity()+ "位置是:" + bf.position()); } channel.close(); } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } finally { if (fin != null) { try { fin.close(); } catch (IOException e) { e.printStackTrace(); } } } } static void writeNIO() { String filename = "out.txt"; FileOutputStream fos = null; try { fos = new FileOutputStream(new File(filename)); FileChannel channel = fos.getChannel(); ByteBuffer src = Charset.forName("utf8").encode("你好你好你好你好你好"); // 字节缓冲的容量和 limit 会随着数据长度变化,不是固定不变的 System.out.println("初始化容量和 limit:" + src.capacity() + "," + src.limit()); int length = 0; while ((length = channel.write(src)) != 0) { /* * 注意,这里不需要 clear,将缓冲中的数据写入到通道中后 第二次接着上一次 的顺序往下读 */ System.out.println("写入长度:" + length); } } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } finally { if (fos != null) { try { fos.close(); } catch (IOException e) { e.printStackTrace(); } } } } - 使用 AIO 实现文件的读取和写入
public class ReadFromFile { public static void main(String[] args) throws Exception { Path file = Paths.get("/usr/a.txt"); AsynchronousFileChannel channel = AsynchronousFileChannel.open(file); ByteBuffer buffer = ByteBuffer.allocate(100_000); Future<Integer> result = channel.read(buffer, 0); while (!result.isDone()) { ProfitCalculator.calculateTax(); } Integer bytesRead = result.get(); System.out.println("Bytes read [" + bytesRead + "]"); } } class ProfitCalculator { public ProfitCalculator() { } public static void calculateTax() { } } public class WriteToFile { public static void main(String[] args) throws Exception { AsynchronousFileChannel fileChannel = AsynchronousFileChannel.open(Paths.get("/asynchronous.txt"), StandardOpenOption.READ, StandardOpenOption.WRITE, StandardOpenOption.CREATE); CompletionHandler<Integer, Object> handler = new CompletionHandler<Integer, Object>() { @Override public void completed(Integer result, Object attachment) { System.out.println("Attachment: " + attachment + " " + result + " bytes written"); System.out.println("CompletionHandler Thread ID: " + Thread.currentThread().getId()); } @Override public void failed(Throwable e, Object attachment) { System.err.println("Attachment: " + attachment + " failed with:"); e.printStackTrace(); } }; System.out.println("Main Thread ID: " + Thread.currentThread().getId()); fileChannel.write(ByteBuffer.wrap("Sample".getBytes()), 0, "First Write",handler); fileChannel.write(ByteBuffer.wrap("Box".getBytes()), 0, "Second Write",handler); } }
- 使用 BIO 实现文件的读取和写入
- IO
- netty
- Netty 是一个非阻塞 I/O 客户端-服务器框架,主要用于开发 Java 网络应用程序,如协议服务器和客户端。异步事件驱动的网络应用程序框架和工具用于简化网络编程,例如 TCP 和 UDP 套接字服务器。Netty 包括了反应器编程模式的实现。Netty 最初由 JBoss 开发,现在由 Netty 项目社区开发和维护
- 除了作为异步网络应用程序框架,Netty 还包括了对 HTTP、HTTP2、DNS 及其他协议的支持,涵盖了在 Servlet 容器内运行的能力、对 WebSockets 的支持、与 Google Protocol Buffers 的集成、对 SSL/TLS 的支持以及对用于 SPDY 协议和消息压缩的支持。自 2004 年以来,Netty 一直在被积极开发
- 从版本 4.0.0 开始,Netty 在支持 NIO 和阻塞 Java 套接字的同时,还支持使用 NIO. 2 作为后端
- 本质:JBoss 做的一个 Jar 包
- 目的:快速开发高性能、高可靠性的网络服务器和客户端程序
- 优点:提供异步的、事件驱动的网络应用程序框架和工具
- 字符流、字节流
-
反射
- 反射
- 反射机制指的是程序在运行时能够获取自身的信息。在 java 中,只要给定类的名字,那么就可以通过反射机制来获得类的所有属性和方法
- 反射有什么作用
- 在运行时判断任意一个对象所属的类
- 在运行时判断任意一个类所具有的成员变量和方法
- 在运行时任意调用一个对象的方法
- 在运行时构造任意一个类的对象
- Class 类
- Java 的 Class 类是 java 反射机制的基础,通过 Class 类我们可以获得关于一个类的相关信息
- Java.lang.Class 是一个比较特殊的类,它用于封装被装入到 JVM 中的类(包括类和接口)的信息。当一个类或接口被装入的 JVM 时便会产生一个与之关联的 java.lang.Class 对象,可以通过这个 Class 对象对被装入类的详细信息进行访问
- 虚拟机为每种类型管理一个独一无二的 Class 对象。也就是说,每个类(型)都有一个 Class 对象。运行程序时,Java 虚拟机(JVM)首先检查是否所要加载的类对应的Class 对象是否已经加载。如果没有加载,JVM 就会根据类名查找.class 文件,并将其Class 对象载入
- 反射与工厂模式实现 Spring IOC
-
反射机制概念
- 我们考虑一个场景,如果我们在程序运行时,一个对象想要检视自己所拥有的成员属性,该如何操作?再考虑另一个场景,如果我们想要在运行期获得某个类的 Class 信息如它的属性、构造方法、一般方法后再考虑是否创建它的对象,这种情况该怎么办呢?这就需要用到反射!我们.java 文件在编译后会变成.class 文件,这就像是个镜面,本身是.java,在镜中是.class,他们其实是一样的;那么同理,我们看到镜子的反射是.class,就能通过反编译,了解到.java 文件的本来面目。对于反射,官方给出的概念:反射是 Java 语言的一个特性,它允许程序在运行时(注意不是编译的时候)来进行自我检查并且对内部的成员进行操作。例如它允许一个 Java 类获取它所有的成员变量和方法并且显示出来。反射主要是指程序可以访问,检测和修改它本身状态或行为的一种能力,并能根据自身行为的状态和结果,调整或修改应用所描述行为的状态和相关的语义。在 Java 中,只要给定类的名字,那么就可以通过反射机制来获得类的所有信息。反射是 Java 中一种强大的工具,能够使我们很方便的创建灵活的代码,这些代码可以再运行时装配,无需在组件之间进行源代码链接。但是反射使用不当会成本很高!类中有什么信息,利用反射机制就能可以获得什么信息,不过前提是得知道类的名字
-
反射机制的作用
- 在运行时判断任意一个对象所属的类
- 在运行时获取类的对象
- 在运行时访问 java 对象的属性,方法,构造方法等
- 首先要搞清楚为什么要用反射机制?直接创建对象不就可以了吗,这就涉及到了动态与静态的概念
- 静态编译:在编译时确定类型,绑定对象,即通过
- 动态编译:运行时确定类型,绑定对象。动态编译最大限度发挥了 Java 的灵活性,体现了多态的应用,有以降低类之间的藕合性
-
反射机制的优缺点
- 反射机制的优点:可以实现动态创建对象和编译,体现出很大的灵活性(特别是在 J2EE 的开发中它的灵活性就表现的十分明显)。通过反射机制我们可以获得类的各种内容,进行反编译。对于 JAVA 这种先编译再运行的语言来说,反射机制可以使代码更加灵活,更加容易实现面向对象
- 比如,一个大型的软件,不可能一次就把把它设计得很完美,把这个程序编译后,发布了,当发现需要更新某些功能时,我们不可能要用户把以前的卸载,再重新安装新的版本,假如这样的话,这个软件肯定是没有多少人用的。采用静态的话,需要把整个程序重新编译一次才可以实现功能的更新,而采用反射机制的话,它就可以不用卸载,只需要在运行时动态地创建和编译,就可以实现该功能
- 反射机制的缺点:对性能有影响。使用反射基本上是一种解释操作,我们可以告诉 JVM,我们希望做什么并且让它满足我们的要求。这类操作总是慢于直接执行相同的操作
-
反射与工厂模式实现 IOC
-
Spring 中的 IoC 的实现原理就是工厂模式加反射机制
-
我们首先看一下不用反射机制时的工厂模式
interface fruit { public abstract void eat(); } class Apple implements fruit{ public void eat(){ System.out.println("Apple"); } } class Orange implements fruit{ public void eat(){ System.out.println("Orange"); } } //构造工厂类 //也就是说以后如果我们在添加其他的实例的时候只需要修改工厂类就行了 class Factory{ public static fruit getInstance(String fruitName){ fruit f=null; if("Apple".equals(fruitName)){ f=new Apple(); } if("Orange".equals(fruitName)){ f=new Orange(); } return f; } } class hello{ public static void main(String[] a){ fruit f=Factory.getInstance("Orange"); f.eat(); } } -
下面用反射机制实现工厂模式
interface fruit { public abstract void eat(); } class Apple implements fruit{ public void eat(){ System.out.println("Apple"); } } class Orange implements fruit{ public void eat(){ System.out.println("Orange"); } } class Factory{ public static fruit getInstance(String ClassName){ fruit f=null; try{ f=(fruit)Class.forName(ClassName).newInstance(); }catch (Exception e) { e.printStackTrace(); } return f; } } class hello{ public static void main(String[] a){ fruit f=Factory.getInstance("Reflect.Apple"); if(f!=null){ f.eat(); } } } -
下面编写使用反射机制并结合属性文件的工厂模式(即 IoC)
apple=Reflect.Apple orange=Reflect.Orangeinterface fruit { public abstract void eat(); } class Apple implements fruit{ public void eat(){ System.out.println("Apple"); } } class Orange implements fruit{ public void eat(){ System.out.println("Orange"); } } //操作属性文件类 class init{ public static Properties getPro() throws FileNotFoundException, IOException{ Properties pro=new Properties(); File f=new File("fruit.properties"); if(f.exists()){ pro.load(new FileInputStream(f)); }else{ pro.setProperty("apple", "Reflect.Apple"); pro.setProperty("orange", "Reflect.Orange"); pro.store(new FileOutputStream(f), "FRUIT CLASS"); } return pro; } } class Factory{ public static fruit getInstance(String ClassName){ fruit f=null; try{ f=(fruit)Class.forName(ClassName).newInstance(); }catch (Exception e) { e.printStackTrace(); } return f; } } class hello{ public static void main(String[] a) throws FileNotFoundException, IOException{ Properties pro=init.getPro(); fruit f=Factory.getInstance(pro.getProperty("apple")); if(f!=null){ f.eat(); } } }
-
-
IOC 容器的技术剖析
- IOC 中最基本的技术就是“反射(Reflection)”编程,通俗来讲就是根据给出的类名(字符串方式)来动态地生成对象,这种编程方式可以让对象在生成时才被决定到底是哪一种对象。只是在 Spring 中要生产的对象都在配置文件中给出定义,目的就是提高灵活性和可维护性
- 目前 C#、Java 和 PHP5 等语言均支持反射,其中 PHP5 的技术书籍中,有时候也被翻译成“映射”。有关反射的概念和用法,大家应该都很清楚。反射的应用是很广泛的,很多的成熟的框架,比如像 Java 中的 Hibernate、Spring 框架,.Net 中 NHibernate、Spring.NET 框架都是把”反射“做为最基本的技术手段
- 反射技术其实很早就出现了,但一直被忽略,没有被进一步的利用。当时的反射编程方式相对于正常的对象生成方式要慢至少得 10 倍。现在的反射技术经过改良优化,已经非常成熟,反射方式生成对象和通常对象生成方式,速度已经相差不大了,大约为 1-2 倍的差距
- 我们可以把 IOC 容器的工作模式看做是工厂模式的升华,可以把 IOC 容器看作是一个工厂,这个工厂里要生产的对象都在配置文件中给出定义,然后利用编程语言提供的反射机制,根据配置文件中给出的类名生成相应的对象。从实现来看,IOC 是把以前在工厂方法里写死的对象生成代码,改变为由配置文件来定义,也就是把工厂和对象生成这两者独立分隔开来,目的就是提高灵活性和可维护性
-
使用 IOC 框架应该注意什么
- 使用 IOC 框架产品能够给我们的开发过程带来很大的好处,但是也要充分认识引入 IOC 框架的缺点,做到心中有数,杜绝滥用框架
- 软件系统中由于引入了第三方 IOC 容器,生成对象的步骤变得有些复杂,本来是两者之间的事情,又凭空多出一道手续,所以,我们在刚开始使用 IOC 框架的时候,会感觉系统变得不太直观。所以,引入了一个全新的框架,就会增加团队成员学习和认识的培训成本,并且在以后的运行维护中,还得让新加入者具备同样的知识体系
- 由于 IOC 容器生成对象是通过反射方式,在运行效率上有一定的损耗。如果你要追求运行效率的话,就必须对此进行权衡
- 具体到 IOC 框架产品(比如 Spring)来讲,需要进行大量的配制工作,比较繁琐,对于一些小的项目而言,客观上也可能加大一些工作成本
- IOC 框架产品本身的成熟度需要进行评估,如果引入一个不成熟的 IOC 框架产品,那么会影响到整个项目,所以这也是一个隐性的风险
- 我们大体可以得出这样的结论:一些工作量不大的项目或者产品,不太适合使用 IOC 框架产品。另外,如果团队成员的知识能力欠缺,对于 IOC 框架产品缺乏深入的理解,也不要贸然引入。最后,特别强调运行效率的项目或者产品,也不太适合引入 IOC 框架产品,像 WEB2.0 网站就是这种情况
- 使用 IOC 框架产品能够给我们的开发过程带来很大的好处,但是也要充分认识引入 IOC 框架的缺点,做到心中有数,杜绝滥用框架
- 反射
-
枚举类型和泛型
- 枚举的用法
- 背景
- 在 java 语言中还没有引入枚举类型之前,表示枚举类型的常用模式是声明一组具 int 常量。当然这种模式不是类型安全的,比如说我们设计一个函数,要求传入春夏秋冬的某个值。但是使用 int 类型,我们无法保证传入的值为合法
public class Season { public static final int SPRING = 1; public static final int SUMMER = 2; public static final int AUTUMN = 3; public static final int WINTER = 4; }
- 在 java 语言中还没有引入枚举类型之前,表示枚举类型的常用模式是声明一组具 int 常量。当然这种模式不是类型安全的,比如说我们设计一个函数,要求传入春夏秋冬的某个值。但是使用 int 类型,我们无法保证传入的值为合法
- 定义
- 枚举类型(enum type)是指由一组固定的常量组成合法的类型。Java 中由关键字 enum 来定义一个枚举类型
public enum Season { SPRING, SUMMER, AUTUMN, WINTER; }
- 枚举类型(enum type)是指由一组固定的常量组成合法的类型。Java 中由关键字 enum 来定义一个枚举类型
- 特点
- 使用关键字 enum
- 类型名称,比如这里的 Season
- 一串允许的值,比如上面定义的春夏秋冬四季
- 枚举可以单独定义在一个文件中,也可以嵌在其它 Java 类中除了这样的基本要求外,用户还有一些其他选择
- 枚举可以实现一个或多个接口(Interface)
- 可以定义新的变量
- 可以定义新的方法
- 可以定义根据具体枚举值而相异的类
- 枚举的使用
- 略
- 背景
- 枚举的实现
- enum 就和 class 一样,只是一个关键字
public enum t { SPRING,SUMMER; } - 然后我们使用反编译,看看这段代码到底是怎么实现的,反编译后代码内容如下:
public final class T extends Enum { private T(String s, int i){ super(s, i); } public static T[] values(){ T at[]; int i; T at1[]; System.arraycopy(at = ENUM$VALUES, 0, at1 = new T[i = at.length], 0,i); return at1; } public static T valueOf(String s){ return (T)Enum.valueOf(demo/T, s); } public static final T SPRING; public static final T SUMMER; private static final T ENUM$VALUES[]; static{ SPRING = new T("SPRING", 0); SUMMER = new T("SUMMER", 1); ENUM$VALUES = (new T[] {SPRING, SUMMER}); } } - 通过反编译后代码我们可以看到,public final class T extends Enum,说明,该类是继承了 Enum 类的,同时 final 关键字告诉我们,这个类也是不能被继承的。当我们使用 enmu 来定义一个枚举类型的时候,编译器会自动帮我们创建一个 final 类型的类继承 Enum 类,所以枚举类型不能被继承
- 使用枚举实现单例是一种很好的方法
public enum Singleton { INSTANCE; public void whateverMethod() { } } - 枚举可解决线程安全问题
- 深度分析Java的枚举类型—-枚举的线程安全性及序列化问题
- 示例代码及反编译
public enum T { SPRING,SUMMER,AUTUMN,WINTER; }public final class T extends Enum { //省略部分内容 public static final T SPRING; public static final T SUMMER; public static final T AUTUMN; public static final T WINTER; private static final T ENUM$VALUES[]; { SPRING = new T("SPRING", 0); SUMMER = new T("SUMMER", 1); AUTUMN = new T("AUTUMN", 2); WINTER = new T("WINTER", 3); ENUM$VALUES = (new T[] {SPRING, SUMMER, AUTUMN, WINTER}); } } - 了解 JVM 的类加载机制的朋友应该对这部分比较清楚。static 类型的属性会在类被加载之后被初始化,我们在 深度分析 Java 的 ClassLoader 机制(源码级别)和Java 类的加载、链接和初始化两个文章中分别介绍过,当一个 Java 类第一次被真正使用到的时候静态资源被初始化、Java 类的加载和初始化过程都是线程安全的(因为虚拟机在加载枚举的类的时候,会使用 ClassLoader 的 loadClass 方法,而这个方法使用同步代码块保证了线程安全)。所以,创建一个 enum 类型是线程安全的。也就是说,我们定义的一个枚举,在第一次被真正用到的时候,会被虚拟机加载并初始化,而这个初始化过程是线程安全的。而我们知道,解决单例的并发问题,主要解决的就是初始化过程中的线程安全问题。所以,由于枚举的以上特性,枚举实现的单例是天生线程安全的
- 枚举可解决反序列化会破坏单例的问题
- 在序列化的时候 Java 仅仅是将枚举对象的 name 属性输出到结果中,反序列化的时候则是通过 java.lang.Enum 的 valueOf 方法来根据名字查找枚举对象。同时,编译器是不允许任何对这种序列化机制的定制的,因此禁用了 writeObject、readObject、readObjectNoData、writeReplace 和 readResolve 等方法
- 普通的 Java 类的反序列化过程中,会通过反射调用类的默认构造函数来初始化对象。所以,即使单例中构造函数是私有的,也会被反射给破坏掉。由于反序列化后的对象是重新 new 出来的,所以这就破坏了单例。但是,枚举的反序列化并不是通过反射实现的。所以,就不会发生由于反序列化导致的单例破坏问题。这部分内容在深度分析 Java 的枚举类型-枚举的线程安全性及序列化问题中也有更加详细的介绍,还展示了部分代码,感兴趣的朋友可以前往阅读
public static <T extends Enum<T>> T valueOf(Class<T> enumType,String name){ T result = enumType.enumConstantDirectory().get(name); if (result != null) return result; if (name == null) throw new NullPointerException("Name is null"); throw new IllegalArgumentException("No enum const " + enumType +"." + name); }- 从代码中可以看到,代码会尝试从调用enumType这个Class对象的 enumConstantDirectory() 方法返回的 map 中获取名字为 name 的枚举对象,如果不存在就会抛出异常。再进一步跟到 enumConstantDirectory() 方法,就会发现到最后会以反射的方式调用 enumType 这个类型的 values() 静态方法,也就是上面我们看到的编译器为我们创建的那个方法,然后用返回结果填充 enumType 这个 Class 对象中 enumConstantDirectory 属性。所以,JVM 对序列化有保证
- enum 就和 class 一样,只是一个关键字
- Enum 类
- Java 中定义枚举是使用 enum 关键字的,但是 Java 中其实还有一个 java.lang.Enum 类。这是一个抽象类
package java.lang; public abstract class Enum<E extends Enum<E>> implements Constable, Comparable<E>, Serializable { private final String name; private final int ordinal; } - 这个类我们在日常开发中不会用到,但是其实我们使用 enum 定义的枚举,其实现方式就是通过继承 Enum 类实现的。当我们使用 enmu 来定义一个枚举类型的时候,编译器会自动帮我们创建一个 final 类型的类继承 Enum 类,所以枚举类型不能被继承
- Java 中定义枚举是使用 enum 关键字的,但是 Java 中其实还有一个 java.lang.Enum 类。这是一个抽象类
- Java 枚举如何比较
- java 枚举值比较用 == 和 equals 方法没啥区别,两个随便用都是一样的效果。因为枚举 Enum 类的 equals 方法默认实现就是通过 == 来比较的;类似的 Enum 的 compareTo 方法比较的是 Enum 的 ordinal 顺序大小;类似的还有 Enum 的 name 方法和 toString 方法一样都返回的是 Enum 的 name 值
- switch 对枚举的支持
- Java 1.7 之前 switch 参数可用类型为 short、byte、int、char,枚举类型之所以能使用其实是编译器层面实现的,编译器会将枚举 switch 转换为类似:
switch(s.ordinal()) { case Status.START.ordinal() } - 所以实质还是 int 参数类型
- Java 1.7 之前 switch 参数可用类型为 short、byte、int、char,枚举类型之所以能使用其实是编译器层面实现的,编译器会将枚举 switch 转换为类似:
- 什么是泛型
- Java 泛型( generics) 是 JDK 5 中引⼊的⼀个新特性,允许在定义类和接口的时候使⽤类型参数(type parameter)。声明的类型参数在使⽤时⽤具体的类型来替换。 泛型最主要的应⽤是在 JDK 5 中的新集合类框架中
- 泛型最⼤的好处是可以提⾼代码的复⽤性。以 List 接口为例,我们可以将 String、Integer 等类型放⼊ List 中,如不⽤泛型,存放 String 类型要写⼀个 List 接口,存放 Integer 要写另外⼀个 List 接口,泛型可以很好的解决这个问题
- 类型擦除
- 各种语言中的编译器是如何处理泛型的
- 分类
- Code specialization。在实例化一个泛型类或泛型方法时都产生一份新的目标代码(字节码 or 二进制代码)。例如,针对一个泛型 list,可能需要针对 string,integer,float 产生三份目标代码
- Code sharing。对每个泛型类只生成唯一的一份目标代码;该泛型类的所有实例都映射到这份目标代码上,在需要的时候执行类型检查和类型转换
- 应用
- C++ 中的模板(template)是典型的 Code specialization 实现。C++ 编译器会为每一个泛型类实例生成一份执行代码。执行代码中 integer list 和 string list 是两种不同的类型。这样会导致代码膨胀(code bloat)。 C# 里面泛型无论在程序源码中、编译后的 IL 中(Intermediate Language,中间语言,这时候泛型是一个占位符)或是运行期的 CLR 中都是切实存在的,List 与 List 就是两个不同的类型,它们在系统运行期生成,有自己的虚方法表和类型数据,这种实现称为类型膨胀,基于这种方法实现的泛型被称为真实泛型。Java 语言中的泛型则不一样,它只在程序源码中存在,在编译后的字节码文件中,就已经被替换为原来的原生类型(Raw Type,也称为裸类型)了,并且在相应的地方插入了强制转型代码,因此对于运行期的 Java 语言来说,ArrayList 与 ArrayList 就是同一个类。所以说泛型技术实际上是 Java 语言的一颗语法糖,Java 语言中的泛型实现方法称为类型擦除,基于这种方法实现的泛型被称为伪泛型
- C++ 和 C# 是使用 Code specialization 的处理机制,前面提到,他有一个缺点,那就是会导致代码膨胀。另外一个弊端是在引用类型系统中,浪费空间,因为引用类型集合中元素本质上都是一个指针。没必要为每个类型都产生一份执行代码。而这也是 Java 编译器中采用 Code sharing 方式处理泛型的主要原因。Java 编译器通过 Code sharing 方式为每个泛型类型创建唯一的字节码表示,并且将该泛型类型的实例都映射到这个唯一的字节码表示上。将多种泛型类形实例映射到唯一的字节码表示是通过类型擦除(type erasue)实现的
- Java 编译器通过 Code sharing 方式为每个泛型类型创建唯一的字节码表示,并且将该泛型类型的实例都映射到这个唯一的字节码表示上。将多种泛型类形实例映射到唯一的字节码表示是通过类型擦除(type erasue)实现的
- 分类
- 什么是类型擦除
- 前面我们多次提到这个词:类型擦除(type erasue),那么到底什么是类型擦除呢?类型擦除指的是通过类型参数合并,将泛型类型实例关联到同一份字节码上。编译器只为泛型类型生成一份字节码,并将其实例关联到这份字节码上。类型擦除的关键在于从泛型类型中清除类型参数的相关信息,并且再必要的时候添加类型检查和类型转换的方法。 类型擦除可以简单的理解为将泛型 java 代码转换为普通 java 代码,只不过编译器更直接点,将泛型 java 代码直接转换成普通 java 字节码。 类型擦除的主要过程如下:
- 将所有的泛型参数用其最左边界(最顶级的父类型)类型替换
- 移除所有的类型参数
- 前面我们多次提到这个词:类型擦除(type erasue),那么到底什么是类型擦除呢?类型擦除指的是通过类型参数合并,将泛型类型实例关联到同一份字节码上。编译器只为泛型类型生成一份字节码,并将其实例关联到这份字节码上。类型擦除的关键在于从泛型类型中清除类型参数的相关信息,并且再必要的时候添加类型检查和类型转换的方法。 类型擦除可以简单的理解为将泛型 java 代码转换为普通 java 代码,只不过编译器更直接点,将泛型 java 代码直接转换成普通 java 字节码。 类型擦除的主要过程如下:
- Java 编译器处理泛型的过程
// 示例 public static void main(String[] args) { Map<String, String> map = new HashMap<String, String>(); map.put("name", "hollis"); map.put("age", "22"); System.out.println(map.get("name")); System.out.println(map.get("age")); } // 反编译 public static void main(String[] args) { Map map = new HashMap(); map.put("name", "hollis"); map.put("age", "22"); System.out.println((String) map.get("name")); System.out.println((String) map.get("age")); }// 示例 interface Comparable<A> { public int compareTo(A that); } public final class NumericValue implements Comparable<NumericValue> { private byte value; public NumericValue(byte value) { this.value = value; } public byte getValue() { return value; } public int compareTo(NumericValue that) { return this.value - that.value; } } // 反编译 interface Comparable { public int compareTo( Object that); } public final class NumericValue implements Comparable { public NumericValue(byte value) { this.value = value; } public byte getValue(){ return value; } public int compareTo(NumericValue that) { return value - that.value; } public volatile int compareTo(Object obj) { return compareTo((NumericValue)obj); } private byte value; }// 示例 public class Collections { public static <A extends Comparable<A>> A max(Collection<A> xs) { Iterator<A> xi = xs.iterator(); A w = xi.next(); while (xi.hasNext()) { A x = xi.next(); if (w.compareTo(x) < 0) w = x; } return w; } } // 反编译 public class Collections { public Collections() { } public static Comparable max(Collection xs) { Iterator xi = xs.iterator(); Comparable w = (Comparable)xi.next(); while(xi.hasNext()) { Comparable x = (Comparable)xi.next(); if(w.compareTo(x) < 0) w = x; } return w; } }- 第 2 个泛型类 Comparable 擦除后 A 被替换为最左边界 Object 。Comparable 的类型参数 NumericValue 被擦除掉,但是这直接导致 NumericValue 没有实现接口 Comparable 的 compareTo(Object that) 方法,于是编译器充当好人,添加了一个桥接方法。 第 3 个示例中限定了类型参数的边界 <A extends Comparable>A,A 必须为 Comparable 的子类,按照类型擦除的过程,先讲所有的类型参数 ti 换为最左边界 Comparable,然后去掉参数类型 A,得到最终的擦除后结果
- 泛型带来的问题
- 当泛型遇到重载
- 上面这段代码,有两个重载的函数,因为他们的参数类型不同,一个是 List 另一个是 List ,但是,这段代码是编译通不过的。因为我们前面讲过,参数List和 List编译之后都被擦除了,变成了一样的原生类型 List,擦除动作导致这两个方法的特征签名变得一模一样
public class GenericTypes { public static void method(List<String> list) { System.out.println("invoke method(List<String> list)"); } public static void method(List<Integer> list) { System.out.println("invoke method(List<Integer> list)"); } } - 当泛型遇到 catch
- 如果我们自定义了一个泛型异常类 GenericException,那么,不要尝试用多个catch取匹配不同的异常类型,例如你想要分别捕获 GenericException、GenericException,这也是有问题的
- 当泛型内包含静态变量
- 答案是——2!由于经过类型擦除,所有的泛型类实例都关联到同一份字节码上,泛型类的所有静态变量是共享的
public class StaticTest { public static void main(String[] args){ GT<Integer> gti = new GT<Integer>(); gti.var=1; GT<String> gts = new GT<String>(); gts.var=2; System.out.println(gti.var); } } class GT<T>{ public static int var=0; public void nothing(T x){} }
- 当泛型遇到重载
- 总结
- 虚拟机中没有泛型,只有普通类和普通方法,所有泛型类的类型参数在编译时都会被擦除,泛型类并没有自己独有的 Class 类对象。比如并不存在 List.class 或是List.class,而只有 List.class
- 创建泛型对象时请指明类型,让编译器尽早的做参数检查(Effective Java,第 23 条:请不要在新代码中使用原生态类型)
- 不要忽略编译器的警告信息,那意味着潜在的 ClassCastException 等着你
- 静态变量是被泛型类的所有实例所共享的。对于声明为 MyClass 的类,访问其中的静态变量的方法仍然是 MyClass.myStaticVar。不管是通过 new MyClass 还是 new MyClass 创建的对象,都是共享一个静态变量
- 泛型的类型参数不能用在 Java 异常处理的 catch 语句中。因为异常处理是由 JVM 在运行时刻来进行的。由于类型信息被擦除,JVM 是无法区分两个异常类型 MyException 和 MyException 的。对于 JVM 来说,它们都是 MyException 类型的。也就无法执行与异常对应的 catch 语句
- 各种语言中的编译器是如何处理泛型的
- 泛型中 K T V E ? object 等的含义
- E - Element (在集合中使用,因为集合中存放的是元素)
- T - Type(Java 类)
- K - Key(键)
- V - Value(值)
- N - Number(数值类型)
- ? - 表示不确定的 java 类型(无限制通配符类型)
- S、U、V - 2nd、3rd、4th types
- Object - 是所有类的根类,任何类的对象都可以设置给该 Object 引用变量,使用的时候可能需要类型强制转换,但是用使用了泛型 T、E 等这些标识符后,在实际用之前类型就已经确定了,不需要再进行类型强制转换
- 限定通配符和非限定通配符
- 限定通配符对类型进⾏限制, 泛型中有两种限定通配符:
- 表示类型的上界,格式为:<? extends T>,即类型必须为 T 类型或者 T 子类
- 表示类型的下界,格式为:<? super T>,即类型必须为 T 类型或者 T 的父类
- 泛型类型必须⽤限定内的类型来进⾏初始化,否则会导致编译错误
- ⾮限定通配符表⽰可以⽤任意泛型类型来替代,类型为
- 限定通配符对类型进⾏限制, 泛型中有两种限定通配符:
- 上下界限定符 extends 和 super
- <? extends T>和<? super T>是 Java 泛型中的“通配符(Wildcards)”和“边界(Bounds)”的概念
- <? extends T>:是指 “上界通配符(Upper Bounds Wildcards)”,即泛型中的类必须为当前类的子类或当前类
- <? super T>:是指 “下界通配符(Lower Bounds Wildcards)”,即泛型中的类必须为当前类或者其父类 ```java public class Food {} public class Fruit extends Food {} public class Apple extends Fruit {} public class Banana extends Fruit{} public class GenericTest { public void testExtends(List<? extends Fruit> list){ // 报错,extends 为上界通配符,只能取值,不能放. // 因为 Fruit 的子类不只有 Apple 还有 Banana,这里不能确定具体的泛型到底是 Apple 还是 Banana,所以放入任何一种类型都会报错 // list.add(new Apple()); // 可以正常获取 Fruit fruit = list.get(1); } public void testSuper(List<? super Fruit> list){ // super 为下界通配符,可以存放元素,但是也只能存放当前类或者子类的实例,以当前的例子来讲, // 无法确定 Fruit 的父类是否只有 Food 一个(Object 是超级父类) // 因此放入 Food 的实例编译不通过 list.add(new Apple()); // list.add(new Food()); Object object = list.get(1); } } ```
- List 和原始类型 List 之间的区别
- 原始类型 List 和带参数类型 List 之间的主要区别是,在编译时编译器不会对原始类型进行类型安全检查,却会对带参数的类型进行检查。通过使用 Object 作为类型,可以告知编译器该方法可以接受任何类型的对象,比如 String 或 Integer
- 它们之间的第二点区别是,你可以把任何带参数的类型传递给原始类型 List,但却不能把 List 传递给接受 List 的方法,因为会产生编译错误
- List<?> 和 List 之间的区别是什么?
- List<?> 是一个未知类型的 List,而 List 其实是任意类型的 List。你可以把 List, List 赋值给 List<?>,却不能把 List 赋值给 List
- 枚举的用法
-
动态代理
- 静态代理
- 所谓静态代理,就是代理类是由程序员自己编写的,在编译期就确定好了的
public interface HelloSerivice { public void say(); } public class HelloSeriviceImpl implements HelloSerivice{ @Override public void say() { System.out.println("hello world"); } } - 代理类
public class HelloSeriviceProxy implements HelloSerivice{ private HelloSerivice target; public HelloSeriviceProxy(HelloSerivice target) { this.target = target; } @Override public void say() { System.out.println("记录日志"); target.say(); System.out.println("清理数据"); } } - 这就是一个简单的静态的代理模式的实现。代理模式中的所有角色(代理对象、目标对象、目标对象的接口)等都是在编译期就确定好的
- 静态代理的用途
- 控制真实对象的访问权限,通过代理对象控制对真实对象的使用权限
- 避免创建大对象 通过使用一个代理小对象来代表一个真实的大对象,可以减少系统资源的消耗,对系统进行优化并提高运行速度
- 增强真实对象的功能 这个比较简单,通过代理可以在调用真实对象的方法的前后增加额外功能
- 所谓静态代理,就是代理类是由程序员自己编写的,在编译期就确定好了的
- 动态代理
- 动态代理中的代理类并不要求在编译期就确定,而是可以在运行期动态生成,从而实现对目标对象的代理功能
- 动态代理和反射的关系
- 反射是动态代理的一种实现方式
- 动态代理的几种实现方式
- Java 中,实现动态代理有两种方式:
- JDK 动态代理:java.lang.reflect 包中的 Proxy 类和 InvocationHandler 接口提供了生成动态代理类的能力
- Cglib 动态代理:Cglib (Code Generation Library )是一个第三方代码生成类库,运行时在内存中动态生成一个子类对象从而实现对目标对象功能的扩展
- JDK 动态代理和 Cglib 动态代理的区别
- 使用动态代理的对象必须实现一个或多个接口,使用 cglib 代理的对象则无需实现接口,达到代理类无侵入
- Java 实现动态代理的大致步骤
- 定义一个委托类和公共接口
- 自己定义一个类(调用处理器类,即实现 InvocationHandler 接口),这个类的目的是指定运行时将生成的代理类需要完成的具体任务(包括 Preproces s 和 Postprocess),即代理类调用任何方法都会经过这个调用处理器类
- 生成代理对象(当然也会生成代理类),需要为他指定(1)委托对象(2)实现的一系列接口(3)调用处理器类的实例。因此可以看出一个代理对象对应一个委托对象,对应一个调用处理器实例
- Java 实现动态代理主要涉及哪几个类
- java.lang.reflect.Proxy: 这是生成代理类的主类,通过 Proxy 类生成的代理类都继承了 Proxy 类,即 DynamicProxyClass extends Proxy
- java.lang.reflect.InvocationHandler: 这里称他为"调用处理器",他是一个接口,我们动态生成的代理类需要完成的具体内容需要自己定义一个类,而这个类必须实现 InvocationHandler 接口
- 动态代理实现
public class UserServiceImpl implements UserService { @Override public void add() { // TODO Auto-generated method stub System.out.println("--------------------add----------------------"); } } - jdk 动态代理
public class MyInvocationHandler implements InvocationHandler { private Object target; public MyInvocationHandler(Object target) { super(); this.target = target; } @Override public Object invoke(Object proxy, Method method, Object[] args) throws Throwable { PerformanceMonior.begin(target.getClass().getName()+"."+method.getName()); //System.out.println("-----------------begin "+method.getName()+"-----------------"); Object result = method.invoke(target, args); //System.out.println("-----------------end "+method.getName()+"-----------------"); PerformanceMonior.end(); return result; } public Object getProxy(){ return Proxy.newProxyInstance(Thread.currentThread().getContextClas sLoader(), target.getClass().getInterfaces(), this); } } public static void main(String[] args) { UserService service = new UserServiceImpl(); MyInvocationHandler handler = new MyInvocationHandler(service); UserService proxy = (UserService) handler.getProxy(); proxy.add(); } - cglib 动态代理
public class CglibProxy implements MethodInterceptor{ private Enhancer enhancer = new Enhancer(); public Object getProxy(Class clazz){ //设置需要创建子类的类 enhancer.setSuperclass(clazz); enhancer.setCallback(this); //通过字节码技术动态创建子类实例 return enhancer.create(); } //实现 MethodInterceptor 接口方法 public Object intercept(Object obj, Method method, Object[] args, MethodProxy proxy) throws Throwable { System.out.println("前置代理"); //通过代理类调用父类中的方法 Object result = proxy.invokeSuper(obj, args); System.out.println("后置代理"); return result; } } public class DoCGLib { public static void main(String[] args) { CglibProxy proxy = new CglibProxy(); //通过生成子类的方式创建代理类 UserServiceImpl proxyImp = (UserServiceImpl)proxy.getProxy(UserServiceImpl.class); proxyImp.add(); } }
- Java 中,实现动态代理有两种方式:
- AOP
- Spring AOP 中的动态代理主要有两种方式,JDK 动态代理和 CGLIB 动态代理
- JDK 动态代理通过反射来接收被代理的类,并且要求被代理的类必须实现一个接口。JDK 动态代理的核心是 InvocationHandler 接口和 Proxy 类,如果目标类没有实现接口,那么 Spring AOP 会选择使用 CGLIB 来动态代理目标类。CGLIB(Code Generation Library),是一个代码生成的类库,可以在运行时动态的生成某个类的子类,注意,CGLIB 是通过继承的方式做的动态代理,因此如果某个类被标记为 final,那么它是无法使用 CGLIB 做动态代理的
- 静态代理
-
序列化
- 什么是序列化与反序列化
- 序列化是将对象转换为可传输格式的过程。是一种数据的持久化手段。一般广泛应用于网络传输,RMI 和 RPC 等场景中
- 反序列化是序列化的逆操作。序列化是将对象的状态信息转换为可存储或传输的形式的过程。一般是以字节码或 XML 格式传输。而字节码或 XML 编码格式可以还原为完全相等的对象。这个相反的过程称为反序列化
- Java 如何实现序列化与反序列化
- Java 对象的序列化与反序列化
- 在 Java 中,我们可以通过多种方式来创建对象,并且只要对象没有被回收我们都可以复用该对象。但是,我们创建出来的这些 Java 对象都是存在于 JVM 的堆内存中的。只有 JVM 处于运行状态的时候,这些对象才可能存在。一旦 JVM 停止运行,这些对象的状态也就随之而丢失了。但是在真实的应用场景中,我们需要将这些对象持久化下来,并且能够在需要的时候把对象重新读取出来。Java 的对象序列化可以帮助我们实现该功能
- 对象序列化机制(object serialization)是 Java 语言内建的一种对象持久化方式,通过对象序列化,可以把对象的状态保存为字节数组,并且可以在有需要的时候将这个字节数组通过反序列化的方式再转换成对象。对象序列化可以很容易的在 JVM 中的活动对象和字节数组(流)之间进行转换。在 Java 中,对象的序列化与反序列化被广泛应用到 RMI (远程方法调用)及网络传输中
- 相关接口及类
- Java 为了方便开发人员将 Java 对象进行序列化及反序列化提供了一套方便的 API 来支持。其中包括以下接口和类
- java.io.Serializable
- java.io.Externalizable
- ObjectOutput
- ObjectInput
- ObjectOutputStream
- ObjectInputStream
- Java 为了方便开发人员将 Java 对象进行序列化及反序列化提供了一套方便的 API 来支持。其中包括以下接口和类
- Serializable 接口
- 类通过实现 java.io.Serializable 接口以启用其序列化功能。未实现此接口的类将无法使其任何状态序列化或反序列化。可序列化类的所有子类型本身都是可序列化的。序列化接口没有方法或字段,仅用于标识可序列化的语义。深入分析Java的序列化与反序列化
- 当试图对一个对象进行序列化的时候,如果遇到不支持 Serializable 接口的对象。在此情况下,将抛出 NotSerializableException。如果要序列化的类有父类,要想同时将在父类中定义过的变量持久化下来,那么父类也应该集成 java.io.Serializable 接口。下面是一个实现了 java.io.Serializable 接口的类
package com.hollischaung.serialization.SerializableDemos; import java.io.Serializable; /** * Created by hollis on 16/2/17. * 实现 Serializable 接口 */ public class User1 implements Serializable { private String name; private int age; public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } @Override public String toString() { return "User{" + "name='" + name + '\'' + ", age=" + age + '}'; } } - 通过下面的代码进行序列化及反序列化
package com.hollischaung.serialization.SerializableDemos; import org.apache.commons.io.FileUtils; import org.apache.commons.io.IOUtils; import java.io.*; /** * Created by hollis on 16/2/17. * SerializableDemo1 结合 SerializableDemo2 说明 一个类要想被序列化必须实现 Serial izable 接口 */ public class SerializableDemo1 { public static void main(String[] args) { //Initializes The Object User1 user = new User1(); user.setName("hollis"); user.setAge(23); System.out.println(user); //Write Obj to File ObjectOutputStream oos = null; try { oos = new ObjectOutputStream(new FileOutputStream("tempFile")); oos.writeObject(user); } catch (IOException e) { e.printStackTrace(); } finally { IOUtils.closeQuietly(oos); } //Read Obj from File File file = new File("tempFile"); ObjectInputStream ois = null; try { ois = new ObjectInputStream(new FileInputStream(file)); User1 newUser = (User1) ois.readObject(); System.out.println(newUser); } catch (IOException e) { e.printStackTrace(); } catch (ClassNotFoundException e) { e.printStackTrace(); } finally { IOUtils.closeQuietly(ois); try { FileUtils.forceDelete(file); } catch (IOException e) { e.printStackTrace(); } } } } //OutPut: //User{name='hollis', age=23} //User{name='hollis', age=23}
- Externalizable 接口
package com.hollischaung.serialization.ExternalizableDemos; import java.io.Externalizable; import java.io.IOException; import java.io.ObjectInput; import java.io.ObjectOutput; /** * Created by hollis on 16/2/17. * 实现 Externalizable 接口 */ public class User1 implements Externalizable { private String name; private int age; public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } public void writeExternal(ObjectOutput out) throws IOException { } public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException { } @Override public String toString() { return "User{" + "name='" + name + '\'' + ", age=" + age + '}'; } } package com.hollischaung.serialization.ExternalizableDemos; import java.io.*; /** * Created by hollis on 16/2/17. */ public class ExternalizableDemo1 { //为了便于理解和节省篇幅,忽略关闭流操作及删除文件操作。真正编码时千万不要忘记 //IOException 直接抛出 public static void main(String[] args) throws IOException, ClassNotFoundException { //Write Obj to file ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("tempFile")); User1 user = new User1(); user.setName("hollis"); user.setAge(23); oos.writeObject(user); //Read Obj from file File file = new File("tempFile"); ObjectInputStream ois = new ObjectInputStream(new FileInputStream(file)); User1 newInstance = (User1) ois.readObject(); //output System.out.println(newInstance); } } //OutPut:- 通过上面的实例可以发现,对 User1 类进行序列化及反序列化之后得到的对象的所有属性的值都变成了默认值。也就是说,之前的那个对象的状态并没有被持久化下来。这就是Externalizable 接口和 Serializable 接口的区别:
- Externalizable 继承了 Serializable,该接口中定义了两个抽象方法:writeExternal() 与 readExternal()。当使用 Externalizable 接口来进行序列化与反序列化的时候需要开发人员重写 writeExternal() 与 readExternal() 方法。由于上面的代码中,并没有在这两个方法中定义序列化实现细节,所以输出的内容为空。还有一点值得注意:在使用 Externalizable 进行序列化的时候,在读取对象时,会调用被序列化类的无参构造器去创建一个新的对象,然后再将被保存对象的字段的值分别填充到新对象中。所以,实现 Externalizable 接口的类必须要提供一个 public 的无参的构造器
package com.hollischaung.serialization.ExternalizableDemos; import java.io.Externalizable; import java.io.IOException; import java.io.ObjectInput; import java.io.ObjectOutput; /** * Created by hollis on 16/2/17. * 实现 Externalizable 接口,并实现 writeExternal 和 readExternal 方法 */ public class User2 implements Externalizable { private String name; private int age; public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } public void writeExternal(ObjectOutput out) throws IOException { out.writeObject(name); out.writeInt(age); } public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException { name = (String) in.readObject(); age = in.readInt(); } @Override public String toString() { return "User{" + "name='" + name + '\'' + ", age=" + age + '}'; } } package com.hollischaung.serialization.ExternalizableDemos; import java.io.*; /** * Created by hollis on 16/2/17. */ public class ExternalizableDemo2 { //为了便于理解和节省篇幅,忽略关闭流操作及删除文件操作。真正编码时千万不要忘记 //IOException 直接抛出 public static void main(String[] args) throws IOException, ClassNotFoundException { //Write Obj to file ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("tempFile")); User2 user = new User2(); user.setName("hollis"); user.setAge(23); oos.writeObject(user); //Read Obj from file File file = new File("tempFile"); ObjectInputStream ois = new ObjectInputStream(new FileInputStream(file)); User2 newInstance = (User2) ois.readObject(); //output System.out.println(newInstance); } } //OutPut: //User{name='hollis', age=23} - 通过上面的实例可以发现,对 User1 类进行序列化及反序列化之后得到的对象的所有属性的值都变成了默认值。也就是说,之前的那个对象的状态并没有被持久化下来。这就是Externalizable 接口和 Serializable 接口的区别:
- 如果 User 类中没有无参数的构造函数,在运行时会抛出异常:java.io.InvalidClassException
- Java 对象的序列化与反序列化
- Serializable 和 Externalizable 有何不同
- Java 中的类通过实现 java.io.Serializable 接口以启⽤其序列化功能。未实现此接口的类将⽆法使其任何状态序列化或反序列化。可序列化类的所有⼦类型本⾝都是可序列化的。序列化接口没有⽅法或字段,仅⽤于标识可序列化的语义。当试图对⼀个对象进⾏序列化的时候,如果遇到不⽀持 Serializable 接口的对象。在此情况下,将抛 NotSerializableException。如果要序列化的类有⽗类,要想同时将在⽗类中定义过的变量持久化下来,那么⽗类也应该集成 java.io.Serializable 接口。External i zable 继承了 Serial izable,该接⼜中定义了两个抽象⽅法:writeExternal() 与 readExternal()。当使⽤Externalizable 接口来进⾏序列化与反序列化的时候需要开发⼈员重写 writeExternal()与 readExternal()⽅法。如果没有在这两个⽅法中定义序列化实现细节,那么序列化之后,对象内容为空。实现 Externalizable 接⼜的类必须要提供⼀个 public 的⽆参的构造器。所以,实现 Externalizable,并实现 writeExternal() 和 readExternal() ⽅法可以指定序列化哪些属性
- serialVersionUID
- 序列化是将对象的状态信息转换为可存储或传输的形式的过程。我们都知道,Java 对象是保存在 JVM 的堆内存中的,也就是说,如果 JVM 堆不存在了,那么对象也就跟着消失了。⽽序列化提供了⼀种⽅案,可以让你在即使 JVM 停机的情况下也能把对象保存下来的⽅案。就像我们平时⽤的 U 盘⼀样。把 Java 对象序列化成可存储或传输的形式(如⼆进制流),如保存在⽂件中。这样, 当再次需要这个对象的时候,从⽂件中读取出⼆进制流,再从⼆进制流中反序列化出对象
- 但是,虚拟机是否允许反序列化,不仅取决于类路径和功能代码是否⼀致,⼀个⾮常重要的⼀点是两个类的序列化 ID 是否⼀致,即 serialVersionUID 要求⼀致。在进⾏反序列化时,JVM 会把传来的字节流中的 serialVersionUID 与本地相应实体类的 serialVersionUID 进⾏⽐较,如果相同就认为是⼀致的,可以进⾏反序列化,否则就会出现序列化版本不⼀致的异常,即是 InvalidCastException。这样做是为了保证安全,因为⽂件存储中的内容可能被篡改。当实现 java.io.Serializable 接口的类没有显式地定义⼀个 serialVersionUID 变量时候,Java 序列化机制会根据编译的 Class ⾃动⽣成⼀个 serialVersionUID 作序列化版本⽐较⽤,这种情况下,如果 Class ⽂件没有发⽣变化,就算再编译多次,serialVersionUID 也不会变化的。但是,如果发⽣了变化,那么这个⽂件对应的 serialVersionUID 也就会发⽣变化。基于以上原理,如果我们⼀个类实现了 Serializable 接口,但是没有定义 serialVersionUID,然后序列化。在序列化之后,由于某些原因,我们对该类做了变更,重新启动应⽤后,我们相对之前序列化过的对象进⾏反序列化的话就会报错
- 为什么 serialVersionUID 不能随便改
- 《Java 开发手册》中有以下规定
【强制】序列化类新增属性时,请不要修改 serialVersionUID 字段,避免反序列失败;如果完全不兼容升级,避免反序列化混乱,那么请修改 serialVersionUID 值 说明:注意 serialVersionUID 不一致会抛出序列化运行时异常 - 背景知识
- Serializable 和 Externalizable 类通过实现 java.io.Serializable 接口以启用其序列化功能。未实现此接口的类将无法进行序列化或反序列化。可序列化类的所有子类型本身都是可序列化的。如果读者看过 Serializable 的源码,就会发现,他只是一个空的接口,里面什么东西都没有。Serializable 接口没有方法或字段,仅用于标识可序列化的语义。但是,如果一个类没有实现这个接口,想要被序列化的话,就会抛出 java.io.NotSerializableException 异常。它是怎么保证只有实现了该接口的方法才能进行序列化与反序列化的呢?原因是在执行序列化的过程中,会执行到以下代码
if (obj instanceof String) { writeString((String) obj, unshared); } else if (cl.isArray()) { writeArray(obj, desc, unshared); } else if (obj instanceof Enum) { writeEnum((Enum<?>) obj, desc, unshared); } else if (obj instanceof Serializable) { writeOrdinaryObject(obj, desc, unshared); } else { if (extendedDebugInfo) { throw new NotSerializableException(cl.getName() + "\n" + debugInfoStack.toString()); } else { throw new NotSerializableException(cl.getName()); } } - 在进行序列化操作时,会判断要被序列化的类是否是 Enum、Array 和 Serializable 类型,如果都不是则直接抛出 NotSerializableException。Java 中还提供了 Externalizable 接口,也可以实现它来提供序列化能力。Externalizable 继承自 Serializable,该接口中定义了两个抽象方法:writeExternal() 与 readExternal()。当使用 Externalizable 接口来进行序列化与反序列化的时候需要开发人员重写 writeExternal() 与 readExternal() 方法。否则所有变量的值都会变成默认值
- Serializable 和 Externalizable 类通过实现 java.io.Serializable 接口以启用其序列化功能。未实现此接口的类将无法进行序列化或反序列化。可序列化类的所有子类型本身都是可序列化的。如果读者看过 Serializable 的源码,就会发现,他只是一个空的接口,里面什么东西都没有。Serializable 接口没有方法或字段,仅用于标识可序列化的语义。但是,如果一个类没有实现这个接口,想要被序列化的话,就会抛出 java.io.NotSerializableException 异常。它是怎么保证只有实现了该接口的方法才能进行序列化与反序列化的呢?原因是在执行序列化的过程中,会执行到以下代码
- Transient
- transient 关键字的作用是控制变量的序列化,在变量声明前加上该关键字,可以阻止该变量被序列化到文件中,在被反序列化后,transient 变量的值被设为初始值,如 int 型的是 0,对象型的是 null
- 自定义序列化策略
- 在序列化过程中,如果被序列化的类中定义了 writeObject 和 readObject 方法,虚拟机会试图调用对象类里的 writeObject 和 readObject 方法,进行用户自定义的序列化和反序列化。如果没有这样的方法,则默认调用是 ObjectOutputStream 的 defaultWriteObject 方法以及 ObjectInputStream 的 defaultReadObject 方法。用户自定义的 writeObject 和 readObject 方法可以允许用户控制序列化的过程,比如可以在序列化的过程中动态改变序列化的数值。所以,对于一些特殊字段需要定义序列化的策略的时候,可以考虑使用 transient 修饰,并自己重写 writeObject 和 readObject 方法,如 java.util.ArrayList 中就有这样的实现。我们随便找几个 Java 中实现了序列化接口的类,如 String、Integer 等,我们可以发现一个细节,那就是这些类除了实现了 Serializable 外,还定义了一 serialVersionUID
- 什么是 serialVersionUID
- 序列化是将对象的状态信息转换为可存储或传输的形式的过程。我们都知道,Java 对象是保存在 JVM 的堆内存中的,也就是说,如果 JVM 堆不存在了,那么对象也就跟着消失了。而序列化提供了一种方案,可以让你在即使 JVM 停机的情况下也能把对象保存下来的方案。就像我们平时用的 U 盘一样。把 Java 对象序列化成可存储或传输的形式(如二进制流),比如保存在文件中。这样,当再次需要这个对象的时候,从文件中读取出二进制流,再从二进制流中反序列化出对象。虚拟机是否允许反序列化,不仅取决于类路径和功能代码是否一致,一个非常重要的一点是两个类的序列化 ID 是否一致,这个所谓的序列化 ID,就是我们在代码中定义的 serialVersionUID
- 如果 serialVersionUID 变了会怎样
public class SerializableDemo1 { public static void main(String[] args) { //Initializes The Object User1 user = new User1(); user.setName("hollis"); //Write Obj to File ObjectOutputStream oos = null; try { oos = new ObjectOutputStream(new FileOutputStream("tempFile")); oos.writeObject(user); } catch (IOException e) { e.printStackTrace(); } finally { IOUtils.closeQuietly(oos); } } } class User1 implements Serializable { private static final long serialVersionUID = 1L; private String name; public String getName() { return name; } public void setName(String name) { this.name = name; } }- 我们先执行以上代码,把一个 User1 对象写入到文件中。然后我们修改一下 User1 类,把 serialVersionUID 的值改为 2L
class User1 implements Serializable { private static final long serialVersionUID = 2L; private String name; public String getName() { return name; } public void setName(String name) { this.name = name; } }- 然后执行以下代码,把文件中的对象反序列化出来
public class SerializableDemo2 { public static void main(String[] args) { //Read Obj from File File file = new File("tempFile"); ObjectInputStream ois = null; try { ois = new ObjectInputStream(new FileInputStream(file)); User1 newUser = (User1) ois.readObject(); System.out.println(newUser); } catch (IOException e) { e.printStackTrace(); } catch (ClassNotFoundException e) { e.printStackTrace(); } finally { IOUtils.closeQuietly(ois); try { FileUtils.forceDelete(file); } catch (IOException e) { e.printStackTrace(); } } } }- 执行结果
java.io.InvalidClassException: com.hollis.User1; local class incompatible: stream classdesc serialVersionUID = 1, local class serialVersionUID = 2- 可以发现,以上代码抛出了一个 java.io.InvalidClassException,并且指出 serialVersionUID 不一致。这是因为,在进行反序列化时,JVM 会把传来的字节流中的 serialVersionUID 与本地相应实体类的 serialVersionUID 进行比较,如果相同就认为是一致的,可以进行反序列化,否则就会出现序列化版本不一致的异常,即是 InvalidCastException
- 为什么要明确定一个 serialVersionUID
class User1 implements Serializable { private String name; public String getName() { return name; } public void setName(String name) { t his.name = name; } }- 然后我们修改 User1 类,向其中增加一个属性。在尝试将其从文件中读取出来,并进行反序列化
class User1 implements Serializable { private String name; private int age; public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } }- 执行结果
java.io.InvalidClassException: com.hollis.User1; local class incompatible: stream classdesc serialVersionUID = -2986778152837257883, local class serialVersionUID = 7961728318907695402- 同样,抛出了 InvalidClassException,并且指出两个 serialVersionUID 不同,分别是 -2986778152837257883 和 7961728318907695402。从这里可以看出,系统自己添加了一个 serialVersionUID。所以,一旦类实现了 Serializable,就建议明确的定义一个 serialVersionUID。不然在修改类的时候,就会发生异常。serialVersionUID 有两种显示的生成方式: 一是默认的 1L,比如:private staticfinal long serialVersionUID = 1L; 二是根据类名、接口名、成员方法及属性等来生成一个 64 位的哈希字段,比如: private static final long serialVersionUID = xxxxL
- 背后原理
- 为了简化代码量,反序列化的调用链如下: ObjectInputStream.readObject -> readObject0 -> readOrdinaryObject -> readClassDesc -> readNonProxyDesc -> ObjectStreamClass.initNonProxy

- 在反序列化过程中,对 serialVersionUID 做了比较,如果发现不相等,则直接抛出异常,深入看一下 getSerialVersionUID 方法
public long getSerialVersionUID() { // REMIND: synchronize instead of relying on volatile? if (suid == null) { suid = AccessController.doPrivileged(new PrivilegedAction<Long>() { public Long run() { return computeDefaultSUID(cl); } }); } return suid.longValue(); }- 在没有定义 serialVersionUID 的时候,会调用 computeDefaultSUID 方法,生成一个默认的 serialVersionUID
- 为了简化代码量,反序列化的调用链如下: ObjectInputStream.readObject -> readObject0 -> readOrdinaryObject -> readClassDesc -> readNonProxyDesc -> ObjectStreamClass.initNonProxy
- IDEA 提示
- 为了确保我们不会忘记定义 serialVersionUID,可以调节一下 Intellij IDEA 的配置,在实现 Serializable 接口后,如果没定义 serialVersionUID 的话,IDEA(eclipse 一样)会进行提示,并且可以一键生成一个,当然,这个配置并不是默认生效的,需要手动到 IDEA 中设置一下



- 为了确保我们不会忘记定义 serialVersionUID,可以调节一下 Intellij IDEA 的配置,在实现 Serializable 接口后,如果没定义 serialVersionUID 的话,IDEA(eclipse 一样)会进行提示,并且可以一键生成一个,当然,这个配置并不是默认生效的,需要手动到 IDEA 中设置一下
- 总结
- serialVersionUID 是用来验证版本一致性的。所以在做兼容性升级的时候,不要改变类中 serialVersionUID 的值
- 如果一个类实现了 Serializable 接口,一定要记得定义 serialVersionUID,否则会发生异常。可以在 IDE 中通过设置,让他帮忙提示,并且可以一键快速生成一个 serialVersionUID
- 之所以会发生异常,是因为反序列化过程中做了校验,并且如果没有明确定义的话,会根据类的属性自动生成一个
- 《Java 开发手册》中有以下规定
- 序列化底层原理
- Java 对象的序列化
- Java 平台允许我们在内存中创建可复用的 Java 对象,但一般情况下,只有当 JVM 处于运行时,这些对象才可能存在,即,这些对象的生命周期不会比 JVM 的生命周期更长。但在现实应用中,就可能要求在 JVM 停止运行之后能够保存(持久化)指定的对象,并在将来重新读取被保存的对象。Java 对象序列化就能够帮助我们实现该功能。使用 Java 对象序列化,在保存对象时,会把其状态保存为一组字节,在未来,再将这些字节组装成对象。必须注意地是,对象序列化保存的是对象的"状态",即它的成员变量。由此可知,对象序列化不会关注类中的静态变量。除了在持久化对象时会用到对象序列化之外,当使用 RMI(远程方法调用),或在网络中传递对象时,都会用到对象序列化。Java 序列化 API 为处理对象序列化提供了一个标准机制,该 API 简单易用
- 如何对 Java 对象进行序列化与反序列化
- 在 Java 中,只要一个类实现了 java.io.Serializable 接口,那么它就可以被序列化
- code 1 创建一个 User 类,用于序列化及反序列化
package com.hollis; import java.io.Serializable; import java.util.Date; /** * Created by hollis on 16/2/2. */ public class User implements Serializable{ private String name; private int age; private Date birthday; private transient String gender; private static final long serialVersionUID = -6849794470754667710L; public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } public Date getBirthday() { return birthday; } public void setBirthday(Date birthday) { this.birthday = birthday; } public String getGender() { return gender; } public void setGender(String gender) { this.gender = gender; } @Override public String toString() { return "User{" + "name='" + name + '\'' + ", age=" + age + ", gender=" + gender + ", birthday=" + birthday + '}'; } } - code 2 对 User 进行序列化及反序列化的 Demopackage com.hollis;
import org.apache.commons.io.FileUtils; import org.apache.commons.io.IOUtils; import java.io.*; import java.util.Date; /** * Created by hollis on 16/2/2. */ public class SerializableDemo { public static void main(String[] args) { //Initializes The Object User user = new User(); user.setName("hollis"); user.setGender("male"); user.setAge(23); user.setBirthday(new Date()); System.out.println(user); //Write Obj to File ObjectOutputStream oos = null; try { oos = new ObjectOutputStream(new FileOutputStream("tempFile")); oos.writeObject(user); } catch (IOException e) { e.printStackTrace(); } finally { IOUtils.closeQuietly(oos); } //Read Obj from File File file = new File("tempFile"); ObjectInputStream ois = null; try { ois = new ObjectInputStream(new FileInputStream(file)); User newUser = (User) ois.readObject(); System.out.println(newUser); } catch (IOException e) { e.printStackTrace(); } catch (ClassNotFoundException e) { e.printStackTrace(); } finally { IOUtils.closeQuietly(ois); try { FileUtils.forceDelete(file); } catch (IOException e) { e.printStackTrace(); } } } } //output //User{name='hollis', age=23, gender=male, birthday=Tue Feb 02 17:37:38 CST 2016} //User{name='hollis', age=23, gender=null, birthday=Tue Feb 02 17:37:38 CST 2016}
- 序列化及反序列化相关知识
- 在 Java 中,只要一个类实现了 java.io.Serializable 接口,那么它就可以被序列化
- 通过 ObjectOutputStream 和 ObjectInputStream 对对象进行序列化及反序列化
- 虚拟机是否允许反序列化,不仅取决于类路径和功能代码是否一致,一个非常重要的一点是两个类的序列化 ID 是否一致(就是 private static final long serialVersionUID)
- 序列化并不保存静态变量
- 要想将父类对象也序列化,就需要让父类也实现 Serializable 接口
- Transient 关键字的作用是控制变量的序列化,在变量声明前加上该关键字,可以阻止该变量被序列化到文件中,在被反序列化后,transient 变量的值被设为初始值,如 int 型的是 0,对象型的是 null
- 服务器端给客户端发送序列化对象数据,对象中有一些数据是敏感的,比如密码字符串等,希望对该密码字段在序列化时,进行加密,而客户端如果拥有解密的密钥,只有在客户端进行反序列化时,才可以对密码进行读取,这样可以一定程度保证序列化对象的数据安全
- ArrayList 的序列化
- code 3
public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable { private static final long serialVersionUID = 8683452581122892189L; transient Object[] elementData; // non-private to simplify nested class access private int size; } - 从上面的代码中可以知道ArrayList实现了 java.io.Serializable 接口,那么我们就可以对它进行序列化及反序列化。因为 elementData 是 transient 的
- code 4
public static void main(String[] args) throws IOException, ClassNotFoundException { List<String> stringList = new ArrayList<String>(); stringList.add("hello"); stringList.add("world"); stringList.add("hollis"); stringList.add("chuang"); System.out.println("init StringList" + stringList); ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream("stringlist")); objectOutputStream.writeObject(stringList); IOUtils.close(objectOutputStream); File file = new File("stringlist"); ObjectInputStream objectInputStream = new ObjectInputStream(new FileInputStream(file)); List<String> newStringList = (List<String>)objectInputStream.readObject(); IOUtils.close(objectInputStream); if(file.exists()){ file.delete(); } System.out.println("new StringList" + newStringList); } // init StringList[hello, world, hollis, chuang] // new StringList[hello, world, hollis, chuang] - writeObject 和 readObject 方法
- 在 ArrayList 中定义了来个方法: writeObject 和 readObject
- 在序列化过程中,如果被序列化的类中定义了 writeObject 和 readObject 方法,虚拟机会试图调用对象类里的 writeObject 和 readObject 方法,进行用户自定义的序列化和反序列化。如果没有这样的方法,则默认调用是 ObjectOutputStream 的 defaultWriteObject方法以及 ObjectInputStream 的 defaultReadObject 方法。用户自定义的 writeObject 和 readObject 方法可以允许用户控制序列化的过程,比如可以在序列化的过程中动态改变序列化的数值
- code 5
private void readObject(java.io.ObjectInputStream s) throws java.io.IOException, ClassNotFoundException { elementData = EMPTY_ELEMENTDATA; // Read in size, and any hidden stuff s.defaultReadObject(); // Read in capacity s.readInt(); // ignored if (size > 0) { // be like clone(), allocate array based upon size not capacity ensureCapacityInternal(size); Object[] a = elementData; // Read in all elements in the proper order. for (int i=0; i<size; i++) { a[i] = s.readObject(); } } } - code 6
private void writeObject(java.io.ObjectOutputStream s) throws java.io.IOException{ // Write out element count, and any hidden stuff int expectedModCount = modCount; s.defaultWriteObject(); // Write out size as capacity for behavioural compatibility with clone() s.writeInt(size); // Write out all elements in the proper order. for (int i=0; i<size; i++) { s.writeObject(elementData[i]); } if (modCount != expectedModCount) { throw new ConcurrentModificationException(); } } - why transient
- ArrayList 实际上是动态数组,每次在放满以后自动增长设定的长度值,如果数组自动增长长度设为 100,而实际只放了一个元素,那就会序列化 99 个 null 元素。为了保证在序列化的时候不会将这么多 null 同时进行序列化,ArrayList 把元素数组设置为 transient
- why writeObject and readObject
- 前面说过,为了防止一个包含大量空对象的数组被序列化,为了优化存储,所以,ArrayList 使用 transient 来声明 elementData。 但是,作为一个集合,在序列化过程中还必须保证其中的元素可以被持久化下来,所以,通过重写 writeObject 和 readObject 方法的方式把其中的元素保留下来。writeObject 方法把 elementData 数组中的元素遍历的保存到输出流(ObjectOutputStream)中。readObject 方法从输入流(ObjectInputStream)中读出对象并保存赋值到 elementData 数组中
- 至此,我们先试着来回答刚刚提出的问题:
- 如何自定义的序列化和反序列化策略?
- 答:可以通过在被序列化的类中增加 writeObject 和 readObject 方法。那么问题又来了:虽然 ArrayList 中写了 writeObject 和 readObject 方法,但是这两个方法并没有显示的被调用啊。那么如果一个类中包含 writeObject 和 readObject 方法,那么这两个方法是怎么被调用的呢?
- ObjectOutputStream
- 从 code 4 中,我们可以看出,对象的序列化过程通过 ObjectOutputStream 和 ObjectInputputStream 来实现的
- 这里给出 ObjectOutputStream 的 writeObject 的调用栈:writeObject —> writeObject0 —>writeOrdinaryObject—>writeSerialData—>invokeWriteObject
void invokeWriteObject(Object obj, ObjectOutputStream out) throws IOException, UnsupportedOperationException{ if (writeObjectMethod != null) { try { writeObjectMethod.invoke(obj, new Object[]{ out }); } catch (InvocationTargetException ex) { Throwable th = ex.getTargetException(); if (th instanceof IOException) { throw (IOException) th; } else { throwMiscException(th); } } catch (IllegalAccessException ex) { // should not occur, as access checks have been suppressed throw new InternalError(ex); } } else { throw new UnsupportedOperationException(); } } - 其中 writeObjectMethod.invoke(obj, new Object[]{ out });是关键,通过反射的方式调用 writeObjectMethod 方法。官方是这么解释这个 writeObjectMethod 的:class-defined writeObject method, or null if none;在我们的例子中,这个方法就是我们在 ArrayList 中定义的 writeObject 方法。通过反射的方式被调用了。至此,我们先试着来回答刚刚提出的问题:
- 如果一个类中包含 writeObject 和 readObject 方法,那么这两个方法是怎么被调用的?
- 答:在使用 ObjectOutputStream 的 writeObject 方法和 ObjectInputStream 的readObject 方法时,会通过反射的方式调用
- Serializable 接口的定义
- 我们再回到刚刚 ObjectOutputStream 的 writeObject 的调用栈:writeObject —> writeObject0 —>writeOrdinaryObject—>writeSerialData—>invokeWriteObject
if (obj instanceof String) { writeString((String) obj, unshared); } else if (cl.isArray()) { writeArray(obj, desc, unshared); } else if (obj instanceof Enum) { writeEnum((Enum<?>) obj, desc, unshared); } else if (obj instanceof Serializable) { writeOrdinaryObject(obj, desc, unshared); } else { if (extendedDebugInfo) { throw new NotSerializableException(cl.getName() + "\n" + debugInfoStack.toString()); } else { throw new NotSerializableException(cl.getName()); } }- 在进行序列化操作时,会判断要被序列化的类是否是 Enum、Array 和 Serializable 类型,如果不是则直接抛出 NotSerializableException
- code 3
- 总结
- 如果一个类想被序列化,需要实现Serializable接口。否则将抛出 NotSerializableException 异常,这是因为,在序列化操作过程中会对类型进行检查,要求被序列化的类必须属于 Enum、Array 和 Serializable 类型其中的任何一种
- 在变量声明前加上该关键字,可以阻止该变量被序列化到文件中
- 在类中增加 writeObject 和 readObject 方法可以实现自定义序列化策略
- Java 对象的序列化
- 序列化如何破坏单例模式
- 序列化对单例的破坏
- code1
package com.hollis; import java.io.Serializable; /** * Created by hollis on 16/2/5. * 使用双重校验锁方式实现单例 */ public class Singleton implements Serializable{ private volatile static Singleton singleton; private Singleton (){} public static Singleton getSingleton() { if (singleton == null) { synchronized (Singleton.class) { if (singleton == null) { singleton = new Singleton(); } } } return singleton; } } - code 2
package com.hollis; import java.io.*; /** * Created by hollis on 16/2/5. */ public class SerializableDemo1 { //为了便于理解,忽略关闭流操作及删除文件操作。真正编码时千万不要忘记 //Exception 直接抛出 public static void main(String[] args) throws IOException, ClassNotFoundException { //Write Obj to file ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("tempFile")); oos.writeObject(Singleton.getSingleton()); //Read Obj from file File file = new File("tempFile"); ObjectInputStream ois = new ObjectInputStream(new FileInputStream(file)); Singleton newInstance = (Singleton) ois.readObject(); //判断是否是同一个对象 System.out.println(newInstance == Singleton.getSingleton()); } } //false - 通过对 Singleton 的序列化与反序列化得到的对象是一个新的对象,这就破坏了 Singleton 的单例性
- code1
- ObjectInputStream
- 对象的序列化过程通过 ObjectOutputStream 和 ObjectInputputStream 来实现的,那么带着刚刚的问题,分析一下 ObjectInputputStream 的 readObject 方法执行情况到底是怎样的,为了节省篇幅,这里给出 ObjectInputStream 的 readObject 的调用栈

- code 3
private Object readOrdinaryObject(boolean unshared) throws IOException{ //此处省略部分代码 Object obj; try { obj = desc.isInstantiable() ? desc.newInstance() : null; } catch (Exception ex) { throw (IOException) new InvalidClassException(desc.forClass().getName(),"unable to create instance").initCause(ex); } //此处省略部分代码 if (obj != null && handles.lookupException(passHandle) == null && desc.hasReadResolveMethod()){ Object rep = desc.invokeReadResolve(obj); if (unshared && rep.getClass().isArray()) { rep = cloneArray(rep); } if (rep != obj) { handles.setObject(passHandle, obj = rep); } } return obj; } - code 3.1
Object obj; try { obj = desc.isInstantiable() ? desc.newInstance() : null; } catch (Exception ex) { throw (IOException) new InvalidClassException(desc.forClass().getName(),"unable to create instance").initCause(ex); }- 这里创建的这个 obj 对象,就是本方法要返回的对象,也可以暂时理解为是 ObjectInputStream 的 readObject 返回的对象

- isInstantiable:如果一个 serializable/externalizable 的类可以在运行时被实例化,那么该方法就返回 true。针对 serializable 和 externalizable 我会在其他文章中介绍
- desc.newInstance:该方法通过反射的方式调用无参构造方法新建一个对象。所以。到目前为止,也就可以解释,为什么序列化可以破坏单例了?答:序列化会通过反射调用无参数的构造方法创建一个新的对象
- 这里创建的这个 obj 对象,就是本方法要返回的对象,也可以暂时理解为是 ObjectInputStream 的 readObject 返回的对象
- 对象的序列化过程通过 ObjectOutputStream 和 ObjectInputputStream 来实现的,那么带着刚刚的问题,分析一下 ObjectInputputStream 的 readObject 方法执行情况到底是怎样的,为了节省篇幅,这里给出 ObjectInputStream 的 readObject 的调用栈
- 防止序列化破坏单例模式
- 先给出解决方案,然后再具体分析原理:只要在 Singleton 类中定义 readResolve 就可以解决该问题
- code 4
package com.hollis; import java.io.Serializable; /** * Created by hollis on 16/2/5. * 使用双重校验锁方式实现单例 */ public class Singleton implements Serializable{ private volatile static Singleton singleton; private Singleton (){} public static Singleton getSingleton() { if (singleton == null) { synchronized (Singleton.class) { if (singleton == null) { singleton = new Singleton(); } } } return singleton; } private Object readResolve() { return singleton; } } - 还是运行以下测试类
package com.hollis; import java.io.*; /** * Created by hollis on 16/2/5. */ public class SerializableDemo1 { //为了便于理解,忽略关闭流操作及删除文件操作。真正编码时千万不要忘记 //Exception 直接抛出 public static void main(String[] args) throws IOException, ClassNotFoundException { //Write Obj to file ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("tempFile")); oos.writeObject(Singleton.getSingleton()); //Read Obj from file File file = new File("tempFile"); ObjectInputStream ois = new ObjectInputStream(new FileInputStream(file)); Singleton newInstance = (Singleton) ois.readObject(); //判断是否是同一个对象 System.out.println(newInstance == Singleton.getSingleton()); } } //true - code 3.2
if (obj != null && handles.lookupException(passHandle) == null && desc.hasReadResolveMethod()){ Object rep = desc.invokeReadResolve(obj); if (unshared && rep.getClass().isArray()) { rep = cloneArray(rep); } if (rep != obj) { handles.setObject(passHandle, obj = rep); } }- hasReadResolveMethod:如果实现了 serializable 或者 externalizable 接口的类中包含 readResolve 则返回 true
- invokeReadResolve:通过反射的方式调用要被反序列化的类的 readResolve 方法。所以,原理也就清楚了,主要在 Singleton 中定义 readResolve 方法,并在该方法中指定要返回的对象的生成策略,就可以防止单例被破坏。 总结在涉及到序列化的场景时,要格外注意他对单例的破坏
- 序列化对单例的破坏
- 什么是序列化与反序列化
-
注解
-
元注解
- 说简单点,就是定义其他注解的注解。比如 Override 这个注解,就不是一个元注解。而是通过元注解定义出来的
@Target(ElementType.METHOD) @Retention(RetentionPolicy.SOURCE) public @interface Override { } - 这里面的 @Target @Retention 就是元注解
- 元注解有四个
- @Target:用于指定被修饰的注解修饰哪些程序单元,也就是上面说的类,方法,字段
- @Retention:用于指定被修饰的注解被保留多长时间,分别 SOURCE(注解仅存在于源码中,在 class 字节码文件中不包含),CLASS(默认的保留策略,注解会在 class 字节码文件中存在,但运行时无法获取),RUNTIME(注解会在 class 字节码文件中存在,在运行时可以通过反射获取到)三种类型,如果想要在程序运行过程中通过反射来获取注解的信息需要将 Retention 设置为 RUNTIME
- @Documented:用于指定被修饰的注解类将被 javadoc 工具提取成文档
- @Inherited:用于指定被修饰的注解类将具有继承性
- 说简单点,就是定义其他注解的注解。比如 Override 这个注解,就不是一个元注解。而是通过元注解定义出来的
-
自定义注解
- 除了元注解,都是自定义注解。通过元注解定义出来的注解。如我们常用的 Override 、Autowire 等。日常开发中也可以自定义一个注解,这些都是自定义注解
-
Java 中常用注解使用
- @Override 表示当前方法覆盖了父类的方法
- @Deprecation 表示方法已经过时,方法上有横线,使用时会有警告
- @SuppressWarnings 表示关闭一些警告信息(通知 java 编译器忽略特定的编译警告)。SafeVarargs (jdk1.7 更新) 表示:专门为抑制“堆污染”警告提供的
- @FunctionalInterface (jdk1.8 更新) 表示:用来指定某个接口必须是函数式接口,否则就会编译出错
-
注解与反射的结合
- 可以通过反射来判断类,方法,字段上是否有某个注解以及获取注解中的值
Class<?> clz = bean.getClass(); Method[] methods = clz.getMethods(); for (Method method : methods) { if (method.isAnnotationPresent(EnableAuth.class)) { String name = method.getAnnotation(EnableAuth.class).name(); } } - 示例
@Retention(RetentionPolicy.RUNTIME) @Target(ElementType.FIELD) @Documented @Inherited public @interface MyAnno { String value() default "有注解"; } // @Data @ToString public class Person { @MyAnno private String stra; private String strb; private String strc; public Person(String str1,String str2,String str3){ super(); this.stra = str1; this.strb = str2; this.strc = str3; } } // public class MyTest { public static void main(String[] args) { //初始化全都赋值无注解 Person person = new Person("无注解","无注解","无注解"); //解析注解 doAnnoTest(person); System.out.println(person.toString()); } private static void doAnnoTest(Object obj) { Class clazz = obj.getClass(); Field[] declareFields = clazz.getDeclaredFields(); for (Field field:declareFields) { //检查该类是否使用了某个注解 if(clazz.isAnnotationPresent(MyAnno.class)){ MyAnno anno = field.getAnnotation(MyAnno.class); if(anno!=null){ String fieldName = field.getName(); try { Method setMethod = clazz.getDeclaredMethod("set" + fieldName.substring(0, 1).toUpperCase() + fieldName.substring(1),String.class); //获取注解的属性 String annoValue = anno.value(); //将注解的属性值赋给对应的属性 setMethod.invoke(obj,annoValue); }catch (NoSuchMethodException e){ e.printStackTrace(); } catch (IllegalAccessException e) { e.printStackTrace(); } catch (InvocationTargetException e) { e.printStackTrace(); } } } } } }
- 可以通过反射来判断类,方法,字段上是否有某个注解以及获取注解中的值
-
Spring 常用注解
- 常用注解
- @Configuration 把一个类作为一个 IoC 容器,它的某个方法头上如果注册了
- @Bean,就会作为这个 Spring 容器中的 Bean
- @Scope 注解 作用域
- @Lazy(true) 表示延迟初始化
- @Service 用于标注业务层组件
- @Controller 用于标注控制层组件
- @Repository 用于标注数据访问组件,即 DAO 组件
- @Component 泛指组件,当组件不好归类的时候,我们可以使用这个注解进行标注
- @Scope 用于指定 scope 作用域的(用在类上)
- @PostConstruct 用于指定初始化方法(用在方法上)
- @PreDestory 用于指定销毁方法(用在方法上)
- @DependsOn:定义 Bean 初始化及销毁时的顺序
- @Primary:自动装配时当出现多个 Bean 候选者时,被注解为 @Primary 的 Bean 将作为首选者,否则将抛出异常
- @Autowired 默认按类型装配,如果我们想使用按名称装配,可以结合 @Qualifier 注解一起使用。如下: @Autowired @Qualifier(“personDaoBean”) 存在多个实例配合使用
- @Resource 默认按名称装配,当找不到与名称匹配的 bean 才会按类型装配
- @PostConstruct 初始化注解
- @PreDestroy 摧毁注解 默认单例启动就加载
- Spring 中的这几个注解有什么区别:@Component 、@Repository、@Service、 @Controller
- @Component 指的是组件: @Controller,@Repository 和 @Service 注解都被 @Component 修饰,用于代码中区分表现层,持久层和业务层的组件,代码中组件不好归类时可以使用 @Component 来标注
- 当前版本只有区分的作用,未来版本可能会添加更丰富的功能
- 常用注解
-
-
单元测试
- Junit
- 介绍
- JUnit 是一个 Java 语言的单元测试框架。JUnit 促进了“先测试后编码”的理念,强调建立测试数据的一段代码,可以先测试,然后再应用。这个方法就好比“测试一点,编码一点,测试一点,编码一点……”,增加了程序员的产量和程序的稳定性,可以减少程序员的压力和花费在排错上的时间
- 特点
- JUnit 是一个开放的资源框架,用于编写和运行测试
- 提供注释来识别测试方法
- 提供断言来测试预期结果
- 提供测试运行来运行测试
- JUnit 测试允许你编写代码更快,并能提高质量
- JUnit 优雅简洁。没那么复杂,花费时间较少
- JUnit 测试可以自动运行并且检查自身结果并提供即时反馈。所以也没有必要人工梳理测试结果的报告
- JUnit 测试可以被组织为测试套件,包含测试用例,甚至其他的测试套件
- JUnit 在一个条中显示进度。如果运行良好则是绿色;如果运行失败,则变成红色
- JUnit 知识经常 和测试驱动开发的讨论融合在一起。可以参考 Kent Beck 的《Test -Driven Development: By Example》一书(有中文版和影印版)
- mock
- 在 Java 中可以使用 mock 对象来模拟真实对象来进行单元测试
- 介绍
- Junit
-
API&SPI
- API 和 SPI 的关系和区别
- Java 中区分 API 和 SPI,通俗的讲:API 和 SPI 都是相对的概念,他们的差别只在语义上,API 直接被应用开发人员使用,SPI 被框架扩展人员使用
- API Application Programming Interface。大多数情况下,都是实现方来制定接口并完成对接口的不同实现,调用方仅仅依赖却无权选择不同实现
- SPI Service Provider Interface。而如果是调用方来制定接口,实现方来针对接口来实现不同的实现。调用方来选择自己需要的实现方
- Java 中区分 API 和 SPI,通俗的讲:API 和 SPI 都是相对的概念,他们的差别只在语义上,API 直接被应用开发人员使用,SPI 被框架扩展人员使用
- 如何定义 SPI
- 步骤 1、定义一组接口 (假设是 org.foo.demo.IShout),并写出接口的一个或多个实现,(假设是 org.foo.demo.animal.Dog、org.foo.demo.animal.Cat)
public interface IShout { void shout(); } public class Cat implements IShout { @Override public void shout() { System.out.println("miao miao"); } } public class Dog implements IShout { @Override public void shout() { System.out.println("wang wang"); } } - 步骤 2、在 src/main/resources/ 下建立 /META-INF/services 目录, 新增一个以接口命名的文件 (org.foo.demo.IShout 文件),内容是要应用的实现类(这里是org.foo.demo.animal.Dog 和 org.foo.demo.animal.Cat,每行一个类)
org.foo.demo.animal.Dog org.foo.demo.animal.Cat - 步骤 3、使用 ServiceLoader 来加载配置文件中指定的实现
public class SPIMain { public static void main(String[] args) { ServiceLoader<IShout> shouts = ServiceLoader.load(IShout.class); for (IShout s : shouts) { s.shout(); } } } // 代码输出 // wang wang // miao miao
- 步骤 1、定义一组接口 (假设是 org.foo.demo.IShout),并写出接口的一个或多个实现,(假设是 org.foo.demo.animal.Dog、org.foo.demo.animal.Cat)
- SPI 的实现原理
- 看 ServiceLoader 类的签名类的成员变量
public final class ServiceLoader<S> implements Iterable<S>{ private static final String PREFIX = "META-INF/services/"; // 代表被加载的类或者接口 private final Class<S> service; // 用于定位,加载和实例化 providers 的类加载器 private final ClassLoader loader; // 创建 ServiceLoader 时采用的访问控制上下文 private final AccessControlContext acc; // 缓存 providers,按实例化的顺序排列 private LinkedHashMap<String,S> providers = new LinkedHashMap<>(); // 懒查找迭代器 private LazyIterator lookupIterator; ...... } - 应用程序调用 ServiceLoader.load 方法
- ServiceLoader.load 方法内先创建一个新的 ServiceLoader,并实例化该类中的成员变量,包括:
- loader(ClassLoader 类型,类加载器)
- acc(AccessControlContext 类型,访问控制器)
- providers(LinkedHashMap 类型,用于缓存加载成功的类)
- lookupIterator(实现迭代器功能)
- 应用程序通过迭代器接口获取对象实例
- ServiceLoader 先判断成员变量 providers 对象中(LinkedHashMap 类型)是否有缓存实例对象,如果有缓存,直接返回
- 如果没有缓存,执行类的装载:读取 META-INF/services/ 下的配置文件,获得所有能被实例化的类的名称
- 通过反射方法 Class.forName() 加载类对象,并用 instance() 方法将类实例化
- 把实例化后的类缓存到 providers 对象中(LinkedHashMap 类型)
- 然后返回实例对象
- ServiceLoader.load 方法内先创建一个新的 ServiceLoader,并实例化该类中的成员变量,包括:
- 看 ServiceLoader 类的签名类的成员变量
- API 和 SPI 的关系和区别
-
时间处理
- 时区
- 时区是地球上的区域使用同一个时间定义
- 冬令时和夏令时
- 夏令时、冬令时的出现,是为了充分利用夏天的日照,所以时钟要往前拨快一小时,冬天再把表往回拨一小时。其中夏令时从 3 月第二个周日持续到 11 月第一个周日
- 冬令时: 北京和洛杉矶时差:16 北京和纽约时差:13
- 夏令时: 北京和洛杉矶时差:15 北京和纽约时差:12
- 时间戳
- 时间戳(timestamp),一个能表示一份数据在某个特定时间之前已经存在的、 完整的、 可验证的数据,通常是一个字符序列,唯一地标识某一刻的时间
- 时间戳是指格林威治时间 1970 年 01 月 01 日 00 时 00 分 00 秒(北京时间 1970 年 0 1 月 01 日 08 时 00 分 00 秒)起至现在的总秒数。通俗的讲,时间戳是一份能够表示一份数据在一个特定时间点已经存在的完整的可验证的数据
- 格林威治时间
- 格林尼治平时(英语:Greenwich Mean Time,GMT)是指位于英国伦敦郊区的皇家格林尼治天文台当地的平太阳时,因为本初子午线被定义为通过那里的经线
- 自 1924 年 2 月 5 日开始,格林尼治天文台负责每隔一小时向全世界发放调时信息。 一般使用 GMT+8 表示中国的时间,是因为中国位于东八区,时间上比格林威治时间快 8 个小时
- CET,UTC,GMT,CST 几种常见时间的含义和关系
- CET:欧洲中部时间(英語:Central European Time,CET)是比世界标准时间(UTC)早一个小时的时区名称之一。它被大部分欧洲国家和部分北非国家采用。冬季时间为 UTC +1,夏季欧洲夏令时为 UTC+2
- UTC:协调世界时,又称世界标准时间或世界协调时间,简称 UTC,协调世界时是以原子时秒长为基础,在时刻上尽量接近于世界时的一种时间计量系统
- GMT:格林尼治标准时间
- CST:北京时间,China Standard Time,又名中国标准时间,是中国的标准时间。在时区划分上,属东八区,比协调世界时早 8 小时,记为 UTC+8,与中华民国国家标准时间(旧称“中原标准时间”)、香港时间和澳门时间和相同
- 关系:CET=UTC/GMT + 1 小时 CST=UTC/GMT +8 小时 CST=CET+9
- SimpleDateFormat 的线程安全性问题

- SimpleDateFormat 用法
- SimpleDateFormat 是 Java 提供的一个格式化和解析日期的工具类。它允许进行格式化(日期 -> 文本)、解析(文本 -> 日期)和规范化。SimpleDateFormat 使得可以选择任何用户定义的日期-时间格式的模式
- 在 Java 中,可以使用 SimpleDateFormat 的 format 方法,将一个 Date 类型转化成 String 类型,并且可以指定输出格式
//Date 转 String Date data = new Date(); SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); String dataStr = sdf.format(data); System.out.println(dataStr); - 以上代码,转换的结果是:2018-11-25 13 00,日期和时间格式由"日期和时间模式"字符串指定。如果你想要转换成其他格式,只要指定不同的时间模式就行了。在 Java 中,可以使用 SimpleDateFormat 的 parse 方法,将一个 String 类型转化成 Date 类型
// String 转 Data System.out.println(sdf.parse(dataStr));
- 日期和时间模式表达方法
- 在使用 SimpleDateFormat 的时候,需要通过字母来描述时间元素,并组装成想要的日期和时间模式。常用的时间元素和字母的对应表如下


- 在使用 SimpleDateFormat 的时候,需要通过字母来描述时间元素,并组装成想要的日期和时间模式。常用的时间元素和字母的对应表如下
- 输出不同时区的时间
- 默认情况下,如果不指明,在创建日期的时候,会使用当前计算机所在的时区作为默认时区,这也是为什么我们通过只要使用 new Date() 就可以获取中国的当前时间的原因
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); sdf.setTimeZone(TimeZone.getTimeZone("America/Los_Angeles")); System.out.println(sdf.format(Calendar.getInstance().getTime()));
- 默认情况下,如果不指明,在创建日期的时候,会使用当前计算机所在的时区作为默认时区,这也是为什么我们通过只要使用 new Date() 就可以获取中国的当前时间的原因
- SimpleDateFormat 线程安全性
- 示例
public class Main { private static SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); public static void main(String[] args) { simpleDateFormat.setTimeZone(TimeZone.getTimeZone("America/New_York")); System.out.println(simpleDateFormat.format(Calendar.getInstance().getTime())); } } - 问题重现
/** * @author Hollis */ public class Main { /** * 定义一个全局的 SimpleDateFormat */ private static SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); /** * 使用 ThreadFactoryBuilder 定义一个线程池 */ private static ThreadFactory namedThreadFactory = new ThreadFactoryBuilder().setNameFormat("demo-pool-%d").build(); private static ExecutorService pool = new ThreadPoolExecutor(5, 200, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>(1024), namedThreadFactory, new ThreadPoolExecutor.AbortPolicy() ); /** * 定义一个 CountDownLatch,保证所有子线程执行完之后主线程再执行 */ private static CountDownLatch countDownLatch = new CountDownLatch(100); public static void main(String[] args) { //定义一个线程安全的 HashSet Set<String> dates = Collections.synchronizedSet(new HashSet<String>()); for (int i = 0; i < 100; i++) { //获取当前时间 Calendar calendar = Calendar.getInstance(); int finalI = i; pool.execute(() -> { //时间增加 calendar.add(Calendar.DATE, finalI); //通过 simpleDateFormat 把时间转换成字符串 String dateString = simpleDateFormat.format(calendar.getTime()); //把字符串放入 Set 中 dates.add(dateString); //countDown countDownLatch.countDown(); }); } //阻塞,直到 countDown 数量为 0 countDownLatch.await(); //输出去重后的时间个数 System.out.println(dates.size()); } }- 正常情况下,以上代码输出结果应该是 100。但是实际执行结果是一个小于 100 的数字
- 线程不安全原因
- SimpleDateFormat 中的 format 方法在执行过程中,会使用一个成员变量 calendar 来保存时间。这其实就是问题的关键
- 由于我们在声明 SimpleDateFormat 的时候,使用的是 static 定义的。那么这个 SimpleDateFormat 就是一个共享变量,随之,SimpleDateFormat 中的 calendar 也就可以被多个线程访问到
- 假设线程 1刚刚执行完 calendar.setTime 把时间设置成 2018-11-11,还没等执行完,线程 2 又执行了 calendar.setTime 把时间改成了 2018-12-12。这时候线程 1 继续往下执行,拿到的 calendar.getTime 得到的时间就是线程 2 改过之后的。除了 format 方法以外,SimpleDateFormat 的 parse 方法也有同样的问题。所以,不要把 SimpleDateFormat 作为一个共享变量使用
- 如何解决
- 使用局部变量
for (int i = 0; i < 100; i++) { //获取当前时间 Calendar calendar = Calendar.getInstance(); int finalI = i; pool.execute(() -> { // SimpleDateFormat 声明成局部变量 SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); //时间增加 calendar.add(Calendar.DATE, finalI); //通过 simpleDateFormat 把时间转换成字符串 String dateString = simpleDateFormat.format(calendar.getTime()); //把字符串放入 Set 中 dates.add(dateString); //countDown countDownLatch.countDown(); }); } - 加同步锁
for (int i = 0; i < 100; i++) { //获取当前时间 Calendar calendar = Calendar.getInstance(); int finalI = i; pool.execute(() -> { //加锁 synchronized (simpleDateFormat) { //时间增加 calendar.add(Calendar.DATE, finalI); //通过 simpleDateFormat 把时间转换成字符串 String dateString = simpleDateFormat.format(calendar.getTime()); //把字符串放入 Set 中 dates.add(dateString); //countDown countDownLatch.countDown(); } }); } - 使用 ThreadLocal
/** * 使用 ThreadLocal 定义一个全局的 SimpleDateFormat */ private static ThreadLocal<SimpleDateFormat> simpleDateFormatThreadLocal = new ThreadLocal<SimpleDateFormat>() { @Override protected SimpleDateFormat initialValue() { return new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); } }; //用法 String dateString = simpleDateFormatThreadLocal.get().format(calendar.getTime()); - 使用 DateTimeFormatter
//解析日期 String dateStr= "2016 年 10 月 25 日"; DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy 年 MM 月 dd 日"); LocalDate date= LocalDate.parse(dateStr, formatter); //日期转换为字符串 LocalDateTime now = LocalDateTime.now(); DateTimeFormatter format = DateTimeFormatter.ofPattern("yyyy 年 MM 月 dd 日 hh:mma"); String nowStr = now .format(format); System.out.println(nowStr);
- 使用局部变量
- 示例
- SimpleDateFormat 用法
- Java 8 中的时间处理
- Java 8 通过发布新的 Date-Time API (JSR 310)来进一步加强对日期与时间的处理
- 在旧版的 Java 中,日期时间 API 存在诸多问题,其中有:
- 非线程安全 − java.util.Date 是非线程安全的,所有的日期类都是可变的,这是Java 日期类最大的问题之一
- 设计很差 − Java 的日期/时间类的定义并不一致,在 java.util 和 java.sql 的包中都有日期类,此外用于格式化和解析的类在 java.text 包中定义。java.util.Date 同时包含日期和时间,而 java.sql.Date 仅包含日期,将其纳入 java.sql 包并不合理。另外这两个类都有相同的名字,这本身就是一个非常糟糕的设计
- 时区处理麻烦 − 日期类并不提供国际化,没有时区支持,因此 Java 引入了 java.util. Calendar 和 java.util.TimeZone 类,但他们同样存在上述所有的问题
- 在 Java8 中,新的时间及⽇期 API 位于 java.time 包中,该包中有哪些重要的类。分别代表了什么
- Instant:时间戳
- Duration:持续时间,时间差
- LocalDate:只包含⽇期,⽐如:2016-10-20
- LocalTime:只包含⽇期,⽐如:23 10
- LocalDateTime:只包含⽇期,⽐如:2016-10-20 23 21
- Period:时间段
- ZoneOffset:时区偏移量,⽐如:+8:00
- ZonedDateTime:带时区的时间
- Clock:时钟,⽐如:获取⽬前美国纽约的时间
- LocalTime 和 LocalDate 的区别?
- LocalDate 表⽰⽇期,年⽉⽇
- LocalTime 表⽰时间,时分秒
- 获取当前时间
LocalDate today = LocalDate.now(); int year = today.getYear(); int month = today.getMonthValue(); int day = today.getDayOfMonth(); System.out.printf("Year : %d Month : %d day : %d t %n", year,month,day); - 创建指定日期的时间
LocalDate date = LocalDate.of(2018, 01, 01); - 检查闰年
LocalDate nowDate = LocalDate.now(); //判断闰年 boolean leapYear = nowDate.isLeapYear(); - 计算两个⽇期之间的天数和⽉数
Period period = Period.between(LocalDate.of(2018, 1, 5),LocalDate.of(2018,2, 5));
- 如何在东八区的计算机上获取美国时间
- Java8 中加入了对时区的支持,带时区的时间为分别为:ZonedDate、ZonedTime、ZonedDateTime
- 其中每个时区都对应着 ID,地区 ID 都为“{区域}/{城市}”的格式,如 Asia/Shanghai、America/Los_Angeles 等
- 在 Java8 中,直接使用以下代码即可输出美国洛杉矶的时间:
LocalDateTime now = LocalDateTime.now(ZoneId.of("America/Los_Angeles")); System.out.println(now);- 为什么以下代码无法获得美国时间呢?
System.out.println(Calendar.getInstance(TimeZone.getTimeZone("America/Los_Angeles")).getTime()); - 当我们使用 System.out.println 来输出一个时间的时候,他会调用 Date 类的 toString 方法,而该方法会读取操作系统的默认时区来进行时间的转换
public String toString() { // "EEE MMM dd HH:mm:ss zzz yyyy"; BaseCalendar.Date date = normalize(); ... } private final BaseCalendar.Date normalize() { ... TimeZone tz = TimeZone.getDefaultRef(); if (tz != cdate.getZone()) { cdate.setZone(tz); CalendarSystem cal = getCalendarSystem(cdate); cal.getCalendarDate(fastTime, cdate); } return cdate; } static TimeZone getDefaultRef() { TimeZone defaultZone = defaultTimeZone; if (defaultZone == null) { // Need to initialize the default time zone. defaultZone = setDefaultZone(); assert defaultZone != null; } // Don't clone here. return defaultZone; }
- 为什么以下代码无法获得美国时间呢?
- yyyy 和 YYYY 有什么区别?
- y 表示 Year ,而 Y 表示 Week Year
- 在 ISO 8601 中。对于一年的第一个日历星期有以下四种等效说法:
- 1,本年度第一个星期四所在的星期
- 2,1 月 4 日所在的星期
- 3,本年度第一个至少有 4 天在同一星期内的星期
- 4,星期一在去年 12 月 29 日至今年 1 月 4 日以内的星期
- 时区
-
编码方式
- 什么是 ASCII?
- ASCII(American Standard Code for InformationInterchange,美国信息交换标准代码)是基于拉丁字母的⼀套电脑编码系统,主要⽤于显⽰现代英语和其他西欧语⾔。它是现今最通⽤的单字节编码系统,并等同于国际标准 ISO/IEC646
- 标准 ASCII 码也叫基础 ASCII 码,使⽤ 7 位⼆进制数(剩下的 1 位⼆进制为 0)来表⽰所有的⼤写和⼩写字母,数字 0 到 9、标点符号,以及在美式英语中使⽤的特殊控制字符,其中:
- 0~31 及 127(共 33 个)是控制字符或通信专⽤字符(其余为可显⽰字符),如控制符:LF(换⾏)、CR(回车)、FF(换页)、DEL(删除)、BS(退格)、BEL(响铃)等;通信专⽤字符:SOH(⽂头)、EOT(⽂尾)、ACK(确认)等
- ASCII 值为 8、9、10 和 13 分别转换为退格、制表、换⾏和回车字符。它们并没有特定的图形显⽰,但会依不同的应⽤程序,⽽对⽂本显⽰有不同的影响: 32~126 (共 95 个)是字符( 32 是空格),其中 48~57 为 0 到 9⼗个阿拉伯数字。65~90 为 26 个⼤写英⽂字母,97~122 号为 26 个⼩写英⽂字母,其余为⼀些标点符号、运算符号等
- 什么是 Unicode?
- Unicode(中文:万国码、国际码、统一码、单一码)是计算机科学领域里的一项业界标准。它对世界上大部分的文字系统进行了整理、编码,使得计算机可以用更为简单的方式来呈现和处理文字
- 有了 Unicode 为啥还需要 UTF-8?
- 广义的 Unicode 是一个标准,定义了一个字符集以及一系列的编码规则,即 Unicode 字符集和 UTF-8、UTF-16、UTF-32 等等编码规则
- Unicode 是字符集。UTF-8 是编码规则
- unicode 虽然统一了全世界字符的二进制编码,但没有规定如何存储。如果 Unicode 统一规定,每个符号就要用三个或四个字节表示,因为字符太多,只能用这么多字节才能表示完全。一旦这么规定,那么每个英文字母前都必然有二到三个字节是 0,因为所有英文字母在 ASCII 中都有,都可以用一个字节表示,剩余字节位置就要补充 0。如果这样,文本文件的大小会因此大出二三倍,这对于存储来说是极大的浪费。这样导致一个后果:出现了 Unicode 的多种存储方式
- UTF-8 就是 Unicode 的一个使用方式,通过他的英文名 Unicode Tranformation Format 就可以知道。UTF-8 使用可变长度字节来储存 Unicode 字符,例如 ASCII 字母继续使用 1 字节储存,重音文字、希腊字母或西里尔字母等使用 2 字节来储存,而常用的汉字就要使用 3 字节。辅助平面字符则使用 4 字节。一般情况下,同一个地区只会出现一种文字类型,比如中文地区一般很少出现韩文,日文等。所以使用这种编码方式可以大大节省空间。比如纯英文网站就要比纯中文网站占用的存储小一些
- UTF8、UTF16、UTF32 的区别
- Unicode 是容纳世界所有文字符号的国际标准编码,使用四个字节为每个字符编码
- UTF 是英文 Unicode Transformation Format 的缩写,意为把 Unicode 字符转换为某种格式。UTF 系列编码方案(UTF-8、UTF-16、UTF-32)均是由 Unicode 编码方案衍变而来,以适应不同的数据存储或传递,它们都可以完全表示 Unicode 标准中的所有字符。目前,这些衍变方案中 UTF-8 被广泛使用,而 UTF-16 和 UTF-32 则很少被使用
- UTF-8 使用一至四个字节为每个字符编码,其中大部分汉字采用三个字节编码,少量不常用汉字采用四个字节编码。因为 UTF-8 是可变长度的编码方式,相对于 Unicode 编码可以减少存储占用的空间,所以被广泛使用
- UTF-16 使用二或四个字节为每个字符编码,其中大部分汉字采用两个字节编码,少量不常用汉字采用四个字节编码。UTF-16 编码有大尾序和小尾序之别,即 UTF-16BE 和 UTF-16LE,在编码前会放置一个 U+FEFF 或 U+FFFE(UTF-16BE 以 FEFF 代表,UTF-16LE 以 FFFE 代表),其中 U+FEFF 字符在 Unicode 中代表的意义是 ZERO WIDTH NO-BREAK SPACE,顾名思义,它是个没有宽度也没有断字的空白
- UTF-32 使用四个字节为每个字符编码,使得 UTF-32 占用空间通常会是其它编码的二到四倍。UTF-32 与 UTF-16 一样有大尾序和小尾序之别,编码前会放置 U+0000FEFF 或 U+0000FFFE 以区分
- 有了 UTF8 为什么还需要 GBK?
- 其实 UTF8 确实已经是国际通用的字符编码了,但是这种字符标准毕竟是外国定的,而国内也有类似的标准指定组织,也需要制定一套国内通用的标准,于是 GBK 就诞生了
- GBK、GB2312、GB18030 之间的区别
- 三者都是支持中文字符的编码方式,最常用的是 GBK
- GB2312(1980 年):16 位字符集,收录有 6763 个简体汉字,682 个符号,共 7445 个字符
- 优点:适用于简体中文环境,属于中国国家标准,通行于大陆,新加坡等地也使用此编码
- 缺点:不兼容繁体中文,其汉字集合过少
- GBK(1995 年):16 位字符集,收录有 21003 个汉字,883 个符号,共 21886 个字符
- 优点:适用于简繁中文共存的环境,为简体 Windows 所使用(代码页 cp936),向下完全兼容 gb2312,向上支持 ISO-10646 国际标准 ;所有字符都可以一对一映射到 unicode2.0 上
- 缺点:不属于官方标准,和 big5 之间需要转换;很多搜索引擎都不能很好地支持 GBK 汉字
- GB18030(2000 年):32 位字符集;收录了 27484 个汉字,同时收录了藏文、蒙文、维吾尔文等主要的少数民族文字
- 优点:可以收录所有你能想到的文字和符号,属于中国最新的国家标准
- 缺点:目前支持它的软件较少
- URL 编解码
- 网络标准 RFC 1738 做了硬性规定 :只有字母和数字[0-9a-zA-Z]、一些特殊符号“$-_.+!*’(),”[不包括双引号]、以及某些保留字,才可以不经过编码直接用于 URL;除此以外的字符是无法在 URL 中展示的,所以,遇到这种字符,如中文,就需要进行编码。所以,把带有特殊字符的 URL 转成可以显示的 URL 过程,称之为 URL 编码。反之,就是解码
- URL编码可以使用不同的方式,如escape,URLEncode,encodeURIComponent
- Big Endian 和 Little Endian
- 字节序,也就是字节的顺序,指的是多字节的数据在内存中的存放顺序。在几乎所有的机器上,多字节对象都被存储为连续的字节序列。例如:如果 C/C++中的一个 int 型变量 a 的起始地址是&a = 0x100,那么 a 的四个字节将被存储在存储器的0x100, 0x101, 0x102, 0x103 位置。根据整数 a 在连续的 4 byte 内存中的存储顺序,字节序被分为大端序(Big Endian) 与 小端序(Little Endian)两类
- Big Endian 是指低地址端存放高位字节
- Little Endian 是指低地址端存放低位字节
- 比如数字 0x12345678 在两种不同字节序 CPU 中的存储顺序:Big Endian:12345678 Little Endian : 78563412
- Java 采用 Big Endian 来存储数据、C\C++采用 Little Endian。在网络传输一般采用的网络字节序是 BIG-ENDIAN。和 Java 是一致的。所以在用 C/C++写通信程序时,在发送数据前务必把整型和短整型的数据进行从主机字节序到网络字节序的转换,而接收数据后对于整型和短整型数据则必须实现从网络字节序到主机字节序的转换。如果通信的一方是 JAVA 程序、一方是 C/C++程序时,则需要在C/C++一侧使用以上几个方法进行字节序的转换,而 JAVA 一侧,则不需要做任何处理,因为 JAVA 字节序与网络字节序都是 BIG-ENDIAN,只要 C/C++一侧能正确进行转换即可(发送前从主机序到网络序,接收时反变换)。如果通信的双方都是 JAVA,则根本不用考虑字节序的问题了
- 字节序,也就是字节的顺序,指的是多字节的数据在内存中的存放顺序。在几乎所有的机器上,多字节对象都被存储为连续的字节序列。例如:如果 C/C++中的一个 int 型变量 a 的起始地址是&a = 0x100,那么 a 的四个字节将被存储在存储器的0x100, 0x101, 0x102, 0x103 位置。根据整数 a 在连续的 4 byte 内存中的存储顺序,字节序被分为大端序(Big Endian) 与 小端序(Little Endian)两类
- 什么是 ASCII?
-
语法糖
- Java 中语法糖原理、解语法糖
- 语法糖
- 语法糖(Syntactic Sugar),也称糖衣语法,是由英国计算机学家 Peter.J.Landin 发明的一个术语,指在计算机语言中添加的某种语法,这种语法对语言的功能并没有影响,但是更方便程序员使用,有意思的是,在编程领域,除了语法糖,还有语法盐和语法糖精的说法
- 解语法糖
- 语法糖的存在主要是方便开发人员使用。但其实,Java 虚拟机并不支持这些语法糖。这些语法糖在编译阶段就会被还原成简单的基础语法结构,这过程就是解语法糖。
- 说到编译,大家肯定都知道,Java 语言中,javac 命令可以将后缀名为 .java 的源文件编译为后缀名为 .class 的可以运行于 Java 虚拟机的字节码。如果你去看 com.sun.tools.javac.main.JavaCompiler 的源码,你会发现在 compile() 中有一个步骤就是调用 desugar(),这个方法就是负责解语法糖的实现的。Java 中最常用的语法糖主要有泛型、变长参数、条件编译、自动拆装箱、内部类等
- 糖块一、switch 支持 String 与枚举
- Java 7 中 switch 开始支持 String。在开始 coding 之前先科普下,Java 中的 switch 自身原本就支持基本类型。比如 int、char 等。对于 int 类型,直接进行数值的比较。对于 char 类型则是比较其 ascii 码。所以,对于编译器来说,switch 中其实只能使用整型,任何类型的比较都要转换成整型。比如 byte,short,char(ackii 码是整型)以及 int。那么接下来看下 switch 对 String 得支持,有以下代码:
public class switchDemoString { public static void main(String[] args) { String str = "world"; switch (str) { case "hello": System.out.println("hello"); break; case "world": System.out.println("world"); break; default: break; } } }- 反编译后内容如下:
public class switchDemoString{ public switchDemoString(){ } public static void main(String args[]){ String str = "world"; String s; switch((s = str).hashCode()){ default: break; case 99162322: if(s.equals("hello")) System.out.println("hello"); break; case 113318802: if(s.equals("world")) System.out.println("world"); break; } } }- 看到这个代码,你知道原来字符串的 switch 是通过 equals()和 hashCode() 方法来实现的。还好 hashCode() 方法返回的是 int,而不是 long。仔细看下可以发现,进行 switch 的实际是哈希值,然后通过使用 equals 方法比较进行安全检查,这个检查是必要的,因为哈希可能会发生碰撞。因此它的性能是不如使用枚举进行 switch 或者使用纯整数常量,但这也不是很差
- Java 7 中 switch 开始支持 String。在开始 coding 之前先科普下,Java 中的 switch 自身原本就支持基本类型。比如 int、char 等。对于 int 类型,直接进行数值的比较。对于 char 类型则是比较其 ascii 码。所以,对于编译器来说,switch 中其实只能使用整型,任何类型的比较都要转换成整型。比如 byte,short,char(ackii 码是整型)以及 int。那么接下来看下 switch 对 String 得支持,有以下代码:
- 糖块二、泛型
- 一个编译器处理泛型有两种方式:Code specialization 和 Code sharing。C++ 和 C# 是使用 Code specialization 的处理机制,而 Java 使用的是 Code sharing 的机制
- Code sharing 方式为每个泛型类型创建唯一的字节码表示,并且将该泛型类型的实例都映射到这个唯一的字节码表示上。将多种泛型类形实例映射到唯一的字节码表示是通过类型擦除(type erasue)实现的。也就是说,对于 Java 虚拟机来说,他根本不认识 Map<String, String> map 这样的语法。需要在编译阶段通过类型擦除的方式进行解语法糖
- 类型擦除的主要过程如下: 1.将所有的泛型参数用其最左边界(最顶级的父类型)类型替换。 2.移除所有的类型参数
// 示例 Map<String, String> map = new HashMap<String, String>(); map.put("name", "hollis"); map.put("wechat", "Hollis"); map.put("blog", "www.hollischuang.com"); // 解语法糖 Map map = new HashMap(); map.put("name", "hollis"); map.put("wechat", "Hollis"); map.put("blog", "www.hollischuang.com") // 示例 public static <A extends Comparable<A>> A max(Collection<A> xs) { Iterator<A> xi = xs.iterator(); A w = xi.next(); while (xi.hasNext()) { A x = xi.next(); if (w.compareTo(x) < 0) w = x; } return w; } // 解语法糖 public static Comparable max(Collection xs) { Iterator xi = xs.iterator(); Comparable w = (Comparable)xi.next(); while(xi.hasNext()){ Comparable x = (Comparable)xi.next(); if(w.compareTo(x) < 0) w = x; } return w; } - 虚拟机中没有泛型,只有普通类和普通方法,所有泛型类的类型参数在编译时都会被擦除,泛型类并没有自己独有的 Class 类对象。比如并不存在 List.class 或是List.class,而只有 List.class
- 糖块三、自动装箱与拆箱
- 自动装箱就是 Java 自动将原始类型值转换成对应的对象,比如将 int 的变量转换成 Integer 对象,这个过程叫做装箱,反之将 Integer 对象转换成 int 类型值,这个过程叫做拆箱。因为这里的装箱和拆箱是自动进行的非人为转换,所以就称作为自动装箱和拆箱。原始类型 byte, short, char, int, long, float, double 和 boolean 对应的封装类为 Byte, Short, Character, Integer, Long, Float, Double, Boolean
// 示例 public static void main(String[] args) { int i = 10; Integer n = i; } // 解语法糖 public static void main(String args[]){ int i = 10; Integer n = Integer.valueOf(i); } // 示例 public static void main(String[] args) { Integer i = 10; int n = i; } // 解语法糖 public static void main(String args[]){ Integer i = Integer.valueOf(10); int n = i.intValue(); } - 从反编译得到内容可以看出,在装箱的时候自动调用的是 Integer 的 valueOf(int) 方法。而在拆箱的时候自动调用的是 Integer 的 intValue 方法。所以,装箱过程是通过调用包装器的 valueOf 方法实现的,而拆箱过程是通过调用包装器的 xxxValue 方法实现的
- 自动装箱就是 Java 自动将原始类型值转换成对应的对象,比如将 int 的变量转换成 Integer 对象,这个过程叫做装箱,反之将 Integer 对象转换成 int 类型值,这个过程叫做拆箱。因为这里的装箱和拆箱是自动进行的非人为转换,所以就称作为自动装箱和拆箱。原始类型 byte, short, char, int, long, float, double 和 boolean 对应的封装类为 Byte, Short, Character, Integer, Long, Float, Double, Boolean
- 糖块四、方法变长参数
- 可变参数(variable arguments)是在 Java 1.5 中引入的一个特性。它允许一个方法把任意数量的值作为参数
// 示例 public static void main(String[] args){ print("Holis", "公众号:Hollis", "博客:www.hollischuang.com", "QQ:907607222"); } public static void print(String... strs){ for (int i = 0; i < strs.length; i++){ System.out.println(strs[i]); } } // 解语法糖 public static void main(String args[]){ print(new String[] {"Holis", "\u516C\u4F17\u53F7:Hollis", "\u535A\u5BA2\uFF1Awww.hollischuang.com", "QQ\uFF1A907607222"}); } public static transient void print(String strs[]){ for(int i = 0; i < strs.length; i++) System.out.println(strs[i]); } - 从反编译后代码可以看出,可变参数在被使用的时候,他首先会创建一个数组,数组的长度就是调用该方法是传递的实参的个数,然后再把参数值全部放到这个数组当中,然后再把这个数组作为参数传递到被调用的方法中
- 可变参数(variable arguments)是在 Java 1.5 中引入的一个特性。它允许一个方法把任意数量的值作为参数
- 糖块五、枚举
- 糖块六、内部类
- 内部类又称为嵌套类,可以把内部类理解为外部类的一个普通成员。内部类之所以也是语法糖,是因为它仅仅是一个编译时的概念,outer.java 里面定义了一个内部类 inner,一旦编译成功,就会生成两个完全不同的.class 文件了,分别是outer.class 和 outer$inner.class。所以内部类的名字完全可以和它的外部类名字相同
// 示例 public class OutterClass { private String userName; public String getUserName() { return userName; } public void setUserName(String userName) { this.userName = userName; } public static void main(String[] args) { } class InnerClass{ private String name; public String getName() { return name; } public void setName(String name) { this.name = name; } } } // 解语法糖 // 以上代码编译后会生成两个 class 文件:OutterClass$InnerClass.class 、OutterClass.class 。当我们尝试对 OutterClass.class 文件进行反编译的时候,命令行会打印以下内容:Parsing OutterClass.class...Parsing inner class OutterClass$InnerClass.class... Generating OutterClass.jad 。他会把两个文件全部进行反编译,然后一起生成一个 OutterClass.jad 文件。文件内容如下 public class OutterClass{ class InnerClass{ public String getName(){ return name; } public void setName(String name){ this.name = name; } private String name; final OutterClass this$0; InnerClass(){ this.this$0 = OutterClass.this; super(); } } public OutterClass(){ } public String getUserName(){ return userName; } public void setUserName(String userName){ this.userName = userName; } public static void main(String args1[]){ } private String userName; }
- 内部类又称为嵌套类,可以把内部类理解为外部类的一个普通成员。内部类之所以也是语法糖,是因为它仅仅是一个编译时的概念,outer.java 里面定义了一个内部类 inner,一旦编译成功,就会生成两个完全不同的.class 文件了,分别是outer.class 和 outer$inner.class。所以内部类的名字完全可以和它的外部类名字相同
- 糖块七、条件编译
- —般情况下,程序中的每一行代码都要参加编译。但有时候出于对程序代码优化的考虑,希望只对其中一部分内容进行编译,此时就需要在程序中加上条件,让编译器只对满足条件的代码进行编译,将不满足条件的代码舍弃,这就是条件编译。如在 C 或 CPP 中,可以通过预处理语句来实现条件编译。其实在 Java 中也可实现条件编译
// 示例 public class ConditionalCompilation { public static void main(String[] args) { final boolean DEBUG = true; if(DEBUG) { System.out.println("Hello, DEBUG!"); } final boolean ONLINE = false; if(ONLINE){ System.out.println("Hello, ONLINE!"); } } } // 解语法糖 public class ConditionalCompilation{ public ConditionalCompilation(){ } public static void main(String args[]){ boolean DEBUG = true; System.out.println("Hello, DEBUG!"); boolean ONLINE = false; } } - 首先,我们发现,在反编译后的代码中没有 System.out.println(“Hello, ONLINE!”);,这其实就是条件编译。当 if(ONLINE)为 false 的时候,编译器就没有对其内的代码进行编译。所以,Java 语法的条件编译,是通过判断条件为常量的 if 语句实现的。其原理也是 Java 语言的语法糖。根据 if 判断条件的真假,编译器直接把分支为 false 的代码块消除。通过该方式实现的条件编译,必须在方法体内实现,而无法在正整个 Java 类的结构或者类的属性上进行条件编译,这与 C/C++的条件编译相比,确实更有局限性。在 Java 语言设计之初并没有引入条件编译的功能,虽有局限,但是总比没有更强
- —般情况下,程序中的每一行代码都要参加编译。但有时候出于对程序代码优化的考虑,希望只对其中一部分内容进行编译,此时就需要在程序中加上条件,让编译器只对满足条件的代码进行编译,将不满足条件的代码舍弃,这就是条件编译。如在 C 或 CPP 中,可以通过预处理语句来实现条件编译。其实在 Java 中也可实现条件编译
- 糖块八、断言
- 在 Java 中,assert 关键字是从 JAVA SE 1.4 引入的,为了避免和老版本的 Java 代码中使用了 assert 关键字导致错误,Java 在执行的时候默认是不启动断言检查的(这个时候,所有的断言语句都忽略!),如果要开启断言检查,则需要用开关 -enableassertions 或 -ea 来开启
// 示例 public class AssertTest { public static void main(String args[]) { int a = 1; int b = 1; assert a == b; System.out.println("公众号:Hollis"); assert a != b : "Hollis"; System.out.println("博客:www.hollischuang.com"); } } // 解语法糖 public class AssertTest { public AssertTest(){ } public static void main(String args[]){ int a = 1; int b = 1; if(!$assertionsDisabled && a != b) throw new AssertionError(); System.out.println("\u516C\u4F17\u53F7\uFF1AHollis"); if(!$assertionsDisabled && a == b){ throw new AssertionError("Hollis"); } else{ System.out.println("\u535A\u5BA2\uFF1Awww.hollischuang.com"); return; } } static final boolean $assertionsDisabled = !com/hollis/suguar/AssertTest.desi redAssertionStatus(); } - 很明显,反编译之后的代码要比我们自己的代码复杂的多。所以,使用了 assert 这个语法糖我们节省了很多代码。其实断言的底层实现就是 if 语言,如果断言结果为 true,则什么都不做,程序继续执行,如果断言结果为 false,则程序抛出 AssertError 来打断程序的执行。-enableassertions 会设置 $assertionsDisabled 字段的值
- 在 Java 中,assert 关键字是从 JAVA SE 1.4 引入的,为了避免和老版本的 Java 代码中使用了 assert 关键字导致错误,Java 在执行的时候默认是不启动断言检查的(这个时候,所有的断言语句都忽略!),如果要开启断言检查,则需要用开关 -enableassertions 或 -ea 来开启
- 糖块九、数值字面量
- 在 java 7 中,数值字面量,不管是整数还是浮点数,都允许在数字之间插入任意多个下划线。这些下划线不会对字面量的数值产生影响,目的就是方便阅读
// 示例 public class Test { public static void main(String... args) { int i = 10_000; System.out.println(i); } } // 解语法糖 public class Test{ public static void main(String[] args){ int i = 10000; System.out.println(i); } } - 反编译后就是把_删除了。也就是说 编译器并不认识在数字字面量中的_,需要在编译阶段把他去掉
- 在 java 7 中,数值字面量,不管是整数还是浮点数,都允许在数字之间插入任意多个下划线。这些下划线不会对字面量的数值产生影响,目的就是方便阅读
- 糖块十、for-each
- 增强 for 循环(for-each)相信大家都不陌生,日常开发经常会用到的,他会比 for 循环要少写很多代码,那么这个语法糖背后是如何实现的呢
public static void main(String... args) { String[] strs = {"Hollis", "公众号:Hollis", "博客:www.hollischuang.com"}; for (String s : strs) { System.out.println(s); } List<String> strList = ImmutableList.of("Hollis", "公众号:Hollis", "博客:www.hollischuang.com"); for (String s : strList) { System.out.println(s); } } // 解语法糖 public static transient void main(String args[]){ String strs[] = {"Hollis", "\u516C\u4F17\u53F7\uFF1AHollis", "\u535A\u5BA2\uFF1Awww.hollischuang.com"}; String args1[] = strs; int i = args1.length; for(int j = 0; j < i; j++){ String s = args1[j]; System.out.println(s); } List strList = ImmutableList.of("Hollis", "\u516C\u4F17\u53F7\uFF1AHollis", "\u535A\u5BA2\uFF1Awww.hollischuang.com"); String s; for(Iterator iterator = strList.iterator(); iterator.hasNext(); System.out.println(s)) s = (String)iterator.next(); } - 代码很简单,for-each 的实现原理其实就是使用了普通的 for 循环和迭代器
- 增强 for 循环(for-each)相信大家都不陌生,日常开发经常会用到的,他会比 for 循环要少写很多代码,那么这个语法糖背后是如何实现的呢
- 糖块十一、try-with-resource
- Java 里,对于文件操作 IO 流、数据库连接等开销非常昂贵的资源,用完之后必须及时通过 close 方法将其关闭,否则资源会一直处于打开状态,可能会导致内存泄露等问题。关闭资源的常用方式就是在 finally 块里是释放,即调用 close 方法
// 示例 public static void main(String[] args) { BufferedReader br = null; try { String line; br = new BufferedReader(new FileReader("d:\\hollischuang.xml")); while ((line = br.readLine()) != null) { System.out.println(line); } } catch (IOException e) { // handle exception } finally { try { if (br != null) { br.close(); } } catch (IOException ex) { // handle exception } } } // 从 Java 7 开始,jdk 提供了一种更好的方式关闭资源,使用 try-with-resources 语句,改写一下上面的代码 public static void main(String... args) { try (BufferedReader br = new BufferedReader(new FileReader("d:\\ hollischuang.xml"))) { String line; while ((line = br.readLine()) != null) { System.out.println(line); } } catch (IOException e) { // handle exception } } // 解语法糖 public static transient void main(String args[]){ BufferedReader br; Throwable throwable; br = new BufferedReader(new FileReader("d:\\ hollischuang.xml")); throwable = null; String line; try{ while((line = br.readLine()) != null) System.out.println(line); }catch(Throwable throwable2){ throwable = throwable2; throw throwable2; } if(br != null) if(throwable != null) try{ br.close(); }catch(Throwable throwable1){ throwable.addSuppressed(throwable1); } else br.close(); break MISSING_BLOCK_LABEL_113; Exception exception; exception; if(br != null) if(throwable != null) try{ br.close(); }catch(Throwable throwable3){ throwable.addSuppressed(throwable3); } else br.close(); throw exception; IOException ioexception; ioexception; }
- Java 里,对于文件操作 IO 流、数据库连接等开销非常昂贵的资源,用完之后必须及时通过 close 方法将其关闭,否则资源会一直处于打开状态,可能会导致内存泄露等问题。关闭资源的常用方式就是在 finally 块里是释放,即调用 close 方法
- 糖块十二、Lambda 表达式
- Labmda 表达式不是匿名内部类的语法糖,但是他也是一个语法糖。实现方式其实是依赖了几个 JVM 底层提供的 lambda 相关 api。
// 示例 public static void main(String... args) { List<String> strList = ImmutableList.of("Hollis", "公众号:Hollis", "博客:www.hollischuang.com"); strList.forEach( s -> { System.out.println(s); } ); } // 解语法糖 public static /* varargs */ void main(String ... args) { ImmutableList strList = ImmutableList.of((Object)"Hollis", (Object)"\u516c\u4f17\u53f7\uff1aHollis", (Object)"\u535a\u5ba2\uff1awww.hollischuang.com"); strList.forEach((Consumer<String>)LambdaMetafactory.metafactory(null, null, null, (Ljava/lang/Object;)V, lambda$main$0(java.lang.String ), (Ljava/lang/String;)V)()); } private static /* synthetic */ void lambda$main$0(String s) { System.out.println(s); } // 示例 public static void main(String... args) { List<String> strList = ImmutableList.of("Hollis", "公众号:Hollis", "博客:www.hollischuang.com"); List HollisList = strList.stream().filter(string -> string.contains("Hollis")).collect(Collectors.toList()); HollisList.forEach( s -> { System.out.println(s); } ); } // 解语法糖 public static /* varargs */ void main(String ... args) { ImmutableList strList = ImmutableList.of((Object)"Hollis", (Object)"\u516c\u4f17\u53f7\uff1aHollis", (Object)"\u535a\u5ba2\uff1awww.hollischuang.com"); List<Object> HollisList = strList.stream().filter((Predicate<String>)LambdaMetafactory.metafactory(null, null, null, (Ljava/lang/Object;)Z, lambda$main$0(java.lang.String ), (Ljava/lang/String;)Z)()).collect(Collectors.toList()); HollisList.forEach((Consumer<Object>)LambdaMetafactory.metafactory(null,null, null, (Ljava/lang/Object;)V, lambda$main$1(java.lang.Object ), (Ljava/lang/Object;)V)()); } private static /* synthetic */ void lambda$main$1(Object s) { System.out.println(s); } private static /* synthetic */ boolean lambda$main$0(String string) { return string.contains("Hollis"); } - 两个 lambda 表达式分别调用了 lambda$main 1 和 l a m b d a 1 和 lambda 1和lambdamain$0 两个方法。所以,lambda 表达式的实现其实是依赖了一些底层的 api,在编译阶段,编译器会把 lambda 表达式进行解糖,转换成调用内部 api 的方式
- Labmda 表达式不是匿名内部类的语法糖,但是他也是一个语法糖。实现方式其实是依赖了几个 JVM 底层提供的 lambda 相关 api。
- 可能遇到的坑
- 泛型
- 当泛型遇到重载
public class GenericTypes{ public static void method(List<String> list) { System.out.println("invoke method(List<String> list)"); } public static void method(List<Integer> list) { System.out.println("invoke method(List<Integer> list)"); } }- 上面这段代码,有两个重载的函数,因为他们的参数类型不同,一个是 List 另一个是 List ,但是,这段代码是编译通不过的。因为我们前面讲过,参数 List 和 List 编译之后都被擦除了,变成了一样的原生类型 List,擦除动作导致这两个方法的特征签名变得一模一样
- 当泛型遇到 catch 泛型的类型参数不能用在 Java 异常处理的 catch 语句中。因为异常处理是由 JVM 在运行时刻来进行的。由于类型信息被擦除,JVM 是无法区分两个异常类型 MyException和 MyException 的
- 当泛型内包含静态变量
public class StaticTest{ public static void main(String[] args){ GT<Integer> gti = new GT<Integer>(); gti.var=1; GT<String> gts = new GT<String>(); gts.var=2; System.out.println(gti.var); } } class GT<T>{ public static int var=0; public void nothing(T x){} }- 以上代码输出结果为:2!由于经过类型擦除,所有的泛型类实例都关联到同一份字节码上,泛型类的所有静态变量是共享的
- 当泛型遇到重载
- 自动装箱与拆箱
- 整型对象通过使用相同的对象引用实现了缓存和重用。适用于整数值区间 -128 至 +127
- 只适用于自动装箱。使用构造函数创建对象不适用
- 增强 for 循环
- 示例
for (Student stu : students) { if (stu.getId() == 2) students.remove(stu); } // 抛出 ConcurrentModificationException 异常 - Iterator 是工作在一个独立的线程中,并且拥有一个 mutex 锁。 Iterator 被创建之后会建立一个指向原来对象的单链索引表,当原来的对象数量发生变化时,这个索引表的内容不会同步改变,所以当索引指针往后移动的时候就找不到要迭代的对象,所以按照 fail-fast 原则 Iterator 会马上抛出 java.util.ConcurrentModificationException 异常。所以 Iterator 在工作的时候是不允许被迭代的对象被改变的。但你可以使用 Iterator 本身的方法 remove() 来删除对象,Iterator.remove() 方法会在删除当前迭代对象的同时维护索引的一致性
- 示例
- 泛型
- 语法糖
- Java 中语法糖原理、解语法糖
-
Lambda表达式

















 2747
2747

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









