







一、基础知识
模态
模态是指一些表达或感知事物的方式,每一种信息的来源或者形
式,都可以称为一种模态。例如,人有触觉,听觉,视觉,嗅觉;
信息的媒介,有语音、视频、文字等;多种多样的传感器,如雷
达、红外、加速度计等。以上的每一种都可以称为一种模态。
相较于图像、语音、文本等多媒体(Multi-media)数据划分形式,
“模态”是一个更为细粒度的概念,同一媒介下可存在不同的模态。
比如我们可以把两种不同的语言当做是两种模态,甚至在两种不
同情况下采集到的数据集,亦可认为是两种模态。
多模态
多模态即是从多个模态表达或感知事物。 多模态可归类为同质性
的模态,例如从两台相机中分别拍摄的图片,异质性的模态,例
如图片与文本语言的关系。
多模态可能有以下三种形式:
- 描述同一对象的多媒体数据。如互联网环境下描述某一特定对
象的视频、图片、语音、文本等信息。 - 来自不同传感器的同一类媒体数据。如医学影像学中不同的检查设备所产生的图像数据, 包括B超(B- Scan ultrasonography)、计算机断层扫描(CT)、核磁共振等;物联网背景下不同传感器所检测到的同一
对象数据等。 - 具有不同的数据结构特点、表示形式的表意符号与信息。如描述同一对象的结构化、非结构化的数据
单元;描述同一数学概念的公式、逻辑 符号、函数图及解释性文本;描述同一语义的词向量、词袋、
知识图谱以及其它语义符号单元等。
通常主要研究模态包括"3V":即Verbal(文本)、Vocal(语音)、Visual(视觉)。
多模态学习
多模态机器学习是从多种模态的数据中学习并且提升自身的算法,它不是某一个具体的算法,它是一类
算法的总称。
从语义感知的角度切入,多模态数据涉及不同的感知通道如视觉、听觉、触觉、嗅觉所接收到的信息;
在数据层面理解,多模态数据则可被看作多种数据类型的组合,如图片、数值、文本、符号、音频、时
间序列,或者集合、树、图等不同数据结构所组成的复合数据形式,乃至来自不同数据库、不同知识库
的各种信息资源的组合。对多源异构数据的挖掘分析可被理解为多模态学习。
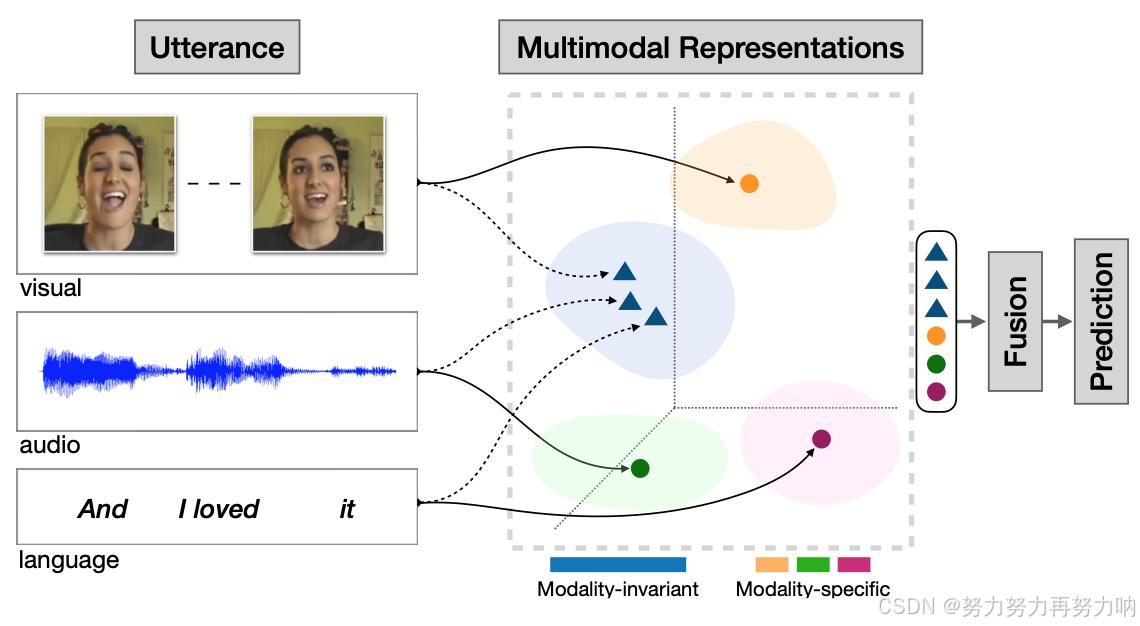
多模态典型任务
1、跨模态预训练
图像/视频与语言预训练。跨任务预训练
2、 Language-Audio
Text-to-Speech Synthesis: 给定文本,生成一段对应的声音。
Audio Captioning:给定一段语音,生成一句话总结并描述主要内容。(不是语音识别)
3、 Vision-Audio
Audio-Visual Speech Recognition(视听语音识别):给定某人的视频及语音进行语音识别。
Video Sound Separation(视频声源分离):给定视频和声音信号(包含多个声源),进行声源定位与分离。
Image Generation from Audio: 给定声音,生成与其相关的图像。
Speech-conditioned Face generation:给定一段话,生成说话人的视频。
Audio-Driven 3D Facial Animation:给定一段话与3D人脸模版,生成说话的人脸3D动画。
4 、Vision-Language
Image/Video-Text Retrieval (图(视频)文检索): 图像/视频<–>文本的相互检索。
Image/Video Captioning(图像/视频描述):给定一个图像/视频,生成文本描述其主要内容。
Visual Question Answering(视觉问答):给定一个图像/视频与一个问题,预测答案。
Image/Video Generation from Text:给定文本,生成相应的图像或视频。
Multimodal Machine Translation:给定一种语言的文本与该文本对应的图像,翻译为另外一种语言。
Vision-and-Language Navigation(视觉-语言导航): 给定自然语言进行指导,使得智能体根据视觉传感
器导航到特定的目标。
Multimodal Dialog(多模态对话): 给定图像,历史对话,以及与图像相关的问题,预测该问题的回答。
5、 定位相关的任务
Visual Grounding:给定一个图像与一段文本,定位到文本所描述的物体。
Temporal Language Localization: 给定一个视频即一段文本,定位到文本所描述的动作(预测起止时间)。
Video Summarization from text query:给定一段话(query)与一个视频,根据这段话的内容进行视频摘要,
预测视频关键帧(或关键片段)组合为一个短的摘要视频。
Video Segmentation from Natural Language Query: 给定一段话(query)与一个视频,分割得到query所指
示的物体。
Video-Language Inference: 给定视频(包括视频的一些字幕信息),还有一段文本假设(hypothesis),判断
二者是否存在语义蕴含(二分类),即判断视频内容是否包含这段文本的语义。
Object Tracking from Natural Language Query: 给定一段视频和一些文本,追踪视频中文本所描述的对
象。
Language-guided Image/Video Editing: 一句话自动修图。给定一段指令(文本),自动进行图像/视频的
编辑。
6、 更多模态
Affect Computing (情感计算):使用语音、视觉(人脸表情)、文本信息、心电、脑电等模态进行情感识别。
Medical Image:不同医疗图像模态如CT、MRI、PETRGB-D模态:RGB图与深度图
二、 本地部署CogVideoX-5B文生视频模型
1.1 模型介绍
CogVideoX是清影同源的开源版本视频生成模型。下表展示我们在本代提供的视频生成模型列表相关信息。[1]
| 模型名 | 模型介绍 | 推理精度 | 单GPU显存消耗(SAT/diffusers) | 多GPU推理显存消耗(diffusers) | 推理速度(Step=50, FP/BF16, 单卡) | 微调精度 | 微调显存消耗(示例) | 提示词语言 | 提示词长度上限 | 视频参数 |
|---|---|---|---|---|---|---|---|---|---|---|
| CogVideoX-2B | 入门级模型,兼顾兼容性。运行,二次开发成本低。 | FP16*, BF16, FP32, FP8*, INT8 | SAT FP16: 18GB diffusers FP16: 4GB起* | FP16: 10GB* | 单卡A100: ~90秒 单卡H100: ~45秒 | FP16 | 47 GB (bs=1, LORA) | English* | 226 Tokens | 视频长度 6 秒 帧率 8 帧/秒 分辨率720*480 |
| CogVideoX-5B | 视频生成质量更高,视觉效果更好的更大尺寸模型。(教程模型) | BF16*(推荐), FP16, FP32, FP8*, INT8 | SAT BF16: 26GB diffusers BF16: 5GB起* | BF16: 15GB* | 单卡A100: ~180秒 单卡H100: ~90秒 | BF16 | 61 GB (bs=2, LORA) 62GB (bs=1, SFT) | English* | 226 Tokens | 视频长度 6 秒 帧率 8 帧/秒 分辨率720*480 |
| CogVideoX-5B-I2V | CogVideoX-5B 图生视频版本。 | BF16(推荐), FP16, FP32, FP8*, INT8 | diffusers INT8(torchao): 3.6G起* diffusers BF16 : 5GB起* | 未提供 | 未提供 | BF16 | 63 GB (bs=1, LORA) 75GB (bs=1, SFT) 78 GB (bs=1, LORA) 75GB (bs=1, SFT, 16GPU) | English* | 226 Tokens | 视频长度 6 秒 帧率 8 帧/秒 分辨率720*480 |
备注:不支持INT4;视频分辨率不支持其他分辨率(含微调)。
1.2 环境安装
# diffusers>=0.30.3
# transformers>=0.44.2
# accelerate>=0.34.0
# imageio-ffmpeg>=0.5.1
pip install --upgrade transformers accelerate diffusers imageio-ffmpeg
1.3 模型下载
git clone https://www.modelscope.cn/ZhipuAI/CogVideoX-5b.git
或者
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('ZhipuAI/CogVideoX-5b',cache_dir="")
1.4 运行代码
import torch
from diffusers import CogVideoXPipeline
from diffusers.utils import export_to_video
prompt = "A panda, dressed in a small, red jacket and a tiny hat, sits on a wooden stool in a serene bamboo forest. The panda's fluffy paws strum a miniature acoustic guitar, producing soft, melodic tunes. Nearby, a few other pandas gather, watching curiously and some clapping in rhythm. Sunlight filters through the tall bamboo, casting a gentle glow on the scene. The panda's face is expressive, showing concentration and joy as it plays. The background includes a small, flowing stream and vibrant green foliage, enhancing the peaceful and magical atmosphere of this unique musical performance."
pipe = CogVideoXPipeline.from_pretrained(
"THUDM/CogVideoX-5b",
torch_dtype=torch.bfloat16
)
pipe.enable_sequential_cpu_offload()
pipe.vae.enable_tiling()
pipe.vae.enable_slicing()
video = pipe(
prompt=prompt,
num_videos_per_prompt=1,
num_inference_steps=50,
num_frames=49,
guidance_scale=6,
generator=torch.Generator(device="cuda").manual_seed(42),
).frames[0]
export_to_video(video, "output.mp4", fps=8)
1.5 生成效果

三、使用ollama部署Llama-3.2-11B-Vision-Instruct-GGUF实现视觉问答
2.1 模型介绍
Llama 3.2-Vision 是一系列多模态大语言模型(LLM),包括预训练和指令调优的图像推理生成模型,大小分别为11B和90B(输入为文本+图像/输出为文本)。Llama 3.2-Vision 指令调优模型针对视觉识别、图像推理、字幕生成以及回答关于图像的一般问题进行了优化。这些模型在常见的行业基准测试中表现优于许多可用的开源和闭源多模态模型。[2][3]
- 模型开发者: Meta
- 模型架构: Llama 3.2-Vision 基于 Llama 3.1 文本模型构建,后者是一个使用优化的Transformer架构的自回归语言模型。调优版本使用有监督的微调(SFT)和基于人类反馈的强化学习(RLHF)来与人类对有用性和安全性的偏好保持一致。为了支持图像识别任务,Llama 3.2-Vision 模型使用了单独训练的视觉适配器,该适配器与预训练的 Llama 3.1 语言模型集成。适配器由一系列交叉注意力层组成,将图像编码器表示传递给核心LLM。
- 支持的语言: 对于纯文本任务,官方支持英语、德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语。Llama 3.2 的训练数据集包含了比这八种语言更广泛的语言。注意,对于图像+文本应用,仅支持英语。
- 模型发布日期: 2024年9月25日
2.2 预期用途
Llama 3.2-Vision旨在用于商业和研究用途。经过指令调优的模型适用于视觉识别、图像推理、字幕添加以及带有图像的助手式聊天,而预训练模型可以适应多种图像推理任务。此外,由于Llama 3.2-Vision能够接受图像和文本作为输入,因此还可能包括以下用途:
- 视觉问答(VQA)与视觉推理。
- 文档视觉问答(DocVQA)。
- 图像字幕。
- 图像-文本检索。
- 视觉接地。[4]
2.3 安装ollama
curl -fsSL https://ollama.com/install.sh | sh
# 查看ollama版本
ollama --version
2.4 安装 Llama 3.2 Vision 模型
ollama run llama3.2-vision:11b
2.5 运行 Llama 3.2-Vision
# 将 images.png 替换为你选择的图像路径。模型将分析图像并根据其理解提供响应。
ollama run x/llama3.2-vision:latest "Which era does this piece belong to? Give details about the era: images.png"
输出示例:
The piece is a painting of a woman in a red dress, surrounded by gold and white ornate details. The woman is depicted in mid-air, with her arms outstretched and her legs bent at the knees. She is holding a bouquet of flowers in her right hand and a fruit in her left hand.
The background of the painting is a light blue sky with pink clouds, and there are also some pink flowers and green leaves surrounding the woman. The overall atmosphere of the painting is one of joy and celebration, as if the woman is dancing or celebrating something.
This piece belongs to the Rococo era, which was a style of art and architecture that emerged in Europe in the 18th century. The Rococo style is characterized by its use of pastel colors, curved
lines, and ornate details. It was popularized during the reign of King Louis XV of France, who ruled
from 1715 to 1774.


















 1537
1537

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









