










安装
1、创建一个创建虚拟环境
conda create -n llamaindex python==3.12 -y
conda activate llamaindex
2、安装 llama-index
注意llama-index每一个版本都互不兼容
###目前版本是0.12.32
pip install llama-index -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install llama-index-embeddings-huggingface -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install llama-index-llms-huggingface -i https://pypi.tuna.tsinghua.edu.cn/simple
3、代码示例
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.core import Settings,SimpleDirectoryReader,VectorStoreIndex
from llama_index.llms.huggingface import HuggingFaceLLM
#初始化一个HuggingFaceEmbedding对象,用于将文本转换为向量表示
embed_model = HuggingFaceEmbedding(
#指定了一个预训练的sentence-transformer模型的路径
model_name=r"D:model\sentence-transformers\paraphrase-multilingual-MiniLM-L12-v2"
)
#将创建的嵌入模型赋值给全局设置的embed_model属性,这样在后续的索引构建过程中,就会使用这个模型
Settings.embed_model = embed_model
#使用HuggingFaceLLM加载本地大模型
llm = HuggingFaceLLM(model_name=r"D:models\Qwen\Qwen2___5-1___5B-Instruct",
tokenizer_name=r"D:models\Qwen\Qwen2___5-1___5B-Instruct",
model_kwargs={"trust_remote_code":True},
tokenizer_kwargs={"trust_remote_code":True,"use_sliding_window_attention": False})
#设置全局的llm属性,这样在索引查询时会使用这个模型。
Settings.llm = llm
#从指定目录读取文档,将数据加载到内存
documents = SimpleDirectoryReader(r"D:\data").load_data()
# print(documents)
#创建一个VectorStoreIndex,并使用之前加载的文档来构建向量索引
#此索引将文档转换为向量,并存储这些向量(内存)以便于快速检索
index = VectorStoreIndex.from_documents(documents)
#创建一个查询引擎,这个引擎可以接收查询并返回相关文档的响应。
query_engine = index.as_query_engine()
rsp = query_engine.query("xtuner是什么?")
print(rsp)
4、运行代码报错如下
D:\envs\llamaindex\python.exe "D:\Program Files\python\PycharmProjects\AiStudyProject\demo17\test02.py"
[nltk_data] Error loading stopwords: <urlopen error [Errno 11004]
[nltk_data] getaddrinfo failed>
[nltk_data] Error loading punkt: <urlopen error [Errno 11004]
[nltk_data] getaddrinfo failed>
Sliding Window Attention is enabled but not implemented for `sdpa`; unexpected results may be encountered.
[nltk_data] Error loading stopwords: <urlopen error [Errno 11004]
[nltk_data] getaddrinfo failed>
[nltk_data] Error loading punkt_tab: <urlopen error [Errno 11004]
[nltk_data] getaddrinfo failed>
Traceback (most recent call last):
File "D:\envs\llamaindex\Lib\site-packages\nltk\corpus\util.py", line 84, in __load
root = nltk.data.find(f"{self.subdir}/{zip_name}")
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\envs\llamaindex\Lib\site-packages\nltk\data.py", line 579, in find
raise LookupError(resource_not_found)
LookupError:
**********************************************************************
Resource stopwords not found.
Please use the NLTK Downloader to obtain the resource:
>>> import nltk
>>> nltk.download('stopwords')
For more information see: https://www.nltk.org/data.html
Attempted to load corpora/stopwords.zip/stopwords/
Searched in:
- 'C:\\Users\\fengxinzi/nltk_data'
- 'D:\\envs\\llamaindex\\nltk_data'
- 'D:\\envs\\llamaindex\\share\\nltk_data'
- 'D:\\envs\\llamaindex\\lib\\nltk_data'
- 'C:\\Users\\fengxinzi\\AppData\\Roaming\\nltk_data'
- 'C:\\nltk_data'
- 'D:\\nltk_data'
- 'E:\\nltk_data'
- 'D:\\envs\\llamaindex\\Lib\\site-packages\\llama_index\\core\\_static/nltk_cache'
**********************************************************************
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "D:\Program Files\python\PycharmProjects\AiStudyProject\demo17\test02.py", line 30, in <module>
index = VectorStoreIndex.from_documents(documents)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\envs\llamaindex\Lib\site-packages\llama_index\core\indices\base.py", line 112, in from_documents
nodes = run_transformations(
^^^^^^^^^^^^^^^^^^^^
File "D:\envs\llamaindex\Lib\site-packages\llama_index\core\ingestion\pipeline.py", line 100, in run_transformations
nodes = transform(nodes, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\envs\llamaindex\Lib\site-packages\llama_index\core\instrumentation\dispatcher.py", line 322, in wrapper
result = func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^
File "D:\envs\llamaindex\Lib\site-packages\llama_index\core\node_parser\interface.py", line 193, in __call__
return self.get_nodes_from_documents(nodes, **kwargs) # type: ignore
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\envs\llamaindex\Lib\site-packages\llama_index\core\node_parser\interface.py", line 165, in get_nodes_from_documents
nodes = self._parse_nodes(documents, show_progress=show_progress, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\envs\llamaindex\Lib\site-packages\llama_index\core\instrumentation\dispatcher.py", line 322, in wrapper
result = func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^
File "D:\envs\llamaindex\Lib\site-packages\llama_index\core\node_parser\interface.py", line 260, in _parse_nodes
splits = self.split_text_metadata_aware(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\envs\llamaindex\Lib\site-packages\llama_index\core\instrumentation\dispatcher.py", line 322, in wrapper
result = func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^
File "D:\envs\llamaindex\Lib\site-packages\llama_index\core\node_parser\text\sentence.py", line 173, in split_text_metadata_aware
return self._split_text(text, chunk_size=effective_chunk_size)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\envs\llamaindex\Lib\site-packages\llama_index\core\node_parser\text\sentence.py", line 190, in _split_text
splits = self._split(text, chunk_size)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\envs\llamaindex\Lib\site-packages\llama_index\core\node_parser\text\sentence.py", line 211, in _split
text_splits_by_fns, is_sentence = self._get_splits_by_fns(text)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\envs\llamaindex\Lib\site-packages\llama_index\core\node_parser\text\sentence.py", line 313, in _get_splits_by_fns
splits = split_fn(text)
^^^^^^^^^^^^^^
File "D:\envs\llamaindex\Lib\site-packages\llama_index\core\node_parser\text\utils.py", line 84, in <lambda>
text, globals_helper.punkt_tokenizer
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\envs\llamaindex\Lib\site-packages\llama_index\core\utils.py", line 117, in punkt_tokenizer
self._stopwords = stopwords.words("english")
^^^^^^^^^^^^^^^
File "D:\envs\llamaindex\Lib\site-packages\nltk\corpus\util.py", line 120, in __getattr__
self.__load()
File "D:\envs\llamaindex\Lib\site-packages\nltk\corpus\util.py", line 86, in __load
raise e
File "D:\envs\llamaindex\Lib\site-packages\nltk\corpus\util.py", line 81, in __load
root = nltk.data.find(f"{self.subdir}/{self.__name}")
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\envs\llamaindex\Lib\site-packages\nltk\data.py", line 579, in find
raise LookupError(resource_not_found)
LookupError:
**********************************************************************
Resource stopwords not found.
Please use the NLTK Downloader to obtain the resource:
>>> import nltk
>>> nltk.download('stopwords')
For more information see: https://www.nltk.org/data.html
Attempted to load corpora/stopwords
Searched in:
- 'C:\\Users\\fengxinzi/nltk_data'
- 'D:\\envs\\llamaindex\\nltk_data'
- 'D:\\envs\\llamaindex\\share\\nltk_data'
- 'D:\\envs\\llamaindex\\lib\\nltk_data'
- 'C:\\Users\\fengxinzi\\AppData\\Roaming\\nltk_data'
- 'C:\\nltk_data'
- 'D:\\nltk_data'
- 'E:\\nltk_data'
- 'D:\\envs\\llamaindex\\Lib\\site-packages\\llama_index\\core\\_static/nltk_cache'
**********************************************************************
Process finished with exit code 1
错误表明 NLTK 仍无法加载 stopwords 和 punkt 资源。
我的nltk版本如下:

5、解决方案:手动下载并放置资源文件
- 下载资源包:
- 访问 NLTK 下载页面,下载以下文件:
stopwords.zippunkt.zip
- 访问 NLTK 下载页面,下载以下文件:
-
解压到 NLTK 的搜索路径:
根据错误信息,优先将文件解压到以下路径:D:\envs\llamaindex\nltk_data\corpora\ # 解压 stopwords.zip 到此路径 D:\envs\llamaindex\nltk_data\tokenizers\ # 解压 punkt.zip 到此路径如果路径不存在,手动创建文件夹。
-
验证资源加载:
在 Python 中运行以下代码,检查资源是否能正确加载:import nltk # 尝试加载资源 print(nltk.data.find('corpora/stopwords')) print(nltk.data.find('tokenizers/punkt'))输出路径(如
D:\envs\llamaindex\nltk_data\corpora\stopwords),说明配置成功。
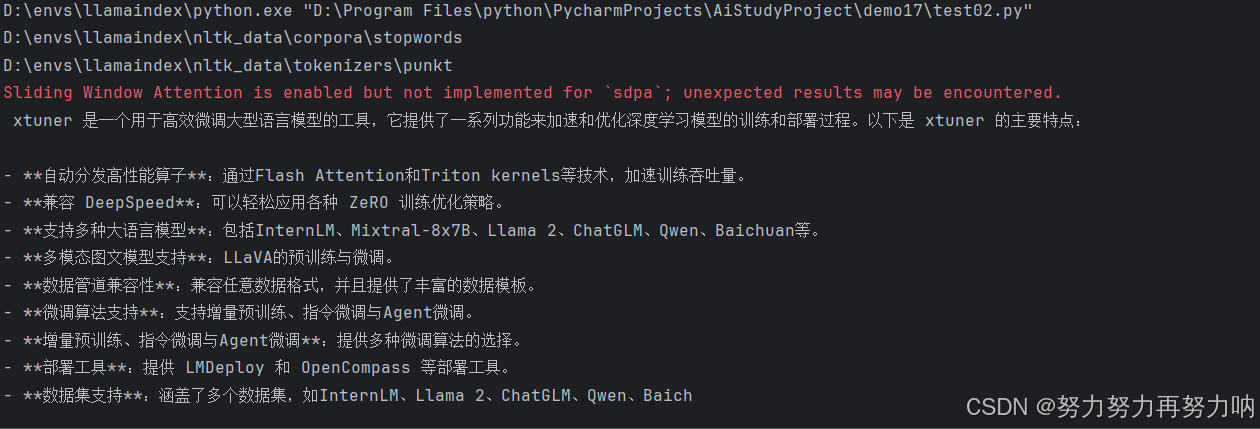
6、再次测试成功
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.core import Settings,SimpleDirectoryReader,VectorStoreIndex
from llama_index.llms.huggingface import HuggingFaceLLM
import nltk
# 下载 NLTK 资源
# 尝试加载资源
print(nltk.data.find('corpora/stopwords'))
print(nltk.data.find('tokenizers/punkt'))
#初始化一个HuggingFaceEmbedding对象,用于将文本转换为向量表示
embed_model = HuggingFaceEmbedding(
#指定了一个预训练的sentence-transformer模型的路径
model_name=r"D:\model\sentence-transformers\paraphrase-multilingual-MiniLM-L12-v2"
)
#将创建的嵌入模型赋值给全局设置的embed_model属性,这样在后续的索引构建过程中,就会使用这个模型
Settings.embed_model = embed_model
#使用HuggingFaceLLM加载本地大模型
llm = HuggingFaceLLM(model_name=r"D:\models\Qwen\Qwen2___5-1___5B-Instruct",
tokenizer_name=r"D:models\Qwen\Qwen2___5-1___5B-Instruct",
model_kwargs={"trust_remote_code":True},
tokenizer_kwargs={"trust_remote_code":True,"use_sliding_window_attention": False})
#设置全局的llm属性,这样在索引查询时会使用这个模型。
Settings.llm = llm
#从指定目录读取文档,将数据加载到内存
documents = SimpleDirectoryReader(r"D:\data").load_data()
# print(documents)
#创建一个VectorStoreIndex,并使用之前加载的文档来构建向量索引
#此索引将文档转换为向量,并存储这些向量(内存)以便于快速检索
index = VectorStoreIndex.from_documents(documents)
#创建一个查询引擎,这个引擎可以接收查询并返回相关文档的响应。
query_engine = index.as_query_engine()
rsp = query_engine.query("xtuner是什么?")
print(rsp)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









