






目录
1.语义分割的目标
语义分割的任务是对输入的图像进行逐像素的分类,标记出像素级别的物体。

如上图,图1中把猫、天空、树、草地进行了逐像素的分类;图2中把牛、 天空、树、草地进行了逐像素的分类。
2.目标检测的目标
目标检测的任务是对输入的图像进行物体检测,标注物体在图像上的位 置,以及该位置上物体属于哪个分类

如上图,模型把图中的人、狗、马分别进行了位置标注,并且也给出了对 应的分类类别。
3.两种任务的异同之处
从大方向的任务特点上来说
从大方向的任务特点来说,语义分割和目标检测任务目标都在意两个关键 信息:
(1)物体的位置
待检测的物体,它在图像中位于什么位置。
对于语义分割来说,这个信息需求的精准度在像素级别的。概括地说,我们需要把物体的轮廓描绘出来,以此来体现它的位置信息。
对于目标检测来说,这个信息需求的精准度仅在标注其外切矩形。换句话 来说,把物体框出来,以此来体现它的位置信息。
(2)物体的分类
有了位置信息之后,语义分割和目标检测都存在对物体的分类。不同的 是:
对于语义分割来说,它提供的信息中位置信息和分类信息是有重叠的,即 通过标记每个像素的分类,同时也达到提供位置信息。
对于目标检测来说,分类信息是针对每个标注的框的,每一个框对应着自 己的分类。
从数据格式来说
正如前文所说,由于在任务的目标上存在着一些区别,这就使得它们需要 不同的数据格式进行标注。
(1)语义分割的数据格式
如上图,这张图中先验是5个类别。在分类中,会有5个channel,每个 channel负责一个类别的概率预测。最后,每个像素上,以5个channel中的最 大值作为最终分类,以此完成图像语义分割的标注工作。
(2)目标检测的数据格式
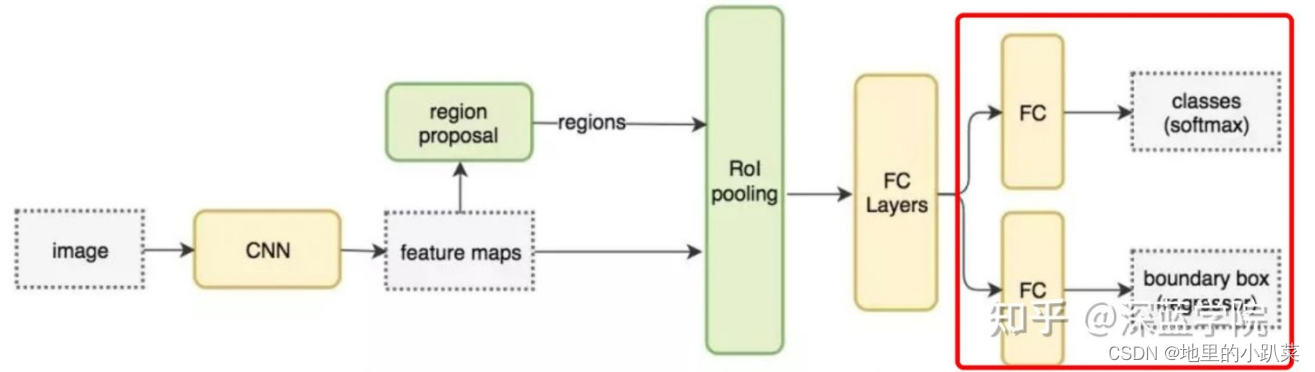
从上图中我们可以看到,对于目标检测的数据格式分为了两个部分,分类 和框的坐标。具体体现为:
分类最终体现在对每个潜在框分类的11channel上,每个channel代表一个 分类,取值最大的channel作为最终分类;位置信息会用4个值来保存:被分类 的物体中它的框的坐标则为左上角的x和y坐标,以及宽和高的尺寸。















 4970
4970

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









