







前言
学习数学建模过程中的Fisher笔记,顺便复习已经学过的模式识别,本文章将用SPSS来分析国赛数模2020C第二题,根据已有指标将给一些企业进行信用评级。笔者还是个菜鸡,如有错误欢迎指正。
**注意:**可能是因为指标选取不当或方法不适合,正确率低于50%
一、2020C题目
国赛数模2020C题目,详情见CUMCM官网
二、选取指标
1.未归一化指标
我需要根据2020C的附件一和附件二共有的信息来确定302个企业的信用评级。于是选取指标2017~2019年的利润额(销项加税合计-进项加税合计,企业能否承担还款的资金)、交易总额(销项加税合计+进项加税合计,企业的规模)、成功订单量
退货率、供求方数量(上下游企业)
附件二:
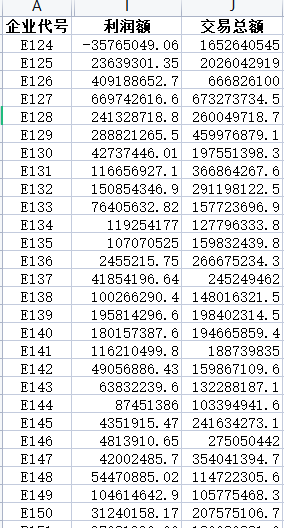

附件一:

2.归一化、正向化
利用如下公式进行处理: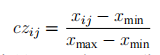
得到归一化数据


三、Fisher判别法介绍
简单来说就是找到一个超平面,使得两类数据的类内方差最小,类见方差最大。
具体理论分析可见Fisher 线性分类器(1)----Fisher准则函数
这个答主写的挺好的,通过spss可以直接使用该方法进行判别,因此不在这里赘述。
四、SPSS的使用
首先将已经归一化的附件一的数据导入到spss中(注意:信用评级的变量类型要改为“有序”)。
这里用4、3、2、1分别表示A、B、C、D。

选择菜单栏的分析-分类-判别式

将自变量和分组变量导入,这时发现分组变量有两个“?”,是还没定义上下限。

本题上下限分别是4和1。

在“统计”中勾选“费舍尔(Fisher)”(如果导入的是为标准化的数据,也要勾选“未标准化”)
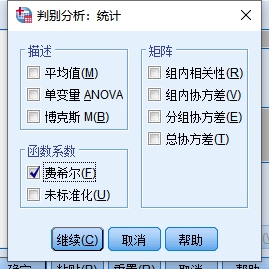
在“分类”中勾选“摘要表”

“保存”中如下图勾选

然后点击确定,得到分析结果

正确率只有46.5%
如果导入附件二的归一化数据就可以按照Fisher的方法,对附件二进行分类了
总结
先前尝试过线性回归、树、支持向量机、神经网络的分类方法,对该组数据进行分析,结果并不令人满意,线性回归和支持向量机直接歇菜,只有神经网络能勉强达到70%左右的正确率。
还望能得到大神的指点,非常感谢














 762
762











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









