







继续是机器学习课程的笔记,这节课会介绍逻辑回归。
分类问题
这节课会介绍的是分类问题,其结果是离散值。分类问题的例子有判断电子邮件是否是垃圾邮件;判断肿瘤是良性还是恶性;判断一次金融交易是否是欺诈等等。
首先从二元的分类问题说起,我们将因变量可能属于的两个类分别称为负类(Negative Class)和正类(Positive Class),则因变量
其中0表示负类,而1表示正类。
分类问题建模
回到初始的乳腺癌分类问题,我们可以用线性回归的方法求出适合数据的一条直线,如下图所示:
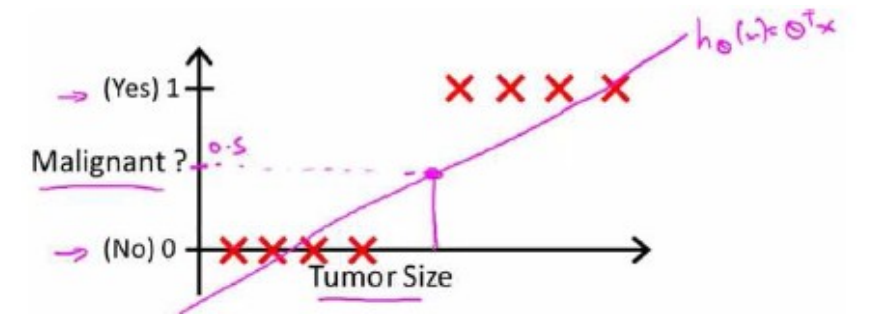
根据线性回归模型,我们只能预测连续值,但对于分类问题,我们需要输出的是0或1,我们可以如此预测:
- 当 hθ≥0.5 ,预测 y=1
- 当 hθ<0.5 ,预测 y=0
那么通过这样的预测,上图所示的数据是可以根据一个线性模型就能很好地完成分类任务的。
但是,此时假设增加了一个非常大尺寸的恶性肿瘤,将其作为实例加入到训练集中,这使得我们获得一条新的直线,如下图所示,
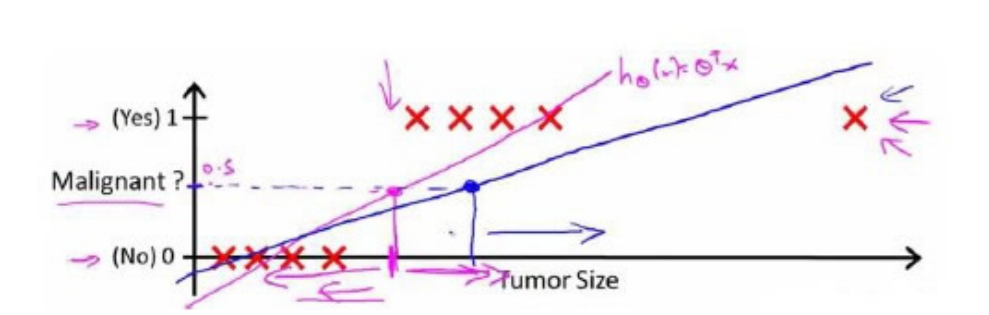
这个时候使用阈值为0.5来预测是否是恶性肿瘤就不合适了,因为会将原来预测为恶性肿瘤的数据预测为良性肿瘤了。可以看出,线性回归模型,因为其预测的值可以超越 [0,1] 的范围,并不适合解决这样的问题。
所以,我们就引入一个新的模型–逻辑回归(Logistic Regression): 0≤htheta(x)≤1 ,即其输出变量范围始终在[0,1]。
逻辑回归简介
逻辑回归模型的假设是:
其中:
* X 代表特征向量
*
所以,我们可以得到逻辑回归模型的假设是:
对于这个模型,可以理解为:
hθ(x) 就是对于给定的输入变量 x ,根据选择的参数计算输出变量
y=1 的可能性,也就是概率值,即 hθ(x)=P(y=1|x;θ)
举个例子,如果对于给定的x,通过已经确定的参数计算得到
hθ(x)=0.7
,则表示有70%的几率可以判定
y
是正类,相应地
决策边界
在之前的逻辑回归中,我们是如此预测的:
- 当 hθ≥0.5 ,预测 y=1
- 当 hθ<0.5 ,预测 y=0
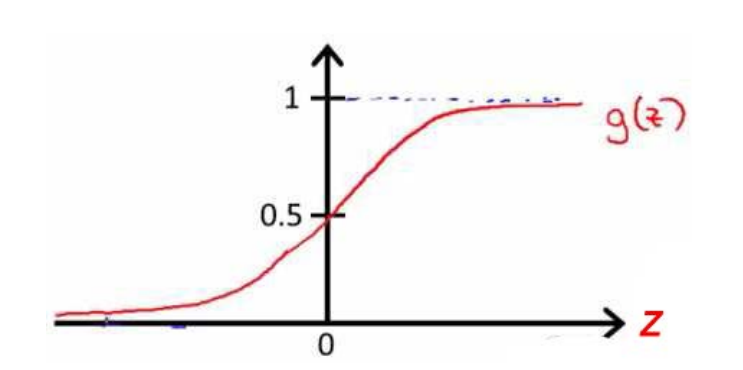
根据上面的S形函数图象,我们可以知道:
- z=0 时, g(z)=0.5
- z>0 时, g(z)>0.5
- z<0 时, g(z)<0.5
又因为 z=θTX ,则有:
- θT≥0 ,预测 y=1
- θT<0 ,预测 y=0
线性边界
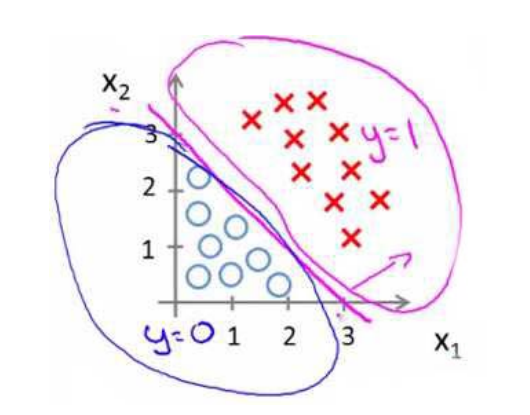
现在假设有一个模型 hθ(x)=g(θ0+θ1x1+θ2x2) ,且参数 θ=⎡⎣⎢−311⎤⎦⎥
那么当
−3+x1+x2≥0
时,可以预测
y=1
,所以我们可以绘制直线
x1+x2=3
,这条线便是我们模型的分界线,将预测为1和预测为0的区域分隔开,如下图所示。
非线性边界
上述例子中的决策边界是一个线性边界,但是并非所有数据都可以通过逻辑回归模型得到一个线性边界的,是存在有非线性边界的,如下图所示
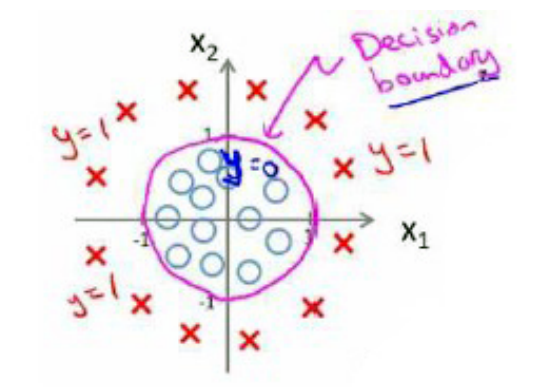
看得出来这个例子中需要使用一个曲线,所以需要二次方特征:
假设参数是 θ=⎡⎣⎢⎢⎢⎢⎢⎢−10011⎤⎦⎥⎥⎥⎥⎥⎥ ,这样我们得到的决策边界恰好是一个圆心在原点,半径是1的圆形。
除了上述例子,还可以有更复杂的模型来适合非常复杂形状的决策边界,比如使用到三次方特征等。
代价函数
在线性回归模型中,我们定义的代价函数是所有建模误差的平方和函数。也就是
J(θ)=12m∑mi=1(hθ(x(i))−y(i))2
。
在逻辑回归模型中可以沿用这个定义,并且我们假设
Cost(hθ(x(i)),y(i))=12(hθ(x(i))−y(i))2
,但是,这里就会产生一个问题:我们得到的代价函数将是一个
非凸函数(non−convex function)
。非凸函数和凸函数的图像如下所示:
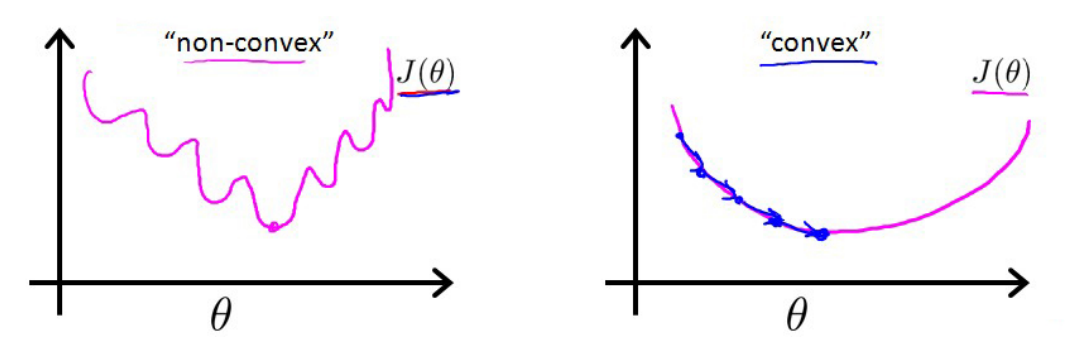
这意味着代价函数将有许多局部最小值,会影响梯度下降算法寻找全局最小值。
因此我们重新定义逻辑回归的代价函数为
J(θ)=1m∑mi=1Cost(hθ(x(i)),y(i))
,其中
也就是
hθ(x)
与
Cost(hθ(x),y)
的关系如下图所示:
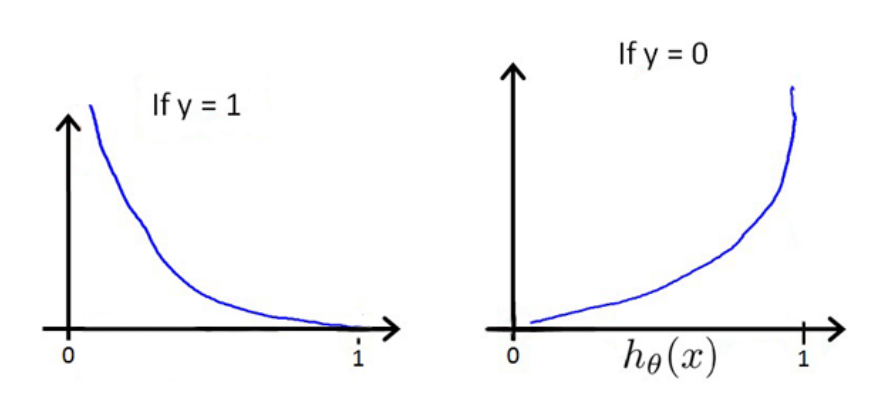
这样构建的 Cost(hθ(x),y) 函数的特点是:
当实际的 y=1 且 hθ=1 时,误差为0,但如果 hθ≠1 时,误差会随着 hθ 的变小而变大;
当实际的 y=0 且 hθ=0 时,误差为0,但如果 hθ≠0 时,误差会随着 hθ 的变大而变大;
简化代价函数
接下来是简化代价函数,将代价函数用一行来表示,由于
y
总是0或1中的一个值,所以,我们可以简化代价函数成如下所示:
那么代价函数是:
梯度下降法
得到上述简化后的代价函数后,我们就可以使用梯度下降算法来求得能使得代价函数最小的参数了。
算法如下所示:
Repeat
θj := θj−α∂∂θjJ(θ)
同时更新所有的参数 θ
求导后得到:
Repeat
θj := θj−α∑i=1m(hθ(x(i))−y(i))x(i)j
同时更新所有的参数 θ
注意:这里虽然得到的梯度下降算法的公式表面上和线性回归得到的梯度下降算法一样,但是两者的模型 hθ(x) 是不一样的,线性回归的是 hθ(x)=θTx ,而逻辑回归的是 hθ(x)=11+e−θTx ,因此两者是不一样的,同时在运行梯度下降算法之前,进行进行特征缩放依旧是必要的。
高级优化方法
目前介绍的让代价函数最小的算法是有使用梯度下降算法以及正规方程方法,但除此之外还有其他算法,它们更加复杂和优越,而且通常不需要人工选择学习率,通常比梯度下降算法要更加快速。
这些算法有:共轭梯度(Conjugate gradient),局部优化法(Broyden fletcher goldfarb shann,BFGS),有限局部优化法(L-BFGS)。
但是这些算法的最大缺点也就是非常复杂了,所以一般是建议直接使用现有的第三方库中实现好的函数来直接运行这些算法,而不是自己写代码来实现。
多类分类
在多类分类问题中,我们的训练集有多个类,此时就无法仅仅用一个二元变量(0或1)来做判断依据。例如,我们要预测天气情况,分四种类型:晴天、多云、下雨或下雪。
下面是一个多类分类问题可能的情况:
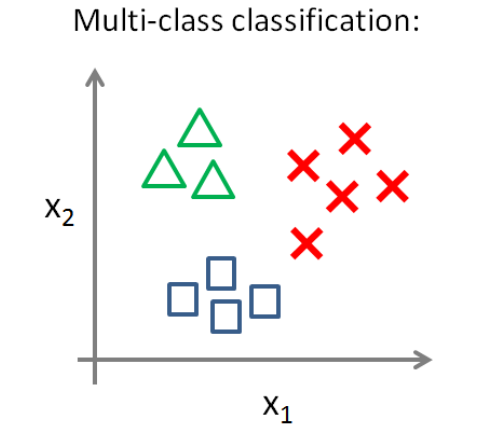
一种解决这类问题的方法是采用一对多(One-vs-All)方法。在一对多方法中,我们可以将多类分类问题转换成二元分类问题。
为了能实现这样的转变,我们将多个类中的一个类标记为正类(
y=1
),然后将其他所有类标记为负类,这个模型记作
h(1)θx
。接着,我们可以同样选择另一个类标记为正类(
y=2
),再将其他类标记为负类,这个模型记作
h(2)θx
,依次类推,也就是可以如下图所示。
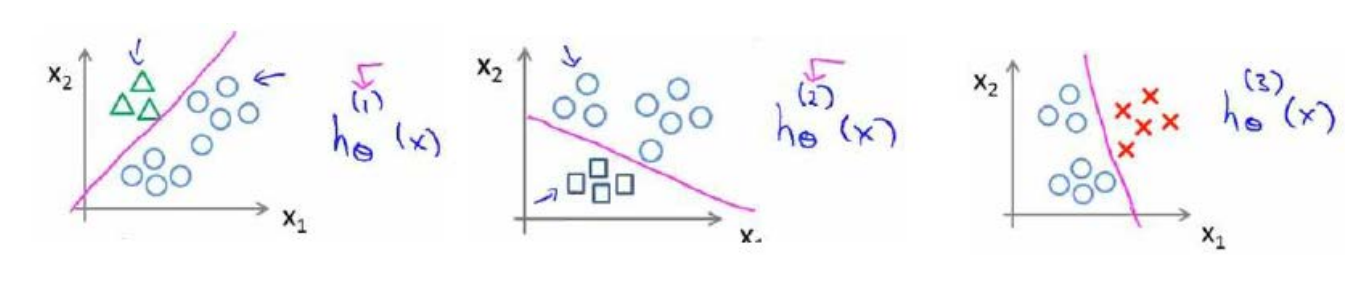
最后我们得到一系列的模型简记为:
h(i)θ=p(y=i |x;θ)其中i=(1,2,3,…,k)
,也就是对于
k
个类的分类问题,使用一对多方法,会得到
然后在预测的时候,对于输入变量
x
,我们会将所有的分类器都运行一遍,然后选择一个类别
小结
本节内容是介绍逻辑回归问题,对应的就是监督学习中的分类问题。这里之所以有回归二字,是因为其使用的模型形式是类似于线性回归的。当然这里介绍的模型函数是一个S形函数,用来解决一个二元分类问题。
接下来就是介绍代价函数,由于直接套用线性回归的代价函数,会得到一个非凸函数,不利于使用梯度下降法来寻找局部最小值,所以这里是使用了一个新的代价函数来达到同样的效果,因此也就顺利得到需要的代价函数以及梯度下降算法的公式。
最后就介绍了除了梯度下降法之外的一些优化方法,但是这些方法会比梯度下降法要复杂得多。然后还有就是对于多类分类问题可以使用一对多的方法来转换成二元分类问题。















 983
983











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











