







继续是机器学习课程的笔记,本节课将介绍推荐系统的内容。
问题形式化
推荐系统是机器学习的一个非常重要的应用,在很多音乐、购物等网站都有推荐系统,如豆瓣,淘宝,网易云音乐等都是有使用到推荐系统的,因此推荐系统的应用范围非常广泛。
我们从一个例子开始定义推荐系统的问题。
假设我们是一个电影供应商,我们有5部电影和4个用户,我们要求用户为电影评分。
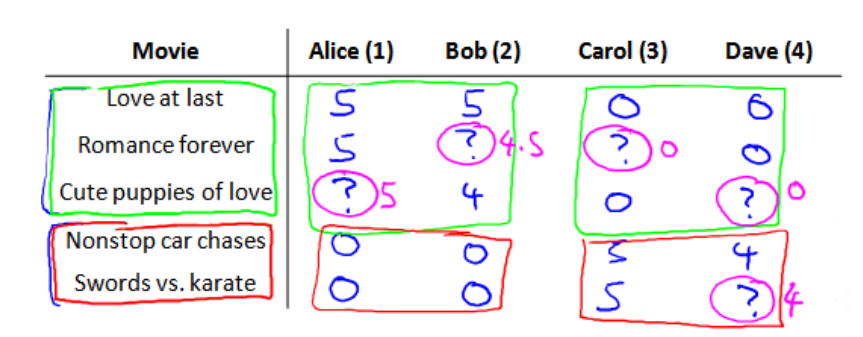
由上图可以知道,前3部电影是爱情片,后两部是动作片,用户Alice和Bob似乎更倾向于爱情片,而其他两位用户Carol和Dave似乎更倾向于动作片。并且没有一个用户给所有的电影都打过分,我们希望构建一个算法来预测他们每个人可能会给他们没看过的电影打多少分,并依此作为推荐的依据。
下面引入一些标记:
- nu 代表用户的数量
- nm 代表电影的数量
- r(i,j)=1 表示用户i给电影j评过分
- y(i,j) 代表用户i给电影j的评分,在上图中,其评分范围是0~5分
- mj 代表用户j评过分的电影的总数
基于内容的推荐系统
在一个基于内容的推荐系统算法中,我们假设对于我们希望推荐的东西有一些数据,这些数据就是有关这些东西的特征。
在我们的例子中,我们可以假设每部电影都有两个特征,如 x1 代表电影的浪漫程度, x2 代表电影的动作程度。
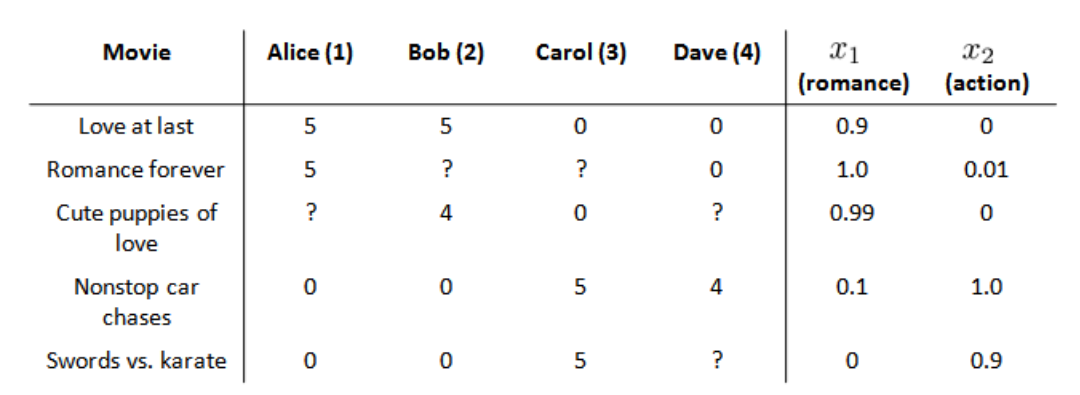
如上图所示,每部电影都有一个特征向量,如 x(1)=[0.9,0] 是第一部电影的特征向量。
下面我们可以基于这些特征来构建一个推荐系统算法。
假设我们使用线性回归模型,我们可以针对每个用户都训练一个线性回归模型,如 θ(1) 是第一个用户的模型的参数。
于是,我们有:
* θ(j) 是用户j的参数向量
* x(i) 是电影i的特征向量
对于用户j和电影i,我们预测评分为: (θ(j))T(x(i))
对于用户j,该线性回归模型的代价函数为预测误差的平方和,加上归一化项:
其中, i:r(i,j)=1 表示我们只计算用户j评过分的电影。在一般的线性回归模型中,误差项和归一化项应该都是乘以 12m ,在这里我们将m去掉,并且不对偏倚项 θ0 进行归一化处理。
上面的代价函数是针对一个用户的,为了学习所有用户,我们将所有用户的代价函数求和:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2343
2343











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











