







 本文是机器学习笔记的一部分,专注于异常检测,一种非监督学习算法。介绍了密度估计、高斯分布和异常检测算法的原理,强调了特征选择的重要性。通过设置阈值并利用高斯分布进行异常检测,同时探讨了多元高斯分布在处理相关特征时的优势。此外,还讨论了如何评价异常检测系统以及与监督学习的区别。
本文是机器学习笔记的一部分,专注于异常检测,一种非监督学习算法。介绍了密度估计、高斯分布和异常检测算法的原理,强调了特征选择的重要性。通过设置阈值并利用高斯分布进行异常检测,同时探讨了多元高斯分布在处理相关特征时的优势。此外,还讨论了如何评价异常检测系统以及与监督学习的区别。
继续是机器学习课程的笔记,本节课内容是异常检测,它是一个非监督学习算法,用于发现可能不应该属于一个已定义的组中的数据。
密度估计
首先是给出一个例子,如下图所示,是一个测试飞机引擎的例子,给定数据集{ x(1),x(2),…,x(m) },假设数据集是正确的,我们希望知道新的数据 xtest 是不是异常的,即这个测试数据不属于该组数据的几率如何。我们所构建的模型应该能根据该测试数据的位置告诉我们其属于一组数据的可能性 p(x) 。
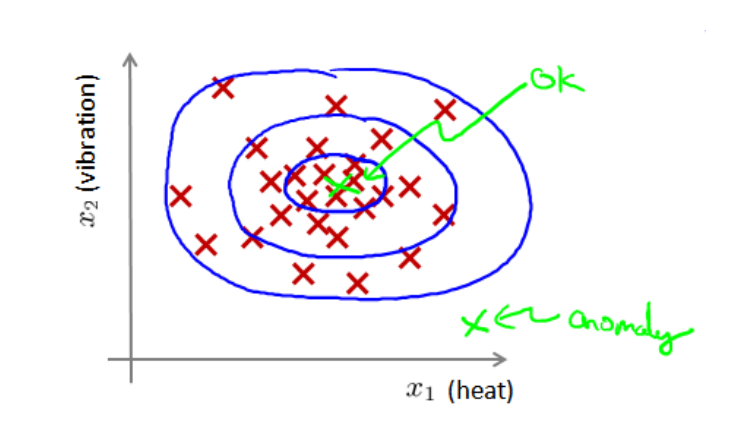
在上图中,在蓝色圈内的数据属于该组数据的可能性较高,而越是偏远的数据,其属于该组数据的可能性就越低。
这种方法称为密度估计,表达如下:
ifp(x){
≤ϵanomaly>ϵnormal
异常检测主要用来识别欺骗。
例如,在线采集而来的有关用户的数据,一个特征向量中可能会包含如:用户多久登陆一次,访问过的页面,在论坛发布的帖子数量,甚至是打字速度等。尝试根据这些特征构建一个模型,可以用这个模型来识别那些不符合该模式的用户。
再一个例子是检测一个数据中心,特征可能包含:内存使用情况,被访问的磁盘数量,CPU的负载,网络的通信量等。根据这些特征可以构建一个模型,用来判断某些计算机是否有可能出错了。
高斯分布
接下来回顾下高斯分布的基本知识。
通常如果我们认为变量x符合高斯分布,即 x∼N(μ,σ2) ,则其概率密度函数为:
p(x,μ,σ2)=1(√2π)σexp−((x−μ)22σ2)
下图是 μ 和 σ2 取不同值时,高斯分布的曲线图例子:
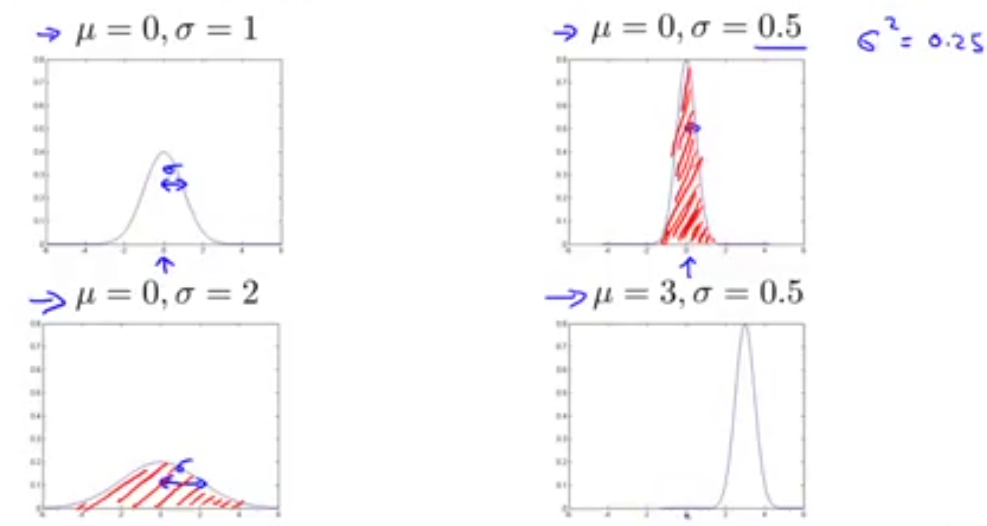
我们可以利用已有的数据来预测总体中的 μ 和 σ2 ,计算方法如下:
μ=
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1259
1259

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











