







 这篇博客介绍了编译器的基础概念,包括编译器与解释器的区别,以及编译器的模块化结构。重点讨论了词法分析阶段,详细阐述了词法分析器的工作原理,特别是通过正则表达式构建非确定有限状态自动机(NFA)的过程,并提及了将NFA转换为确定有限状态自动机(DFA)的必要性。
这篇博客介绍了编译器的基础概念,包括编译器与解释器的区别,以及编译器的模块化结构。重点讨论了词法分析阶段,详细阐述了词法分析器的工作原理,特别是通过正则表达式构建非确定有限状态自动机(NFA)的过程,并提及了将NFA转换为确定有限状态自动机(DFA)的必要性。
文章目录
一、编译器概述
1.编译器
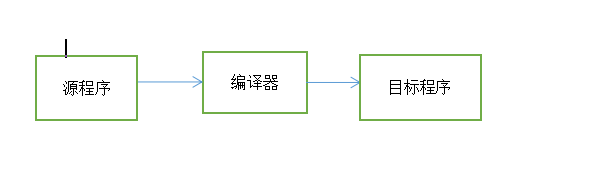
编译器是一个程序
核心功能是把源代码个翻译成目标代码,输出一个可执行程序
源代码:C/C+++,java ,html,SQL
目标代码: xxx86,IA64,ARM,MIPS
2.解释器
解释器也是处理程序的一种程序,直接输出结果
3.编译结构
编译器是非常模块化的高层结构,
4.栈
栈(stack)在计算机科学中是限定仅在表尾进行插入或删除操作的线性表。栈是一种数据结构,它按照后进先出的原则存储数据,先进入的数据被压入栈底,最后的数据在栈顶,需要读数据的时候从栈顶开始弹出数据。栈是只能在某一端插入和删除的特殊线性表。用桶堆积物品,先堆进来的压在底下,随后一件一件往上堆。取走时,只能从上面一件一件取。读和取都在顶部进行,底部一般是不动的。栈就是一种类似桶堆积物品的数据结构,进行删除和插入的一端称栈顶,另一端称栈底。插入一般称为进栈,删除则称为退栈。 栈也称为后进先出表。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









