






 本文介绍了DeformableDETR如何通过引入DeformableAttentionModule解决传统detr在处理大图像时的计算效率问题,以及其如何结合可变型卷积和Transformer,特别是如何处理多尺度特征中的对齐问题。作者还详细解释了偏移量在计算过程中的作用和整体算法流程。
本文介绍了DeformableDETR如何通过引入DeformableAttentionModule解决传统detr在处理大图像时的计算效率问题,以及其如何结合可变型卷积和Transformer,特别是如何处理多尺度特征中的对齐问题。作者还详细解释了偏移量在计算过程中的作用和整体算法流程。
前言
传统detr受限于不能输入特别大的图像到网络,因为展开为一个序列输入到transformer中时,序列长度呈原图宽(高)的指数倍,而且在transformer中展开序列的每一个像素点都需要对全部像素点求注意力,增加图片尺寸对计算量的影响非常大。在deformable-detr中就提出每个位置都只对附近位置进行注意力计算,而不是对全部位置进行计算,降低了计算量。
可变型卷积只知道这些点是重要特征,缺少对点与点之间的位置关系进行联系。在deformable-detr主要的创新点是将可变型卷积与transformer进行关联---- Deformable Attention Module。
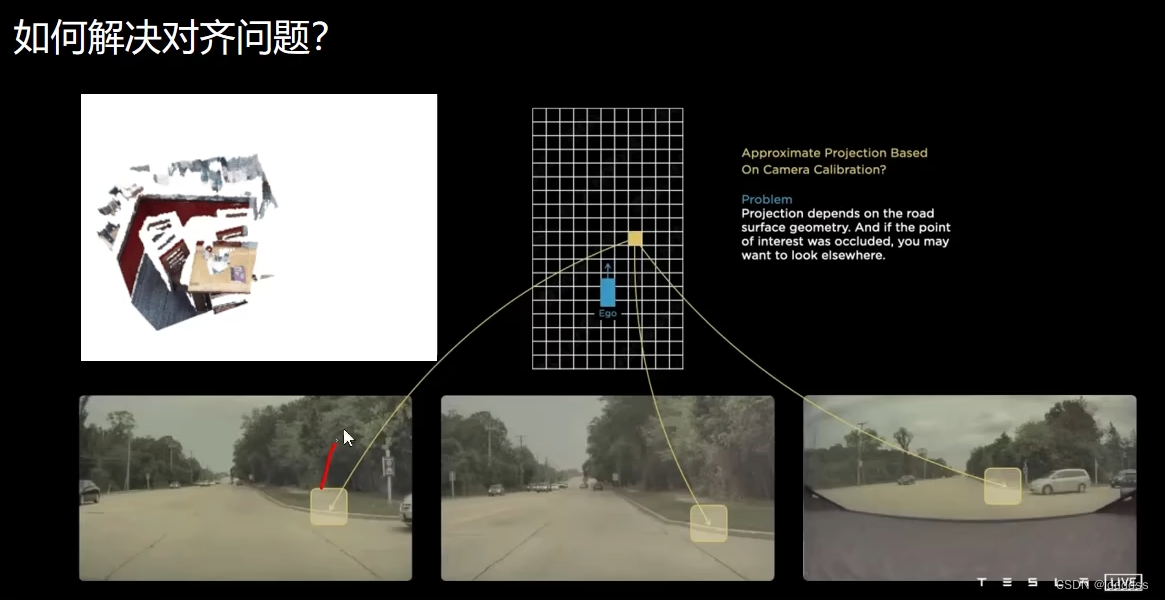
另外,涉及到multi-scale features>>多视角特征中不同大小特征图针对同一个目标的对齐问题?输入的大小不同,每个点的位置都会出现或多或小的偏差---通过偏移解决
Deformable Attention Module

式中,q代表一个像素点,Zq代表组成当前采样点的向量,Pq表示采样点的位置关系2-d reference(2d坐标),M表示mult_head atten的head数,K表示采样点数目,Amqk表示在当前层mult_head atten中每个点计算得到的注意力权重,,表示在Pq下的偏移量,Wm与
表示两个全连接层FC,x表示输入特征图,其中
与Amqk是需要训练的两个重要参数,都是通过全连接层预测出来的。
偏移量sampling offset
举个例子,对当前目标点Zq初始化采样周围四个点,这四个点是固定的,对每一个点都估计一个偏移量到当前采样点相对重要的四个位置(偏移量是由Zq预测得到的,每一个点Zq对应一个特征,连上一个全连接层预测8个值(4x2,四组偏移量),更新w与b即能预测不同的四组偏移量)
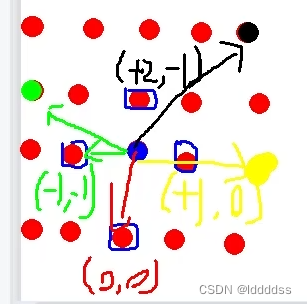
然而加上偏移量的每一个位置并不是刚好对应一个点,没有索引值就对应不到一个具体的位置
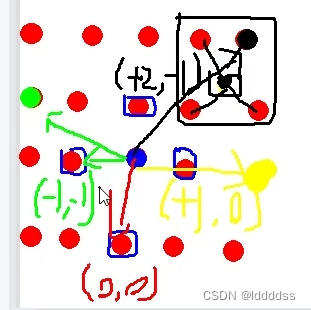
偏移点附近的四个点每个点都对特征有贡献,即对偏移点取周围的四个点进行插值计算特征(更新Pq+),同时乘上Amqk,体现每一个偏移后的点对目标点的特征的重要性。
总的来说,可变型就是偏移量可变 ,可变型注意力模块就是对中心点特征通过周围的点偏移量计算后注意到更远的点做注意力。
具体Deformable Attention Module的流程如下图所示:
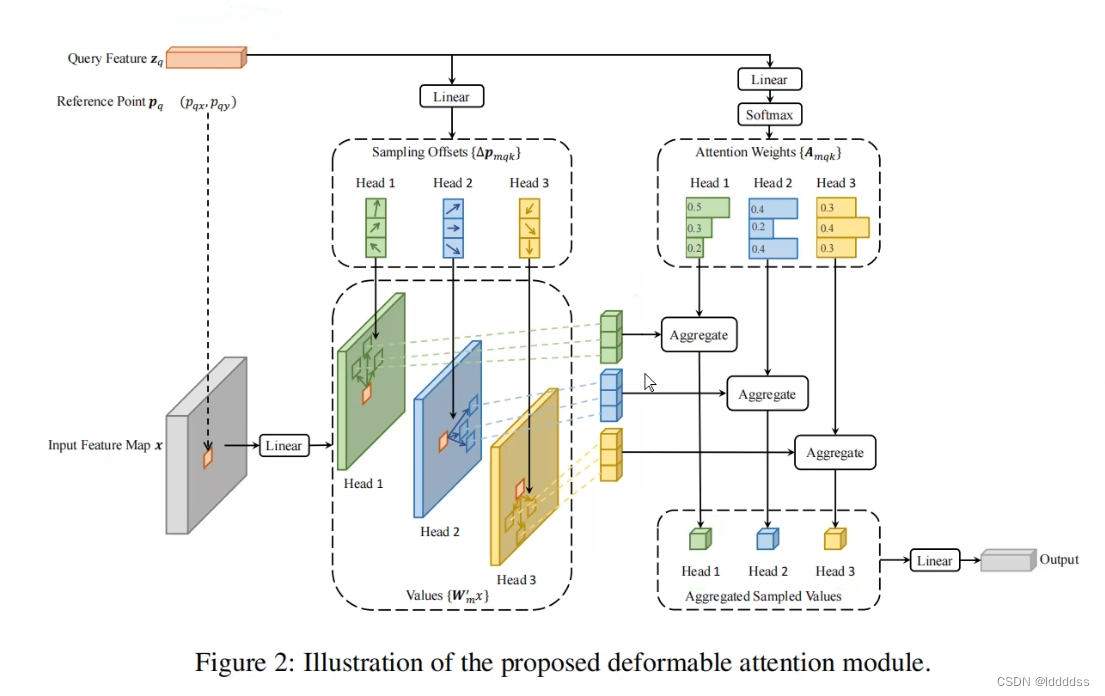
在transformer中输入序列x(在图中是特征图的形式)通过三个FC层得到对应的Q、K、V,在Deformable Attention Module中同样对x中目标点Zq连接一个FC层,得到Zq点的V;同时将Zq连接一个FC层预测偏移量sampling offset和Amqk,将Zq对应的k组偏移量组成的特征空间输出,然后通过Amqk对每一组不同偏移量的特征空间进行权重赋值然后相加,输出Aggregated Sampled Values在连接一个FC层得到最终输出。
Multi-Scale Deformable Attention Module

式中,L代表多尺度特征图的个数,每个层级特征偏移量不一样,最终输出特征是由多个层级特征(每个层级特征维度是相同的)做一个累加得到的。
需要注意的是:
1.需要做归一化操作,由于每个特征图尺寸不一样,因此绝对位置坐标不能表示同一个Zq在不同特征图的位置坐标,将其归一化转换为相对坐标表示。
2.相对坐标并不能绝对准确的表示同一个Zq在不同尺度特征图的位置,利用坐标位置周围的点取插值得到不同特征图的同一个Zq。
整体流程
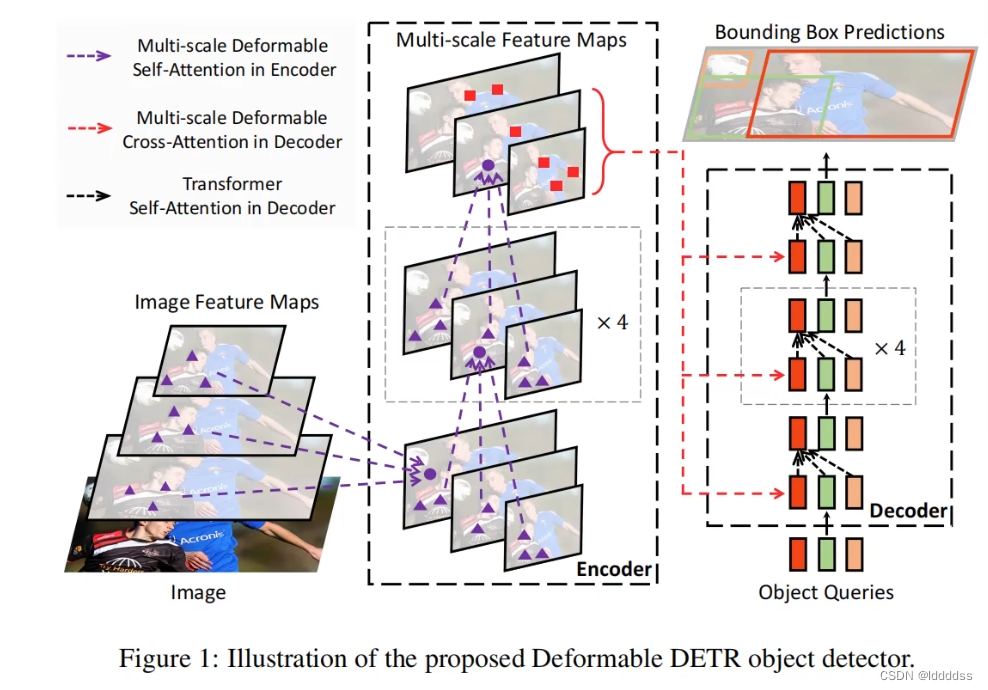
reference:
b站:目标检测算法还只会YOLO?Deformable DETR:超强的小目标检测神器,论文精读+源码复现,迪哥半天带你吃透DeformableDetr算法!_哔哩哔哩_bilibili















 557
557











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









