







目录
一.支持向量机内容
1.SVM简介
支持向量机(support vector machines, SVM)是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机;SVM还包括核技巧,这使它成为实质上的非线性分类器。SVM的的学习策略就是间隔最大化,可形式化为一个求解凸二次规划的问题,也等价于正则化的合页损失函数的最小化问题。SVM的的学习算法就是求解凸二次规划的最优化算法。
2.SVM原理
支持向量机(Support Vector Machine,简称SVM)是一种常用的机器学习算法,用于进行分类和回归分析。它的原理基于统计学习理论中的结构风险最小化思想。
SVM的主要思想是将数据映射到高维特征空间,在该空间中找到一个最优的超平面,将不同类别的样本分开。这个超平面被称为决策边界,它具有最大的间隔,能够最好地区分不同类别的样本。
SVM的工作原理可以概括为以下几个步骤:
-
数据预处理:首先对数据进行预处理,包括特征选择、特征缩放等操作,确保数据的可用性和一致性。
-
特征映射:将数据映射到高维特征空间。通过使用核函数(kernel function),可以避免实际进行高维空间的计算,而是通过在低维空间中计算核函数的值来实现。
-
寻找最优超平面:在特征空间中,寻找一个最优的超平面,使得不同类别的样本能够被最大间隔地分开。这个最优超平面由支持向量表示,支持向量是距离超平面最近的样本点。
-
分类与回归:将新的数据点投影到特征空间中,通过判断其位于哪一侧来进行分类或回归预测。
3.SVM具有以下优点
- 在高维特征空间中进行计算,能够更好地处理线性和非线性可分问题。
- 通过最大间隔原则,具有较好的鲁棒性和泛化能力。
- 可以通过选择不同的核函数适应不同的数据类型。
二.SVM大纲
1.最大间隔与分类
· 线性模型:
在样本空间中寻找一个超平面, 将不同类别的样本分开
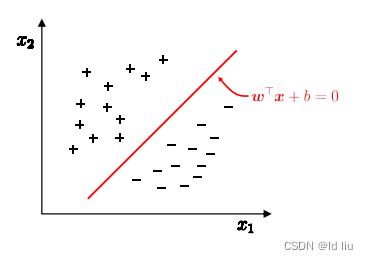
问题
:将训练样本分开的超平面可能有很多, 哪一个好呢?
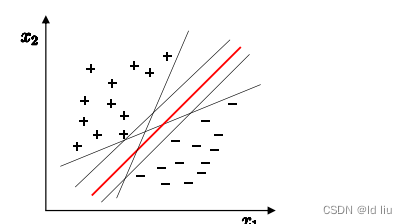
很明显,中间红色的直线效果最好:
容忍性好, 鲁棒性高, 泛化能力最强.
· 拓展多维平面
那么如何得到最大化间隔呢?
超平面方程:
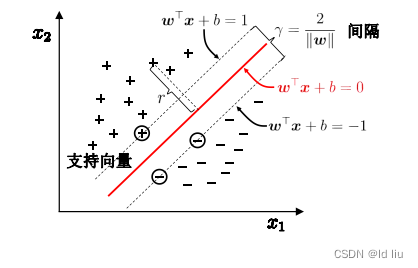
最大化间隔
:
寻找参数
w
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









