






一.理解决策树
1.决策树简介
决策树是一种树形结构,其中每个内部节点(Internal Node)表示一个特征(Feature),每个分支(Branch)表示一个特征取值的判断条件,而每个叶子节点(Leaf Node)表示一个类别(Classification)或者一个数值(Regression)。通过对特征的逐层划分,决策树可以对数据进行分类或者预测
- “内部结点”:有根结点和中间结点,某个属性上的测试(test),这里的test是针对属性进行判断
- 分支:该测试的可能结果,属性有多少个取值,就有多少个分支
- “叶节点”:预测结果
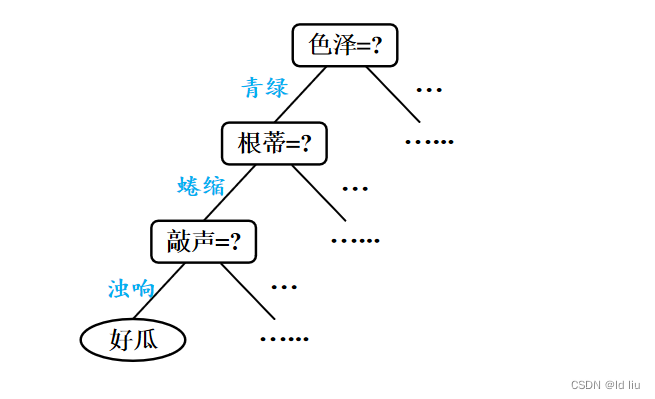
基于西瓜分类决策树
2.构建决策树基本流程
构建决策树的过程可以概括为以下四个步骤:
1.特征选择
从所有特征中选择一个最优特征进行划分。常见的特征选择标准有信息增益(Information Gain)、信息增益比(Gain Ratio)、基尼指数(Gini Index)等。
2.决策树生成
根据选择的特征,将数据集划分为若干个子集。为每个子集生成对应的子节点,并将这些子节点作为当前节点的分支。对每个子节点,重复第1步和第2步,直到满足停止条件。
3.停止条件
当满足以下任一条件时,停止决策树的生成:
- 所有特征已经被用于划分;
- 所有子集中的样本都属于同一类别;
- 子集中样本数量不足以继续划分。
4.剪枝:为了避免过拟合(Overfitting),可以对生成的决策树进行剪枝。常见的剪枝方法有预剪枝(Pre-pruning)和后剪枝(Post-pruning)。
3.决策树的属性划分
经典的属性划分方法:
信息增益: ID 3 增益率:C 4.5 基尼指数:CART
这里涉及到重要概念信息熵与信息增益:
1.信息熵
其中这个“熵”(entropy)是指对复杂系统的刻画,可以理解为系统由不稳定态到稳定态所需要丢失的部分,信息熵可以理解为信息由不干净到干净所需要丢失的部分。信息熵满足公式
Ent(D)=-
2.信息增益
信息增益=划分之前的信息熵-划分之后的信息熵(一般来说,信息增益越大,作为我们分类依据效果越好)
![]()
4.剪枝
为什么剪枝:
“剪枝”是决策树学习算法对付“过拟合”的主要手段 可通过“剪枝”来一定程度避免因决策分支过多,以致于把训练集自身的一些特点当做所有数据都具有的一般性质而导致的过拟
剪枝的两种思路:
- 预剪枝(pre-pruning):提前终止某些分支的生长
- 后剪枝(post-pruning):生成一颗完整树,再回头从下往上“修剪”
二.构建决策树
1.创建数据集
我在官网下载了泰坦尼克号幸存者的数据集,用于构建决策树,下面我将展示部分数据集的内容:
# 导入所需的库和数据集
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix
titanic_data = pd.read_csv('titanic.csv')
titanic_data = pd.read_csv('titanic.csv')
# 显示前20行数据
print(titanic_data.head(20))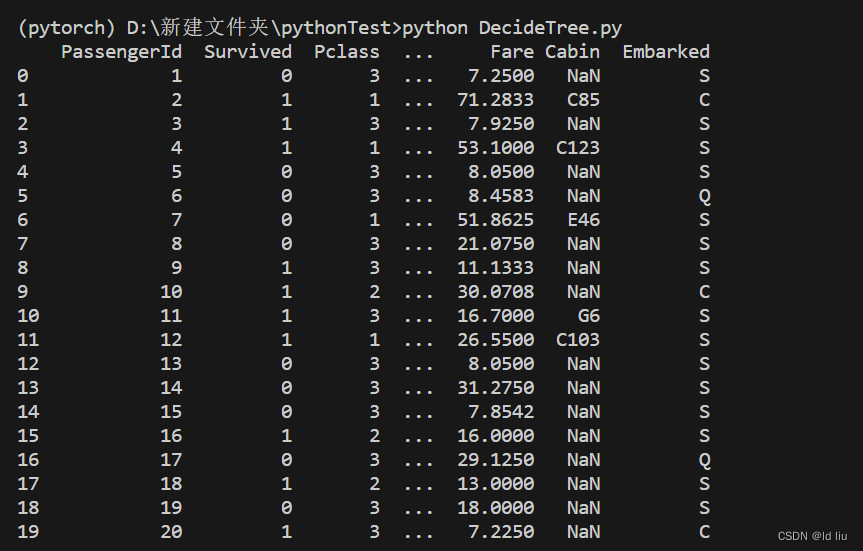
2.完整模型代码
# 导入所需的库和数据集
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix
titanic_data = pd.read_csv('titanic.csv')
# 预处理数据
titanic_data.drop(['Name', 'Ticket', 'Cabin'], axis=1, inplace=True)
titanic_data.fillna({'Age': titanic_data.Age.median()}, inplace=True)
titanic_data = pd.get_dummies(titanic_data)
# 定义特征和目标变量
X = titanic_data.drop(['Survived'], axis=1)
y = titanic_data['Survived']
# 划分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建决策树分类器并在训练集上拟合模型
clf = DecisionTreeClassifier(max_depth=3)
clf.fit(X_train, y_train)
# 在测试集上进行预测,并计算准确率和混淆矩阵
y_pred = clf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
confusion = confusion_matrix(y_test, y_pred)
# 打印结果
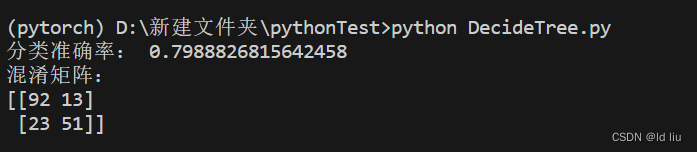
print("分类准确率:", accuracy)
print("混淆矩阵:")
print(confusion)最终结果:
-
导入所需的库和数据集:导入
pandas库用于数据处理,导入DecisionTreeClassifier类用于构建决策树模型,导入train_test_split函数用于划分数据集,导入accuracy_score和confusion_matrix函数用于计算准确率和混淆矩阵。同时,使用pd.read_csv()函数加载titanic.csv数据集。 -
预处理数据:使用
drop()函数删除Name、Ticket和Cabin列,因为这些特征对于分类预测可能没有显著影响。然后,使用fillna()函数将Age列的缺失值用中位数进行填充。最后,使用pd.get_dummies()函数将分类变量转换为虚拟变量。 -
定义特征和目标变量:将数据集中的特征列赋值给
X,将Survived列作为目标变量赋值给y。 -
划分数据集:使用
train_test_split()函数将数据集划分为训练集和测试集,其中测试集占总数据集的20%。 -
创建决策树分类器并拟合模型:使用
DecisionTreeClassifier()创建一个最大深度为3的决策树分类器,然后使用fit()函数在训练集上拟合模型。 -
进行预测并计算准确率和混淆矩阵:使用训练好的模型对测试集进行预测,然后使用
accuracy_score()函数计算准确率,使用confusion_matrix()函数计算混淆矩阵。 -
打印结果:输出分类准确率和混淆矩阵。
三.小结
本次实验是使用决策树模型对泰坦尼克号数据集进行分类预测,通过对数据集的预处理、训练集和测试集的划分以及模型的训练和评估,得出了模型在测试集上的准确率和混淆矩阵。决策树是一种简单易懂、可解释性强的分类算法,适用于处理中小规模、具有离散特征的数据集。在实际应用中,我们需要根据具体情况选择合适的模型和算法,并进行模型调优和性能评估,以达到更好的预测效果。















 3025
3025











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









