









前言
本文参考源码版本为
redis6.2
哨兵是啥?站岗、放哨、巡逻之人,这种模式在生活中也十分常见,军队、安保、押运等等,都需要时刻注意周边异样,并及时作出响应。
redis 哨兵也是如此。前面文章我们分析了 redis 副本机制,本质就是多个数据副本,为防止单副本故障而生。
在 redis 服务遇到故障崩溃时,我们可以通过切换副本节点对外提供服务,你可以写一些脚本,做到一键切换,十分方便;前提是,需要人为判断是否需要故障切换,在工作时间遇到可能还能忍受,要是凌晨两三点呢?
所以,我们可以选择更加智能一些,比如,你想继续写一个自动检测故障的脚本,当检查到 redis 故障时,直接切换从节点顶上就OK了;没错,思路是这样,不过,路子有点野。
有广大需求,肯定就会有人身先士卒,把它做成工具,然后你直接拿来用即可。本文的主角,redis 哨兵就登场了。
redis 哨兵,本质没有多神秘,按照上面思路,你我也能搞一套,关键是你需要花一些精力,还要不断验证它的鲁棒性,如果你还觉得OK,那可以试试咯。
好,回到正题,我们来聊聊 redis 哨兵,要做到自动切换,需要做哪些操作?
- 首先,需要探测到主从节点是否正常?redis 采用定期 PING 的方式。
- 当主节点故障,我们将从在线的从节点列表选择一个提升为主节点。
- 然后通知其他从节点,主节点已更新,需要连接到新主节点。
- 同时,我们还需要继续监听旧主节点,当其重新上线时,将其降级为从节点。
流程上是这样,不过还有些问题需要考虑。比如主节点实际正常在线,只不过主从节点间的网络出了问题,导致从节点一直无法 PING 通,导致从节点误判了?
为了避免单哨兵误判的情况出现,redis 提供了多哨兵支持,只要半数以上的哨兵节点都认为主节点下线了,才真正认为主节点下线,然后准备故障转移。
值得注意的是,在故障转移之前,我们需要先选择一个哨兵节点来完成这个工作。
一、快速开始
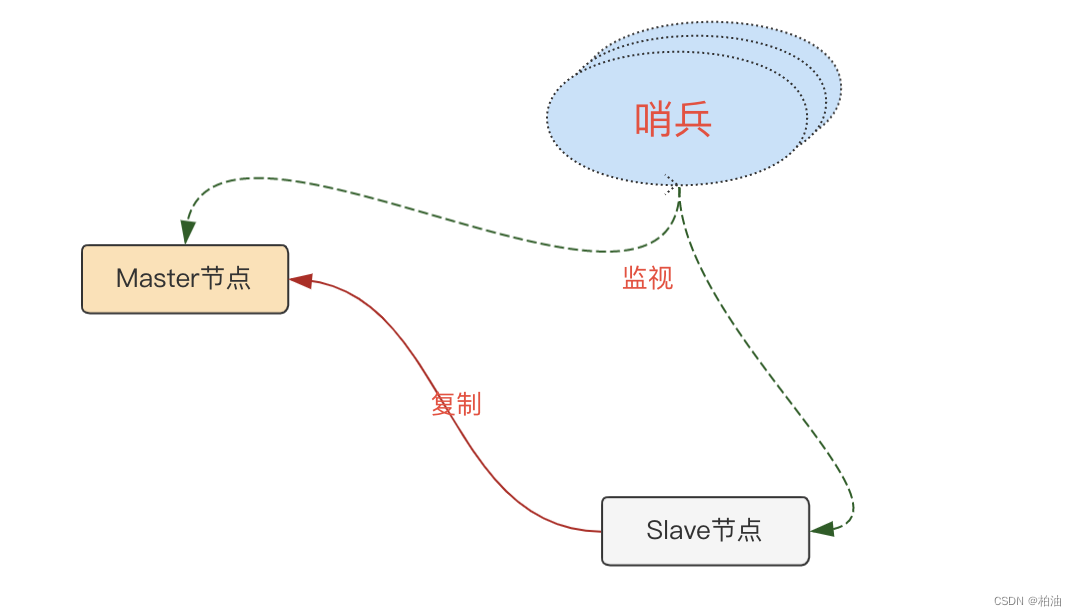
哨兵,本质也是一个 redis 服务,其启动方式都相似。我们先快速搭建 3 哨兵 + 1主 + 1从的集群来看看:
1.配置
首先从官网下载 redis,主节点使用默认配置,从节点则 copy 默认配置并修改端口为 6378,配置文件命名为 redis_6378.conf。
然后配置三个哨兵,配置文件分别命名为 sentinel.conf、sentinel2.conf、sentinel3.conf,其中 sentinel.conf 配置如下:
port 26379
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 60000
sentinel parallel-syncs mymaster 1
另外哨兵的配置文件也类似,端口分别定义为 26380、26381。以上配置中, quorum = 2。
2.启动
首先,启动主节点:
然后启动从节点:
最后启动3个哨兵节点,在命令行分别执行:
➜ redis-sentinel sentinel.conf
➜ redis-sentinel sentinel2.conf
➜ redis-sentinel sentinel3.conf
效果如下:
我们通过命令 ps -ef | grep redis 来查看启动状态:

可以发现所有服务都已启动,我们随意进入一个哨兵节点,查看监控效果:
➜ ~ redis-cli -p 26379
127.0.0.1:26379> SENTINEL master mymaster
1) "name"
2) "mymaster"
3) "ip"
4) "127.0.0.1"
5) "port"
6) "6379"
7) "runid"
8) "a749c4af7998c2330d0e31cc596b571b7d46d4d8"
9) "flags"
10) "master"
11) "link-pending-commands"
12) "0"
13) "link-refcount"
14) "1"
15) "last-ping-sent"
16) "0"
17) "last-ok-ping-reply"
18) "739"
19) "last-ping-reply"
20) "739"
21) "down-after-milliseconds"
22) "60000"
23) "info-refresh"
24) "8197"
25) "role-reported"
26) "master"
27) "role-reported-time"
28) "299300"
29) "config-epoch"
30) "5"
31) "num-slaves"
32) "1"
33) "num-other-sentinels"
34) "3"
35) "quorum"
36) "2"
37) "failover-timeout"
38) "180000"
39) "parallel-syncs"
40) "1"
以上可以看到主节点信息。另外,你可以通过命令:
SENTINEL replicas mymaster
SENTINEL sentinels mymaster
分别查看 从节点信息、其他哨兵信息等。
3.故障转移
模拟主节点故障,命令行输入:
➜ ~ redis-cli -p 6379 DEBUG sleep 70
OK
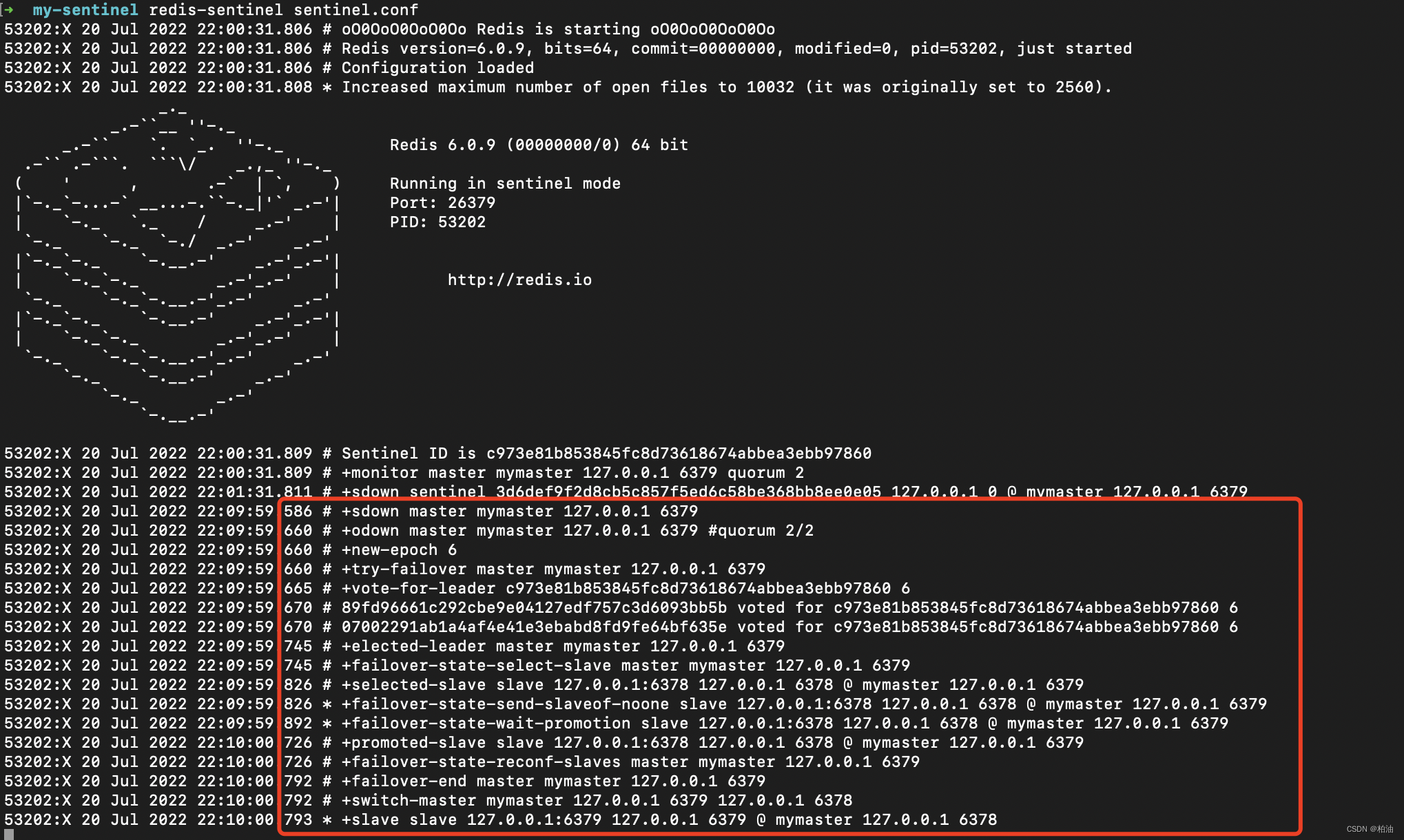
通过上图,我们可以看到完整的故障转移过程。另外,上图也是被选举为哨兵leader 的节点。
然后我们查看主节点信息是否切换:
➜ ~ redis-cli -p 26379
127.0.0.1:26379> SENTINEL master mymaster
1) "name"
2) "mymaster"
3) "ip"
4) "127.0.0.1"
5) "port"
6) "6378"
7) "runid"
8) "2ae9dd98368bcc17c3b679f424a716a84f62bfb5"
9) "flags"
10) "master"
11) "link-pending-commands"
可以发现主节点已经变成了 127.0.0.1:6378,即 已经完成了切换。
二、原理
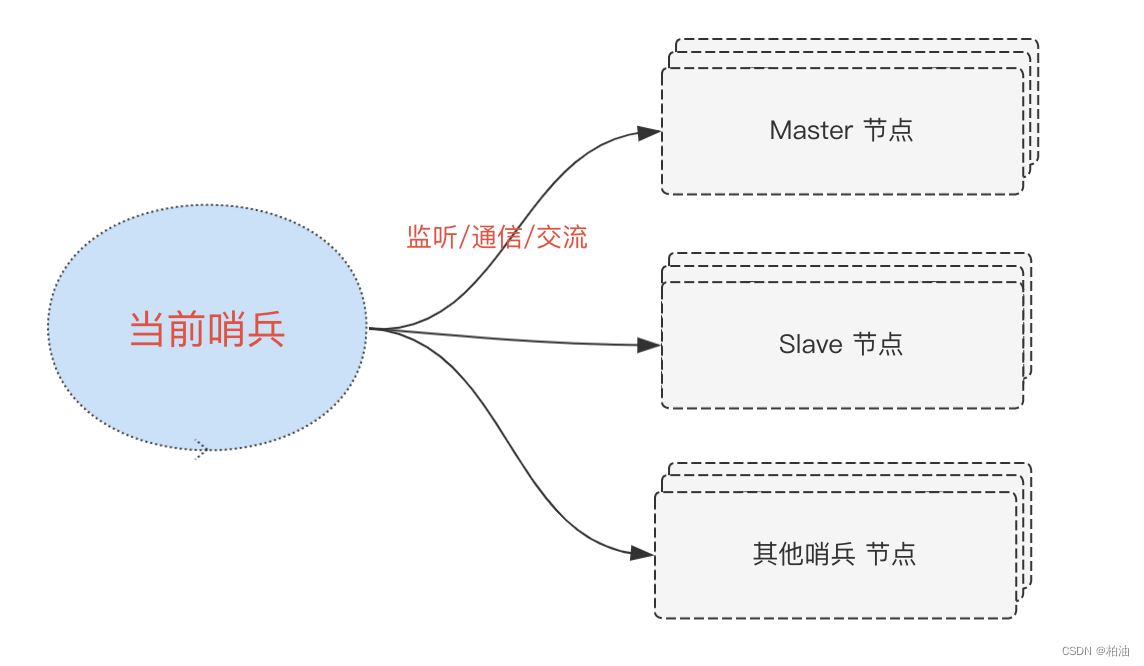
我们先来看看,redis 哨兵主要做了哪些工作?在此之前,先看看它会监听哪些节点:
首先,哨兵的主要职责是保障 redis 服务能正常对外提供服务。因此,肯定是要监听 redis 主节点的在线状态。
其次,当主节点挂掉之后,需要进行故障转移,也就是需要知道所有从节点的信息。因此,哨兵的第二项职责便是监听从节点的状态。
另外,前面部分提到,单哨兵可能并不是那么健壮,我们一般需要搞一个哨兵集群。因此,第三项职责便是哨兵节点间的沟通交流。
简单来说,我们从一个哨兵的角度来看,其会保持与下面三类节点的交流,如下图:
当然,监听节点的目的是为了获取信息,对这些信息进一步处理并采取相应的行动才是目的:
- 哨兵集群信息沟通交流
- master 节点下线判断
- 哨兵集群 leader 选举
- 哨兵 leader 执行故障转移
- 通知客户端,master - slave 变更信息
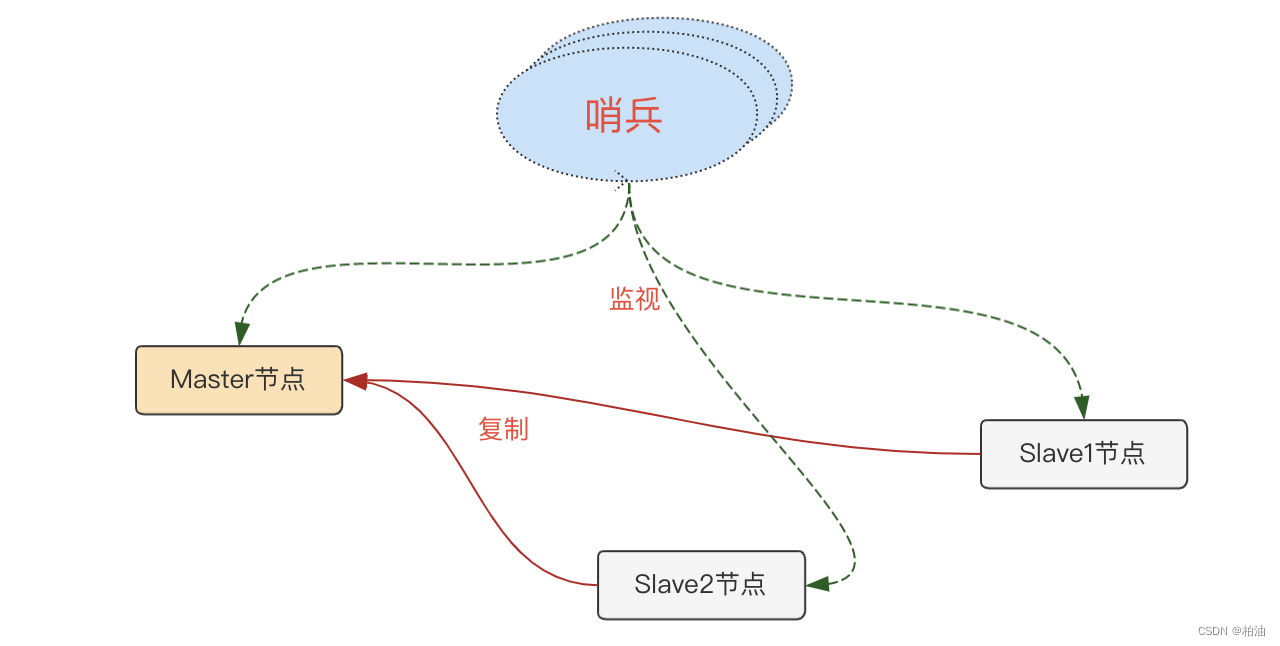
正常监听是这样:
当 master 节点出现故障,哨兵集群执行故障转移后,变成了这样:
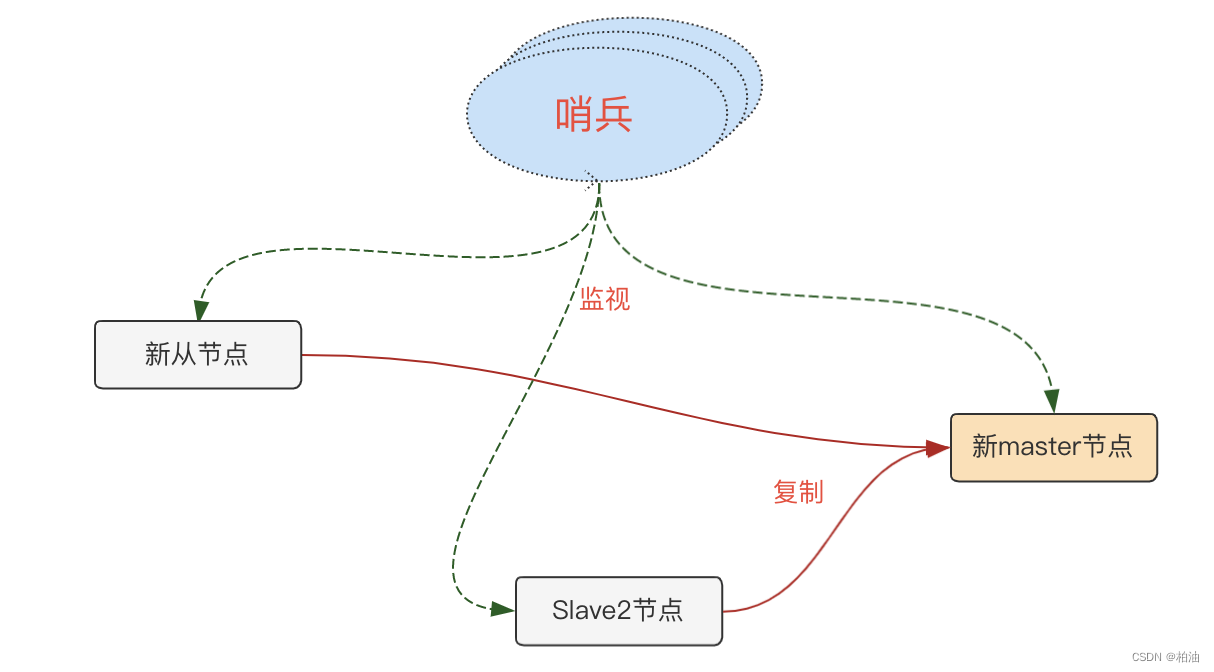
值得注意的是,原 master 节点下线后,哨兵也会持续监听,当其重新上线后,将其处理为新的从节点。
1.主流程
1.1 哨兵工作入口:
哨兵工作的主要工作在前面部分基本已经介绍过了,接下来我们继续看看这些工作是如何串联起里的。
入口方法:server.c#serverCron 中 的 sentinelTimer 方法。我们来看看哨兵相关主干逻辑:
// sentinel.c#sentinelHandleRedisInstance()
void sentinelHandleRedisInstance(sentinelRedisInstance *ri) {
// 主要维护与 master、slave 以及其他 sentinel 之间的连接信息
sentinelReconnectInstance(ri);
// 周期性操作:PING、INFO 以及 PUBLISH
sentinelSendPeriodicCommands(ri);
...
// 哨兵主观下线判断
sentinelCheckSubjectivelyDown(ri);
/* Masters and slaves */
if (ri->flags & (SRI_MASTER|SRI_SLAVE)) {
/* Nothing so far. */
}
/* Only masters */
// 如果维护的是与master节点的连接
if (ri->flags & SRI_MASTER) {
// 哨兵进行客观下线判断
sentinelCheckObjectivelyDown(ri);
// 是否需要故障转移
if (sentinelStartFailoverIfNeeded(ri))
// 尝试选出哨兵leader
sentinelAskMasterStateToOtherSentinels(ri,SENTINEL_ASK_FORCED);
// 哨兵故障转移状态机(执行故障转移)
sentinelFailoverStateMachine(ri);
// 故障转移完成后,做一些清理操作
sentinelAskMasterStateToOtherSentinels(ri,SENTINEL_NO_FLAGS);
}
}
可以看到 redis 哨兵主干逻辑在处理:
- 与其他节点维护连接信息
- 与其他节点保持连接信息(PING)
- 哨兵主观下线判断
如果监控的是主节点,那将进一步处理:
- 哨兵客观下线判断
- 是否需要故障转移,如果需要,则选出哨兵 leader,由 leader 来完成故障转移
- 哨兵 leader 执行故障转移,这个过程有多阶段,这里使用状态机来处理。
- 故障转移之后,做一些清理工作(比如 flag)
值得注意的是,当前哨兵监听的所有节点,都会执行 sentinelCheckSubjectivelyDown 方法,也就是主观判断节点是否下线,如果下线了就更新 flag。
1.2 任督二脉
哨兵,本质也是一个 redis 服务,既能接收请求又能定期监视相关节点,这是如何做到的?
我们知道,事件是贯穿 redis 的核心机制,客户端发来的请求封装为文件事件,另外还有一些后台周期性的任务封装为时间事件。
哨兵的工作过程号称是异步的,比如发出 PING 之后不需要等待响应,而是当响应到来时,通过回调函数来继续处理。哨兵的异步操作是如何实现的?
哨兵在启动时会创建相关连接,并将对应已连接的 fd 向操作系统内核注册,当有请求到来时,和一般的 redis 请求类似,服务正常处理请求即可。
在哨兵主动发起通信时,主要借助于客户端工具 hiredis,其封装了 RESP 通信协议,发送请求时,这个过程不必等待结果返回,因此,异步体现在这里。
我画了张图,大概是这样:
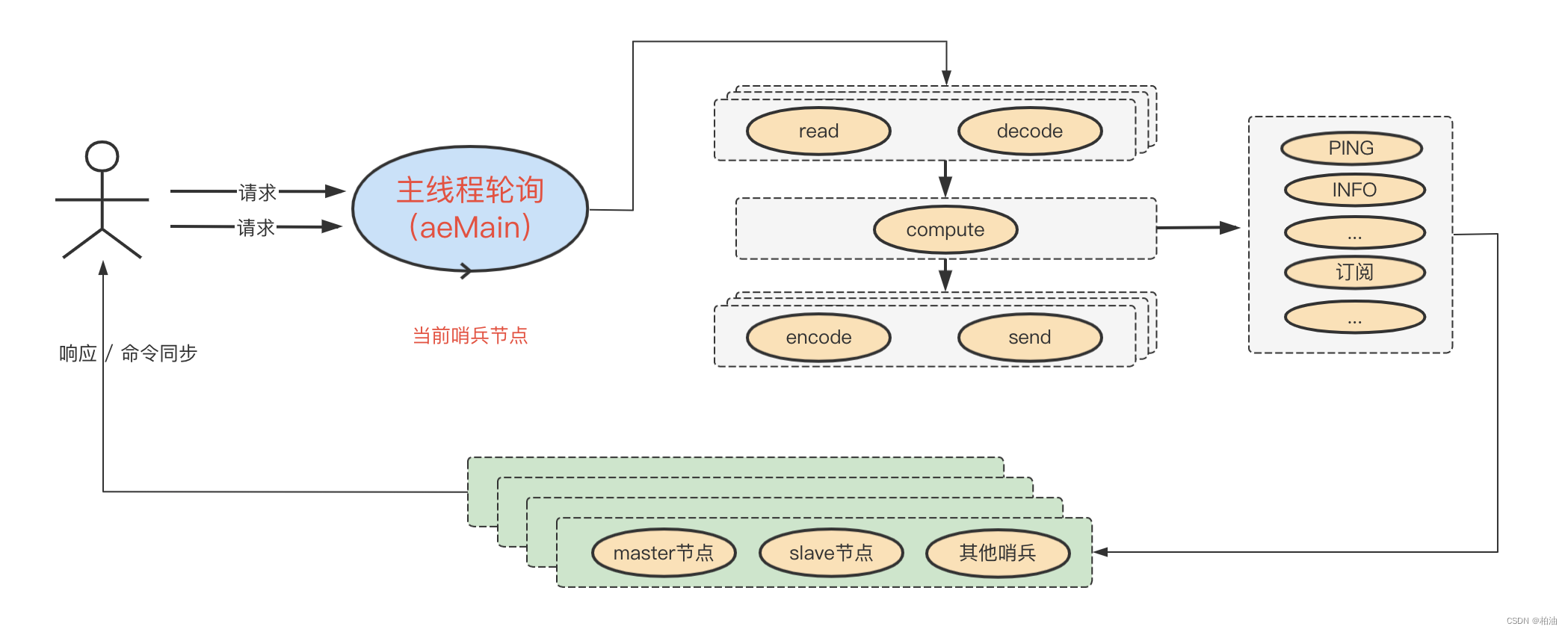
值得注意的是,redis 哨兵的异步过程是与主线程轮训(事件)紧密相连。
2.监视
俗话说,一个人的判断具有具有主观色彩,三人成众,便是代表了大众;redis 哨兵集群也是如此,通过全员投票模式,半数以上哨兵认为主节点下线了,就代表了大众,可以执行故障转移。
2.1 主观下线
从单个哨兵节点的角度来看,当其对 master 节点进行单方面的检测发现已经离线了,有主观性质在里面,也叫主观下线。
主观下线条件:
- PING 相关:指定参数 down-after-milliseconds 时长没有正常响应则视为下线
- INFO 相关:从 master 角色切换到 slave 角色也认为是下线
主观下线相关逻辑:
void sentinelCheckSubjectivelyDown(sentinelRedisInstance *ri) {
...
/* Update the SDOWN flag. We believe the instance is SDOWN if:
*
* 1) It is not replying.
* 2) We believe it is a master, it reports to be a slave for enough time
* to meet the down_after_period, plus enough time to get two times
* INFO report from the instance. */
if (elapsed > ri->down_after_period ||
(ri->flags & SRI_MASTER &&
ri->role_reported == SRI_SLAVE &&
mstime() - ri->role_reported_time >
(ri->down_after_period+SENTINEL_INFO_PERIOD*2)))
{
/* Is subjectively down */
if ((ri->flags & SRI_S_DOWN) == 0) {
sentinelEvent(LL_WARNING,"+sdown",ri,"%@");
ri->s_down_since_time = mstime();
ri->flags |= SRI_S_DOWN;
}
}
...
}
2.2 客观下线
当我们需要判断主节点是否真正下线时,是需要做到尽可能公平公正的判断。这时候,群众投票,就是不错的选择,这种方式便是客观下线的判断依据。
redis 提供了变量 quorum 来控制,quorum 有两层含义:
- 客观下线判断条件:只有哨兵主观下线 >= quorum 才认为客观下线
- 哨兵 leader 选举:投票半数以上 + 大于等于 quorum 两个条件
客观下线相关逻辑:
void sentinelCheckObjectivelyDown(sentinelRedisInstance *master) {
...
if (master->flags & SRI_S_DOWN) {
quorum = 1; /* the current sentinel. */
/* Count all the other sentinels. */
di = dictGetIterator(master->sentinels);
while((de = dictNext(di)) != NULL) {
sentinelRedisInstance *ri = dictGetVal(de);
if (ri->flags & SRI_MASTER_DOWN) quorum++;
}
dictReleaseIterator(di);
// 如果大于指定参数,则客观下线
if (quorum >= master->quorum) odown = 1;
}
...
}
哨兵 leader 选举相关逻辑:
char *sentinelGetLeader(sentinelRedisInstance *master, uint64_t epoch) {
...
/* Check what's the winner. For the winner to win, it needs two conditions:
* 1) Absolute majority between voters (50% + 1).
* 2) And anyway at least master->quorum votes. */
di = dictGetIterator(counters);
while((de = dictNext(di)) != NULL) {
uint64_t votes = dictGetUnsignedIntegerVal(de);
if (votes > max_votes) {
max_votes = votes;
winner = dictGetKey(de);
}
}
dictReleaseIterator(di);
/* Count this Sentinel vote:
* if this Sentinel did not voted yet, either vote for the most
* common voted sentinel, or for itself if no vote exists at all. */
if (winner)
myvote = sentinelVoteLeader(master,epoch,winner,&leader_epoch);
else
myvote = sentinelVoteLeader(master,epoch,sentinel.myid,&leader_epoch);
if (myvote && leader_epoch == epoch) {
uint64_t votes = sentinelLeaderIncr(counters,myvote);
if (votes > max_votes) {
max_votes = votes;
winner = myvote;
}
}
voters_quorum = voters/2+1;
if (winner && (max_votes < voters_quorum || max_votes < master->quorum))
winner = NULL;
...
}
综上,客观下线判断、哨兵 leader 选举都与 quorum 参数有关,因此,设置合适的 quorum 参数十分重要;
另外哨兵 leader 选举还有半数以上哨兵投票的限制,因此通常采用奇数个哨兵节点比较合理。
3.哨兵Leader
哨兵集群一般包含多个,而执行故障转移这个过程只需一个哨兵节点即可,那究竟由谁来真正执行故障转移?
redis 采用的是投票的方式,在主节点进入客观下线状后,哨兵会向哨兵集群其他节点发送以下命令来赢得投票:
SENTINEL IS-MASTER-DOWN-BY-ADDR <ip> <port> <current-epoch> <runid>
哨兵接收请求入口:sentinel.c#sentinelCommand(),然后具体哨兵 leader 选举逻辑可以定位到:
// sentinel.c#sentinelVoteLeader()
char *sentinelVoteLeader(sentinelRedisInstance *master, uint64_t req_epoch, char *req_runid, uint64_t *leader_epoch) {
if (req_epoch > sentinel.current_epoch) {
sentinel.current_epoch = req_epoch;
sentinelFlushConfig();
sentinelEvent(LL_WARNING,"+new-epoch",master,"%llu",
(unsigned long long) sentinel.current_epoch);
}
if (master->leader_epoch < req_epoch && sentinel.current_epoch <= req_epoch)
{
sdsfree(master->leader);
master->leader = sdsnew(req_runid);
master->leader_epoch = sentinel.current_epoch;
sentinelFlushConfig();
sentinelEvent(LL_WARNING,"+vote-for-leader",master,"%s %llu",
master->leader, (unsigned long long) master->leader_epoch);
/* If we did not voted for ourselves, set the master failover start
* time to now, in order to force a delay before we can start a
* failover for the same master. */
if (strcasecmp(master->leader,sentinel.myid))
master->failover_start_time = mstime()+rand()%SENTINEL_MAX_DESYNC;
}
*leader_epoch = master->leader_epoch;
return master->leader ? sdsnew(master->leader) : NULL;
}
首先,所有在线的 Sentinel 都有被选为哨兵 leader 的资格。
其次,每次进行哨兵 leader 选举之后,不论选举是否成功,所有 Sentinel 的配置纪元(epoch)的值都会自增一次。配置纪元实际上就是一个计数器,并没有什么特别的。
在一个配置纪元里面,所有 Sentinel 都有一次将某个 Sentinel 设置为局部哨兵 leader 的机会,并且局部 leader 一旦设置,在这个配置纪元里面就不能再更改。
每个发现主服务器进入客观下线的 Sentinel 都会要求其 他Sentinel 将自己设置为局部哨兵 leader。
当主节点客观下线后,哨兵 leader 选举规则如下:
- 当一个Sentinel(源Sentinel)向另一个 Sentinel(目标Sentinel)发送 SENTINEL is-master-down-by-addr 命令,并且命令中的 runid 参数不是 * 符号而是源 Sentinel 的运行ID时,这表示源 Sentinel 要求目标 Sentinel 将前者设置为后者的
局部哨兵 leader。 - Sentinel 设置局部哨兵 leader 的规则是
先到先得:最先向目标 Sentinel 发送设置要求的源Sentinel 将成为目标 Sentinel 的局部哨兵 leader,而之后接收到的所有设置要求都会被目标Sentinel 拒绝。 - 目标 Sentinel 在接收到 SENTINEL is-master-down-by-addr 命令之后,将向源 Sentinel 返回一条命令回复,回复中的 leader_runid 参数和 leader_epoch 参数分别记录了目标 Sentinel 的局部哨兵 leader 的运行 ID 和配置纪元。
- 源 Sentinel 在接收到目标 Sentinel 返回的命令回复之后,会检查回复中 leader_epoch 参数的值和自己的配置纪元是否相同,如果相同的话,那么源 Sentinel 继续取出回复中的 leader_runid 参数,如果 leader_runid 参数的值和源 Sentinel 的运行 ID 一致,那么表示目标Sentinel 将源 Sentinel 设置成了局部哨兵 leader。
- 如果有某个 Sentinel 被半数以上的 Sentinel 设置成了局部哨兵 leader,那么这个 Sentinel 成为哨兵 leader。
- 因为哨兵 leader 的产生需要半数以上 Sentinel 的支持,并且每个 Sentinel 在每个配置纪元里面只能设置一次局部哨兵 leader,所以在一个配置纪元里面,只会出现唯一的哨兵 leader。
- 如果在给定时限内,没有一个 Sentinel 被选举为哨兵 leader,那么各个 Sentinel 将在一段时间之后再次进行选举,直到选出领头 Sentinel 为止。
4.故障转移
故障转移本质要做的是,在从节点列表中选择一个作为新的主节点,并通知其他从节点、客户端等。
故障转移通过状态机的形式呈现,大致做了这些事情:
// sentinel.c#sentinelFailoverStateMachine()
void sentinelFailoverStateMachine(sentinelRedisInstance *ri) {
serverAssert(ri->flags & SRI_MASTER);
if (!(ri->flags & SRI_FAILOVER_IN_PROGRESS)) return;
switch(ri->failover_state) {
case SENTINEL_FAILOVER_STATE_WAIT_START:
sentinelFailoverWaitStart(ri);
break;
case SENTINEL_FAILOVER_STATE_SELECT_SLAVE: // 执行新主节点选举
sentinelFailoverSelectSlave(ri);
break;
case SENTINEL_FAILOVER_STATE_SEND_SLAVEOF_NOONE:
sentinelFailoverSendSlaveOfNoOne(ri);
break;
case SENTINEL_FAILOVER_STATE_WAIT_PROMOTION:
sentinelFailoverWaitPromotion(ri);
break;
case SENTINEL_FAILOVER_STATE_RECONF_SLAVES:
sentinelFailoverReconfNextSlave(ri);
break;
}
}
我们挑个重点的来看看,通常情况下,从节点有多个,我们改选择哪个来作为新的主节点呢?看看选举主节点的总体逻辑:
sentinelRedisInstance *sentinelSelectSlave(sentinelRedisInstance *master) {
...
di = dictGetIterator(master->slaves);
while((de = dictNext(di)) != NULL) {
sentinelRedisInstance *slave = dictGetVal(de);
mstime_t info_validity_time;
if (slave->flags & (SRI_S_DOWN|SRI_O_DOWN)) continue;
if (slave->link->disconnected) continue;
if (mstime() - slave->link->last_avail_time > SENTINEL_PING_PERIOD*5) continue;
if (slave->slave_priority == 0) continue;
/* If the master is in SDOWN state we get INFO for slaves every second.
* Otherwise we get it with the usual period so we need to account for
* a larger delay. */
if (master->flags & SRI_S_DOWN)
info_validity_time = SENTINEL_PING_PERIOD*5;
else
info_validity_time = SENTINEL_INFO_PERIOD*3;
if (mstime() - slave->info_refresh > info_validity_time) continue;
if (slave->master_link_down_time > max_master_down_time) continue;
instance[instances++] = slave;
}
dictReleaseIterator(di);
if (instances) {
qsort(instance,instances,sizeof(sentinelRedisInstance*),
compareSlavesForPromotion);
selected = instance[0];
}
zfree(instance);
return selected;
}
总结下新主节点选举规则如下:
- 删除列表中所有处于下线或者断线状态的从服务器,这可以保证列表中剩余的从服务器都是正常在线的。
- 删除列表中所有最近五秒内没有回复过哨兵 leader 的 INFO 命令的从服务器,这可以保证列表中剩余的从服务器都是最近成功进行过通信的。
- 删除所有与已下线主服务器连接断开超过down-after-milliseconds*10毫秒的从服务器。即,列表中剩余的从服务器保存的数据都是比较新的。
- 然后,哨兵 leader 将根据从服务器的优先级,对列表中剩余的从服务器进行排序,并选出其中优先级最高的从服务器。
- 如果有多个具有相同最高优先级的从服务器,那么哨兵 leader 将按照从服务器的复制偏移量,对具有相同最高优先级的所有从服务器进行排序,并选出其中偏移量最大的从服务器(复制偏移量最大的从服务器就是保存着最新数据的从服务器)。
- 最后,如果有多个优先级最高、复制偏移量最大的从服务器,那么领头Sentinel将按照运行ID对这些从服务器进行排序,并选出其中运行 ID 最小的从服务器。
当选择出新主节点之后,然后向其他从节点发送以下命令,即连接到新主节点:
SLAVEOF new_masertip new_master_port
总结
哨兵,主从集群的监护者,其核心目的是能自动完成故障转移。为防止单哨兵故障,一般选择使用哨兵集群,哨兵之间会自动发现对方。
从哨兵角度看,可以监视主节点、从节点,并且和其他哨兵节点保持通信。在监视过程中,单方面判断监视节点下线的叫主观下线,半数以上哨兵都认为下线的叫客观下线。
当主节点客观下线后,哨兵集群内部会协商选出一个哨兵 leader 来负责执行故障转移操作。当哨兵 leader 选出后,leader 便开始在从节点列表中选择一个合适的从节点作为新的主节点;然后将其他从节点关联到新的主节点。
另外,原主节点也要监视,当其重新上线时,会作为新主节点的从节点。
相关参考:
- redis 副本机制
- High availability with Redis Sentinel
- <<Redis 设计与实现>> 「黄健宏」
- <<Redis5 设计与源码分析>>「陈雷」
















 504
504











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











