







新版正方教务系统请点这里:模拟登陆新版正方教务管理系统(获取学籍信息、课表和成绩)
最近想学点爬虫玩玩,拿学校的教务系统练练手。学校与很多高校一样,用的是正方教务管理系统,非常的不好用,经常出现登陆不上去、卡死的情况,主页如下图所示:
主页地址:http://222.24.62.120
模拟登录
1. 分析登录的URL和所需提供的数据
我们输入学号、密码和验证码登录后,点击登录。这时浏览器会向服务器提交一个POST请求:
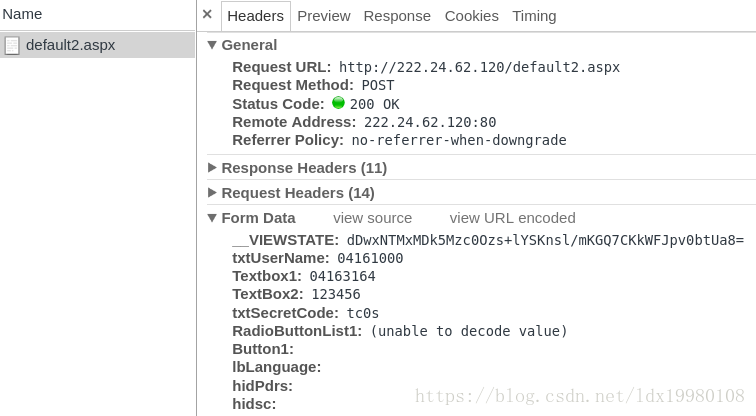
我们由上图中的数据可知,登录请求的URL地址为:
http://222.24.62.120/default2.aspx所提交的数据除了学号、密码、验证码、用户类型,还有其他的数据:
- __VIEWSTATE在源码中可以找到,是一个隐藏域,猜测是用来做验证
<input type="hidden" name="__VIEWSTATE" value="dDwxNTMxMDk5Mzc0Ozs+lYSKnsl/mKGQ7CKkWFJpv0btUa8=" />- Textbox1是上次登陆的用户学号
- RadioButtonList1通过看源码可知为%D1%A7%C9%FA,是”学生”经过URL编码(gb2312)后的字符串。
- 后四个为空可以不用管
创建一个类:ConnectJWGL
属性如下:
private String stuNum;
private String stuName;
private String __VIEWSTATE = "";
private Map<String,String> cookies = new HashMap<>();
private Connection connection;
private Connection.Response response;
private Document document;2. 获取Cookies和__VIEWSTATE
给主页发一个请求,然后将响应的Cookies保存下来。并在其中提取__VIEWSTATE的值。
在ConnectJWGL类中添加一个connectIndex方法
代码如下:
//接获取cookies和__VIEWSTATE
public void connectIndex(){
try{
//获取连接
connection = Jsoup.connect("http://222.24.62.120");
connection.header("User-Agent",// 配置模拟浏览器
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:29.0) Gecko/20100101 Firefox/29.0");
response = connection.timeout(3000).execute();
//保存Cookies
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1538
1538











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









