



从unsplash爬取图片,可以获取大量数据集。
官网链接:API Applications | Unsplash
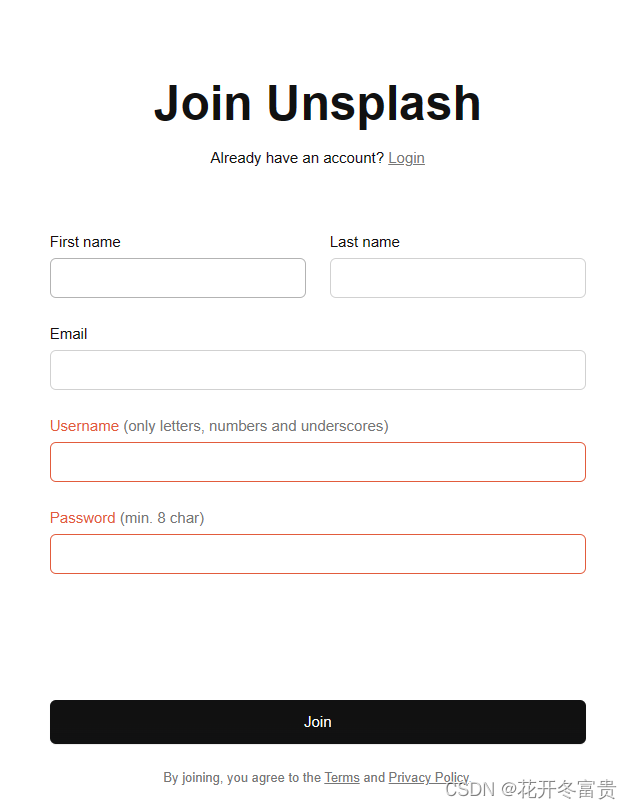
填写信息,进行注册
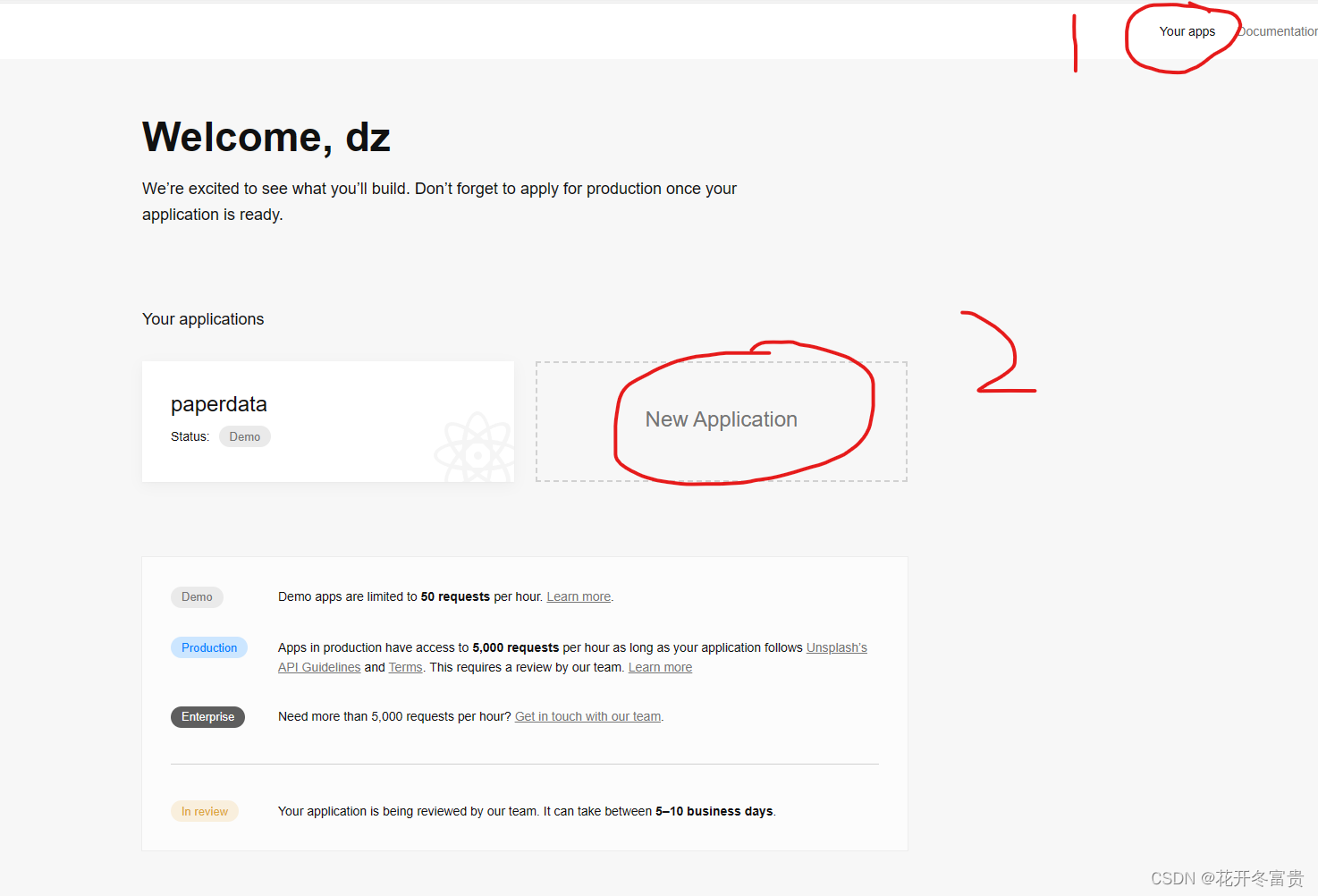
注册完成后-登录-创建项目,
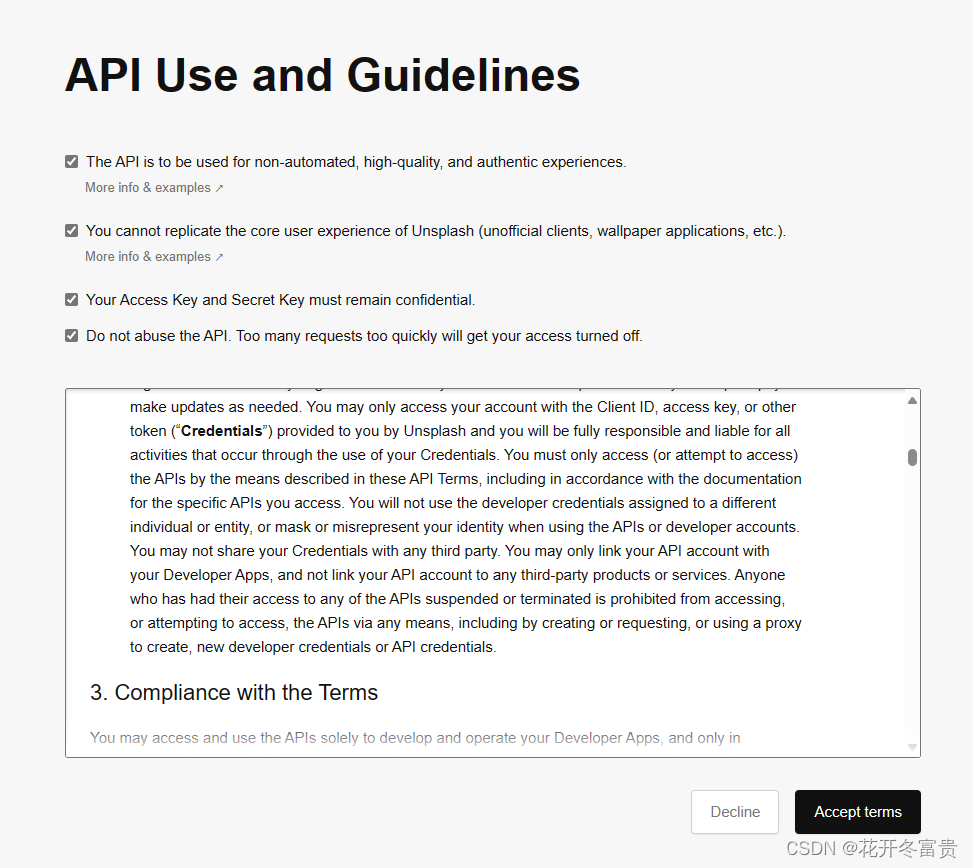
全部勾选-Accept terms
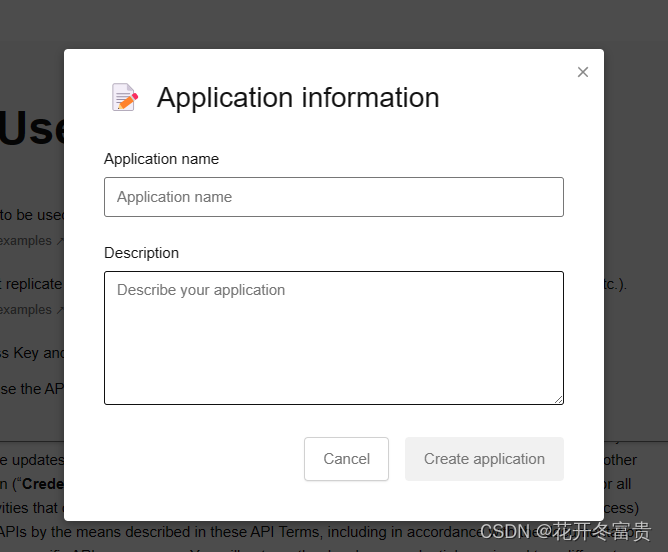
项目命名,填写Description
创建完成后,往下翻找到key密钥
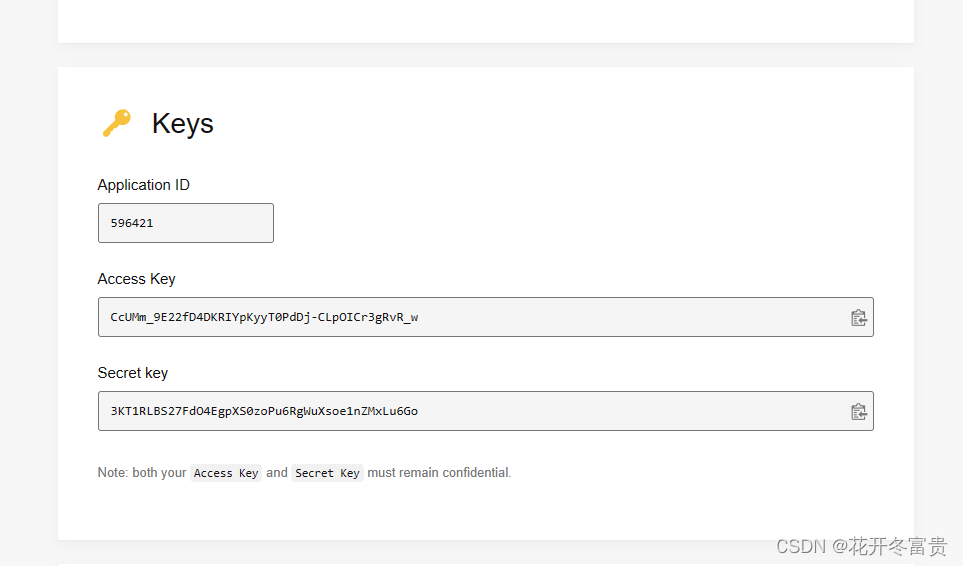
得到API key,修改下方代码即可
import requests
import os
import time
# 替换为你的 Unsplash Application ID
APPLICATION_ID = ""
# 替换为你的 Unsplash Access Key
ACCESS_KEY = ""
# 替换为你的 Unsplash Secret Key
SECRET_KEY = ""
# 设置要下载的类别和每个类别的图片数量
categories = {
"cat": 500,
"dog": 500,
"elephant": 500
}
# 获取访问令牌
def get_access_token():
url = "https://unsplash.com/oauth/token"
payload = {
"client_id": ACCESS_KEY,
"client_secret": SECRET_KEY,
"grant_type": "client_credentials"
}
response = requests.post(url, data=payload)
access_token = response.json()["access_token"]
return access_token
# 开始下载图片
def download_images():
access_token = get_access_token()
headers = {"Authorization": f"Bearer {access_token}"}
# 限制每小时的请求次数为 500 次
requests_per_hour_limit = 500
requests_count = 0
last_reset_time = time.time()
for category, total_images in categories.items():
# 创建类别文件夹
category_folder = f"images/{category}"
os.makedirs(category_folder, exist_ok=True)
per_page = min(30, total_images) # 每页最多30张图片
total_pages = (total_images - 1) // per_page + 1
for page in range(1, total_pages + 1):
# 检查是否达到了每小时的请求限制
current_time = time.time()
if current_time - last_reset_time >= 3600:
requests_count = 0
last_reset_time = current_time
# 如果已达到每小时请求限制,则等待一段时间
while requests_count >= requests_per_hour_limit:
time.sleep(60) # 每次等待一分钟
current_time = time.time()
if current_time - last_reset_time >= 3600:
requests_count = 0
last_reset_time = current_time
# 构建API请求的URL
url = f"https://api.unsplash.com/search/photos/?query={category}&per_page={per_page}&page={page}"
# 发送GET请求
response = requests.get(url, headers=headers)
requests_count += 1
# 检查响应状态码
if response.status_code == 200:
# 解析JSON响应
data = response.json()
# 提取图片下载链接并下载图片
for photo in data['results']:
image_url = photo['urls']['regular']
image_id = photo['id']
# 发送GET请求下载图片
img_data = requests.get(image_url).content
# 保存图片到本地
with open(f"{category_folder}/{image_id}.jpg", 'wb') as f:
f.write(img_data)
print(f"Downloaded {min(total_images, page * per_page)} {category} images")
else:
print(f"Error downloading {category} images:", response.status_code)
if __name__ == "__main__":
download_images()


















 1161
1161

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











