






 本文介绍了如何使用YOLov5进行图像自动标注,包括前期准备、模型训练、使用CUDA加速、追踪标注以及解决报错的方法。推荐了一个改进后的AutoLabelImg项目并提供了解决CPU环境下运行的提示。
本文介绍了如何使用YOLov5进行图像自动标注,包括前期准备、模型训练、使用CUDA加速、追踪标注以及解决报错的方法。推荐了一个改进后的AutoLabelImg项目并提供了解决CPU环境下运行的提示。
- 自动标注:基于yolov5的模型自动标注,将yolov5的检测结果转化为.xml标注文件
- 追踪标注:基于opencv的追踪模块实现的视频自动标注,标注开始的一帧,利用追踪预测后续的一段视频
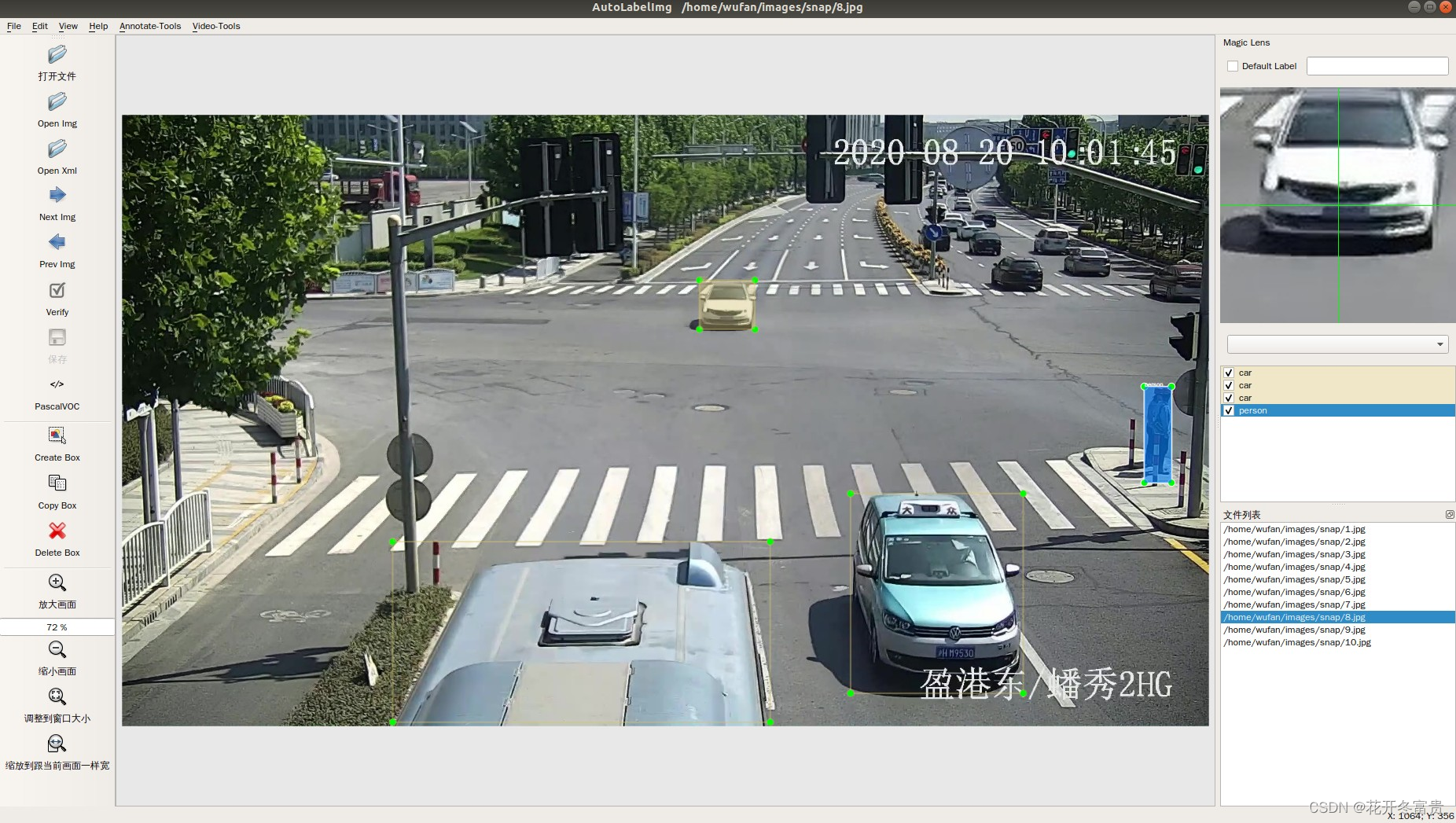
前期准备:先自己打个一百张左右,训练出来模型best.pt,在拿模型去自动打标签
可以使用cuda加速,也可以使用cpu。
原作者项目链接:GitHub - wufan-tb/AutoLabelImg: auto-labelimg based on yolov5, with many other useful tools
但不知道为什么我在使用的时候会出现报错。
所以我找到了另一个改进后的版本:GitHub - yuchen02/AutoLabelImg,建议使用该版本。
点进链接直接git clone或者下载zip压缩包后解压。
cd Autolabelimg #cd进入文件夹
conda create -n 环境名 python=3.7 #创建一个虚拟环境
conda activate 环境名
pip install -r requirements.txt #安装依赖
或
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple #使用清华源加速然后将训练好的yolov5模型best.pt放入 目录 pytorch_yolov5/weights/
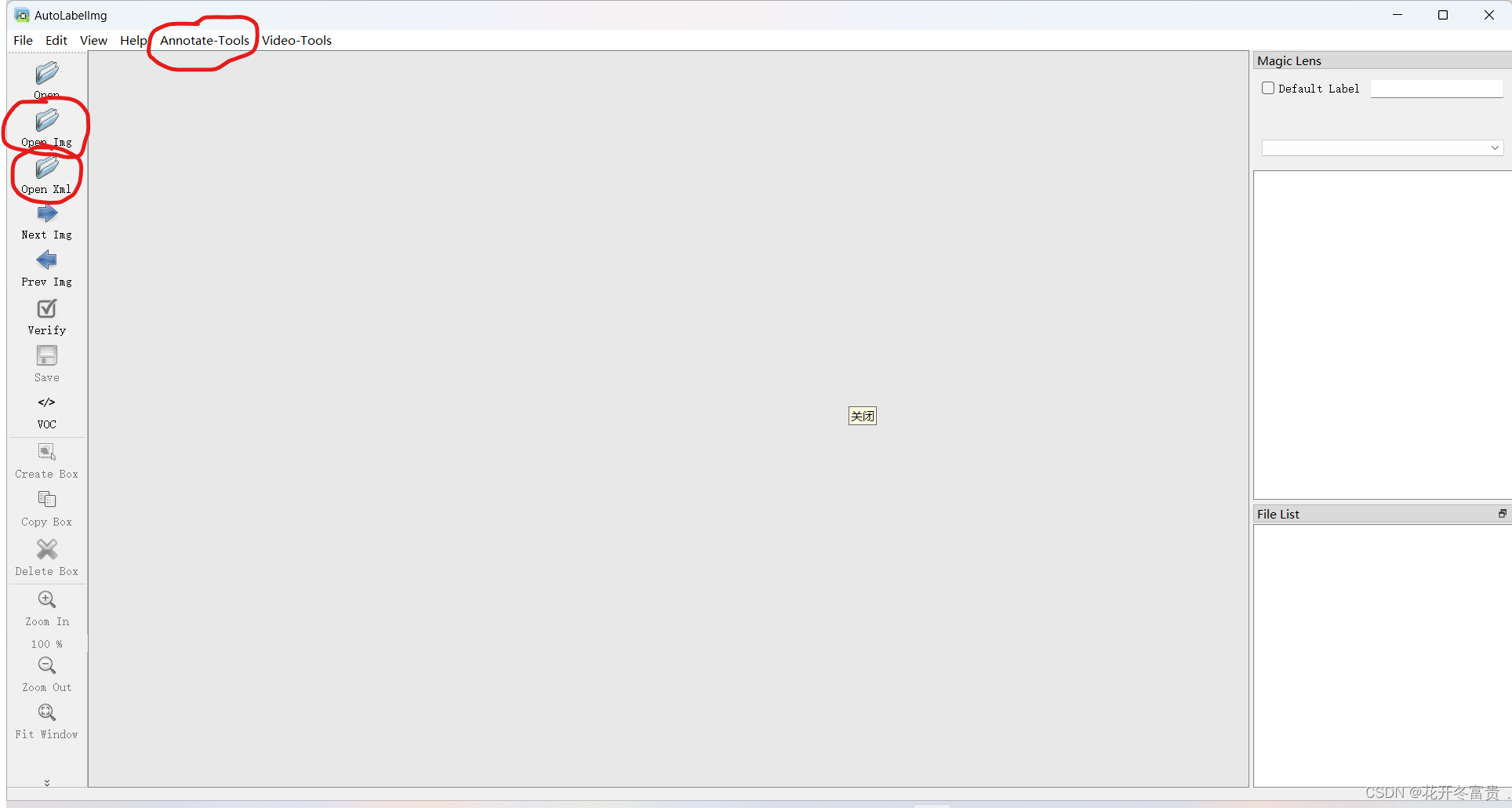
python labelimg.py可以看到与labelimg页面相似。选择好图片和标签文件夹后,点击上方 Annotate-tools,再点击auto labelimg。
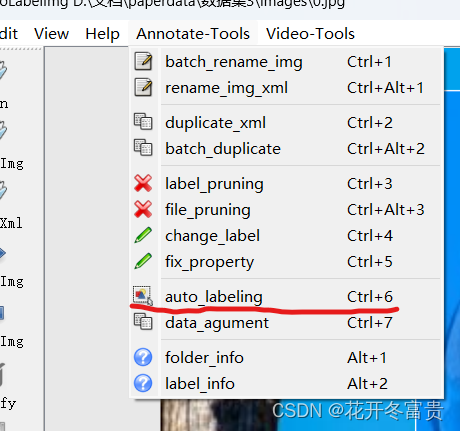
选择你的yolov5模型,点击ok
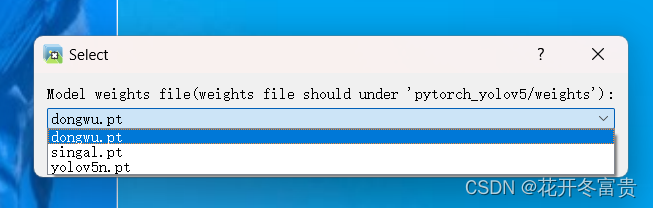
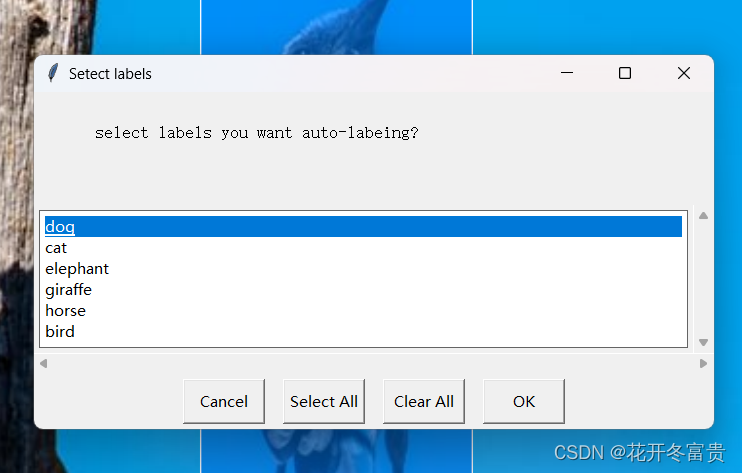
选择你这次要打的标签名,点击ok
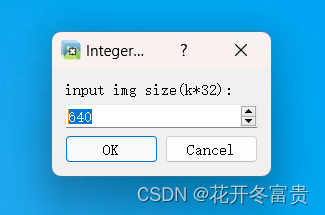
输入input图片的size,默认为640.(这点很重要,最好是用代码把图片size统一转换成640*480),如果图片实际尺寸和这里输入的尺寸不一致的话,yolov5训练出来的标签是错位的,我看很多教程都没提到这一点.
点击ok后,等待进度条完成就可以。
注意,如果没有cuda,会报这个错
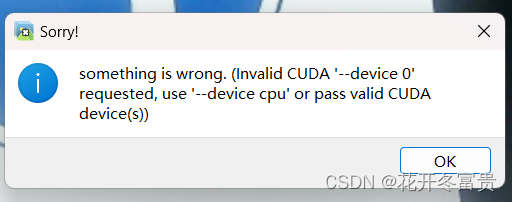
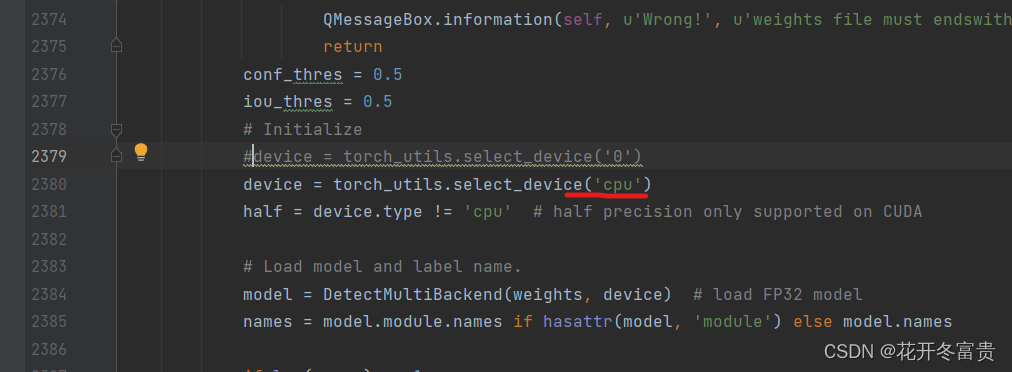
只需要将labelimg.py中2379行左右改成如图所示,即可使用cpu进行标注。
看到这里,如果成功了,点个赞再走好吗!
如果遇到问题,请在评论区留言,看到了就会回复。



















 1311
1311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











