










-
HashMap在Java开发中非常常见 -
今天,我将带来
HashMap的全部源码分析,目录如下:

1. 简介
1.1 类定义
JDK中类定义如下所示:

1.2 主要介绍
-
HashMap的实现在JDK 1.7和JDK 1.8差别较大 -
今天主要是对
JDK 1.7中HashMap的源码进行解析,JDK 1.8源码后面再单独写一篇文章进行讲解。
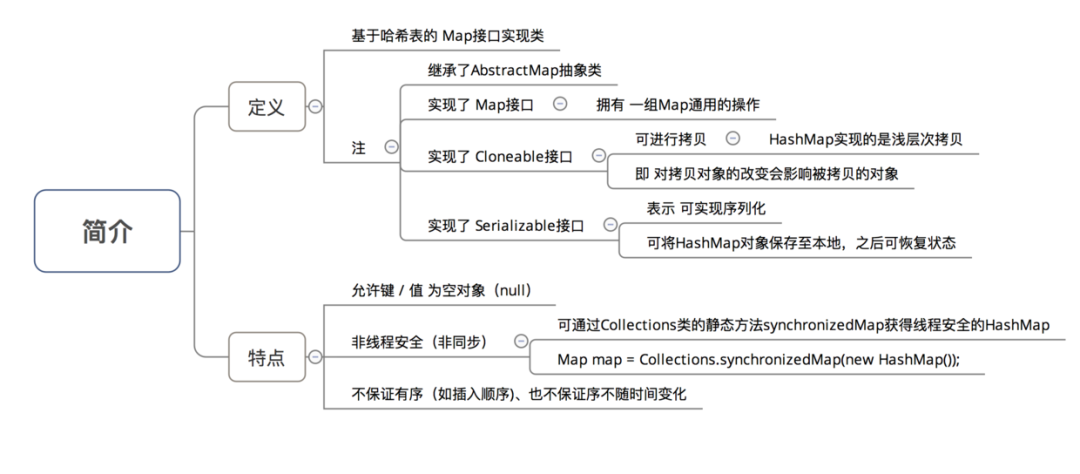
2.数据结构
2.1 具体描述
HashMap 采用的数据结构 = 数组(主) + 单链表(副),详细描述如下图所示:
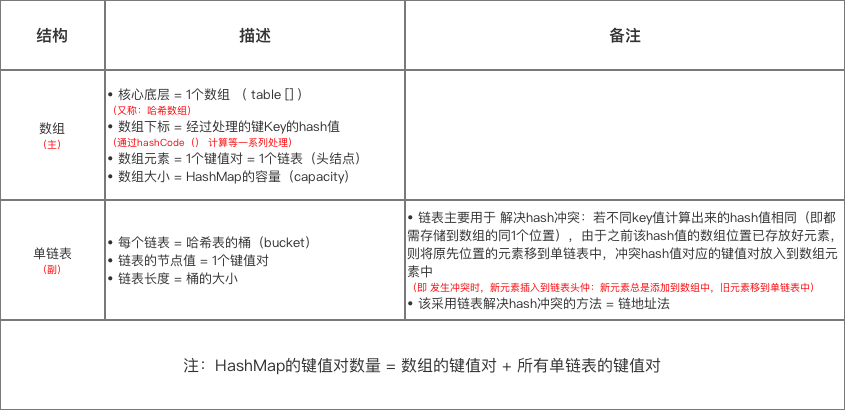
2.2 示意图
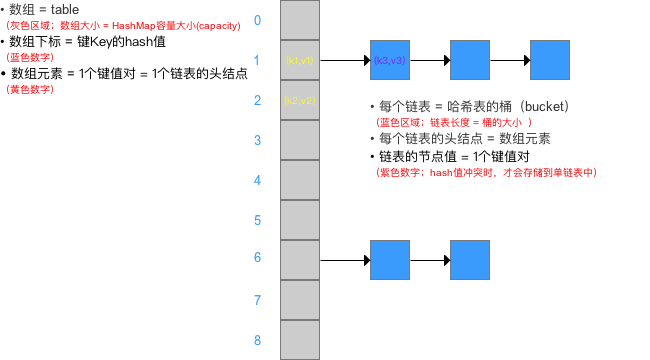
2.3 存储流程
为了让大家有个感性的认识,这里只是简单的画出存储流程,更加详细的存储流程会在下面源码分析中给出:
2.4 数组元素和链表节点的实现类
HashMap中的数组元素 & 链表节点 都采用 Entry类 实现,如下图所示:
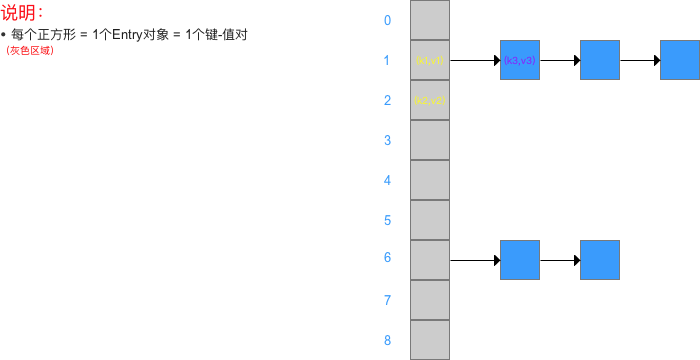
从上图可以看出:
-
HashMap的本质 = 1个存储Entry类对象的数组 + 多个存储Entry类对象单链表; -
Entry对象本质 = 1个映射(键 - 值对),属性包括:键(key)、值(value) & 下一个节点(next) = 单链表的指针 = 也是一个Entry对象,用于解决hash冲突
Entry类 实现如下:


3.具体使用
3.1 主要API

3.2 使用流程
在具体使用过程中,主要流程如下:
-
声明1个
HashMap的对象 -
向
HashMap添加数据(成对 放入 键 - 值对) -
获取
HashMap的某个数据 -
获取
HashMap的全部数据:遍历HashMap
示例代码如下:


运行结果:

下面,我们按照上述的使用过程,对一个个步骤进行源码解析。
4.HashMap中的重要变量
在进行真正的源码分析前,先讲解HashMap中的重要变量。
HashMap中的主要变量有容量、加载因子、扩容阈值
具体介绍如下

参数示意图如下:
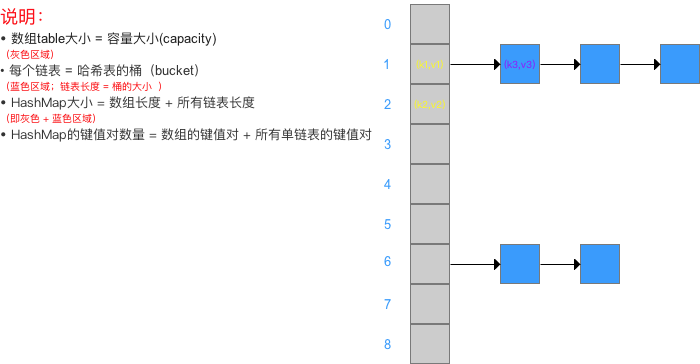
需要注意的是容量大小指的是底层数组的大小,不是哈希表元素的个数。
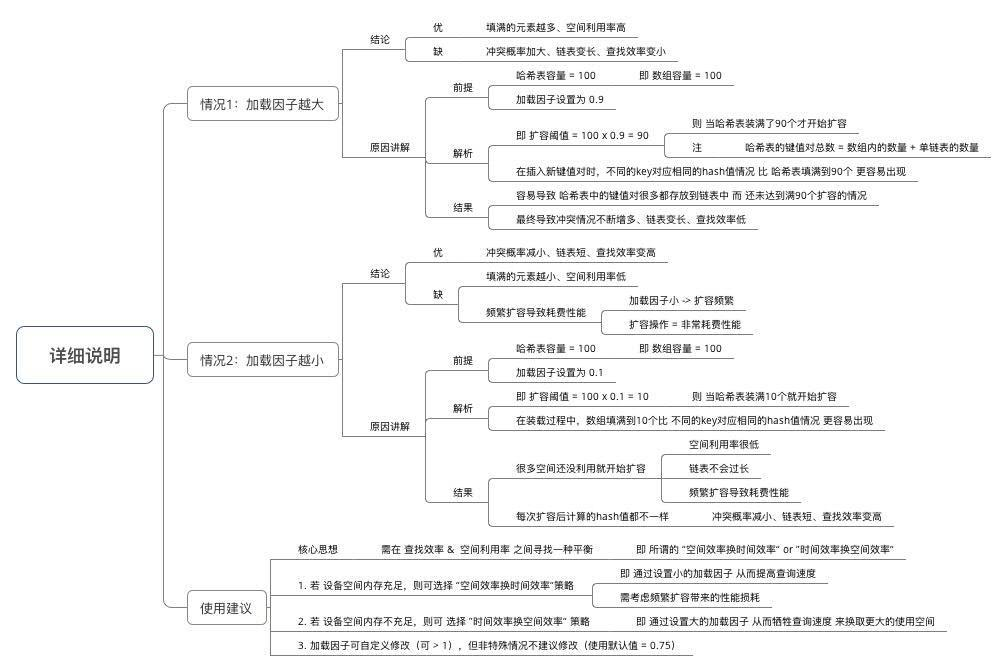
此处详细说明加载因子,所谓的加载因子,也叫扩容因子或者负载因子,加载因子 = 元素个数 / 容量,它是用来进行扩容判断的,假设加载因子是0.5,HashMap初始化容量是16,当HashMap中有16 * 0.5=8个元素时,HashMap就会进行扩容操作。而HashMap中加载因子为0.75,是考虑到了性能和容量的平衡。
加载因子对性能和容量的影响如下图总结:
5.索源码剖析
本次的源码分析主要是根据 使用步骤 进行相关函数的详细分析,主要分析内容如下:
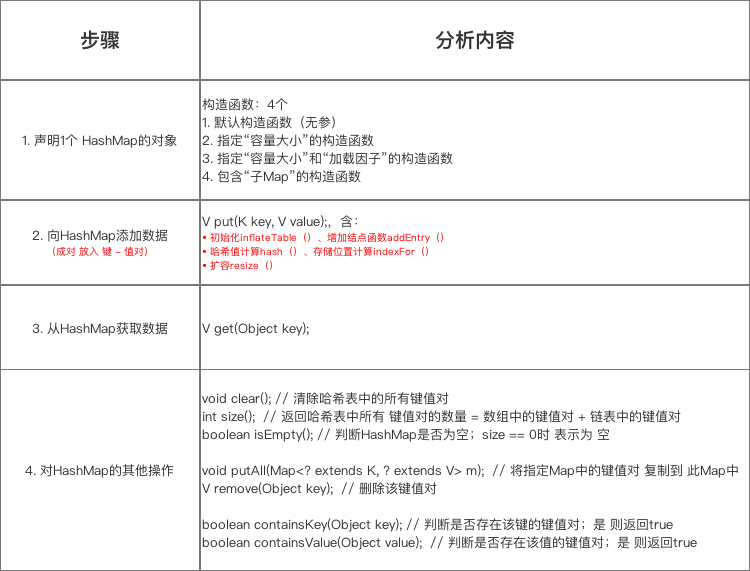
5.1 步骤1:声明一个HashMap对象


正如以上代码所示,声明一个HashMap时,有4个构造函数可供选择,但是我们从源码中可以看到,这4个构造函数都没有真正初始化哈希表,即初始化存储数组table。
真正初始化哈希表(初始化存储数组table)是在第1次添加键值对时,即第1次调用put()时。下面会详细说明
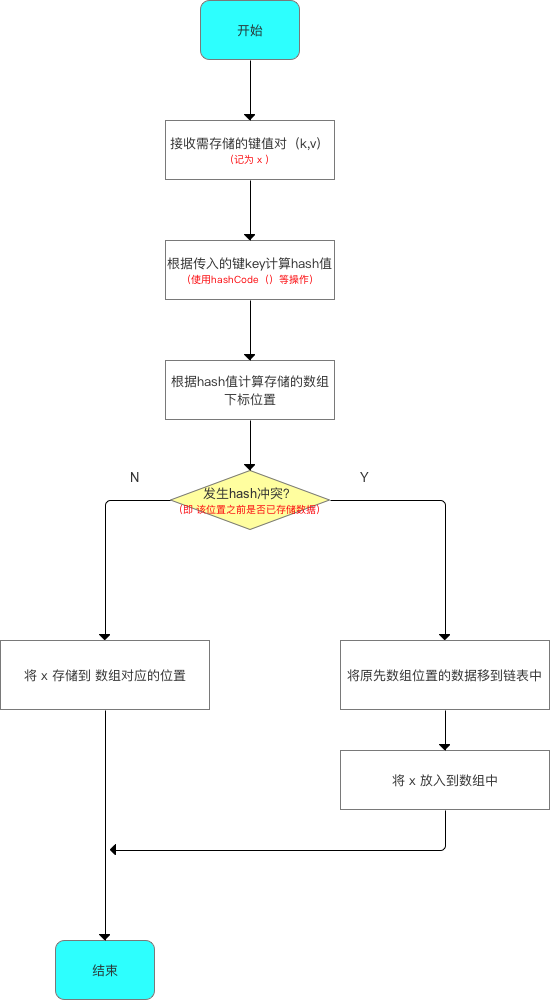
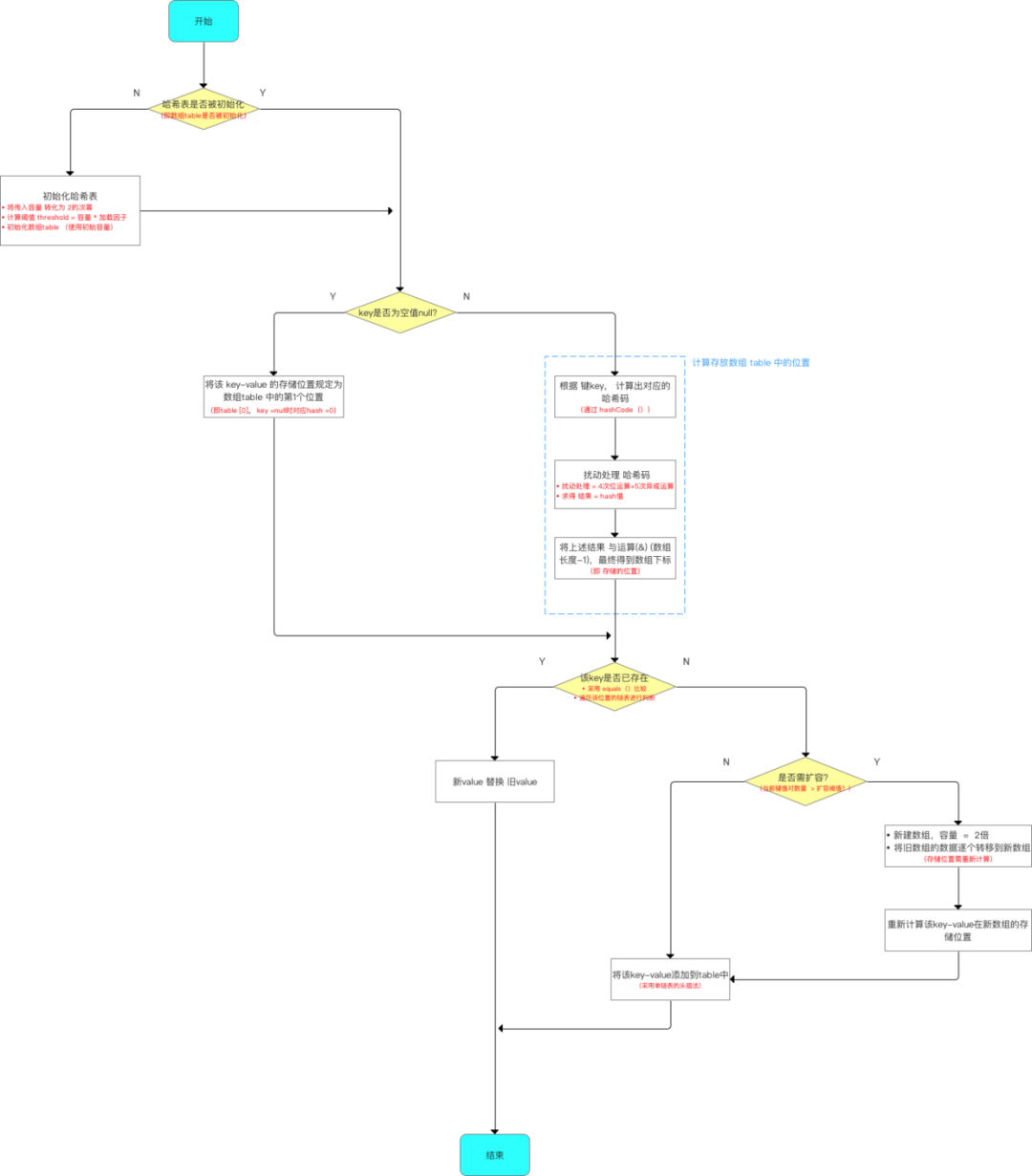
5.2 步骤2:向HashMap中put数据
向HashMap中添加数据的流程如下(这里先简单看下流程图,后面进行源码分析):
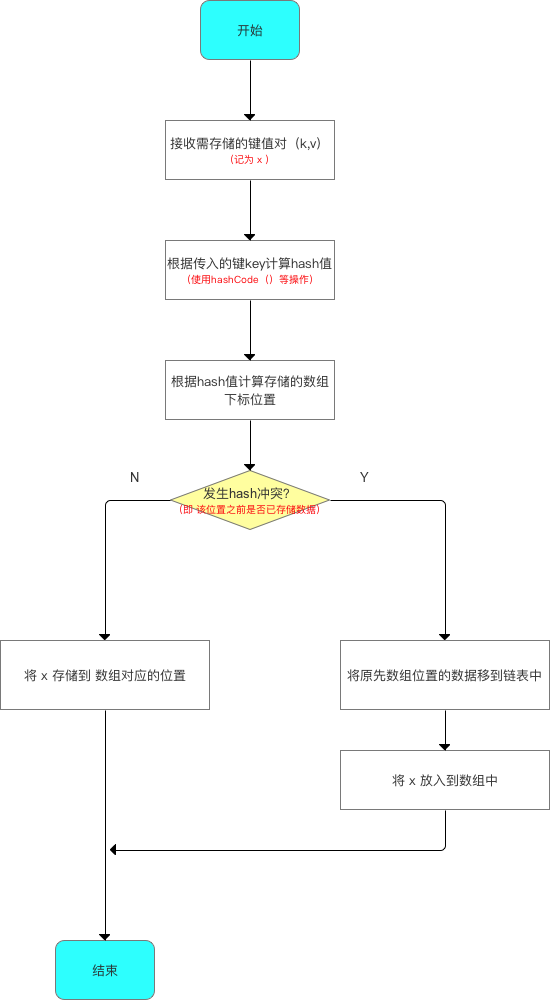

根据源码分析所作出的流程图如下:
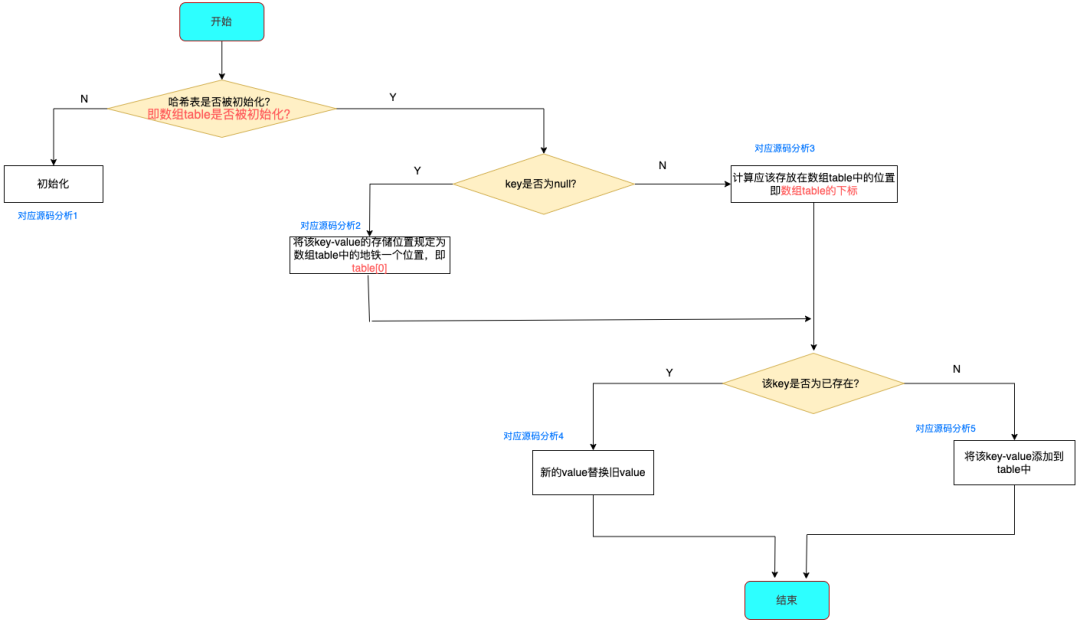
下面,我将根据上述流程的5个分析点进行详细讲解:
分析1:初始化哈希表
即 初始化数组(table)、扩容阈值(threshold)

再次强调:真正初始化哈希表(初始化存储数组table)是在第1次添加键值对时,即第1次调用put()时
分析2:当key==null
当 key ==null时,将该 key-value 的存储位置规定为数组table 中的第1个位置,即table [0],

从此处可以看出:
-
HashMap的键key可为null(区别于HashTable的key不可为null) -
HashMap的键key可为null且只能为1个,但值value可为null且为多个
分析3:根据key计算其应用存放在table的位置(即数组下标)

下图总结 了计算存放在数组 table 中的位置(即数组下标、索引)的过程,大家可以对照源码查看:
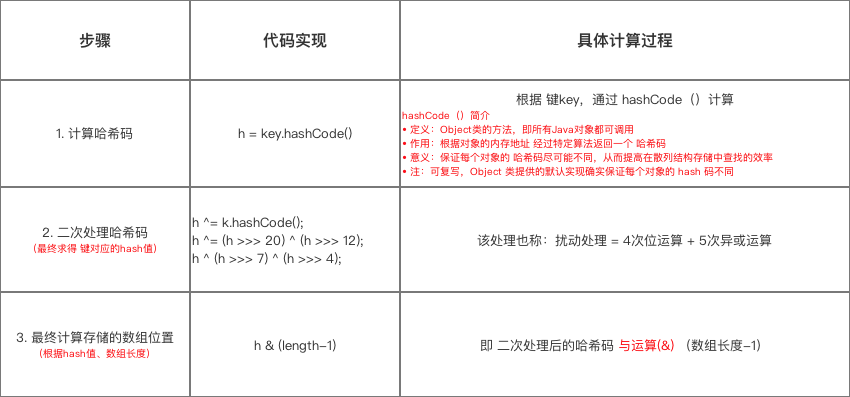
在了解 如何计算存放数组table 中的位置 后,所谓 知其然 而 需知其所以然,下面我将讲解为什么要这样计算,即主要解答以下3个问题:
-
为什么不直接采用经过
hashCode()处理的哈希码 作为 存储数组table的下标位置? -
为什么采用 哈希码 与运算(&) (数组长度-1) 计算数组下标?
-
为什么在计算数组下标前,需对哈希码进行二次处理:扰动处理?
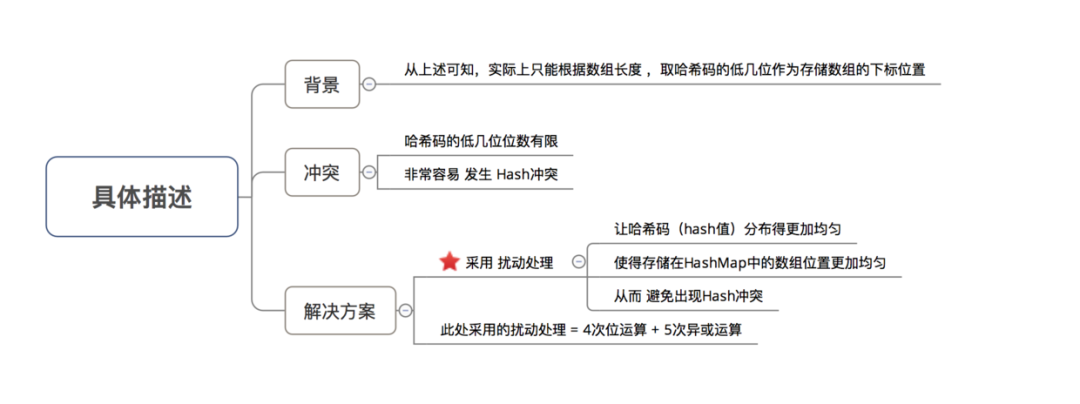
在回答这3个问题前,请大家记住一个核心思想:所有处理的根本目的,都是为了提高 存储key-value的数组下标位置 的随机性 & 分布均匀性,尽量避免出现hash值冲突。即:对于不同key,存储的数组下标位置要尽可能不一样
问题1:为什么不直接采用经过hashCode()处理的哈希码 作为 存储数组table的下标位置?
-
结论:容易出现 哈希码 与 数组大小范围不匹配的情况,即 计算出来的哈希码可能 不在数组大小范围内,从而导致无法匹配存储位置
-
原因描述

- 为了解决 “哈希码与数组大小范围不匹配” 的问题,
HashMap给出了解决方案:哈希码 与运算(&) (数组长度-1);请继续问题2
问题2:为什么采用 哈希码 与运算(&) (数组长度-1) 计算数组下标?
-
结论:根据HashMap的容量大小(数组长度),按需取 哈希码一定数量的低位 作为存储的数组下标位置,从而 解决 “哈希码与数组大小范围不匹配” 的问题
-
具体解决方案描述

问题3:为什么在计算数组下标前,需对哈希码进行二次处理:扰动处理?
-
结论:加大哈希码低位的随机性,使得分布更均匀,从而提高对应数组存储下标位置的随机性 & 均匀性,最终减少Hash冲突
-
具体描述
至此,关于怎么计算 key-value 值存储在HashMap数组位置 & 为什么要这么计算,讲解完毕。
分析4:若对应的key存在,则用新value覆盖旧value
当发生 Hash冲突时,为了保证 键key的唯一性哈希表并不会马上在链表中插入新数据,而是先查找该 key是否已存在,若已存在,则替换即可:

此处无复杂的源码分析,但此处的要点主要有2个:替换流程 & key是否存在(即key值的对比)。
要点1:替换流程
具体如下图:

要点2:key值比较
采用 equals() 或 "" 进行比较,下面给出其介绍 & 与 “”使用的对比:
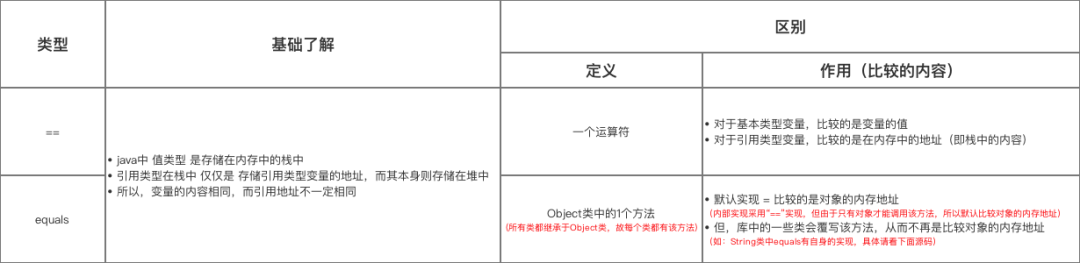
分析5:若对应的key不存在,则将zkey-value添加到table对应的位置
函数源码分析如下



此处有2点需特别注意:键值对的添加方式 & 扩容机制
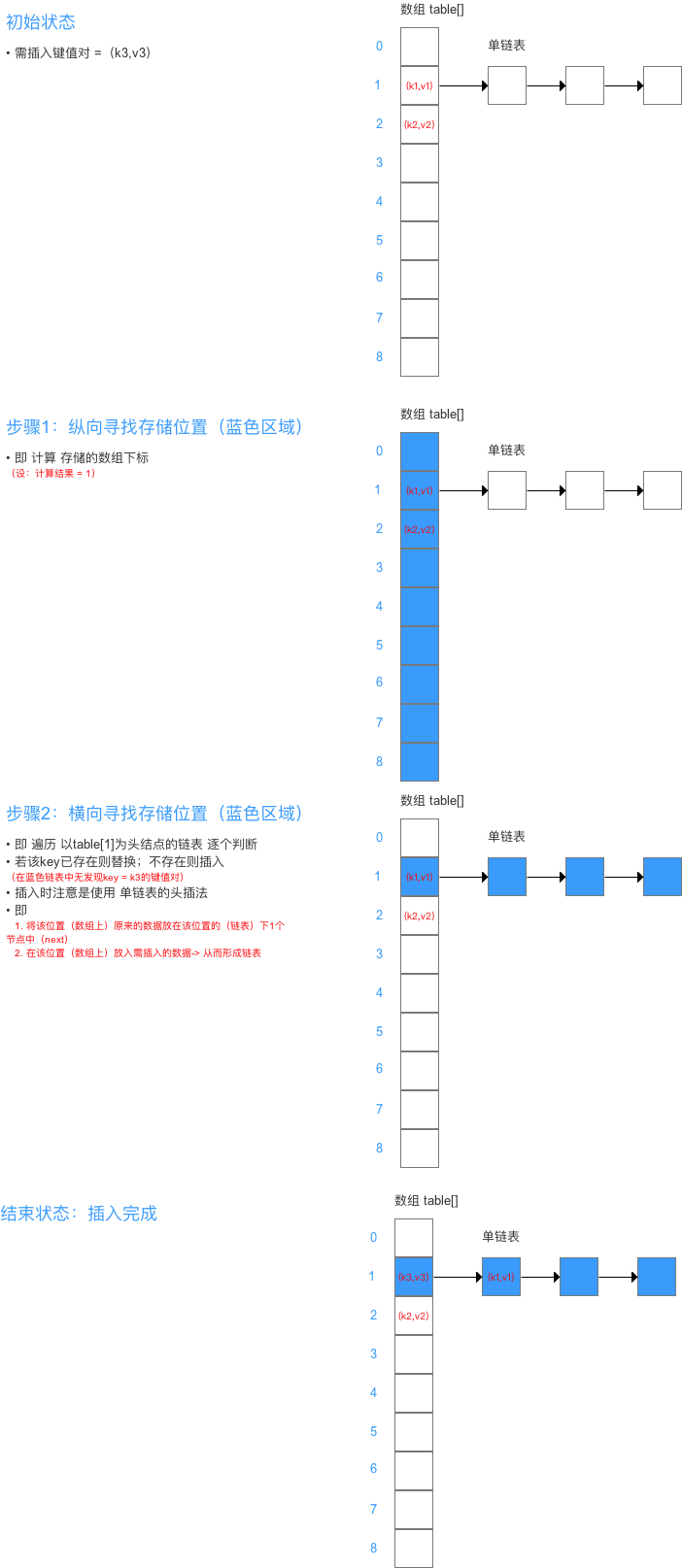
注意点1:键值对的添加方式:单链表的头插法
-
即 将该位置(数组上)原来的数据放在该位置的(链表)下1个节点中(next)、在该位置(数组上)放入需插入的数据-> 从而形成链表
-
如下示意图
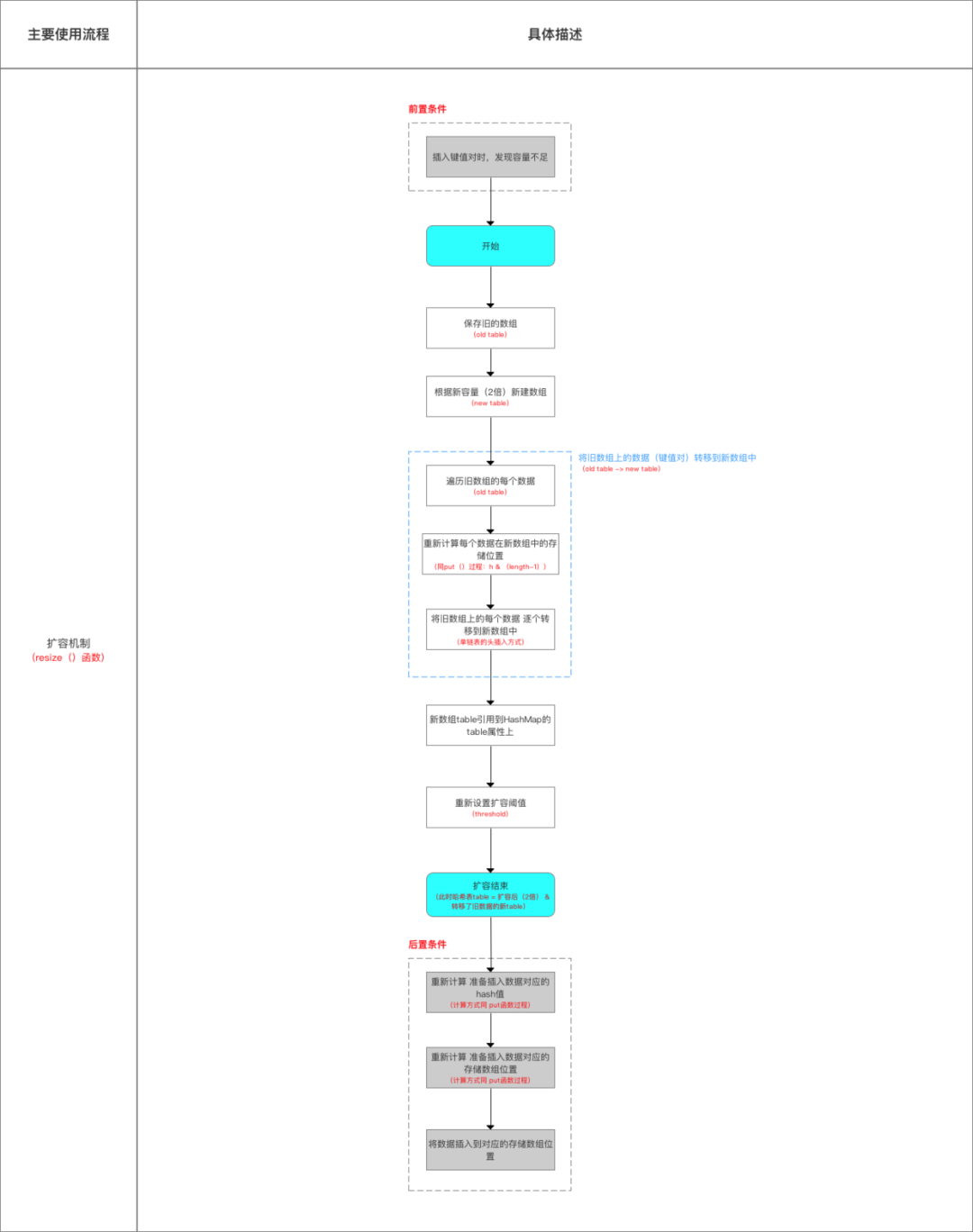
注意点2:扩容机制
具体流程如下:
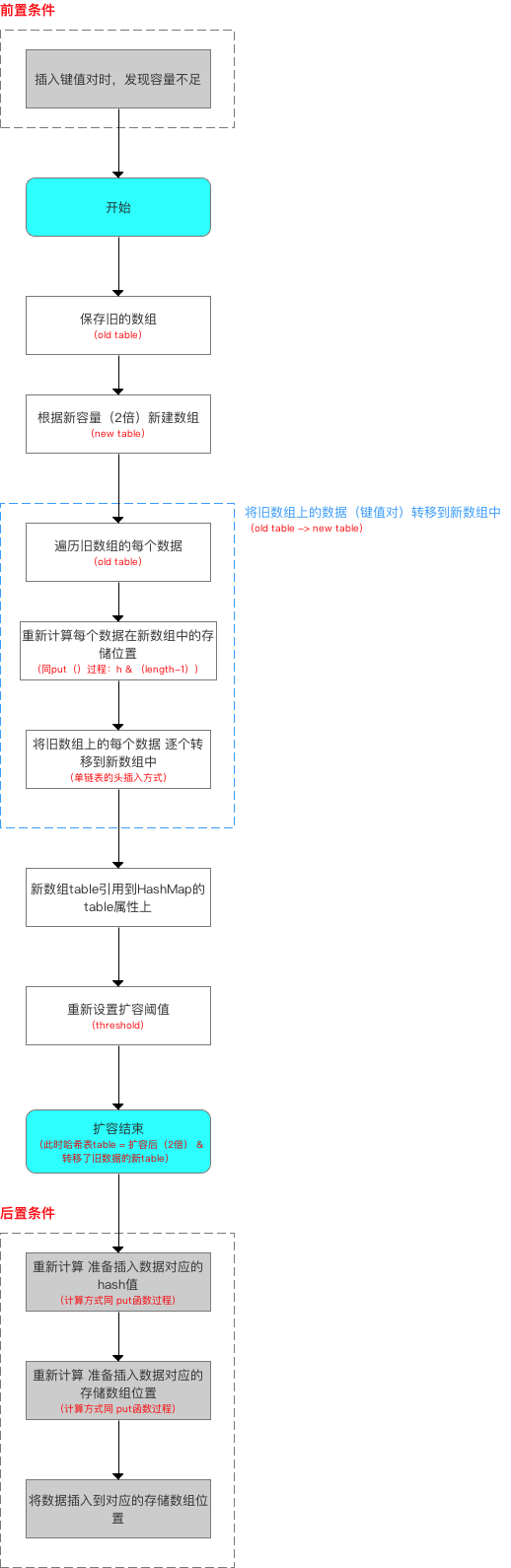
扩容过程中的转移数据示意图如下

在扩容resize()过程中,在将旧数组上的数据 转移到 新数组上时,转移操作 = 按旧链表的正序遍历链表、在新链表的头部依次插入,即在转移数据、扩容后,容易出现链表逆序的情况。注:图片不清楚可以下载到本地放大能看清。
设重新计算存储位置后不变,即扩容前 = 1->2->3,扩容后 = 3->2->1。
此时若(多线程)并发执行 put()操作,一旦出现扩容情况,则 容易出现 环形链表,从而在获取数据、遍历链表时 形成死循环(Infinite Loop),即 死锁的状态 = 线程不安全。
总结
- 向
HashMap添加数据(成对 放入 键 - 值对)的全流程
-
示意图

至此,关于 “向 HashMap 添加数据(成对 放入 键 - 值对)“讲解完毕。
5.3 从HashMap中获取数据
假如理解了上述put()函数的原理,那么get()函数非常好理解,因为二者的过程原理几乎相同,get()函数的流程如下:
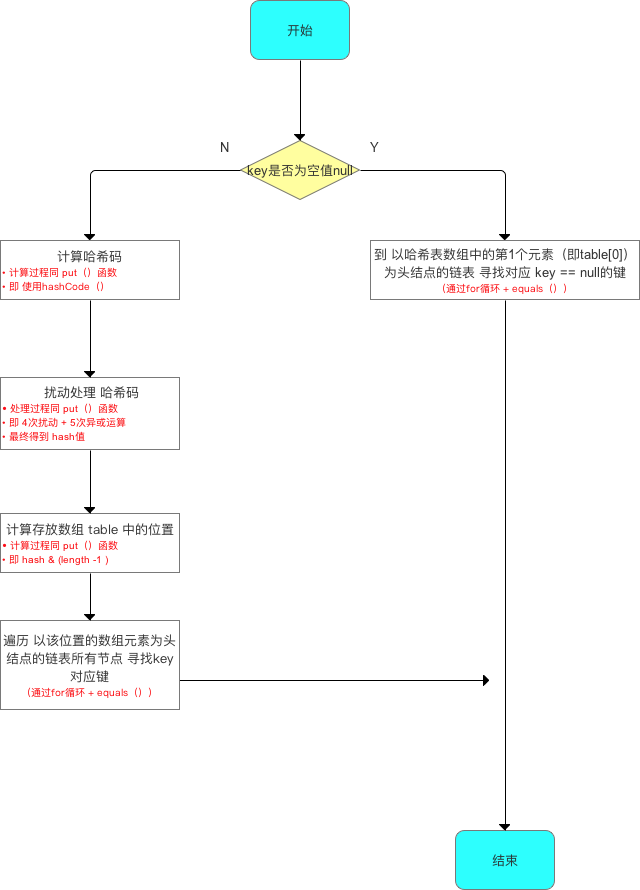
具体源码注释如下:


至此,关于 “向 HashMap 获取数据 “讲解完毕。
5.4 对 HashMap的其它操作
HashMap除了核心的put()、get()函数,还有以下主要使用的函数方法。

下面将介绍以上几个函数的源码,如下:



至此,关于HashMap的底层原理 & 主要使用API(函数、方法)讲解完毕。
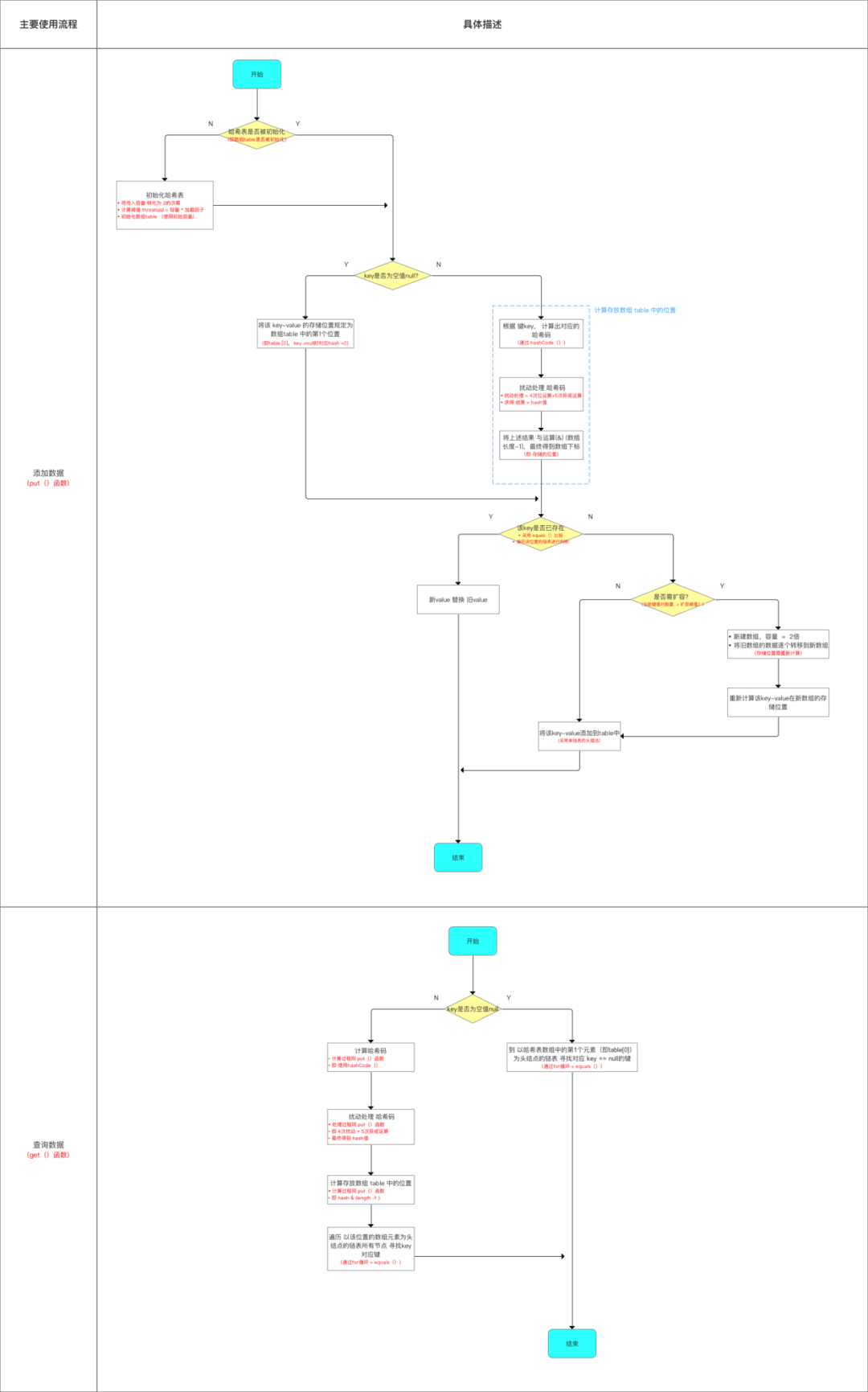
6.源码总结
下面,用3个图总结整个源码内容,总结内容 = 数据结构、主要参数、添加 & 查询数据流程、扩容机制。
- 数据结构 & 主要参数

- 添加&查询数据流程
- 扩容机制
7.额外补充
有几个小问题需要在此补充。
7.1 哈希表如何解决哈希冲突
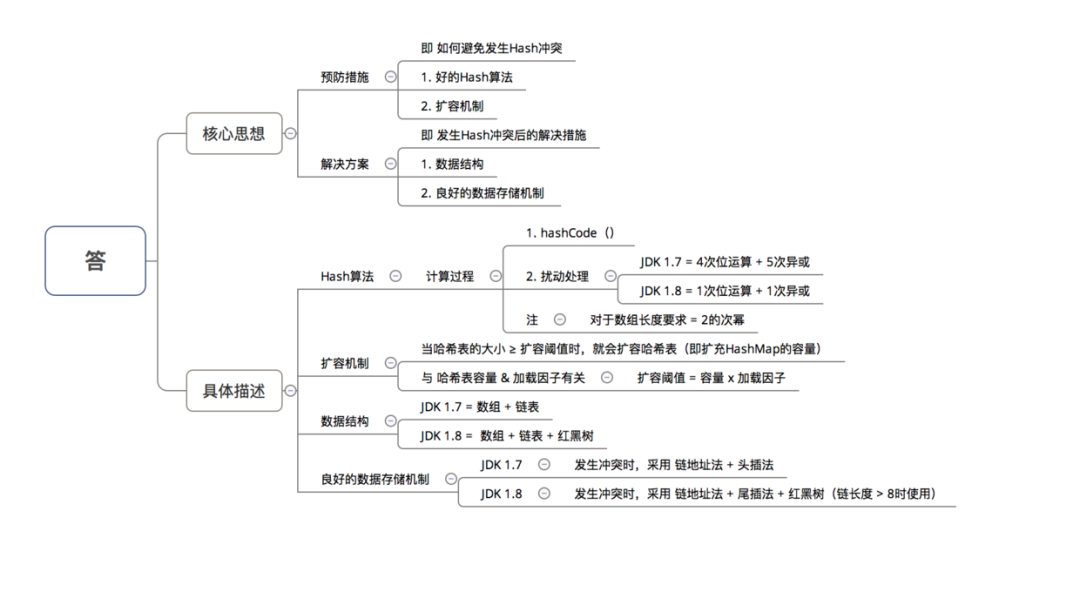
7.2 HashMap的特点
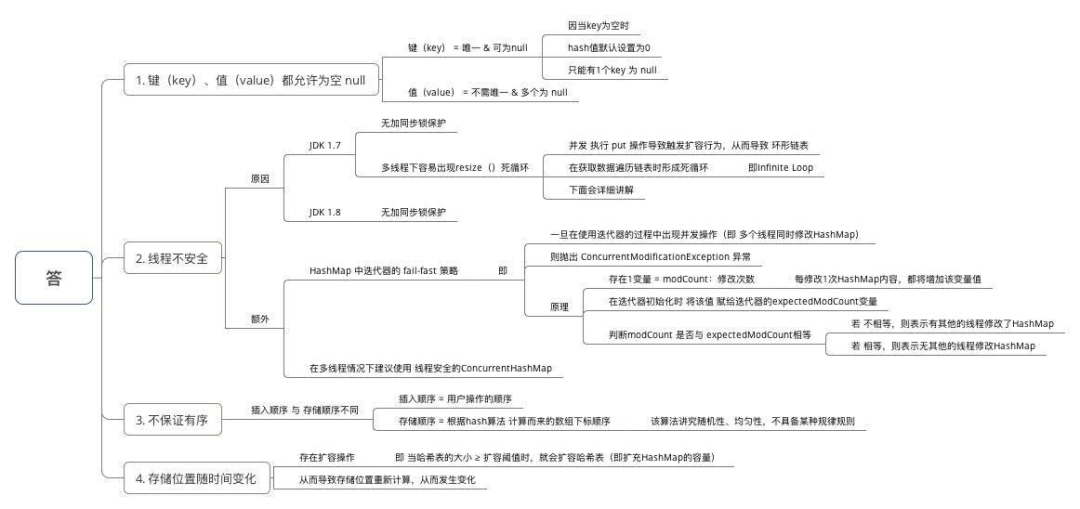
为什么HashMap具备下述特点:键-值(key-value)都允许为空、线程不安全、不保证有序、存储位置随时间变化。
具体解答如下:
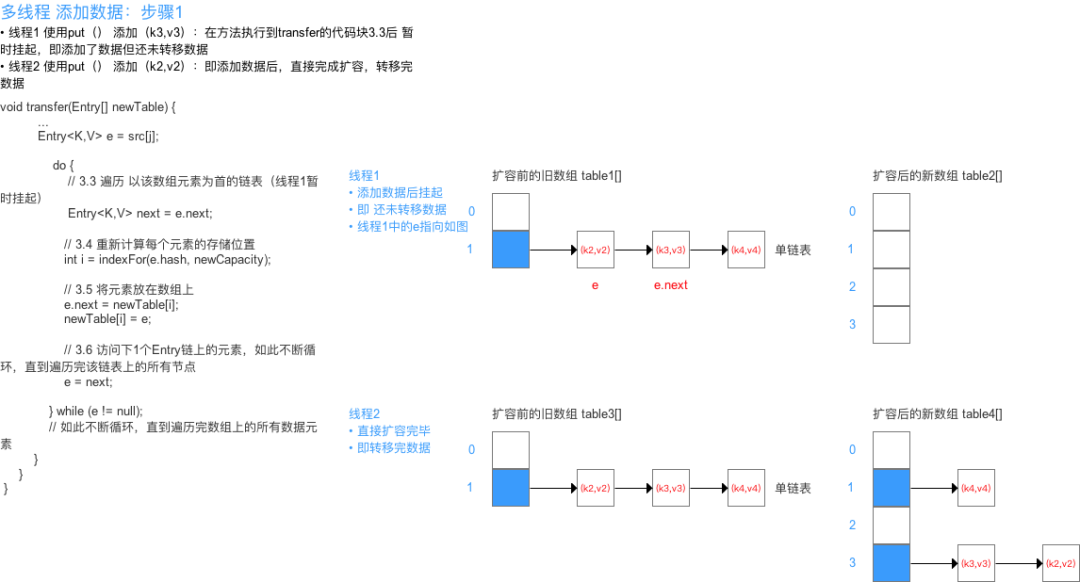
下面主要讲解 HashMap 线程不安全的其中一个重要原因:多线程下容易出现resize()死循环 本质 = 并发 执行 put()操作导致触发 扩容行为,从而导致 环形链表,使得在获取数据遍历链表时形成死循环,即Infinite Loop。
先看扩容的源码分析resize(),关于resize()的源码分析已在上文详细分析,此处仅作重点分析:transfer():


从上面可看出:在扩容resize()过程中,在将旧数组上的数据 转移到 新数组上时,转移数据操作 = 按旧链表的正序遍历链表、在新链表的头部依次插入,即在转移数据、扩容后,容易出现链表逆序的情况
此时若(多线程)并发执行 put()操作,一旦出现扩容情况,则 容易出现 环形链表,从而在获取数据、遍历链表时 形成死循环(Infinite Loop),即 死锁的状态,具体请看下图:

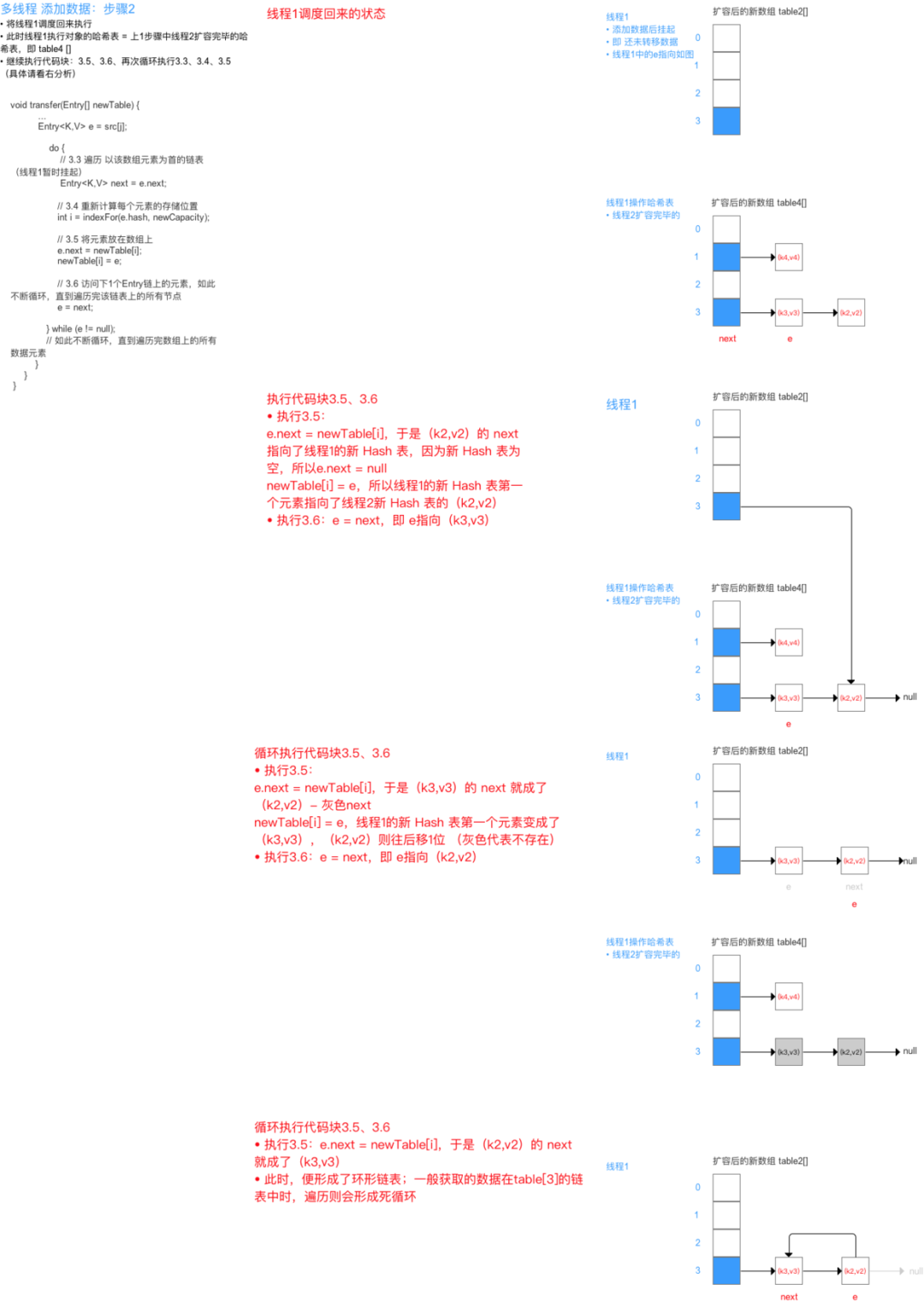
注:由于 JDK 1.8 转移数据操作 = 按旧链表的正序遍历链表、在新链表的尾部依次插入,所以不会出现链表 逆序、倒置的情况,故不容易出现环形链表的情况。但 JDK 1.8 还是线程不安全,因为 无加同步锁保护
7.3 为什么Integer等包装类和String适合作为HashMap的key键
 7.4 HashMap的key键若为object类型,则需要实现哪些方法?
7.4 HashMap的key键若为object类型,则需要实现哪些方法?
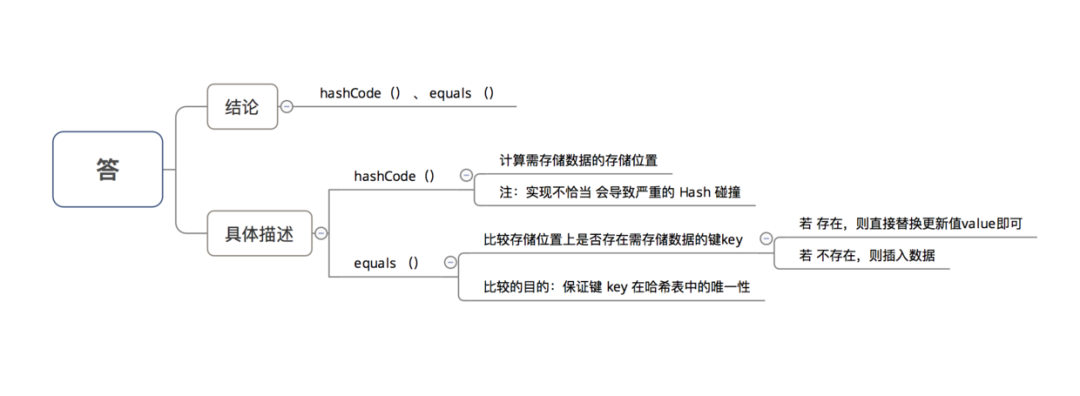
至此,关于HashMap(JDK 1.7)的所有知识讲解完毕。
`黑客&网络安全如何学习
今天只要你给我的文章点赞,我私藏的网安学习资料一样免费共享给你们,来看看有哪些东西。
1.学习路线图
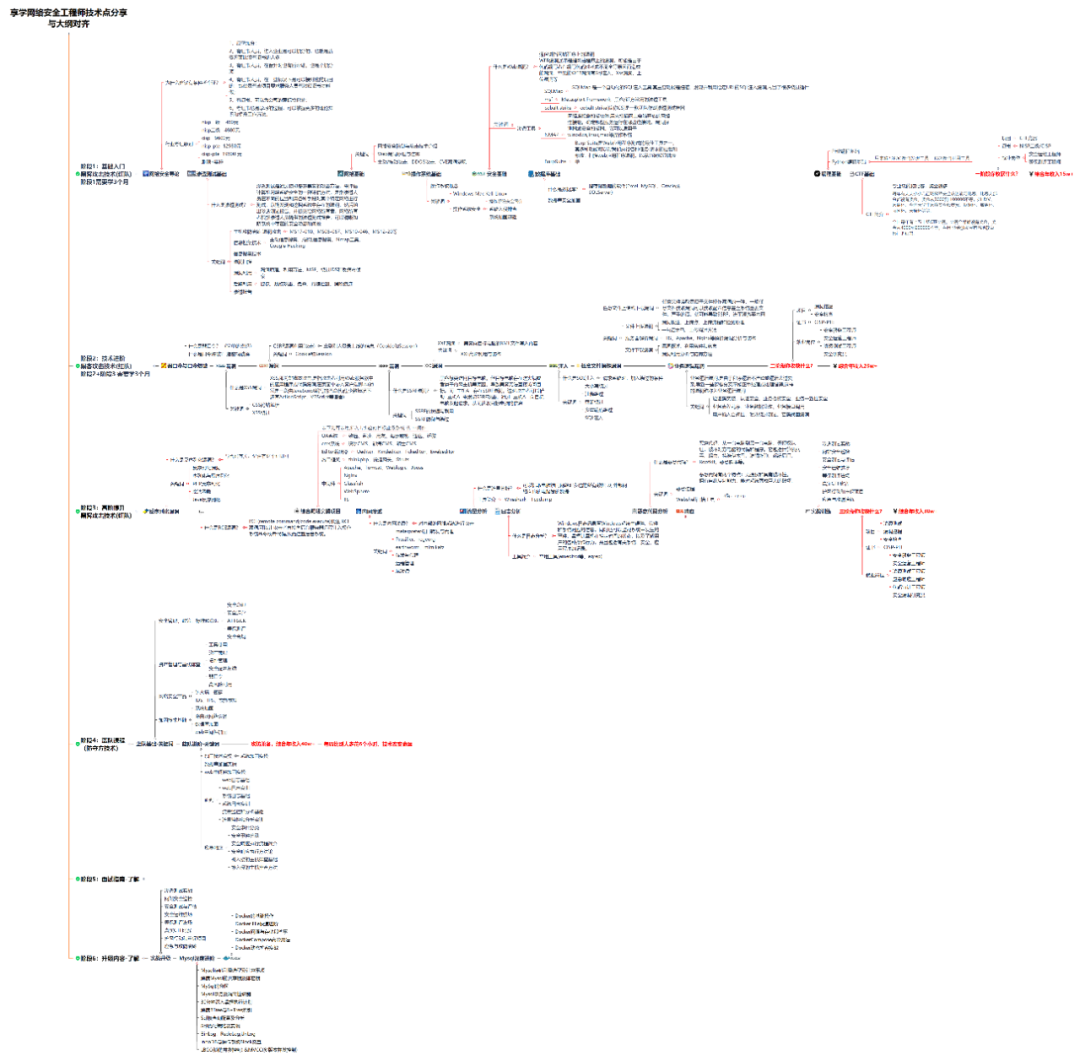
攻击和防守要学的东西也不少,具体要学的东西我都写在了上面的路线图,如果你能学完它们,你去就业和接私活完全没有问题。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己录的网安视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。
内容涵盖了网络安全法学习、网络安全运营等保测评、渗透测试基础、漏洞详解、计算机基础知识等,都是网络安全入门必知必会的学习内容。
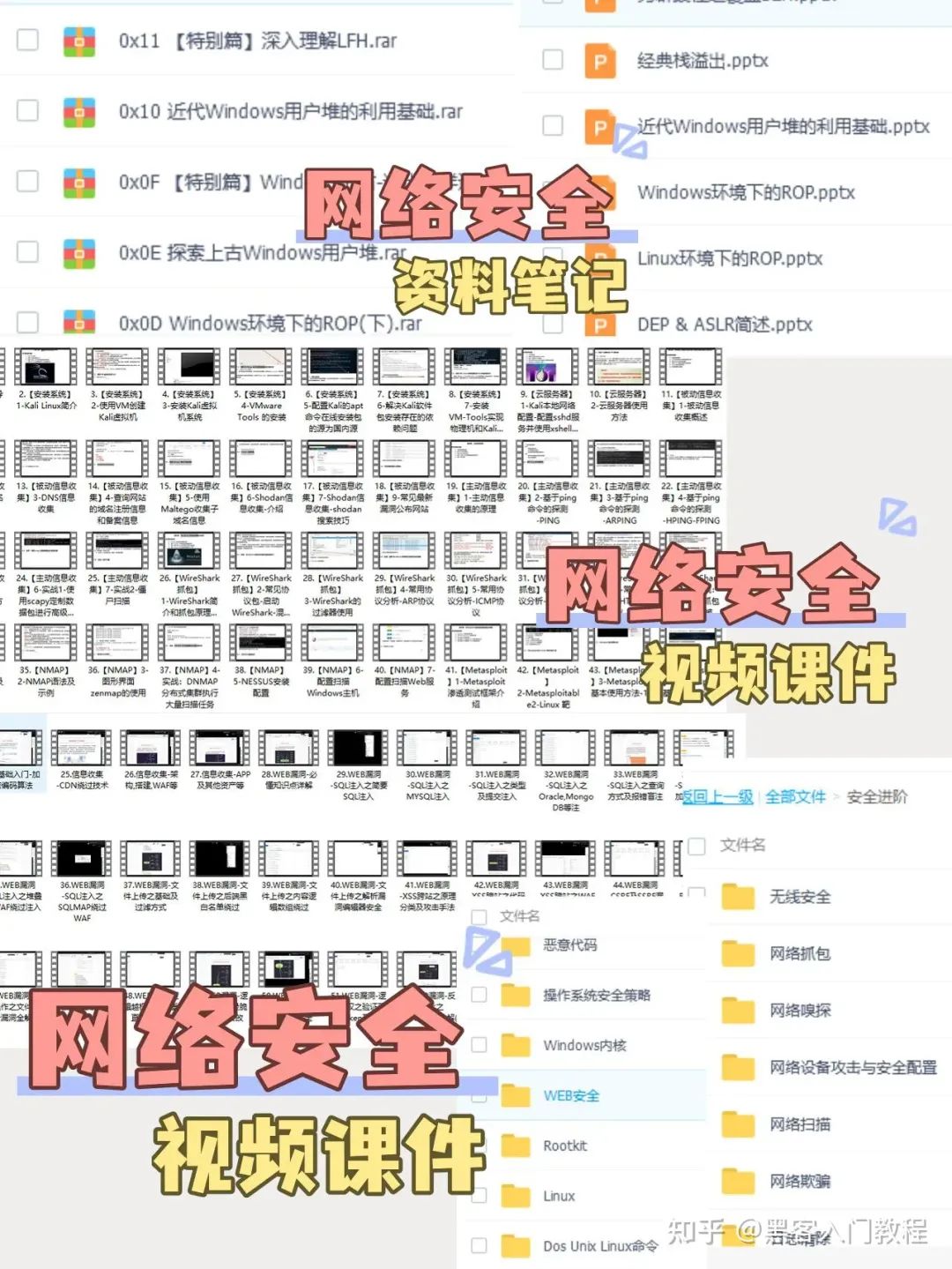
(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
3.技术文档和电子书
技术文档也是我自己整理的,包括我参加大型网安行动、CTF和挖SRC漏洞的经验和技术要点,电子书也有200多本,由于内容的敏感性,我就不一一展示了。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
4.工具包、面试题和源码
“工欲善其事必先利其器”我为大家总结出了最受欢迎的几十款款黑客工具。涉及范围主要集中在 信息收集、Android黑客工具、自动化工具、网络钓鱼等,感兴趣的同学不容错过。
还有我视频里讲的案例源码和对应的工具包,需要的话也可以拿走。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
最后就是我这几年整理的网安方面的面试题,如果你是要找网安方面的工作,它们绝对能帮你大忙。
这些题目都是大家在面试深信服、奇安信、腾讯或者其它大厂面试时经常遇到的,如果大家有好的题目或者好的见解欢迎分享。
参考解析:深信服官网、奇安信官网、Freebuf、csdn等
内容特点:条理清晰,含图像化表示更加易懂。
内容概要:包括 内网、操作系统、协议、渗透测试、安服、漏洞、注入、XSS、CSRF、SSRF、文件上传、文件下载、文件包含、XXE、逻辑漏洞、工具、SQLmap、NMAP、BP、MSF…

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取















 1103
1103

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









