







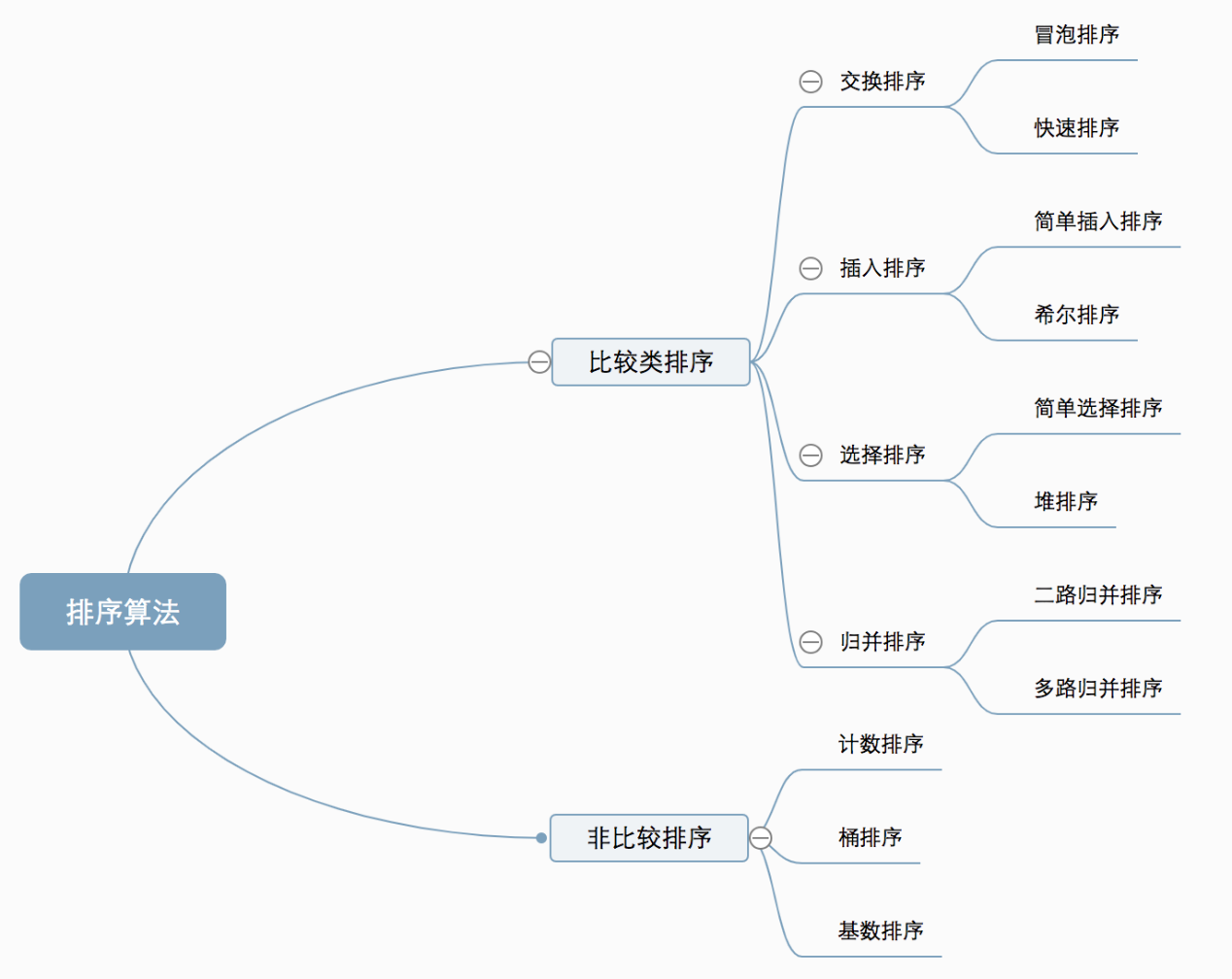
- 基本概念
(一)常见排序算法可以分为两大类:
1、比较类排序:通过比较来决定元素间的相对次序,由于其时间复杂度不能突破O(nlogn),因此也称为非线性时间比较类排序。
2、非比较类排序:不通过比较来决定元素间的相对次序,它可以突破基于比较排序的时间下界,以线性时间运行,因此也称为线性时间非比较类排序。
3、常见的排序算法
二、交换排序-冒泡排序基本概念
(一)概念:冒泡排序是一种简单的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。
(二)原理:比较两个相邻的元素,将值大的元素交换到右边
(三)动图:
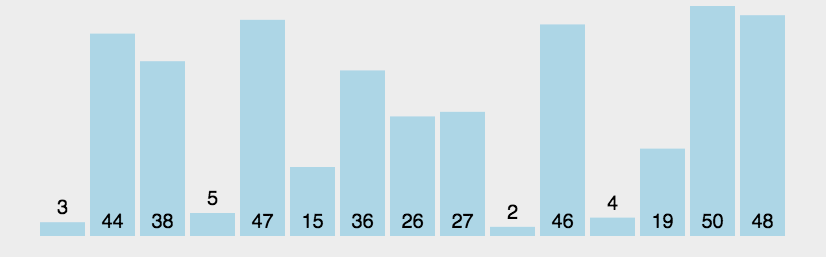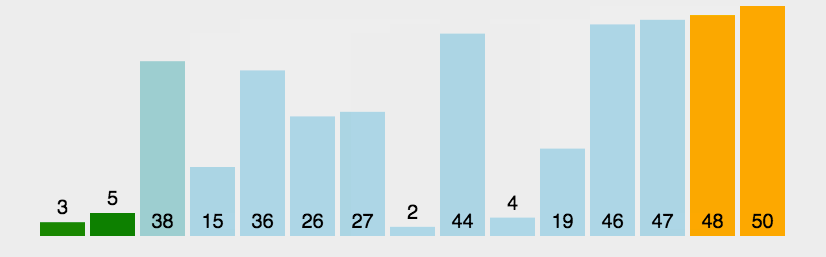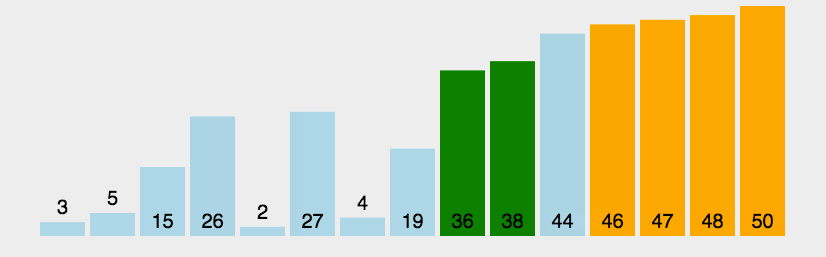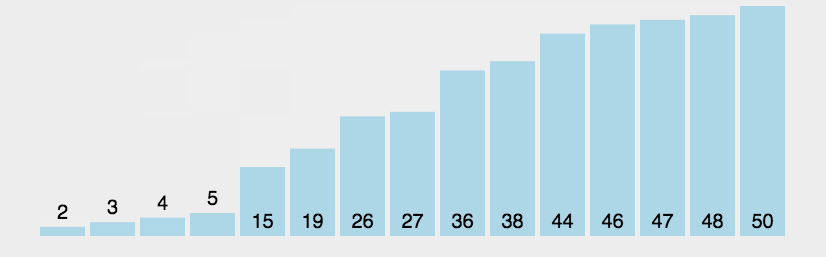
(四)思路:
1、第一趟比较:
(1)第一趟中第一次比较:首先比较第一和第二个数,将小数放在前面,将大数放在后。
(2)第一趟中第二次比较:第2和第3个数,将小数放在前面,大数放在后面。
(3)第一趟中第三次比较:第3和第4个数,将小数放在前面,大数放在后面。
(4)以此类推,直到比较到最后的两个数,将小数放在前面,大数放在后面
2、第二趟比较:
在第一趟比较完成后,最后一个数一定是所有数中最大的一个数,所以在比较第二趟的时候,最后一个数是不参加比较的。
(1)第二趟中第一次比较:首先比较第一和第二个数,将小数放在前面,将大数放在后。
(2)第二趟中第二次比较:第2和第3个数,将小数放在前面,大数放在后面。
(3)第二趟中第三次比较:第3和第4个数,将小数放在前面,大数放在后面。
(4)以此类推,直到比较到倒数第一和倒数第二的两个数,将小数放在前面,大数放在后面。
3、第三趟比较:
在第二趟比较完成后,倒数第二个数也一定是数组中倒数第二大数,所以在第三趟的比较中,最后两个数是不参与比较的。
比较方式和上面两趟示例一样,不作一一叙述。
三、常规实现
1、首先先准备一串数字,循环得到比较的趟数,如下:
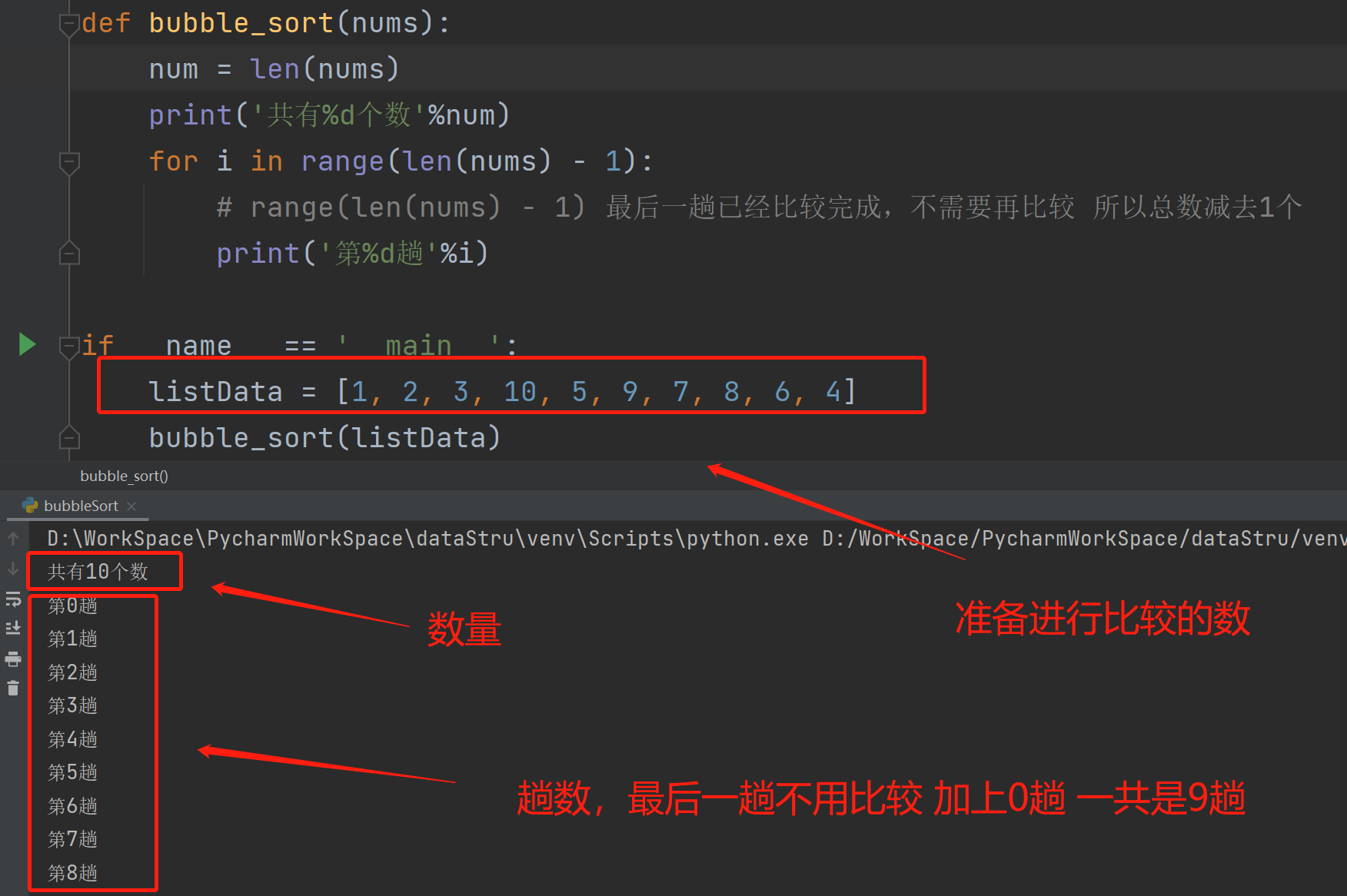
代码:
def bubble_sort(nums):
num = len(nums)
print('共有%d个数'%num)
for i in range(len(nums) - 1):
# range(len(nums) - 1) 最后一趟已经比较完成,不需要再比较 所以总数减去1个
print('第%d趟'%i)
if __name__ == '__main__':
listData = [1, 2, 3, 10, 5, 9, 7, 8, 6, 4]
bubble_sort(listData)2、利用双重循环,得到每一趟中比较的次数,如下:
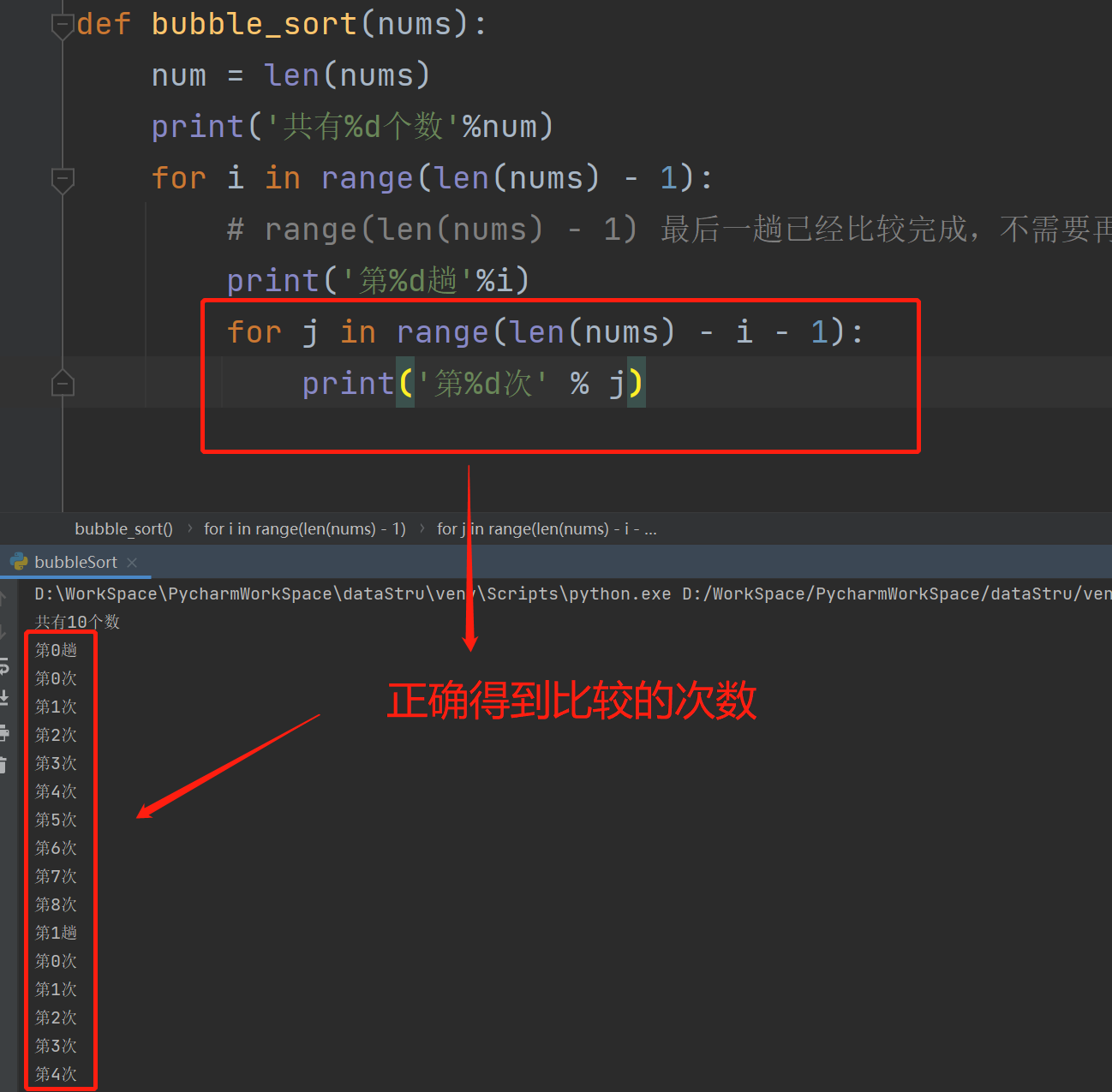
代码:
def bubble_sort(nums):
num = len(nums)
print('共有%d个数'%num)
for i in range(len(nums) - 1):
# range(len(nums) - 1) 最后一趟已经比较完成,不需要再比较 所以总数减去1个
print('第%d趟'%i)
for j in range(len(nums) - i - 1):
print('第%d次' % j)
if __name__ == '__main__':
listData = [1, 2, 3, 10, 5, 9, 7, 8, 6, 4]
bubble_sort(listData)3、每一次都将当前的数和后一次的数进行比较,将大的数放到后面,如下:
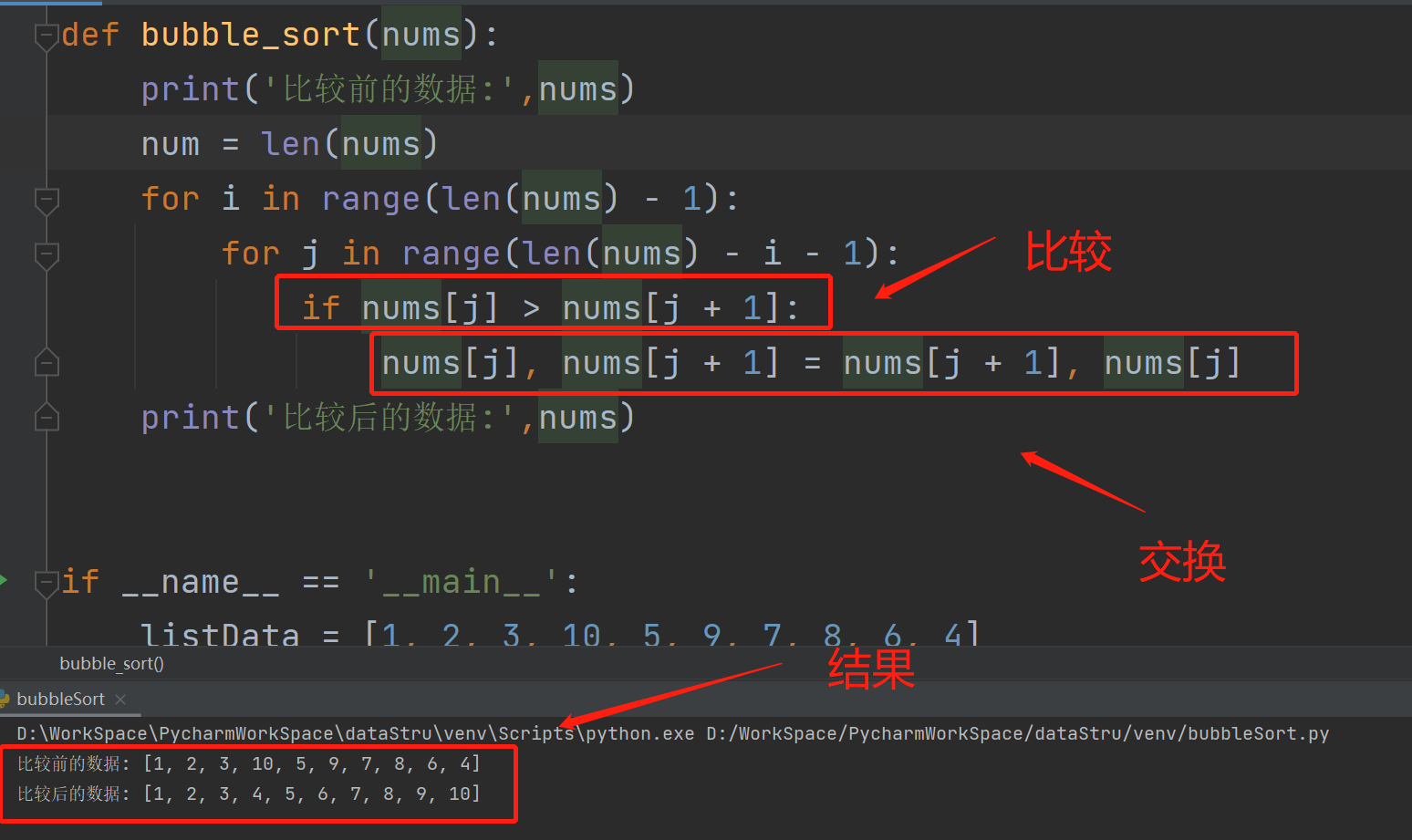
代码:
def bubble_sort(nums):
print('比较前的数据:',nums)
num = len(nums)
for i in range(len(nums) - 1):
for j in range(len(nums) - i - 1):
if nums[j] > nums[j + 1]:
nums[j], nums[j + 1] = nums[j + 1], nums[j]
print('比较后的数据:',nums)
if __name__ == '__main__':
listData = [1, 2, 3, 10, 5, 9, 7, 8, 6, 4]
bubble_sort(listData)4、修改打印显示下每一次的比较结果,如下:
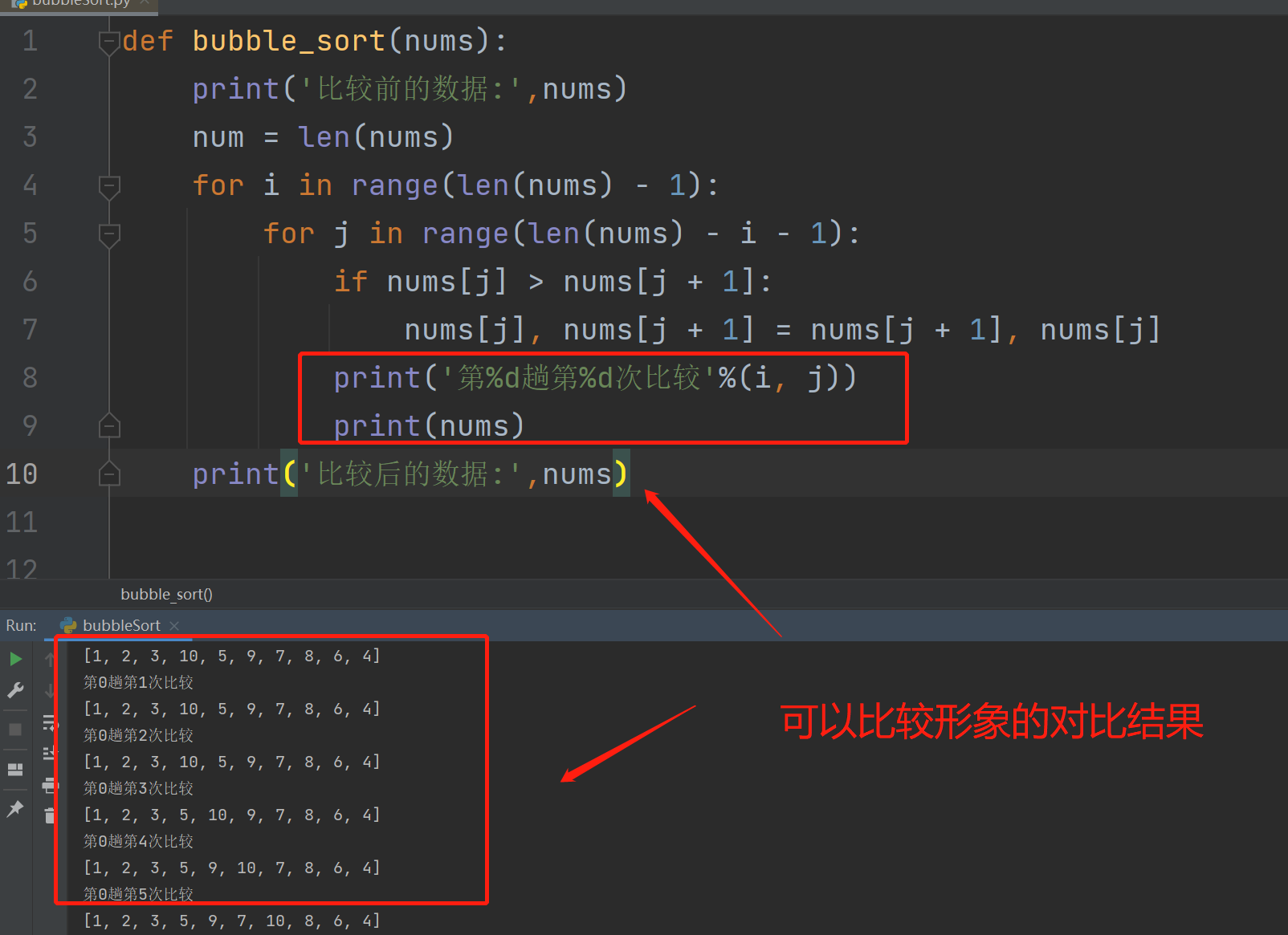
四、算法分析
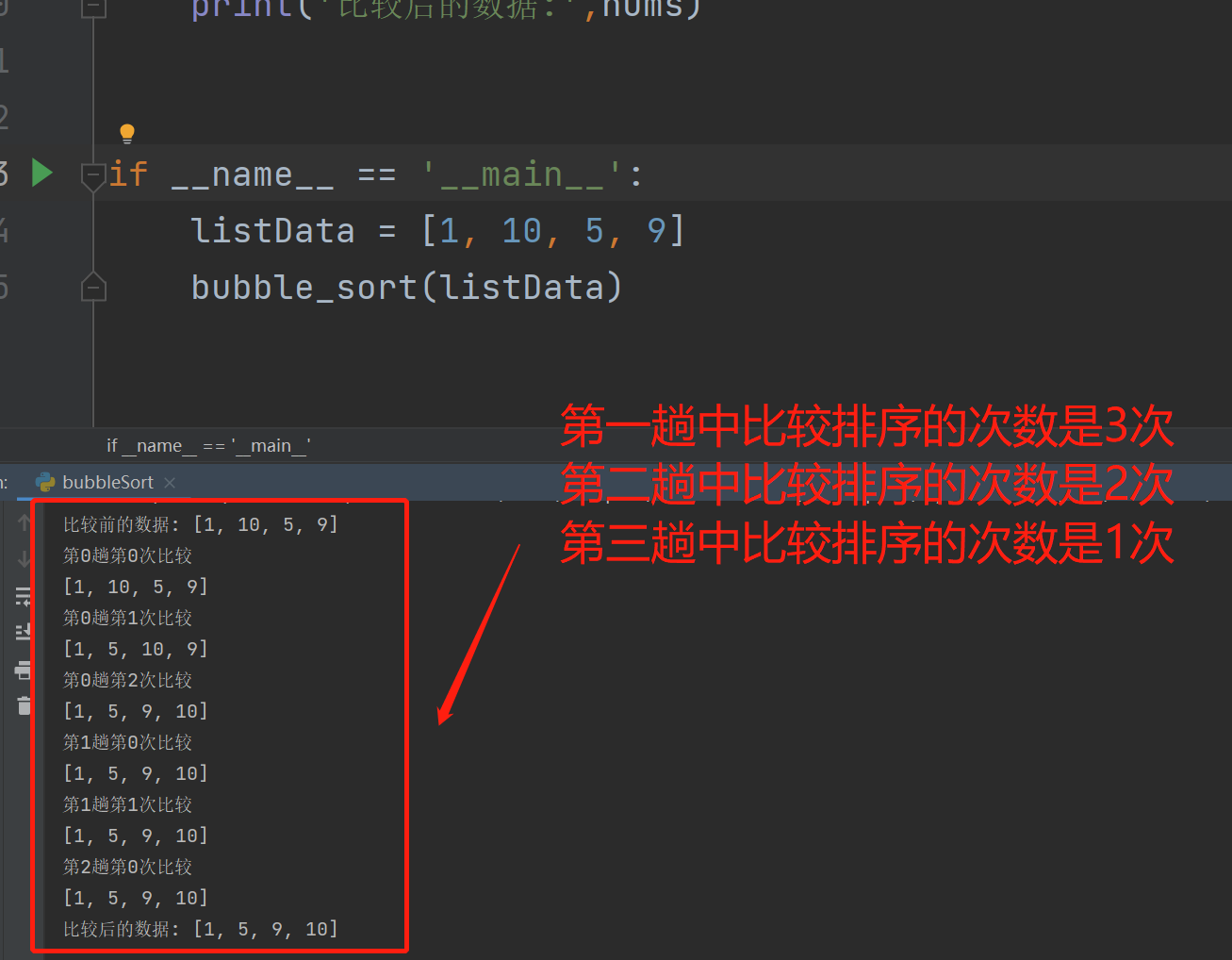
1、如果有5个数要排序,总共进行4趟排序:
(1)第一趟中比较排序的次数是3次。
(2)第二趟中比较排序的次数是2次。
(3)第三趟中比较排序的次数是1次。
运行程序:
2、还成多个数按照这个规律总结一下:N个数字要排序完成,总共进行N-1趟排序,每i趟的排序次数为(N-i)次。所以使用双重循环语句,外层控制循环多少趟,内层控制每一趟的比较次数。
3、优点:每进行一趟排序,就会少比较一次,因为每进行一趟排序都会找出一个较大值。如上例:第一趟比较之后,排在最后的一个数一定是最大的一个数,第二趟排序的时候,只需要比较除了最后一个数以外的其他的数,同样也能找出一个最大的数排在参与第二趟比较的数后面,第三趟比较的时候,只需要比较除了最后两个数以外的其他的数,以此类推,也就是说,每进行一趟比较,就少比较一次,一定程度上减少了运行次数。
4、时间复杂度
(1)如果我数据是正序,有n个数,只需要走一趟即可完成排序。所需的比较次数C和记录移动次数M均达到最小值,即:Cmin=n-1;Mmin=0;所以,冒泡排序最好的时间复杂度为O(n)。
(2)如果很不幸我们的数据是反序的,则需要进行n-1趟排序。每趟排序要进行n-i次比较(1≤i≤n-1),且每次比较都必须移动记录三次来达到交换记录位置。在这种情况下,比较和移动次数均达到最大值。

(3)冒泡排序总的平均时间复杂度为:O(n2) ,时间复杂度和数据状况无关
(4)借用一个图表示

其中稳定性的意思是:在比较的过程中,两个数在整个过程的位置前后关系不会发生任何变化,那么算法就是稳定的。
5、空间复杂度
算法的内存消耗可以通过空间复杂度来衡量,冒泡排序仅需要一个变量tmp来储存交换的数据,因此空间复杂度为 O(1),另外空间复杂度为 O(1) 的排序算法,也叫原地排序算法
五、代码改进
1、上面的冒泡排序算法在遇到有序的数列时,算法复杂度是O(n),也就是说1,2,3,4,5,6这样的一个有序数组,它仍然需要循环比较一次,这就浪费了时间和空间,所以需要做一些改进。
2、改进代码如下,其中bubble_sort_ex通过设置标志位先判断是否数列有序。
def bubble_sort(nums):
print('比较前的数据:',nums)
num = len(nums)
for i in range(len(nums) - 1):
for j in range(len(nums) - i - 1):
if nums[j] > nums[j + 1]:
nums[j], nums[j + 1] = nums[j + 1], nums[j]
print('第%d趟第%d次比较'%(i, j))
print(nums)
print('比较后的数据:',nums)
def bubble_sort_ex(nums):
for i in range(len(nums) - 1):
ex_flag = False # 设置一个交换标志位
for j in range(len(nums) - i - 1):
if nums[j] > nums[j + 1]:
nums[j], nums[j + 1] = nums[j + 1], nums[j]
ex_flag = True
if not ex_flag:
return nums # 已经有序了可以返回数据了
return nums
if __name__ == '__main__':
listData = [1, 10, 5, 9]
bubble_sort_ex(listData)














 1586
1586











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









