







散列表(也叫哈希表),是根据关键字值而直接进行访问的数据结构。
关于哈希表具体知识点介绍可以查看该博文:http://blog.csdn.net/learn_sunzhuli/article/details/47069567
本文采用除留余数法构造散列函数。
H(K) = (H(k) + i) % m; 其中i = 1, 2, …, m为哈希表大小。
本文采用拉链法处理冲突。
根据原始数组建立一个哈希表,哈希表为一个链表(一定要区分数组和链表),且要求哈希表有固定大小。
该方法将所有冲突的记录存储在一个链表中,并将这些链表的表头指针放在数组中。
衡量一个查找算法的指标是平均查找长度,在有冲突发生的情况下,用拉链法处理冲突比用开放地址法处理冲突,其平均查找长度要小。
可以参考以下图片,取H(K) = (H(k) + i) % 11 :
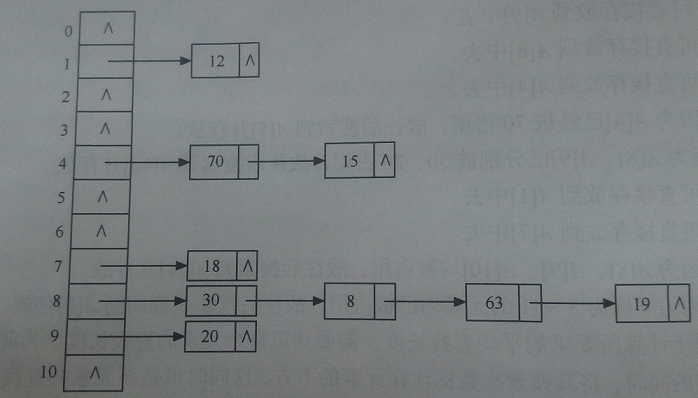
具体实现代码如下,在vs2010测试通过:
#include <iostream>
using namespace std;
void LinkedlistHashTableSearch(int arr[], int searchValue)
{
struct Node
{
int data;
Node* pNext;
};
const int tableSize = 10;
typedef Node* hashTable[tableSize];
hashTable table;
memset(table, 0, sizeof(table));//所有指针全部指向NULL
//插入
int nIndex;
for(int i = 0; i < tableSize; i++)
{
nIndex = arr[i] % tableSize;
if(NULL == table[nIndex])//找到空位
{
table[nIndex] = new Node;//必须新建结点
table[nIndex]->data = arr[i];
table[nIndex]->pNext = NULL;
}
else
{
while(NULL != table[nIndex]->pNext)//直到找到空位才退出循环
table[nIndex] = table[nIndex]->pNext;
table[nIndex]->pNext = new Node;//建立链表关系
table[nIndex]->pNext->data = arr[i];
table[nIndex]->pNext->pNext = NULL;
}
}
//查找
nIndex = searchValue % tableSize;
if(searchValue == table[nIndex]->data)
cout<<"Find the search value: "<<searchValue<<endl;
else
{
while(NULL != table[nIndex]->pNext)
{
table[nIndex] = table[nIndex]->pNext;
if(searchValue == table[nIndex]->data)
{
cout<<"Find the search value: "<<searchValue<<endl;
break;
}
}
cout<<"Fail to find the search value: "<<searchValue<<endl;
}
}
int _tmain(int argc, _TCHAR* argv[])
{
int arr[] = {1, 5, 2, 3, 6, 9, 8, 7, 0, 4, 120};
//链式哈希表查找
LinkedlistHashTableSearch(arr, 5);
LinkedlistHashTableSearch(arr, 10);
return 0;
}















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









