






文章目录
笔记-RAG
课程结构

为什么要用 RAG?

新增知识,尤其是高频变动且精确度要求高的知识,其实比较难通过微调的方式注入模型,而在模型的输入窗口中添加基于相关性的召回段落,能够比较有效地缓解这个问题。RAG 就是对一类方案的概括。
定义

工作原理
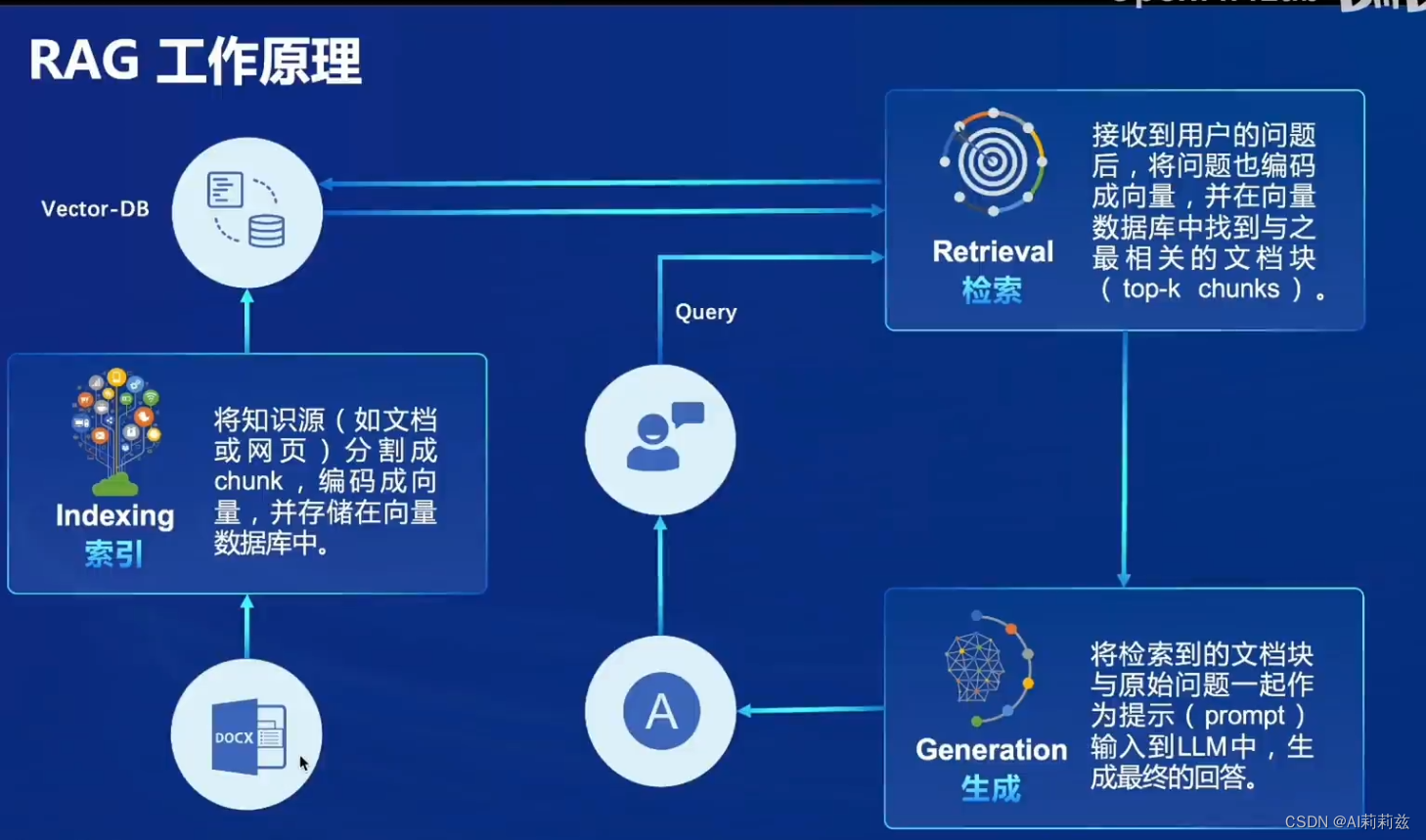
Indexing 部分,llamaIndex 是目前比较火的框架。
向量数据库
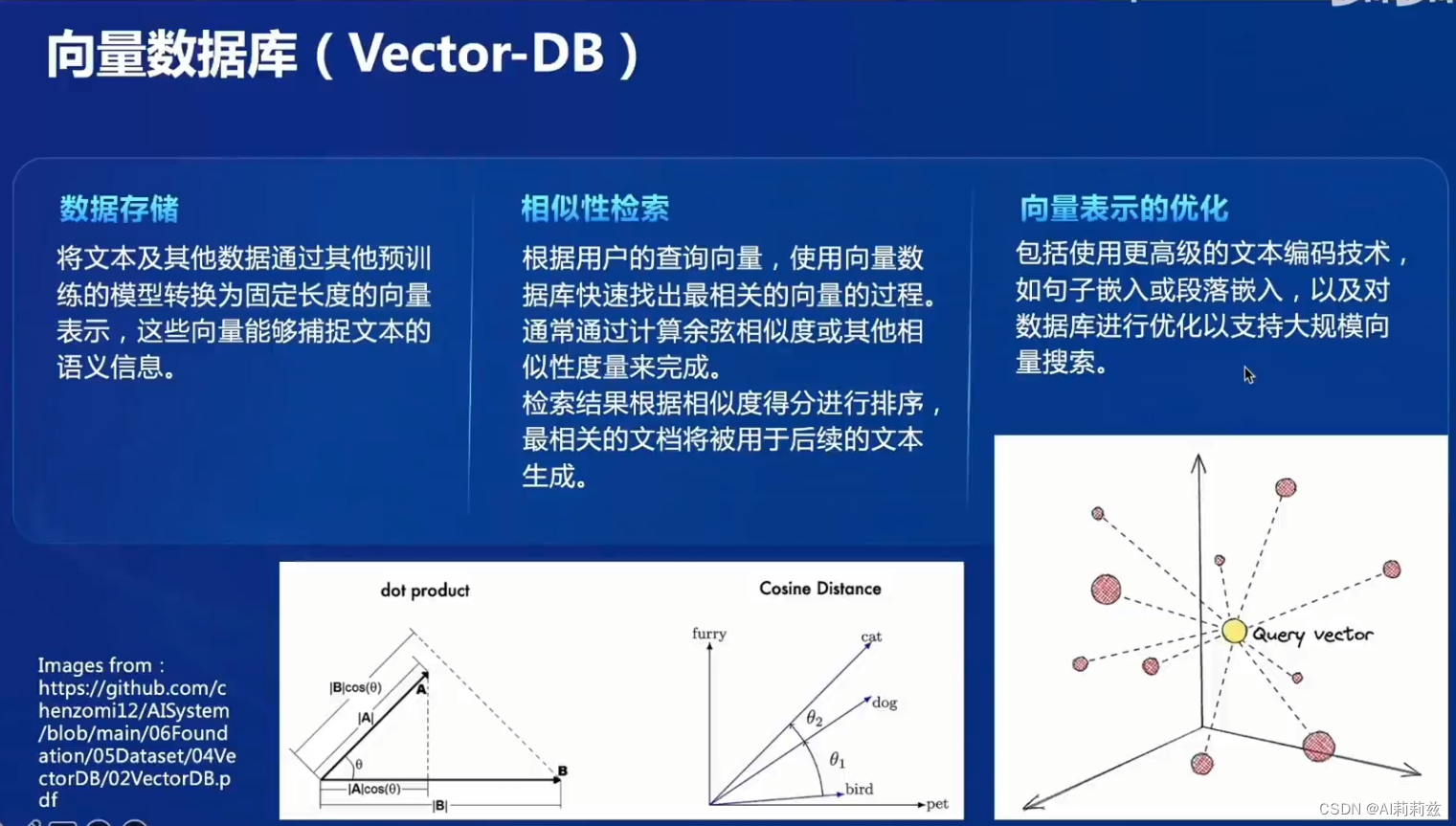
实践中召回部分一般需要基于 term + 基于表示的向量多路召回,尤其在一些医疗不充分、embedding 很难训好的领域,传统方法例如 BM25等等还是需要的。
RAG 工作流程
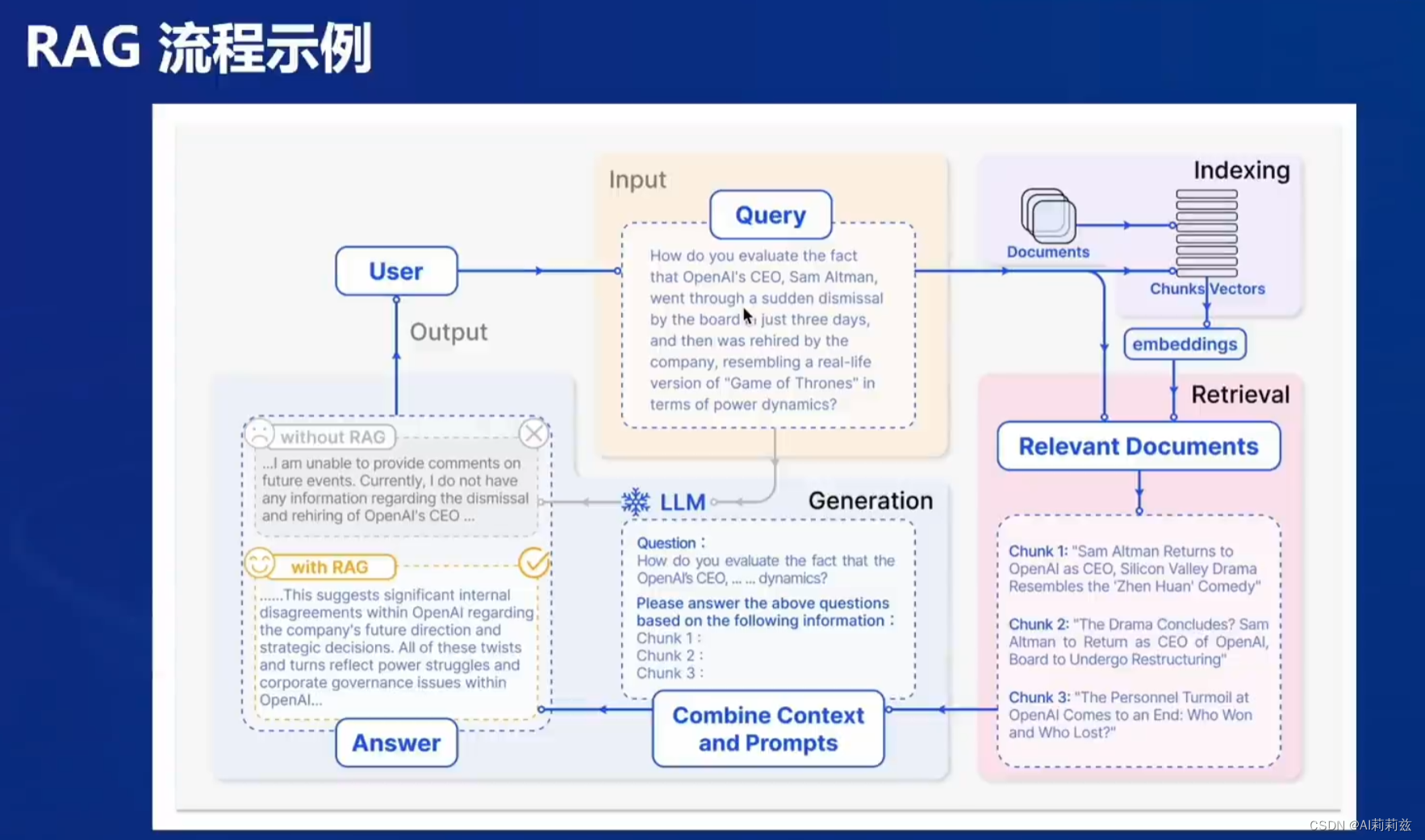
图上例子很典型,尤其具有时效性的事实性的信息,很难通过微调处理。
发展历程
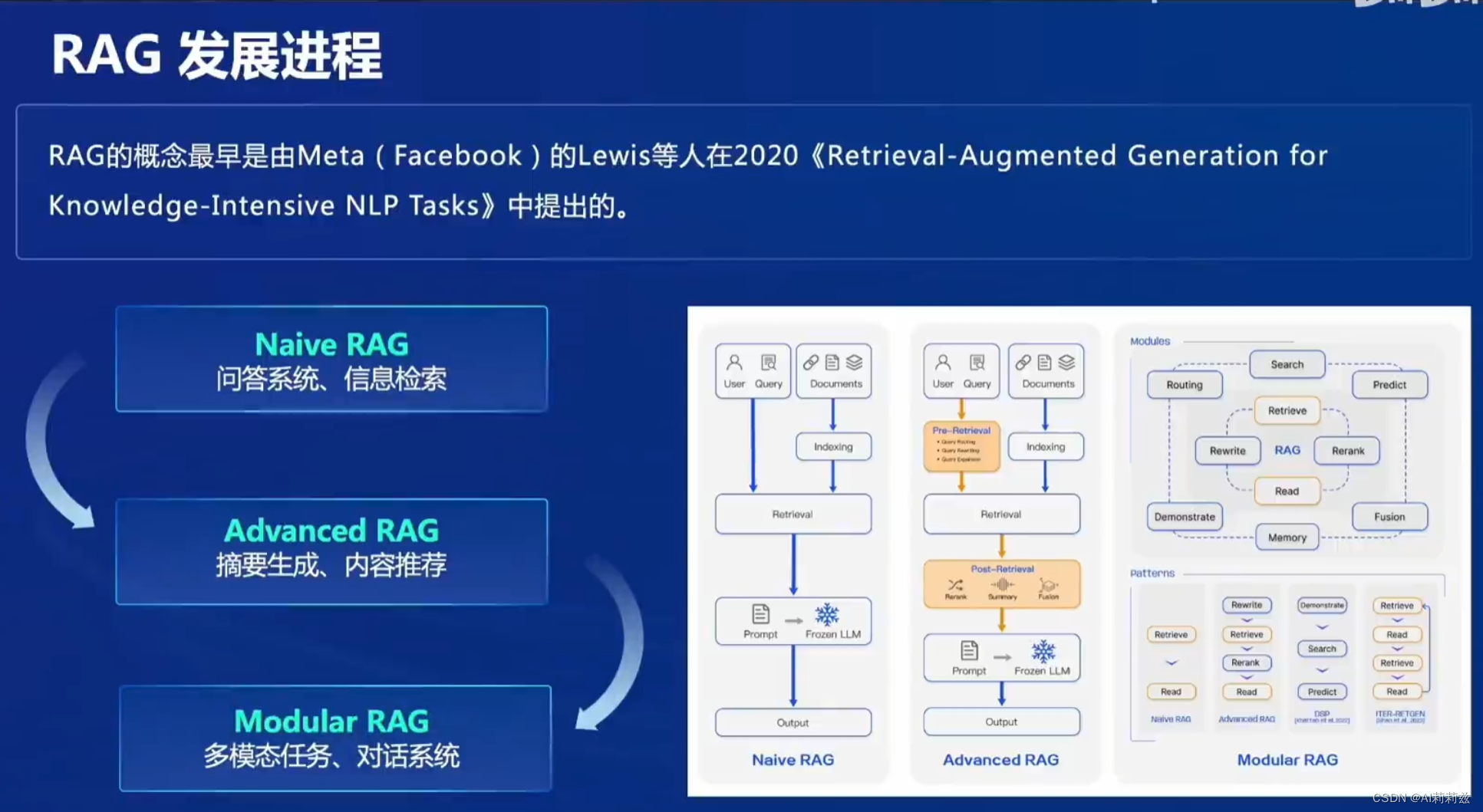
其实后面有点像之前的检索系统了,各个模块逐渐独立出来,分别优化。
常见优化

可以看到这里总结的 RAG 优化,主要优化部分放在了 R 的部分
RAG vs 微调

微调相对存在一些不可控情形,如果是信息密集且需要高保真度的场景,一般不推荐上来就做微调。
LLM 优化方法比较

这里的总结也挺全的,基本上生产环境开发,可以考虑这样的优化链路。
RAG的评价
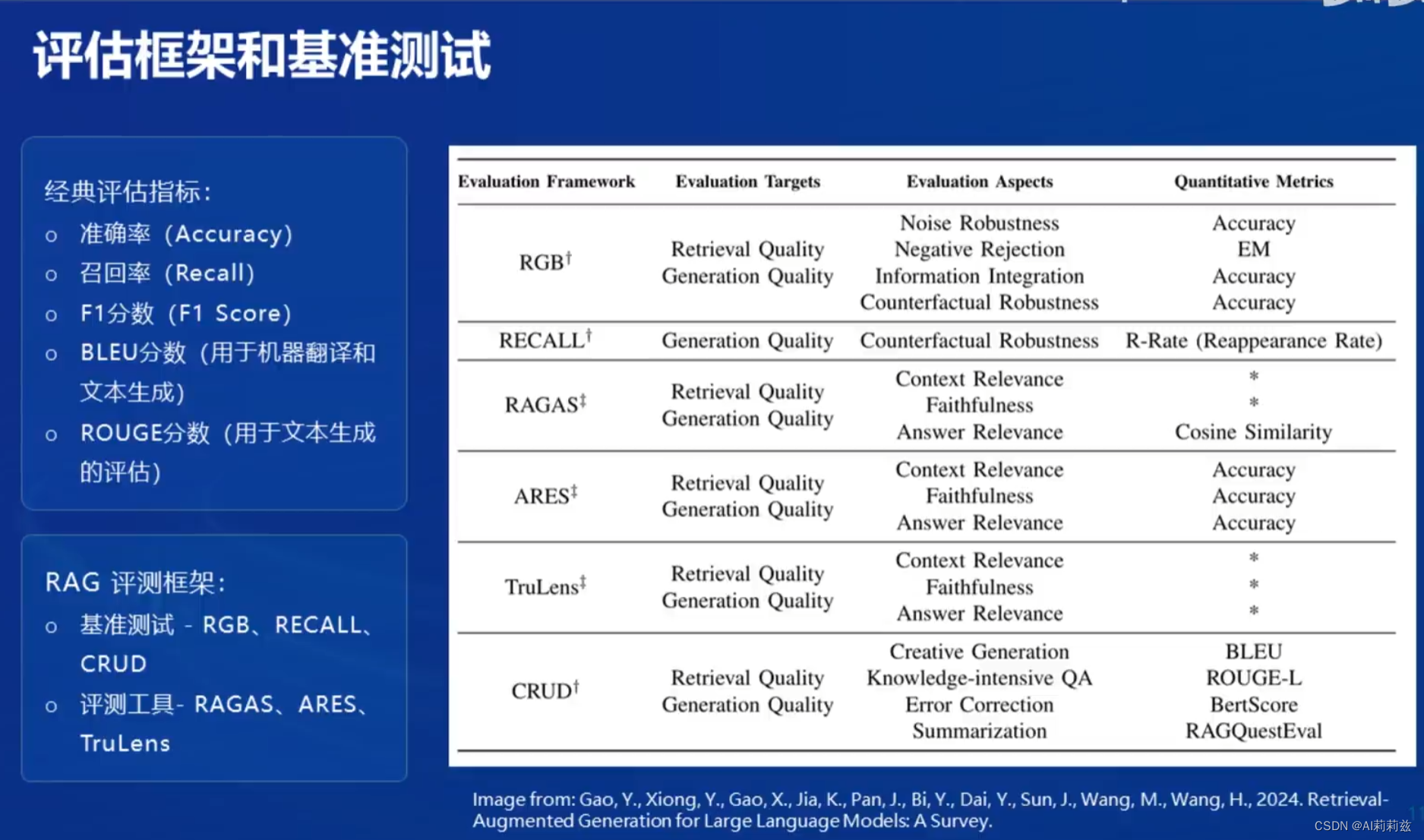
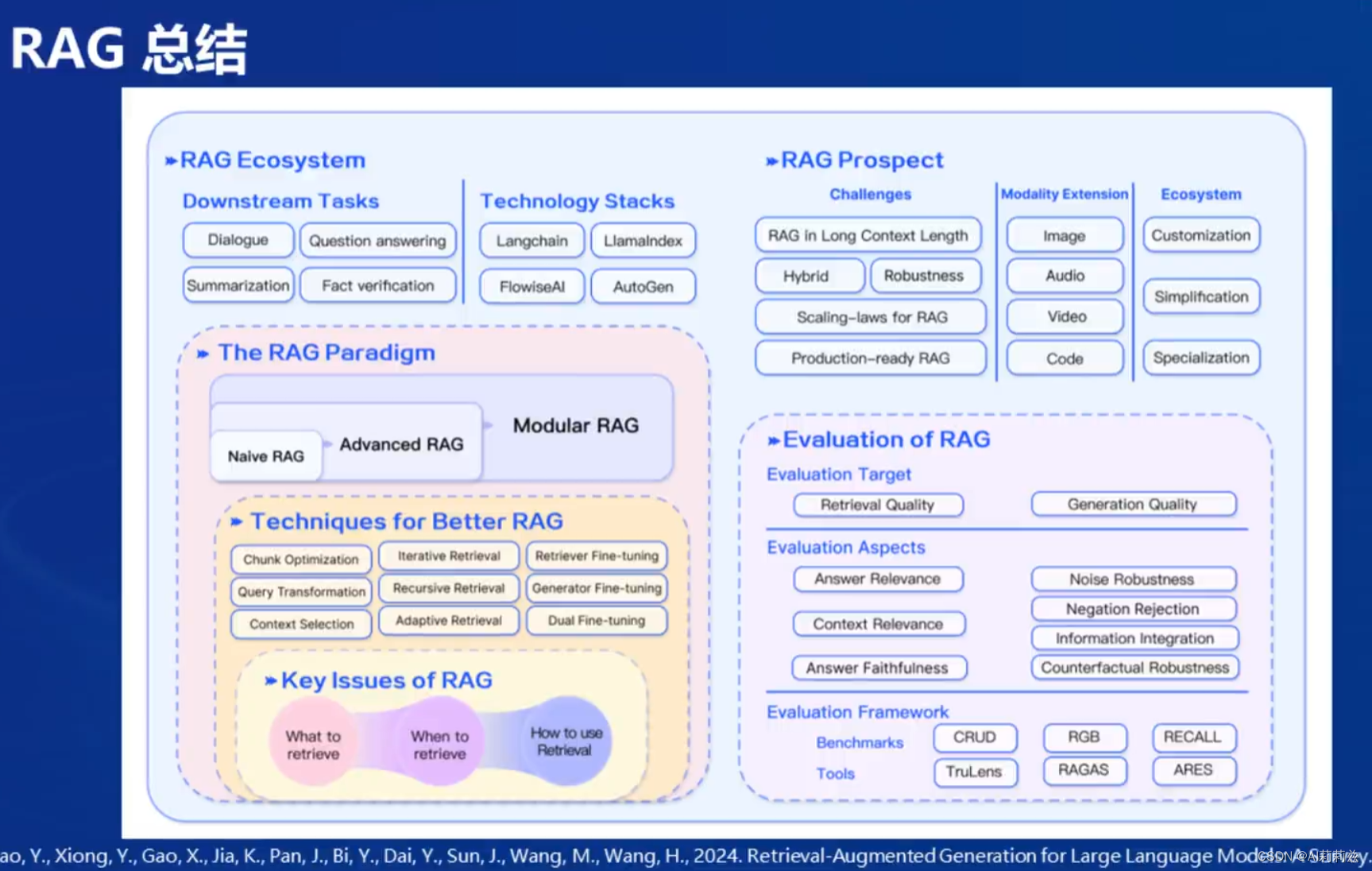
总结
笔记-茴香豆
什么是茴香豆

两篇技术报告写得很好,推荐开发者去读一下,很多问题并不是新问题,但在新技术场景下可以尝试不同的解决方案。

看来浦语对茴香豆的定位升级成平台性产品了。
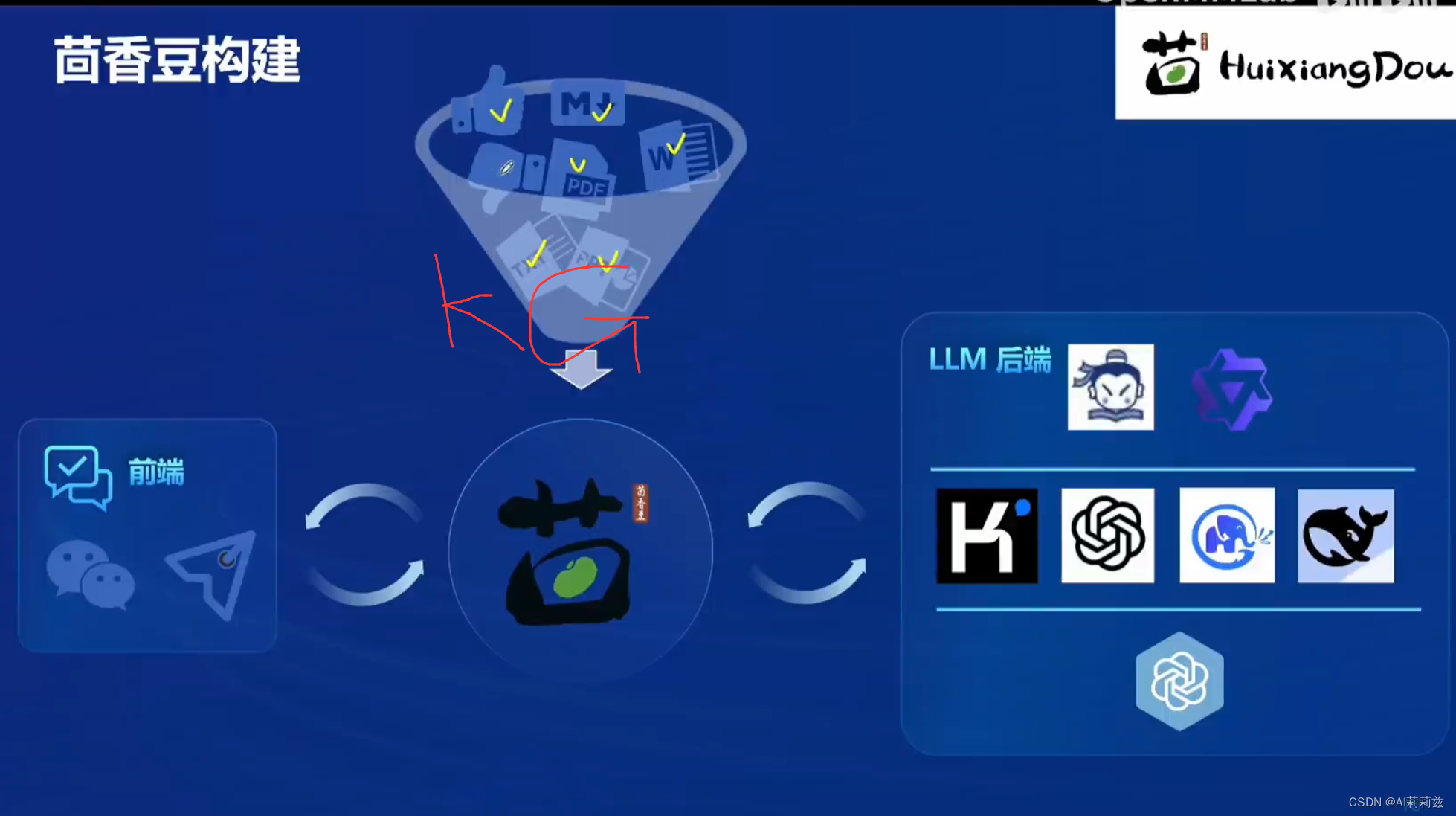
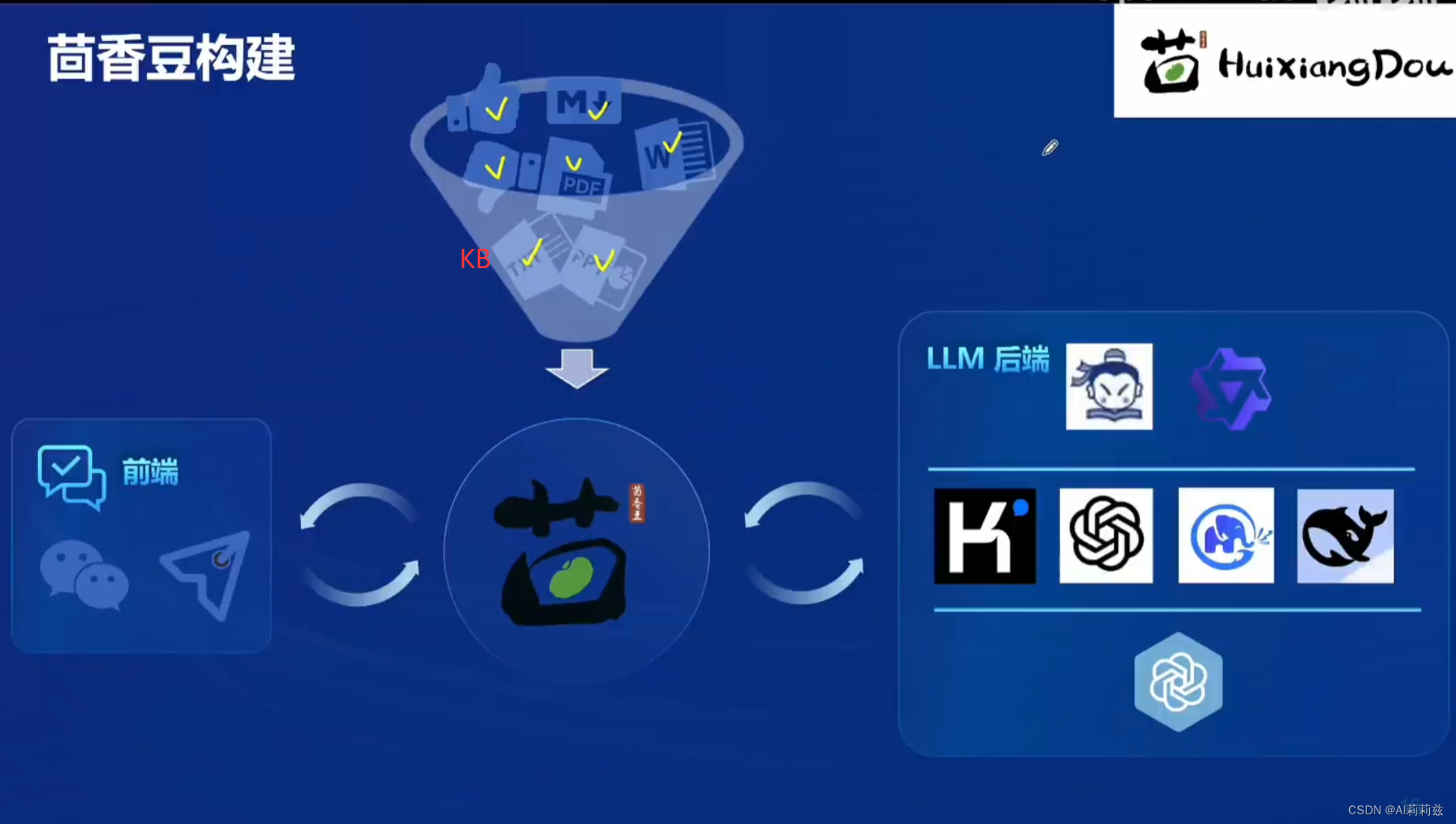
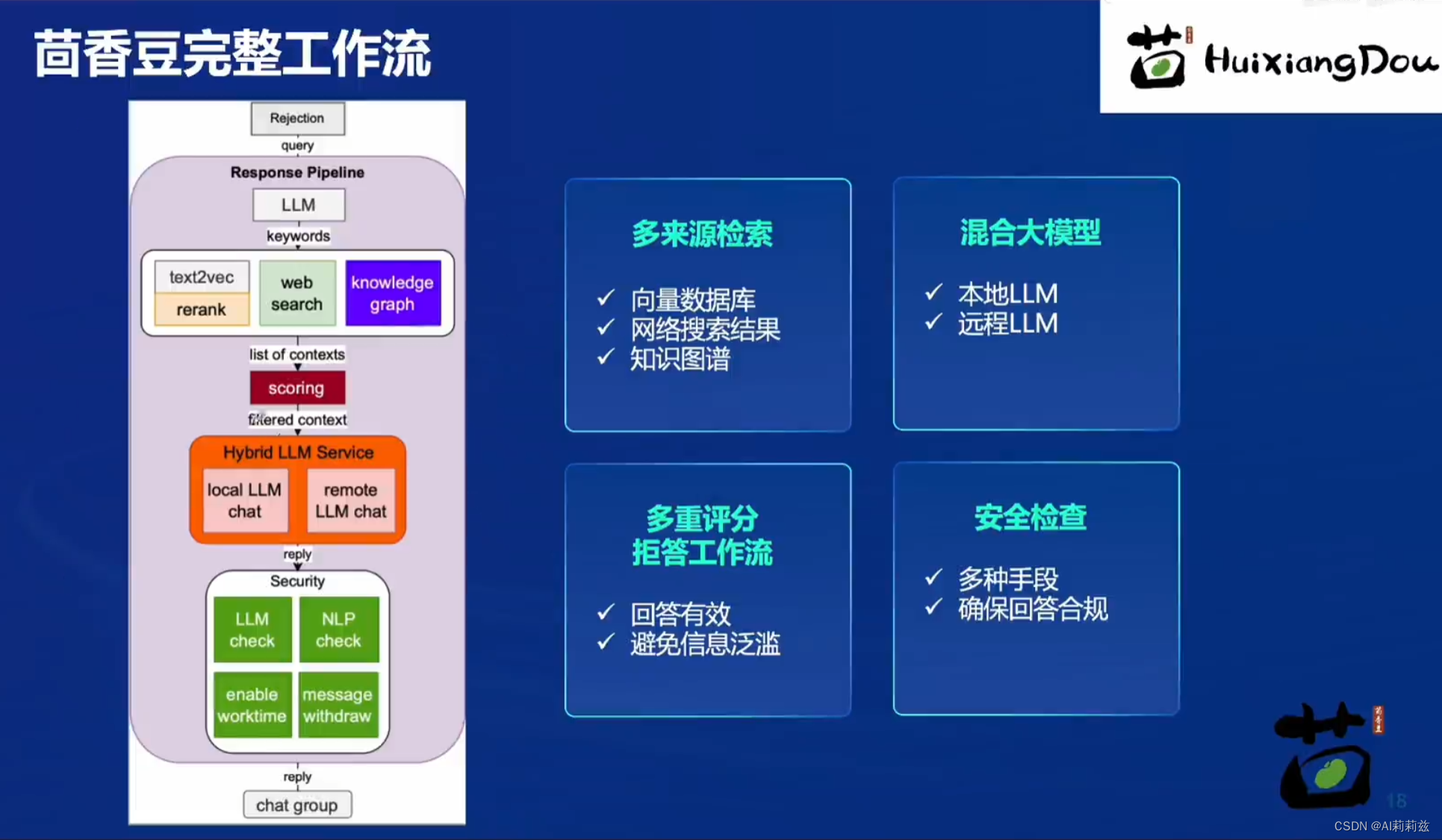
茴香豆实战
视频中视频,笑死。这是白牛老师的真声吗?
跟教程同步做部署,第一步又是要了命的准备环境。猜猜这次需要多久……
对了发现如果是配环境比较花时间,可以先启动一个算力点消耗更少的开发机,全部装完后再切换过去。
……一路按照教程运行至向量化
python3 -m huixiangdou.service.feature_store --sample ./test_queries.json
Traceback (most recent call last):
File "/root/.conda/envs/InternLM2_Huixiangdou/lib/python3.10/runpy.py", line 187, in _run_module_as_main
mod_name, mod_spec, code = _get_module_details(mod_name, _Error)
File "/root/.conda/envs/InternLM2_Huixiangdou/lib/python3.10/runpy.py", line 110, in _get_module_details
__import__(pkg_name)
File "/root/huixiangdou/huixiangdou/__init__.py", line 4, in <module>
from .service import ChatClient # noqa E401
File "/root/huixiangdou/huixiangdou/service/__init__.py", line 17, in <module>
from .web_search import WebSearch # noqa E401
File "/root/huixiangdou/huixiangdou/service/web_search.py", line 11, in <module>
from duckduckgo_search import DDGS
ModuleNotFoundError: No module named 'duckduckgo_search'
是教程没更新吗?安装这个包再试试,又出现了新的错误:
python3 -m huixiangdou.service.feature_store --sample ./test_queries.json
/root/.conda/envs/InternLM2_Huixiangdou/lib/python3.10/runpy.py:126: RuntimeWarning: 'huixiangdou.service.feature_store' found in sys.modules after import of package 'huixiangdou.service', but prior to execution of 'huixiangdou.service.feature_store'; this may result in unpredictable behaviour
warn(RuntimeWarning(msg))
Traceback (most recent call last):
File "/root/.conda/envs/InternLM2_Huixiangdou/lib/python3.10/runpy.py", line 196, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/root/.conda/envs/InternLM2_Huixiangdou/lib/python3.10/runpy.py", line 86, in _run_code
exec(code, run_globals)
File "/root/huixiangdou/huixiangdou/service/feature_store.py", line 531, in <module>
cache = CacheRetriever(config_path=args.config_path)
File "/root/huixiangdou/huixiangdou/service/retriever.py", line 220, in __init__
config = pytoml.load(f)['feature_store']
File "/root/.conda/envs/InternLM2_Huixiangdou/lib/python3.10/site-packages/pytoml/parser.py", line 11, in load
return loads(fin.read(), translate=translate, object_pairs_hook=object_pairs_hook, filename=getattr(fin, 'name', repr(fin)))
File "/root/.conda/envs/InternLM2_Huixiangdou/lib/python3.10/site-packages/pytoml/parser.py", line 43, in loads
error('duplicate_keys. Key "{0}" was used more than once.'.format(k))
File "/root/.conda/envs/InternLM2_Huixiangdou/lib/python3.10/site-packages/pytoml/parser.py", line 27, in error
raise TomlError(msg, pos[0], pos[1], filename)
pytoml.core.TomlError: config.ini(31, 1): duplicate_keys. Key "local_llm_path" was used more than once.
看来今天的探索要暂时告一段落了……
(续)
问题修复了。仔细跟踪了报错位置,是在执行教程命令时不知道什么原因产生了一些偏差,正确配置后可以正常运行:

测试效果


这就是回复内容了:

作业-部署一个茴香豆并测试
基线测试
安装网页界面依赖,输入教程中的命令启动交互:
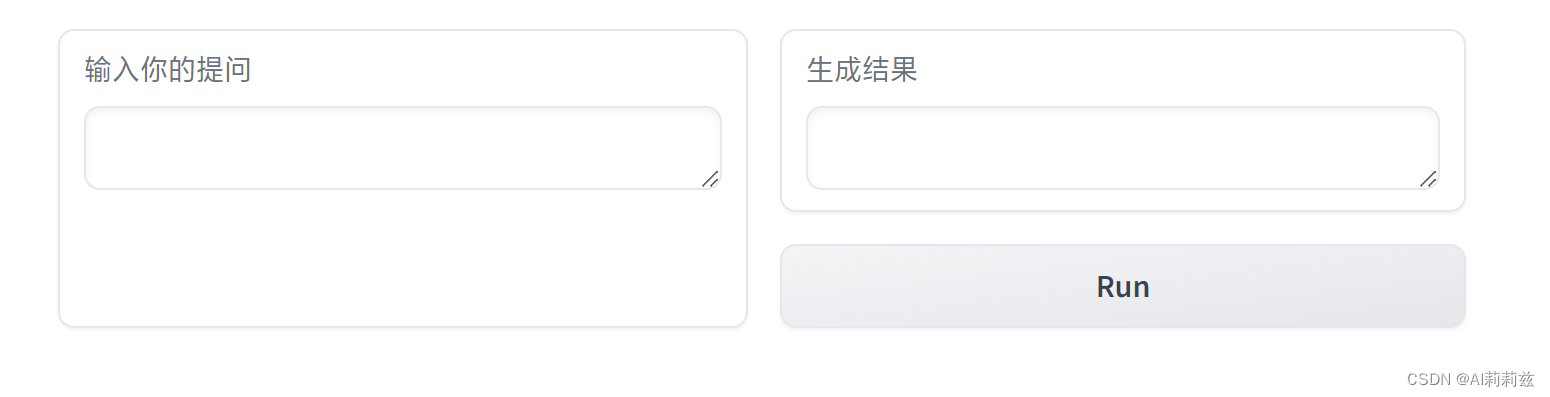
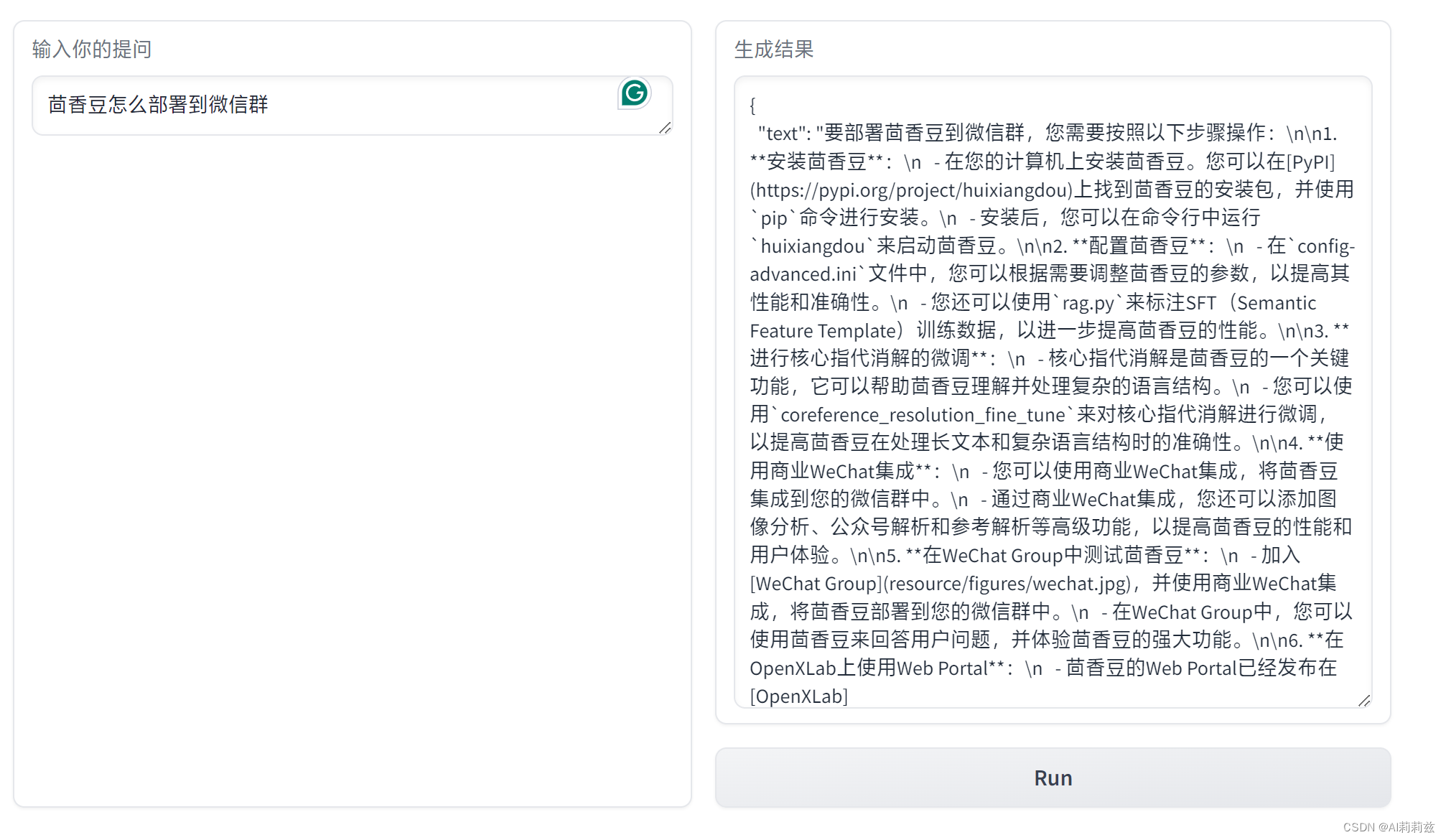
完整响应过程经过了差不多一分钟,看后台日志:
2024-05-29 21:19:49.885 | DEBUG | huixiangdou.service.llm_server_hybrid:generate_response:567 - Q:有主题的疑问句,结果用 0~10 表示。直接提供得分不要解释。
判断标准:有主语谓语宾语并且是疑问句得 10 分;缺少主谓宾扣分;陈述句直接得 0 分;不是疑问句直接得 0 分。直接提供得分不要解释 A:8.0
该句子是一个有主语、谓语和宾语的疑问句,主语是"茴香豆",谓语是"怎么部署",宾语是"到微信群"。虽然句子中没有使用"是"、"吗"等疑问词,但句子的结构符合疑问句的特征,因此得分8.0。 backend local timecost 3.2448830604553223
2024-05-29 21:19:50.181 | DEBUG | huixiangdou.service.llm_server_hybrid:generate_response:567 - Q:告诉我这句话的主题,不要丢失主语和宾语,直接说主题不要解释:“茴香豆怎么部署到微信群 A:主题:茴香豆的微信群部署。 backend local timecost 0.29328465461730957
2024-05-29 21:19:51.058 | DEBUG | huixiangdou.service.retriever:query:153 - retriever.docs [(Document(page_content=' <img alt="bilibili" src="https://img.shields.io/badge/bilibili-pink?logo=bilibili&logocolor=white" />\n</a>\n<a href="https://discord.gg/tw4zbpzz" target="_blank">\n<img alt="discord" src="https://img.shields.io/badge/discord-red?logo=discord&logocolor=white" />\n</a>\n<a href="https://arxiv.org/abs/2401.08772" target="_blank">\n<img alt="arxiv" src="https://img.shields.io/badge/arxiv-2401.08772%20-darkred?logo=arxiv&logocolor=white" />\n</a>\n</div> \n</div> \n茴香豆是一个基于 llm 的**群聊**知识助手,优势: \n1. 设计预处理、拒答、响应三阶段 pipeline 应对群聊场景,解答问题同时不会消息泛滥。精髓见论文 [2401.08772](https://arxiv.org/abs/2401.08772) 和 [2405.02817](https://arxiv.org/abs/2405.02817)\n2. 成本低至 1.5g 显存,无需训练适用各行业\n3. 提供一整套前后端 web、android、算法源码,工业级开源可商用', metadata={'source': 'README_zh.md', 'read': 'workdir/preprocess/repodir_huixiangdou_README_zh.md'}), 0.483950151469399)]
2024-05-29 21:20:08.390 | DEBUG | huixiangdou.service.llm_server_hybrid:generate_response:567 - Q:ing, and reference resolution”
请仔细阅读以上内容,判断问题和材料的关联度,用0~10表示。判断标准:非常相关得 10 分;完全没关联得 0 分。直接提供得分不要解释。 A:8分。材料提供了关于茴香豆的部署到微信群的方法,包括使用GPU内存、提高精度的配置、使用RAG.py进行数据标注、进行核心指代消解的微调,以及使用商业的WeChat集成进行图像分析、公众号解析和指代消解。这些问题都与茴香豆的部署有关,因此材料与问题有很高的相关度。 backend local timecost 2.5623831748962402
2024-05-29 21:20:28.033 | DEBUG | huixiangdou.service.llm_server_hybrid:generate_response:567 - Q:roup chat
- \[2024/05\] Add [Coreference Resolution fine-tune](.”
问题:“茴香豆怎么部署到微信群”
请仔细阅读参考材料回答问题 A:要部署茴香豆到微信群,您需要按照以下步骤操作:……
通过以上步骤,您就可以将茴香豆部署到微信群中,并使用其强大的功能来回答用户问题。请记得在使用茴香豆时,保持其低成本、高效率的特点,并根据需要进行配置和微调,以获得最佳效果。 backend local timecost 19.640525102615356
05/29/2024 21:20:28 - [INFO] -aiohttp.access->>> 127.0.0.1 [29/May/2024:21:20:08 +0800] "POST /inference HTTP/1.1" 200 4492 "-" "python-requests/2.31.0"
2024-05-29 21:20:28.255 | DEBUG | huixiangdou.service.llm_server_hybrid:generate_response:567 - Q:。
判断标准:准确回答问题得 0 分;答案详尽得 1 分;知道部分答案但有不确定信息得 8 分;知道小部分答案但推荐求助其他人得 9 分;不知道任何答案直接推荐求助别人得 10 分。直接打分不要解释 A:8 backend local timecost 0.21931719779968262
2024-05-29 21:20:28.581 | DEBUG | huixiangdou.service.llm_server_hybrid:generate_response:567 - Q:string, 内容是短语或关键字,以空格分隔。
你现在是交流群里的助手,用户问“茴香豆怎么部署到微信群”,你打算通过谷歌搜索查询相关资料,请提供用于搜索的关键字或短语,不要解释直接给出关键字或短语 A:"茴香豆 微信小程序 部署" backend local timecost 0.3217043876647949
可以看到日志中最花时间的是 RAG 中的 G 环节,耗时19秒左右,其他环节都在一两秒内完成。但实际体感长很多,可能是日志不全或没有正常记录(例如调用搜索 API 超时),因此性能上也存在一些优化空间。
另外从日志来看,似乎 internLM7B 的指令遵循有些问题:
请仔细阅读以上内容,判断问题和材料的关联度,用0~10表示。判断标准:非常相关得 10 分;完全没关联得 0 分。直接提供得分不要解释。 A:8分。材料提供了关于茴香豆的部署到微信群的方法,包括使用GPU内存、提高精度的配置、使用RAG.py进行数据标注、进行核心指代消解的微调,以及使用商业的WeChat集成进行图像分析、公众号解析和指代消解。这些问题都与茴香豆的部署有关,因此材料与问题有很高的相关度。 backend local timecost 2.5623831748962402
这行日志显示,模型没有完全按照要求的“直接提供得分不要解释”执行,而是在打分后做了解释,导致额外产生2.5s的延时。
Query理解力测试
时间有限,只做一点简单的泛化性测试,看理解+召回效果如何。仍然是“茴香豆怎么部署到微信群?”的语意,我们改写几个版本:
茴香豆 部署到微信群
huixiangdou 怎么在微信群里部署
在微信群部署茴香豆
怎么在微信群里部署茴香豆?
茴香豆 部署到微信群
模型经过判断选择拒答;InternLM 判断这句话不是疑问句:
2024-05-29 22:00:31.471 | DEBUG | huixiangdou.service.llm_server_hybrid:generate_response:567 - Q:有主题的疑问句,结果用 0~10 表示。直接提供得分不要解释。
判断标准:有主语谓语宾语并且是疑问句得 10 分;缺少主谓宾扣分;陈述句直接得 0 分;不是疑问句直接得 0 分。直接提供得分不要解释 A:0 backend local timecost 0.06922268867492676
05/29/2024 22:00:31 - [INFO] -aiohttp.access->>> 127.0.0.1 [29/May/2024:22:00:31 +0800] "POST /inference HTTP/1.1" 200 184 "-" "python-requests/2.31.0"
2024-05-29 22:00:31.472 | DEBUG | huixiangdou.service.worker:generate:511 - {'PreprocNode_is_question': {'input': '“茴香豆 部署到微信群”\n请仔细阅读以上内容,判断句子是否是个有主题的疑问句,结果用 0~10 表示。直接提供得分不要解释。\n判断标准:有主语谓语宾语并且是疑问句得 10 分;缺少主谓宾扣分;陈述句直接得 0 分;不是疑问句直接得 0 分。直接提供得分不要解释。', 'default': 3, 'relation': '0', 'throttle': 6, 'output': 0}}
huixiangdou 怎么在微信群里部署
仍然拒答,原因相同:

这里其实开始有点不符合预期了,继续第三个测试case
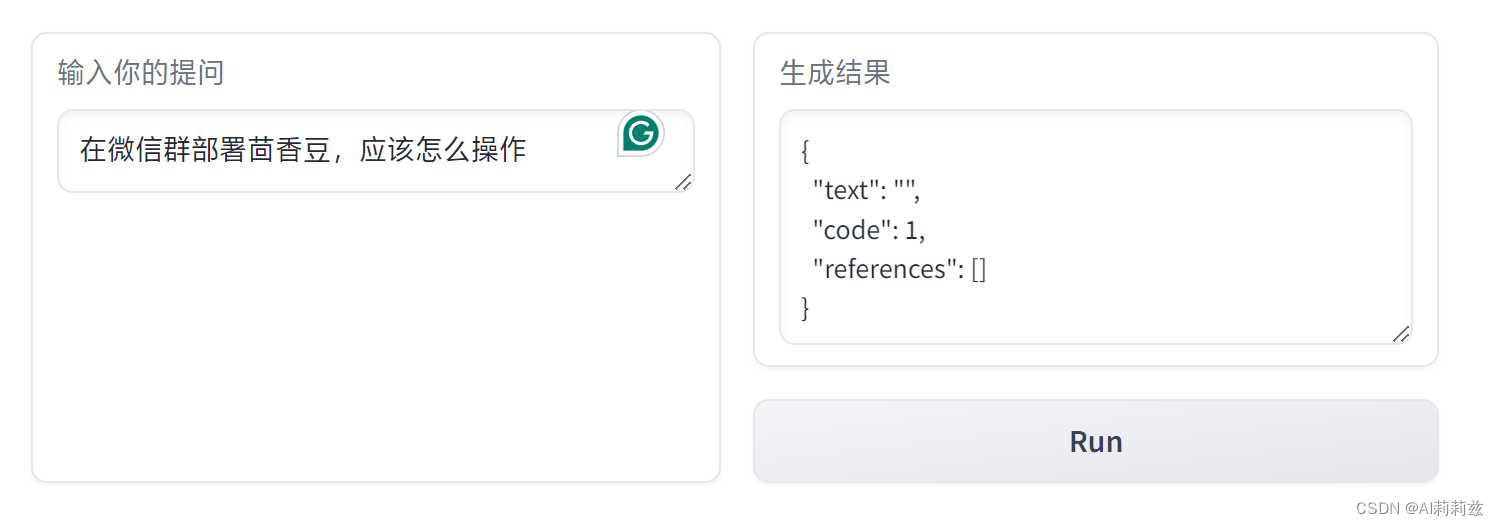
在微信群部署茴香豆,应该怎么操作
仍然拒答:
怎么在微信群里部署茴香豆?
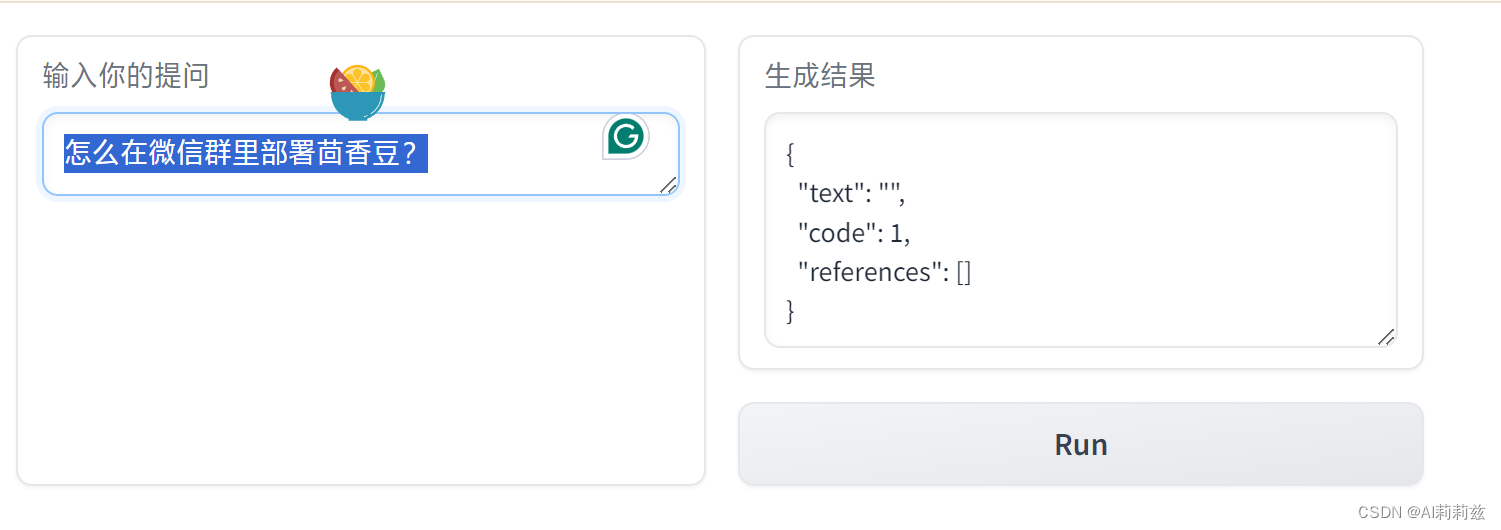
啊?
2024-05-29 22:23:21.496 | DEBUG | huixiangdou.service.llm_server_hybrid:generate_response:567 - Q:有主题的疑问句,结果用 0~10 表示。直接提供得分不要解释。
判断标准:有主语谓语宾语并且是疑问句得 10 分;缺少主谓宾扣分;陈述句直接得 0 分;不是疑问句直接得 0 分。直接提供得分不要解释 A:根据判断标准,该句子的得分是 0。
这句话的构成不符合有主语、谓语和宾语的完整句式,且它不是以疑问词(如“是”、“吗”、“呢”等)作为疑问句的开头,因此它不是一个有主题的疑问句。同时,该句子也不像陈述句,因为它的语义不明确,且没有提供任何具体信息。所以,该句得分为 0。 backend local timecost 2.9991250038146973
再次改写,终于可以正常运行了:
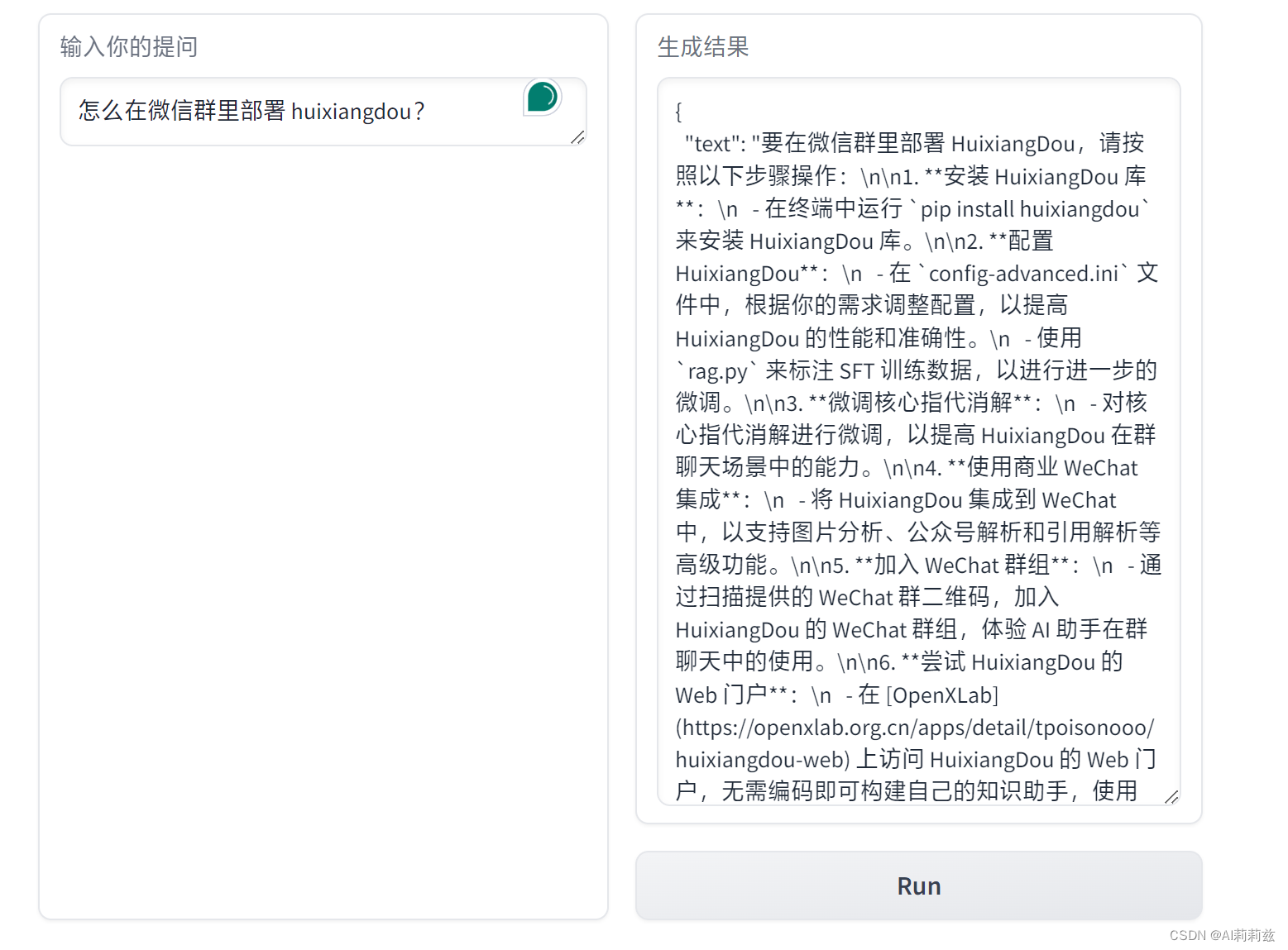
看起来是第一步的疑问句检查存在问题,似乎 InternLM 7B 不理解“茴香豆”和“部署”之间的关系,从而认为这不是一句正常的表达。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









