







代码随想录系列文章目录
动态规划 - 01背包
01背包问题
有n件物品和一个最多能背重量为w 的背包。第i件物品的重量是weight[i],得到的价值是value[i] 。每件物品只能用一次,求解将哪些物品装入背包里物品价值总和最大。
每一件物品其实只有两个状态,取或者不取,所以可以使用回溯法搜索出所有的情况,那么时间复杂度就是
o
(
2
n
)
o(2^n)
o(2n),这里的n表示物品数量。
所以暴力的解法是指数级别的时间复杂度。进而才需要动态规划的解法来进行优化!
二维dp数组
-
状态定义
dp[i][j], 是表示从下标为[0-i]的物品里任意取,放进容量为j的背包,价值总和最大是多少。 -
状态转移
不放物品i:由dp[i - 1][j]推出,即背包容量为j,里面不放物品i的最大价值,此时dp[i][j]就是dp[i - 1][j]。(其实就是当物品i的重量大于背包j的重量时,物品i无法放进背包中,所以被背包内的价值依然和前面相同。)放物品i:由dp[i - 1][j - weight[i]]推出,dp[i - 1][j - weight[i]] 为背包容量为j - weight[i]的时候不放物品i的最大价值,那么dp[i - 1][j - weight[i]] + value[i] (物品i的价值),就是背包放物品i得到的最大价值
所以状态转移公式就是 dp[i][j] = max(dp[i-1][j], dp[i-1][j-weight[i]]+value[i])
-
base case
首先从dp[i][j]的定义出发,如果背包容量j为0的话,即dp[i][0],无论是选取哪些物品,背包价值总和一定为0。如图:
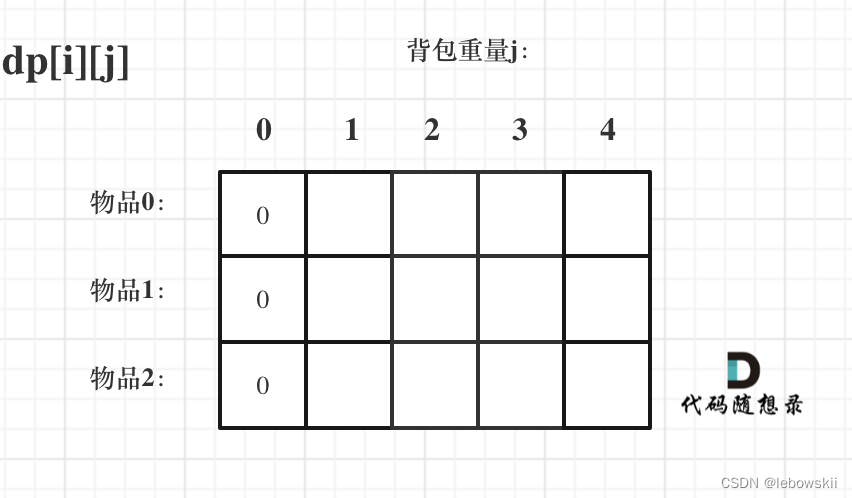
再看其他情况。状态转移方程 dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]); 可以看出i 是由 i-1 推导出来,那么i为0的时候就一定要初始化。
dp[0][j],即:i为0,存放编号0的物品的时候,各个容量的背包所能存放的最大价值。那么很明显当 j < weight[0]的时候,dp[0][j] 应该是 0,因为背包容量比编号0的物品重量还小。
当j >= weight[0]时,dp[0][j] 应该是value[0],因为背包容量放足够放编号0物品。
那么如果我们一开始就给dp数组初始化为0,我们不用去初始化dp[i][0].
for j in range(weight[0], bagweight+1): dp[0][j] = value[0]此时dp数组初始化情况如图所示
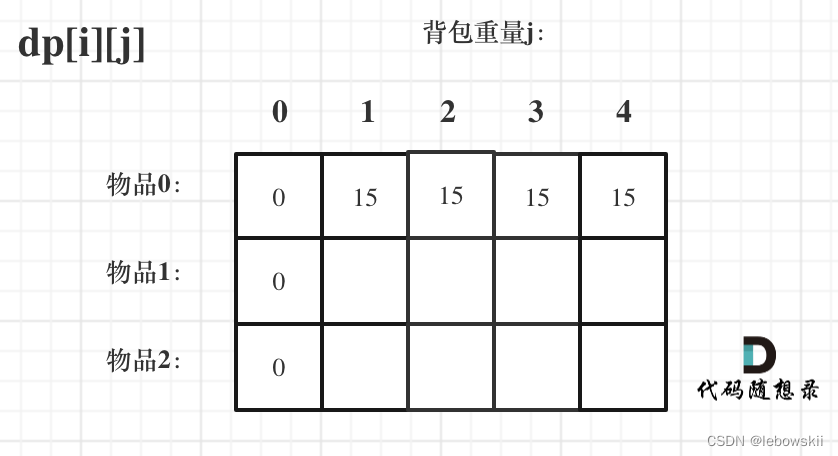
从递归公式: dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]); 可以看出dp[i][j] 是由左上方数值推导出来了,那么 其他下标初始为什么数值都可以,因为都会被覆盖。所以其它都初始化为0 -
遍历顺序和解的所在
有两个遍历的维度:物品与背包重量。先遍历谁都可以,但是一般先遍历物体for i in range(1, n): for j in range(0, bagweight+1): if j < weight[i]: dp[i][j] = dp[i-1][j] else: dp[i][j] = max(dp[i-1][j], dp[i-1][j-weight[i]]+value[i])如果假设有n个物品,最大重量是m ,解应该在dp[n-1][m]
因为定义是,从下标0 -> n-1的物品里选,放进容积为m的背包,最大价值是多少
一维dp数组(滚动数组)
对于背包问题其实状态都是可以压缩的。在使用二维数组的时候,递推公式:dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]);
其实可以发现如果把dp[i - 1]那一层拷贝到dp[i]上,表达式完全可以是:dp[i][j] = max(dp[i][j], dp[i][j - weight[i]] + value[i]);
与其把dp[i - 1]这一层拷贝到dp[i]上,不如只用一个一维数组了,只用dp[j](一维数组,也可以理解是一个滚动数组)。
这就是滚动数组的由来,需要满足的条件是上一层可以重复利用,直接拷贝到当前层。
1.状态定义
在一维dp数组中,dp[j]表示:容量为j的背包,所背的物品价值可以最大为dp[j]。
2.状态转移
一个是取自己dp[j] 相当于 二维dp数组中的dp[i-1][j],即不放物品i,一个是取dp[j - weight[i]] + value[i],即放物品i,指定是取最大的,毕竟是求最大价值,
dp[j] = max(dp[j], dp[j - weight[i]] + value[i])
3.base case
dp[j]表示:容量为j的背包,所背的物品价值可以最大为dp[j],那么dp[0]就应该是0,因为背包容量为0所背的物品的最大价值就是0。其余的位置也初始化为0就行
4.遍历顺序以及解的位置
二维dp遍历的时候,背包容量是从小到大,而一维dp遍历的时候,背包是从大到小。
为什么呢?
倒序遍历是为了保证物品i只被放入一次!。但如果一旦正序遍历了,那么物品0就会被重复加入多次!
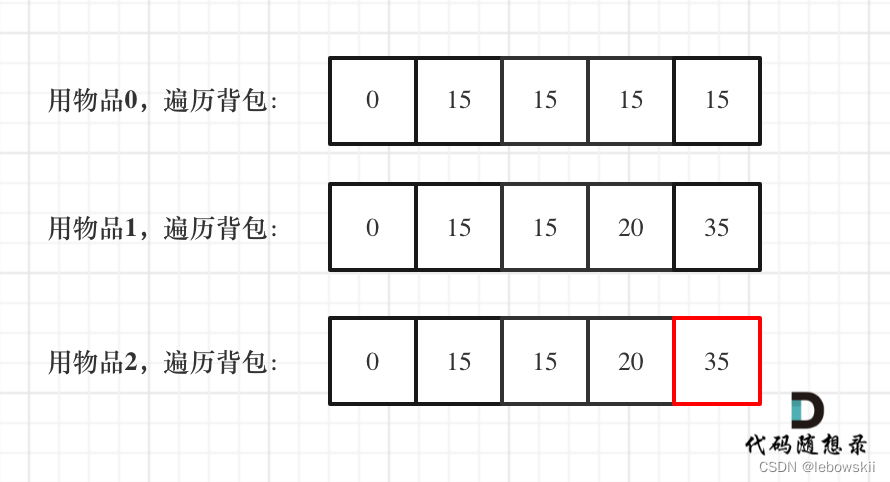
举一个例子:物品0的重量weight[0] = 1,价值value[0] = 15
如果正序遍历
dp[1] = dp[1 - weight[0]] + value[0] = 15
dp[2] = dp[2 - weight[0]] + value[0] = 30
此时dp[2]就已经是30了,意味着物品0,被放入了两次,所以不能正序遍历。
为什么倒序遍历,就可以保证物品只放入一次呢?
倒序就是先算dp[2]
dp[2] = dp[2 - weight[0]] + value[0] = 15 (dp数组已经都初始化为0)
dp[1] = dp[1 - weight[0]] + value[0] = 15
所以从后往前循环,每次取得状态不会和之前取得状态重合,这样每种物品就只取一次了。
那么问题又来了,为什么二维dp数组历的时候不用倒序呢?
因为对于二维dp,dp[i][j]都是通过上一层即dp[i - 1][j]计算而来,本层的dp[i][j]并不会被覆盖!
再来看看两个嵌套for循环的顺序,代码中是先遍历物品嵌套遍历背包容量,那可不可以先遍历背包容量嵌套遍历物品呢?
不可以!
因为一维dp的写法,背包容量一定是要倒序遍历(原因上面已经讲了),如果遍历背包容量放在上一层,那么每个dp[j]就只会放入一个物品,即:背包里只放入了一个物品。
倒序遍历的原因是,本质上还是一个对二维数组的遍历,并且右下角的值依赖上一层左上角的值,因此需要保证左边的值仍然是上一层的,从右向左覆盖。
# n, m 物品个数, 容积
dp = [0] * (m+1)
for i in range(0, n):
for j in range(m, weight[i]-1, -1):
dp[j] = max(dp[j], dp[j - weight[i]] + value[i])
416.分割等和子集
题目链接
这道题为什么能转化为 01背包问题
首先,本题要求集合里能否出现总和为 sum / 2 的子集
只有确定了如下四点,才能把01背包问题套到本题上来。
背包的体积为sum / 2
背包要放入的商品(集合里的元素)重量为 元素的数值,价值也为元素的数值
背包如果正好装满,说明找到了总和为 sum / 2 的子集。
背包中每一个元素是不可重复放入。
1.状态定义
dp[j], 容量为j的背包,所背的物品价值可以最大为dp[j]
2.状态转移
dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
3.base case
初始化为0,如果如果题目给的价值都是正整数那么非0下标都初始化为0就可以了,如果题目给的价值有负数,那么非0下标就要初始化为负无穷。
我们要找数组之和的一半,数据范围是数组长度 <=200, 每个元素小于等于100
那么数组初始化dp = [0]* 10001
4.遍历顺序以及解的位置
01背包的一维dp,应该是正序遍历物体,反序遍历容积
解的位置
dp[j]的数值一定是小于等于j的。
如果dp[j] == j 说明,集合中的子集总和正好可以凑成总和j,理解这一点很重要。
class Solution:
def canPartition(self, nums: List[int]) -> bool:
dp = [0] * 10001
if sum(nums) % 2 != 0: return False
target = sum(nums) // 2
for i in range(0, len(nums)):
for j in range(target, nums[i]-1, -1):
dp[j] = max(dp[j], dp[j-nums[i]]+nums[i])
return dp[target] == target















 226
226











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









