






word2vec中的CBOW模型
简介
word2vec是Google与2013年开源推出的一个用于获取word vecter的工具包,利用神经网络为单词寻找一个连续向量看空间中的表示。
word2vec有两种网络模型,分别为:
- Continous Bag of Words Model (CBOW)
- Skip-Gram Model
CBOW网络模型
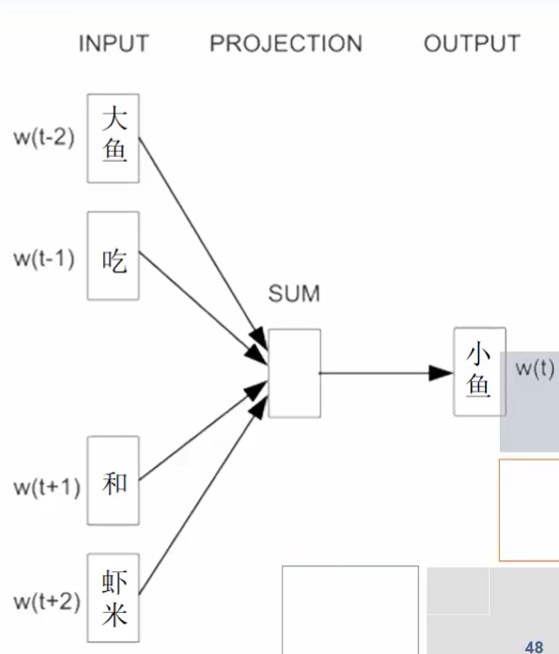
使用上下文的词汇来同时预测中间词
- 滑动时使用双向上下文窗口
- 输入层:仍然直接使用BOW(词袋)方式表示
- 投射层:
- 对向量直接求和(或求平均),以降低向量维度
- 实质上是去掉了投射层
- 隐含层:直接去除(输入信号量直接求和,映射到输出层)
- 输出层:
- 输出层为一棵二叉树,以词库中的词作为叶子结点,并以词频为权重构造出来的Huffman树,如果词库中有D个词,则有D个叶子结点。
- 实质上只是一个线性分类器
- 显然,短语料不适合用word2vec来分析,运算量仍然很大。
降低运算量:分层softmax

降低运算量:负例采样

Word2Vec仍然存在的问题

CBOW模型流程举例
假设 Courpus = { I drik coffee everyday } ,根据 “I”“drink”“everyday”来预测“coffee”。



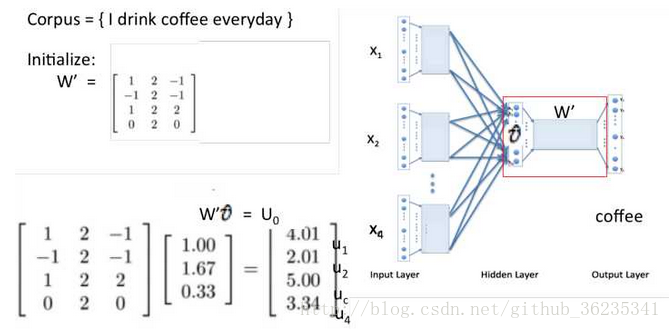
投影层将每个词向量加起来,
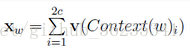
这里Xw即上图Uo ,当Xw传导到输出层时,因为输出层为一棵二叉树,每一次分支都可视为进行一次二分类,将分到左边为负类,分到右边为正类。
根据sigmoid函数,可将二分类函数写成:
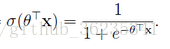
所以,一个结点被分到正类的概率是:

被分到负类的概率是:

这里Θ向量是待定参数。
将每个分支的概率相乘就是所需的 P( W | Context(W) )

对概率函数取对数,即
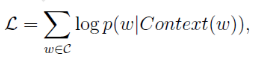
并对式子求 Xw的偏导 和 Θ 的偏导。
最终,通过大量的数据迭代,使用梯度下降更新W和W’,来最小化loss函数,训练结束后的W就是词向量的矩阵,任何一个单词的One-Hot表示乘以这个矩阵W就可以得到其词向量的表示。
















 8258
8258











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









