







 CBOW是一种用于生成词向量的模型,它通过上下文窗口预测目标词。输入层使用One-hot编码,隐藏层通过平均输入词向量得到隐藏层向量,再通过输出层的softmax分类器预测目标词的概率。CBOW模型常用于自然语言处理中的词嵌入技术。
CBOW是一种用于生成词向量的模型,它通过上下文窗口预测目标词。输入层使用One-hot编码,隐藏层通过平均输入词向量得到隐藏层向量,再通过输出层的softmax分类器预测目标词的概率。CBOW模型常用于自然语言处理中的词嵌入技术。
CBOW介绍
CBOW分为输入层 Input layer 、隐藏层 Hidden layer 、输出层 Output layer 。
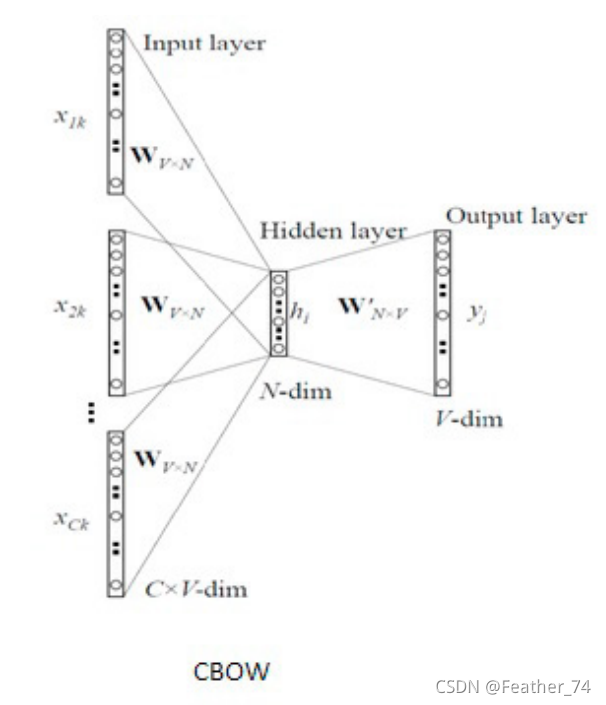
一、输入层 Input layer
1、输入的是 One-hot 编码的 vector 。
什么是 One-hot 编码?
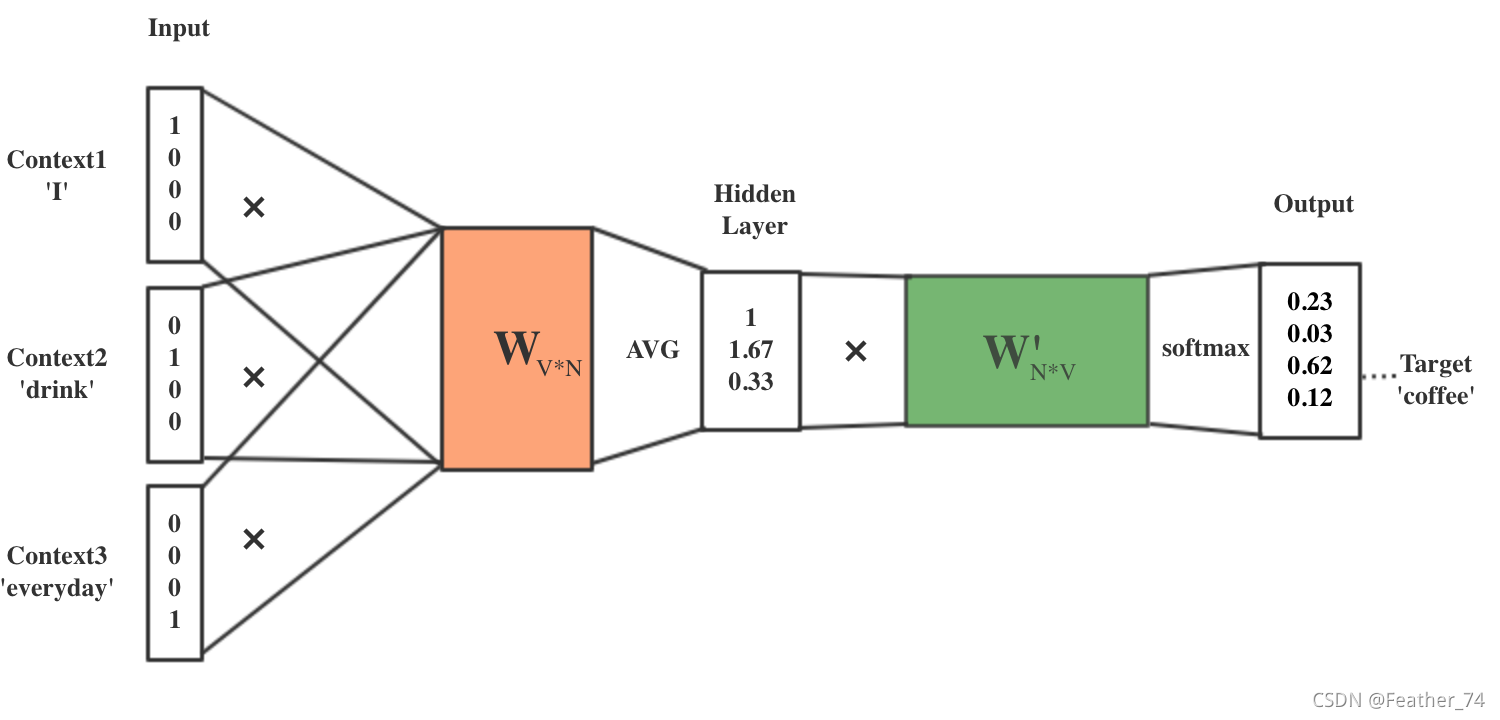
One-hot 编码又称一位有效编码,是将文字数字化的过程。举个例子,一个 corpus (语料库)为“ I drink coffee everyday ”。假设将单词放入数组 str ,则该数组 str 长度为4, vector 也就是4维向量。str[0]=“I”,str[1]=“drink”,str[2]=“coffee”,str[3]=“everyday”。把他转换成One-hot编码就是
| 单词 | One-hot 编码 |
|---|---|
| I | [1,0,0,0] |
| drink | [0,1,0,0] |
| coffee | [0,0,1,0] |
| everyday | [0,0,0,1] |
2、输入层总共有 C 个 V 维 vector 。C 是由 window size (上下文窗口大小)决定的,window size 代表我们从 target word 的一边(左边或右边)选取词的数量。假设 target word 是 coffee , window size 为2,那么则在 coffee 左侧和右侧分别选取2个词,则 C=2+2=4。V 表示语料库中词的个数,即 One-hot vector 的维度 V(window size*2=C<=V)。
二、隐藏层 Hidden layer
1、矩阵 W 是 V 行 N 列
V 表示语料库中词的个数,即 One-hot vector 的维度 V
N 是一个任意数字,即最后得到的词向量维度为 N
2、每个 input vector 分别乘以 W 可以分别得到维度为 N 的词向量,然后再求平均值得到隐藏层向量。
3、隐藏层向量乘 W’ ( N 行 V 列),得到一个维度为 V 的向量。
三、输出层 Output layer
输出层是一个 softmax 回归分类器,它的每个结点将会输出一个0-1之间的值(概率),这些所有输出层神经元结点的概率之和为1。
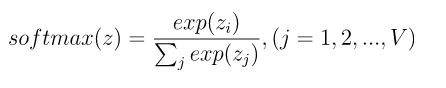
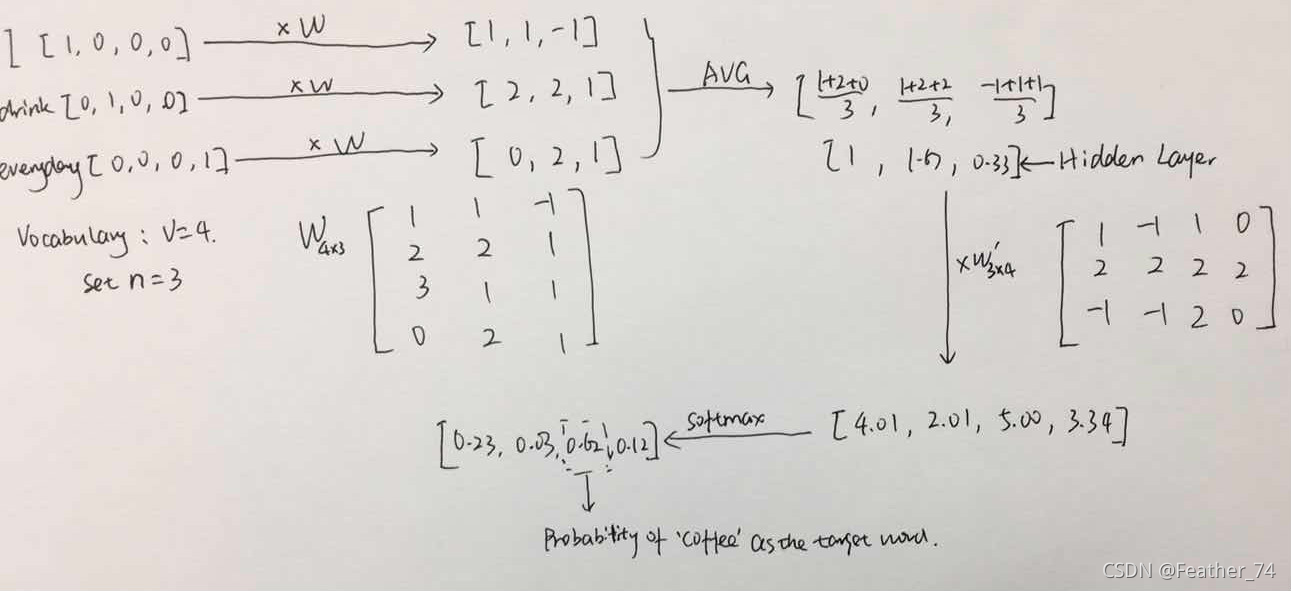
四、I drink coffee everyday 示例图
五、参考文章
1、CBOW 与 skip-gram
2、word2vec是如何得到词向量的?
3、快速笔记:NLP 中的有用术语和概念:BOW、POS、Chunking、Word Embedding
4、理解 Word2Vec 之 Skip-Gram 模型

















 708
708

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









