






IO流:存储和读取数据的解决方案
FILE:表示系统中的文件或者文件夹的路径
获取文件信息、判断文件类型、创建文件/文件夹、删除文件/文件夹
FILE类只能对文件本身进行操作,不能读写文件里面存储的数据
如果要读写数据就要用IO流了
IO流:用于读写数据
IO流的分类
有输入流和输出流
有字节流和字符流
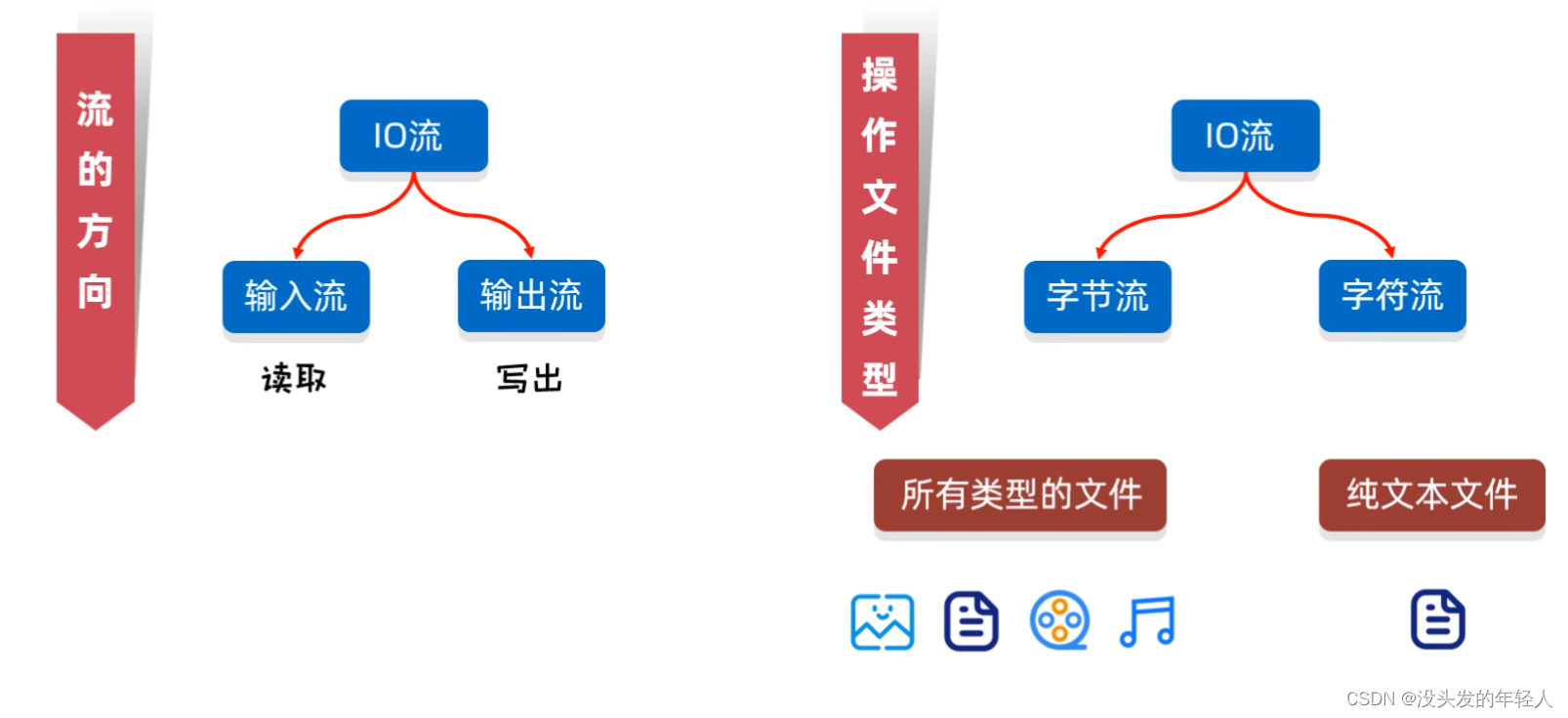
纯文本文件:Windows自带的记事本打开能读懂
总结

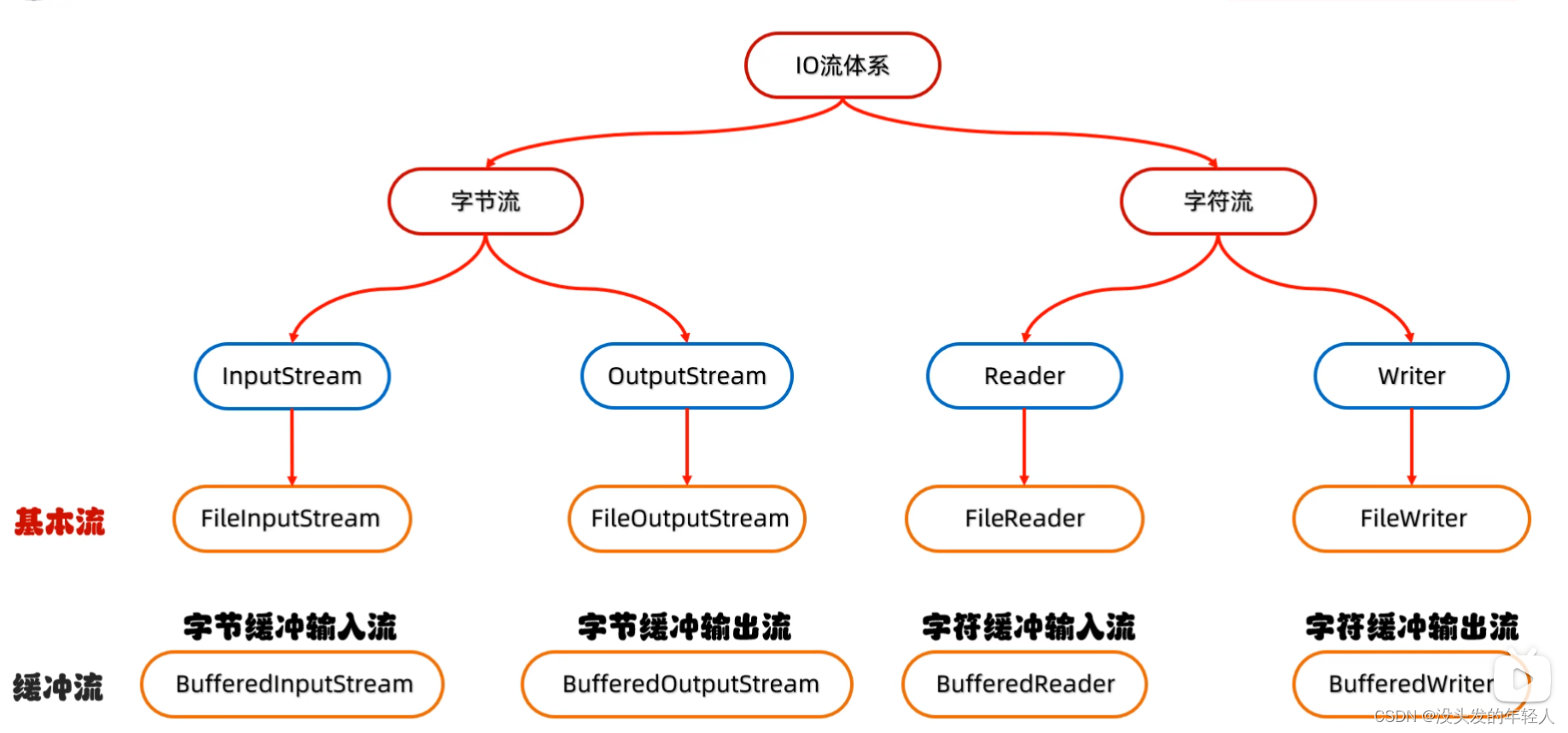
IO流的体系

但是这些都是抽象类 我们要使用对应实现的子类

FileOutputStream
操作本地文件的字节输出流,可以把程序中的数据写到本地文件中

1.创建字符输出流对象
参数是字符串表示的路径或者是File对象都是可以的
如果文件不存在会创建一个新的文件,但是要保证路径是存在的
如果文件已经存在,则会清空文件,而不是追加内容
2.写数据
write方法的参数是整数,但是写到本地文件中的是整数在ASCII上对应的字符
3.释放资源
每次使用完流之后都要释放资源
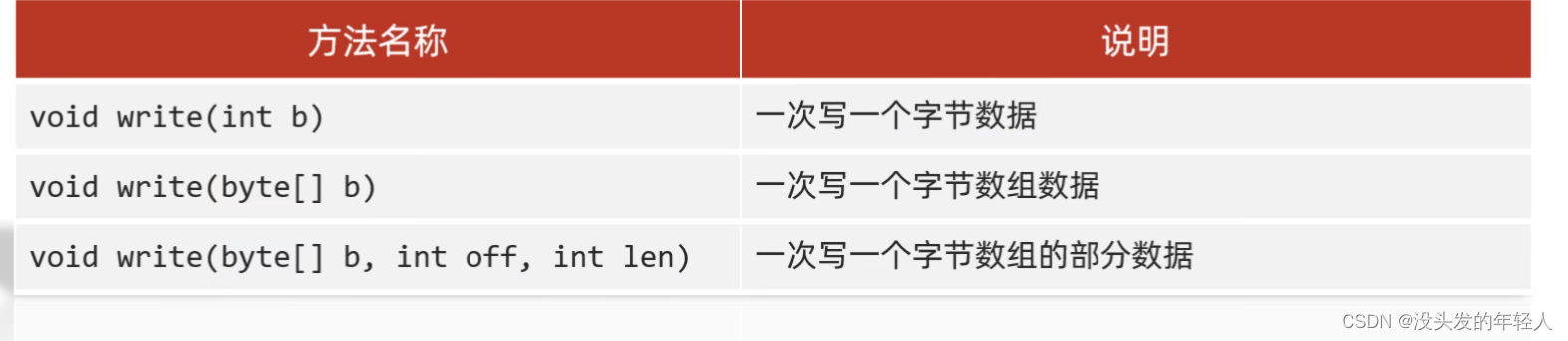
FIleOutputStream写数据的三种方式
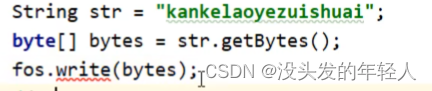
字符串变成字节数组 str.getBytes()
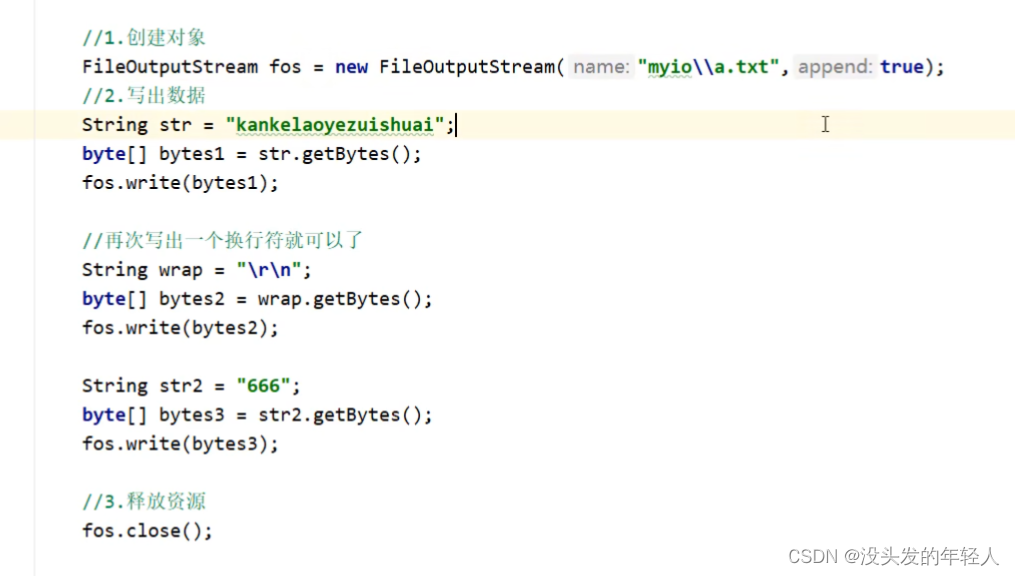
如果想换行写:windows \r\n
但是java用\r或者\n的其中一个也能实现换行,java会自动换行
如果想续写就要打开续写开关
总结

FileInputStream
操作本地文件的字节输入流,可以把本地文件的数据读到程序中

和FIleOutputStream差不多
用read()读取数据 如果读不到了就会返回-1
创建字符输入流对象时如果文件不存在就直接报错

FIleInputStream的循环读取

FileInputStream读取问题
IO流:如果拷贝的文件非常大,那么速度就会特别慢 因为一次只能读一个字节
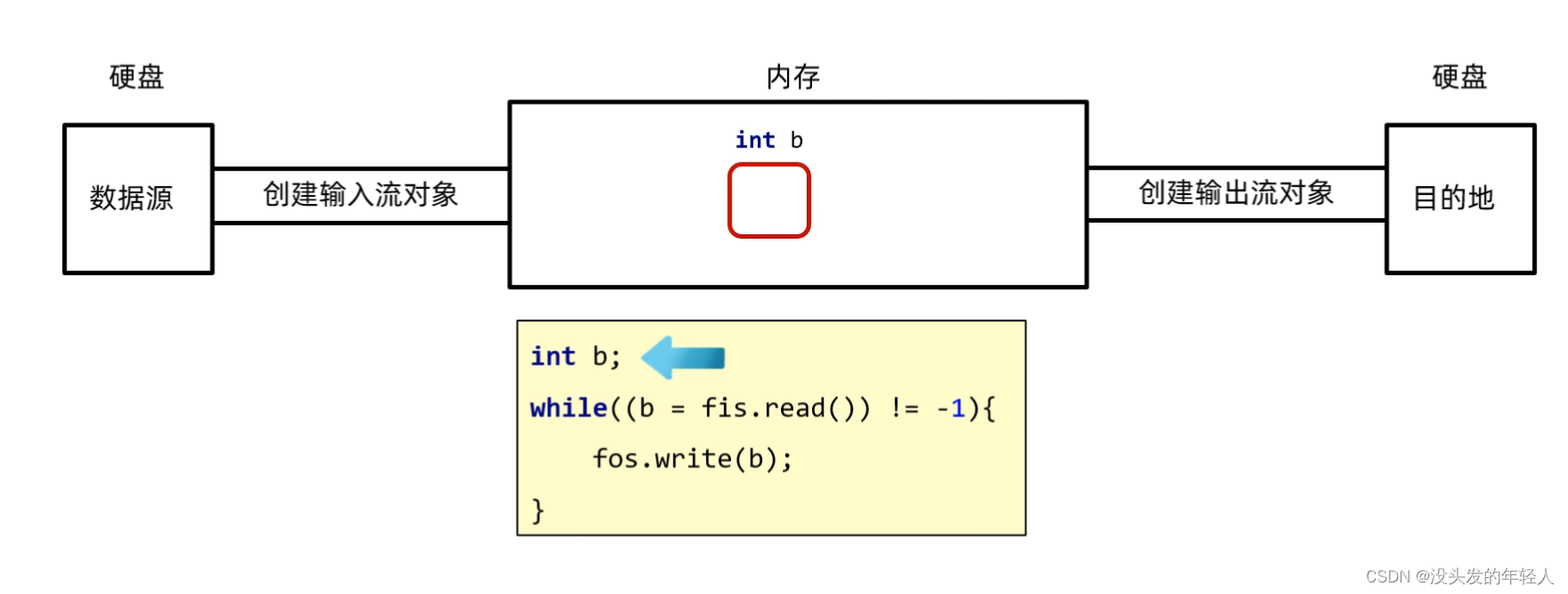

就需要循环38769986次
所以应该采用一次读取多个字节的方法实现文件的读取


但是不是每次读取越多越好,因为字节数组也是需要内存的,太大程序会崩掉
数组长度一般是1024的整数倍
1024*1024*5
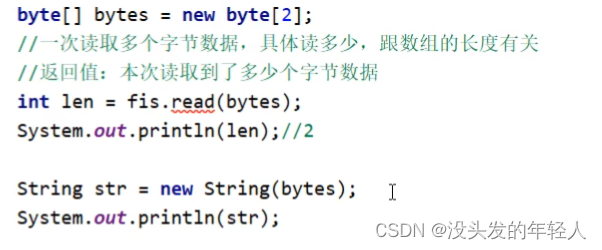
最后一次的读取要注意一下,如果读的数据没有数组那么长,只会覆盖读到长度那么长的数组

所以不要用new String(bytes)的形式读取,应该用newString(bytes,0,len)的形式

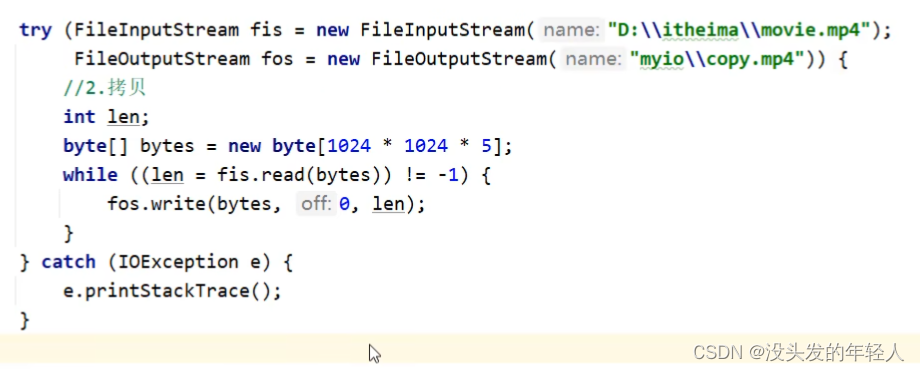
文件拷贝
文件很大 所以应该用一次读很多字节的方式
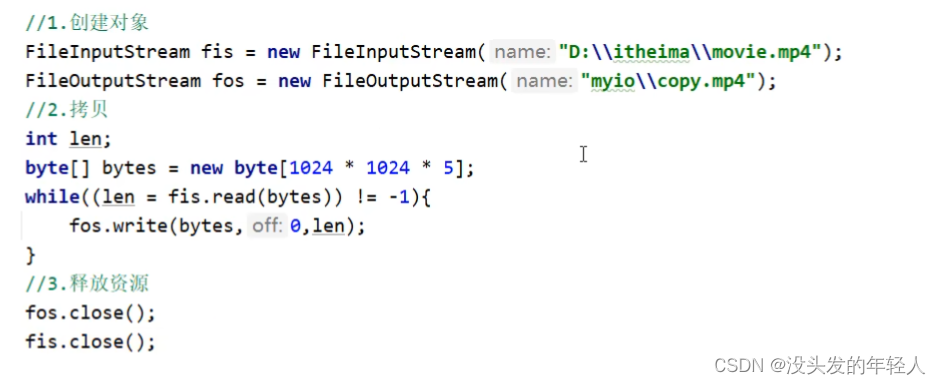
释放资源的原则先开的最后关闭
之前io流的异常都是抛出 现在用try catch捕获一下
close应该放到finally

但是开发的时候异常都是抛出的,因为Springboot有全局的异常处理器

非常麻烦的代码
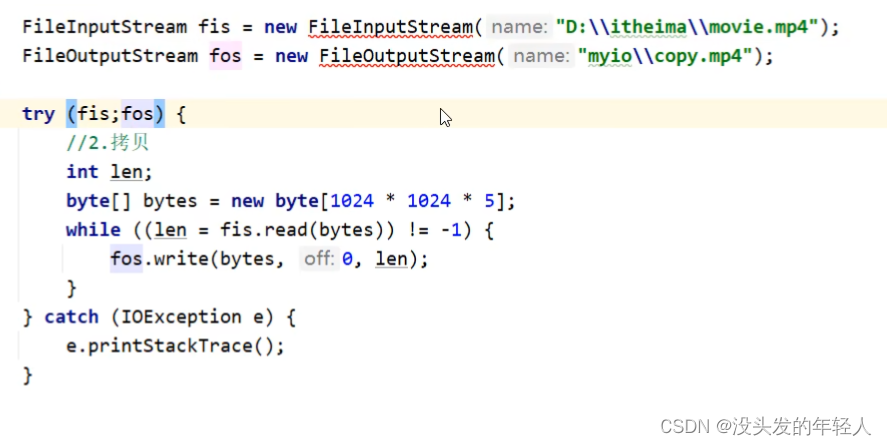
简化方案

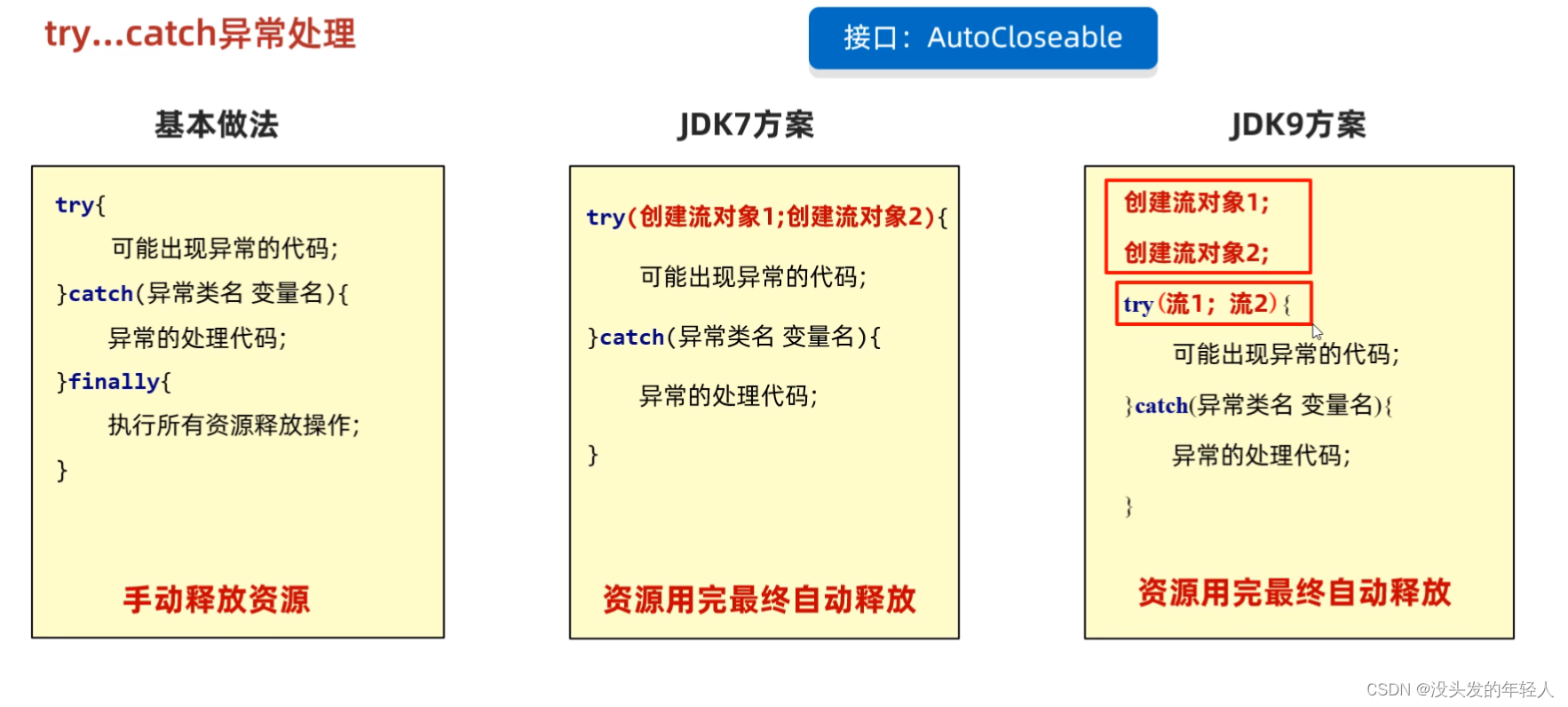
try() 小括号的流会自动释放资源
JDK9的代码
字符集
数据在计算机是二进制存储的
字节是计算机中最小的存储单元
ASCII字符集

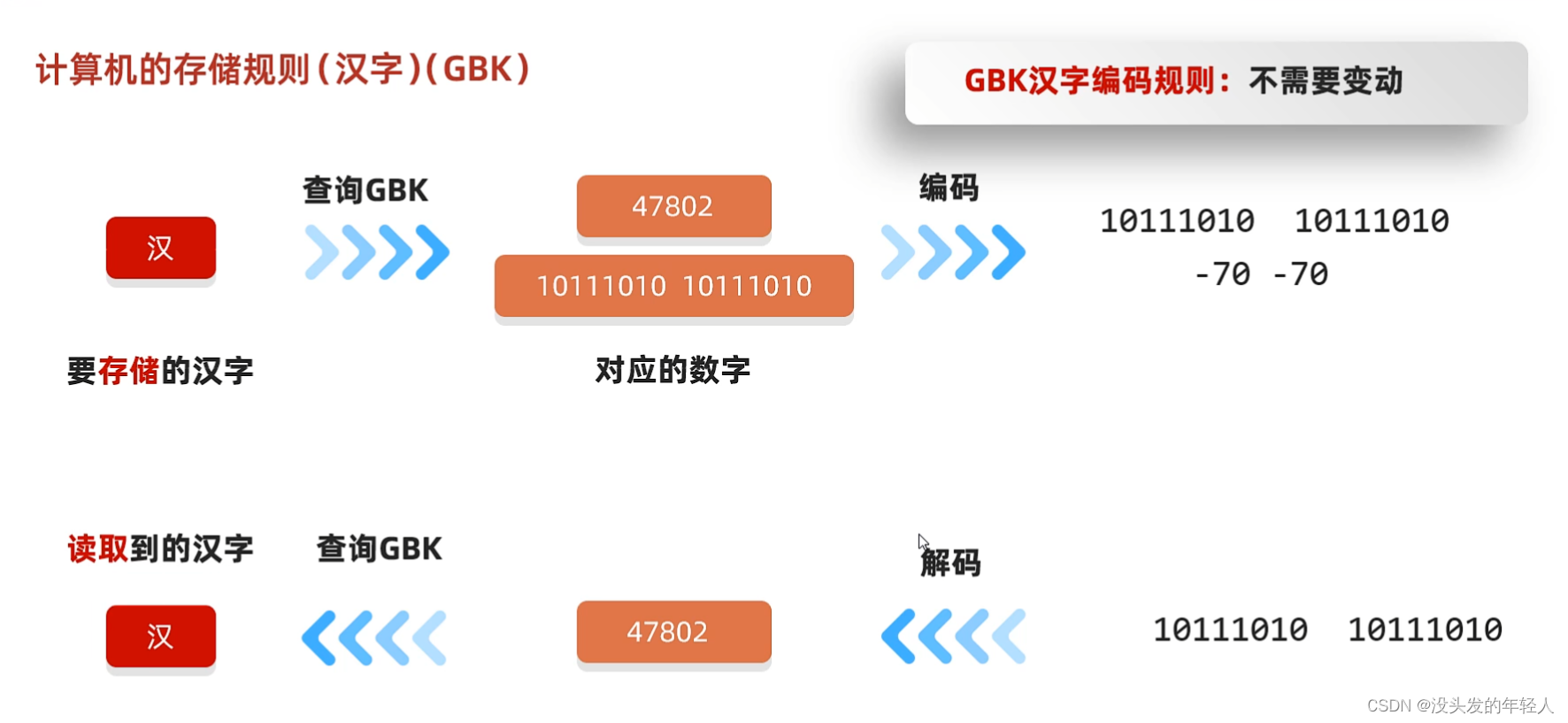
GBK存储规则
GBK在英文用一个字节存储

汉字的存储要用两个字节并且高位字节二进制一定要以1开头,转成十进制之后是一个负数
那么为什么要这样做?因为英文存储是一定要补0的,所以就一定是正数,那么汉字用负数就可以很好识别


总结

Unicode字符集 万国码

但是一般用UTF-8
是一个可变长度的编码 用1-4字节去编码



对于中文

总结

乱码出现的原因
原因1:读取数据时未完整读取整个汉字
想想 刚学习过的字节流 是不是一次只能读取一个字节? 但是中文是由3个字节(万国码中)构成的 那么就会出现乱码

原因2:编码和解码时的方式不统一
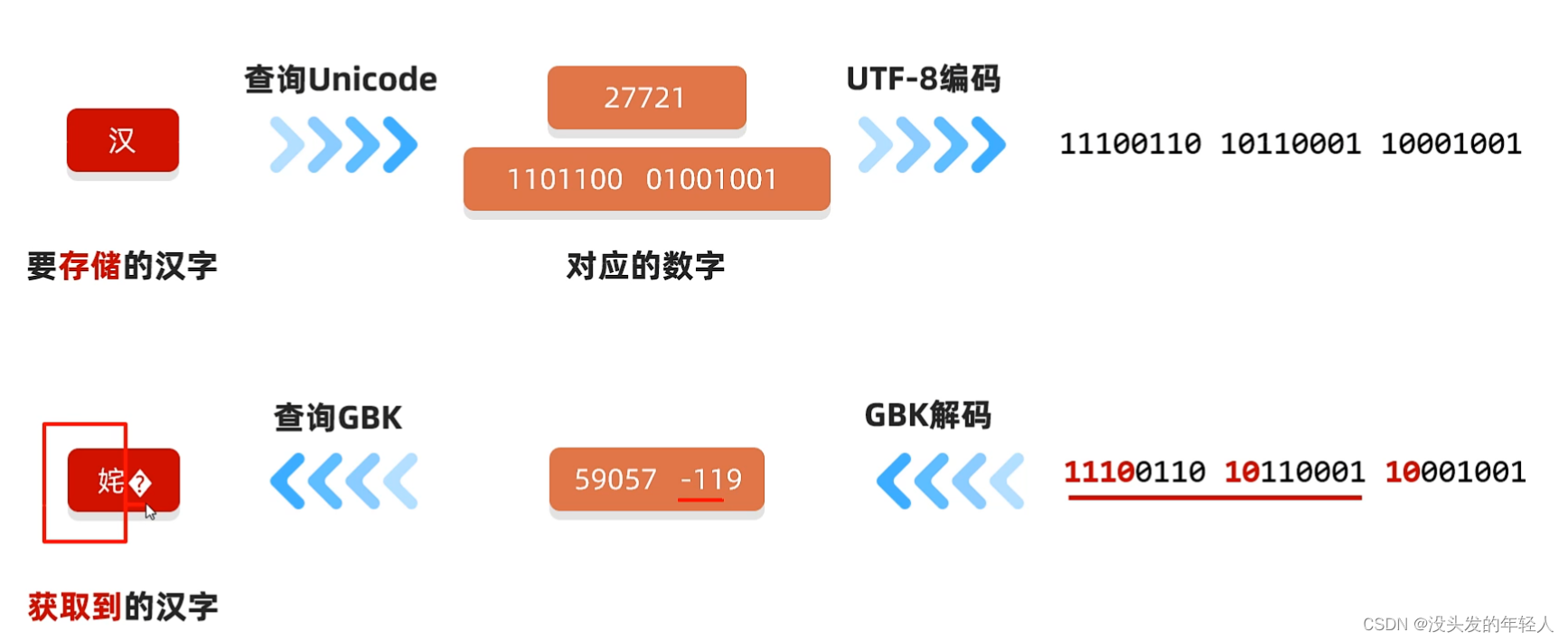
所以不要用字节流读取文本文件 并且 编码和解码的时候要使用同一个码表,同一个解码方式
有没有疑惑:字节流读取中文会乱码,但是拷贝文本文件就不会乱码?
因为拷贝数据的时候是一个一个字节拷过去,不会出现乱码
JAVA中编码解码的方法

字符输入流
为了解决读取数据时未读完整个汉字,所以就要用字符输入流
字符流=字节流+字符集


对于这个 也要用他们的子类
FileReader
和之前差不多,但是还是有一点区别

read方法得到的是一个字符/字符数组,不再是字节了

read方法默认也是一个字节一个字节的读取,如果碰到中文就会一次读取多个(具体看当前用的是什么编码方式),最终把这个十进制作为结果返回,这个数字就是字符集上的数字
但是一般我们都不想看到数字 一般都想看到内容 做个强转就行

用参数

有参的read就是空参的read+强制类型转换 把内容放到数组里面
FIleWriter

和之前的也差不多


字符流原理解析
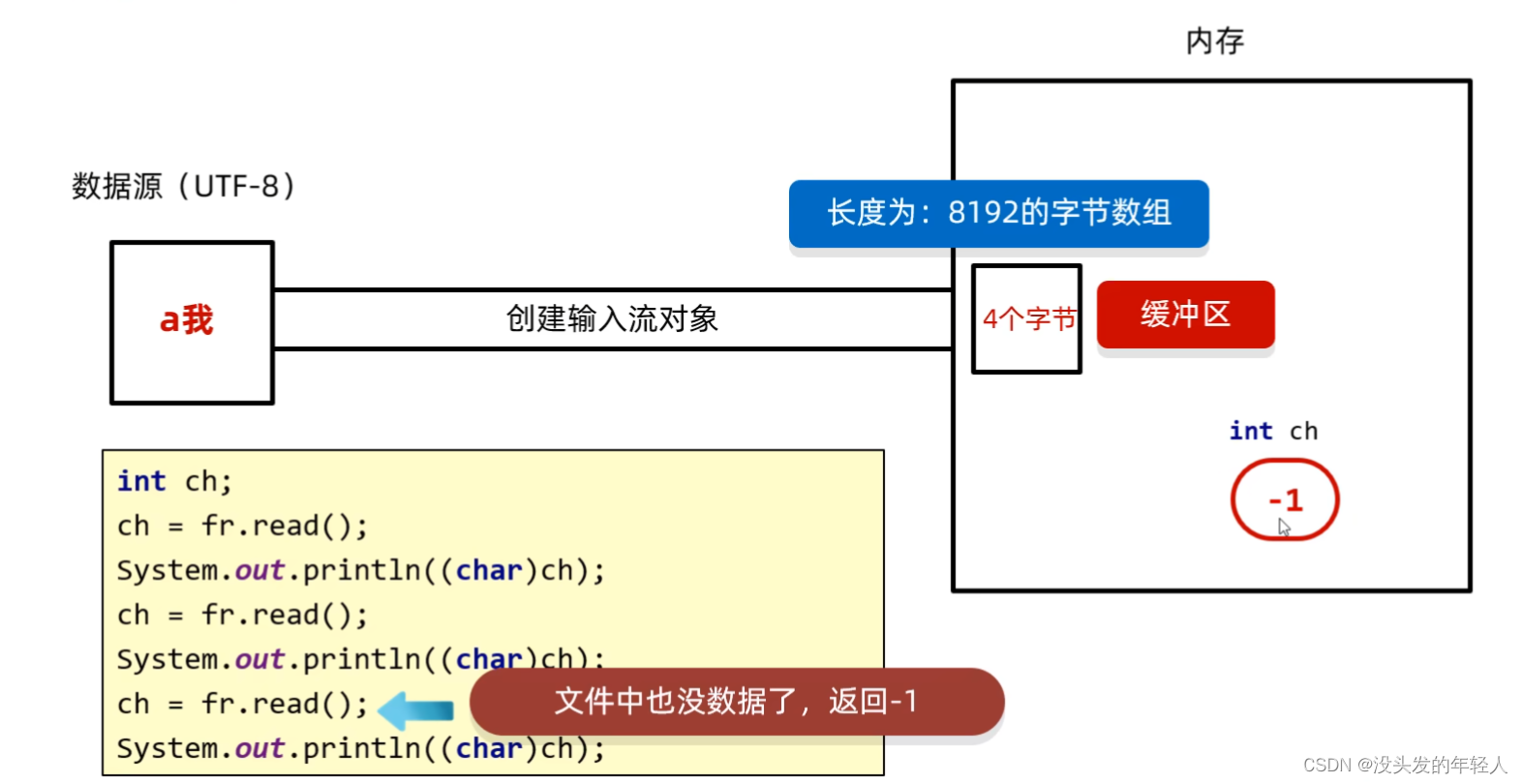
字节输入流没有这个8192的字节数组 也就是没有缓冲区

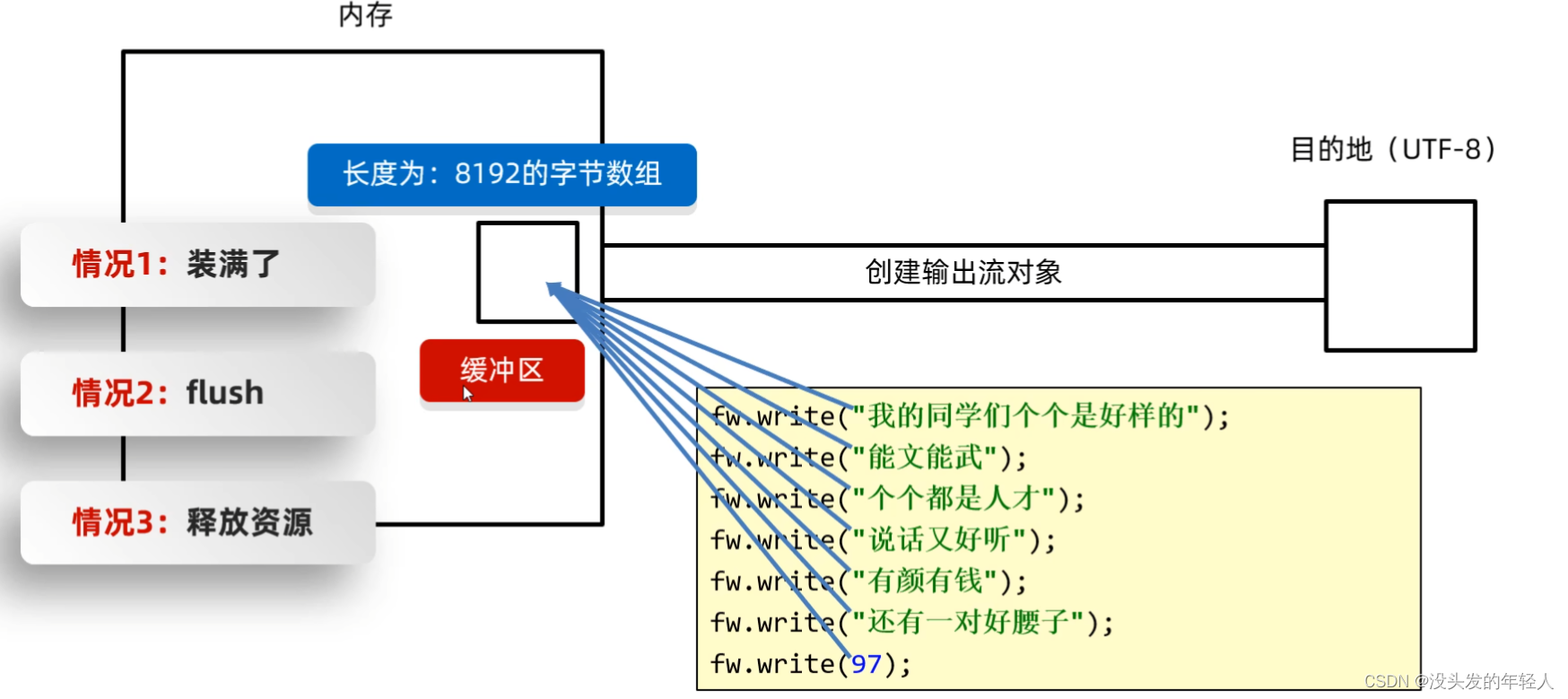
字符输出流原理
在字符输出流中,有三种情况会把缓冲区的数据放到本地,1.装满了,2.手动刷新(flush)3.关流(close)

字节流和字符流的使用场景

缓冲流
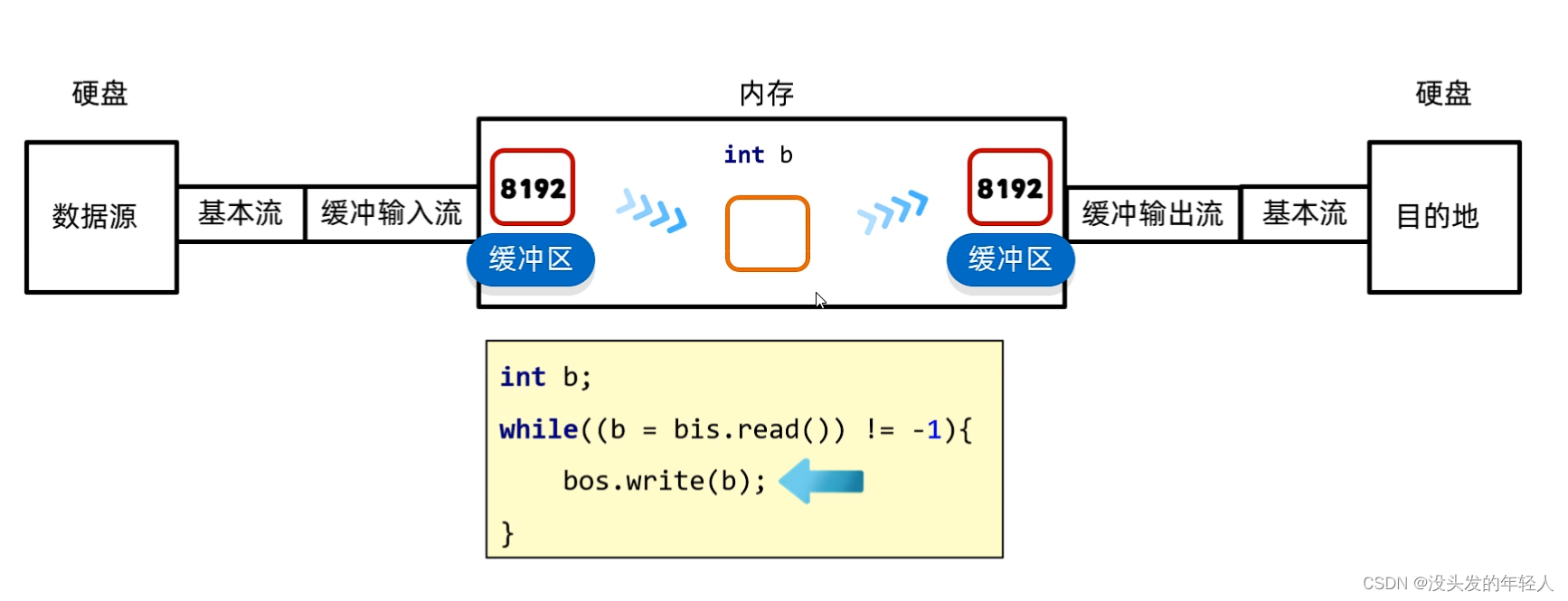
原理:底层自带了长度为8192的缓冲区提高性能
字节缓冲流
实际上只是对字节流进行了包装

字节缓冲流提高效率的原理
字符缓冲流
字符流本来就有缓冲区 所以字符缓冲流提升的性能没多大 但是新增的方法很重要


readline一次读一行读到回车换行结束所以要自己用ln换行
总结

缓冲区中,字节流的是8192的byte数组 但是字符流的是8192的字符数组 所以如果按照字节去算的话字符流的内存空间比字节流大一倍
转换流
是字符流和字节流之间的桥梁
作用:字节流想要使用字符流的方法就需要这个了

很像适配器模式
总结

序列化流
序列化流可以把java的对象写到文件中
反序列化流就是将序列化流存储的文件写到对象中


小细节

要序列化的对象都要这样 这个接口是一个标记型接口
反序列化流

小细节:
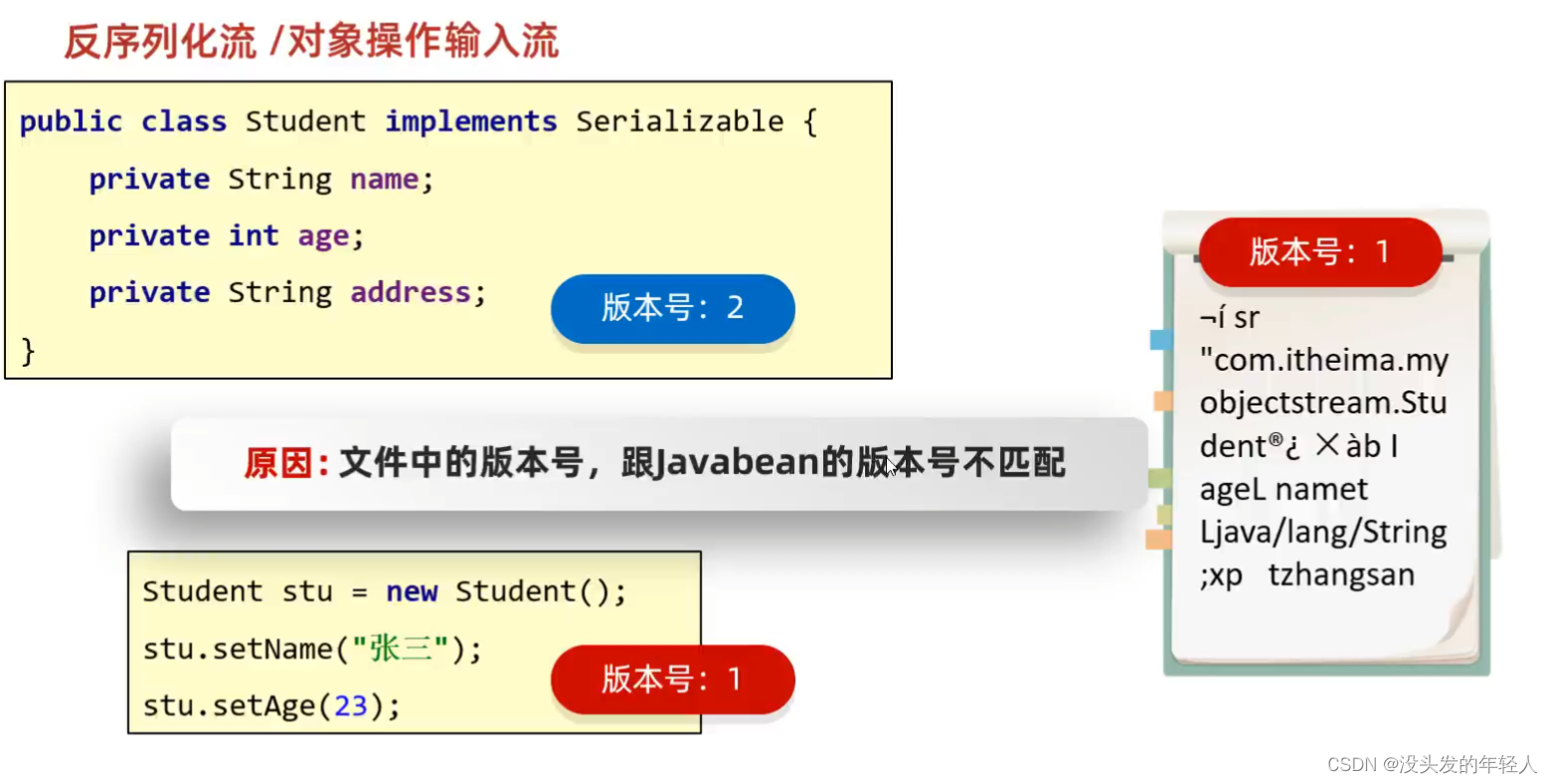
修改javabean以后就会报错
所以要固定版本号

版本号是固定的叫serivalVersionUID
不想某个属性被序列化 可以加transient
总结

打印流
打印流只有输出的 分为字节的和字符的

字节打印流


字符打印流
字符打印流有缓冲区,所以想要自动刷新需要开启
字符打印流效率高点

打印流的应用场景
System.out.println就是字节打印流
总结

解压缩流/压缩流
解压缩流
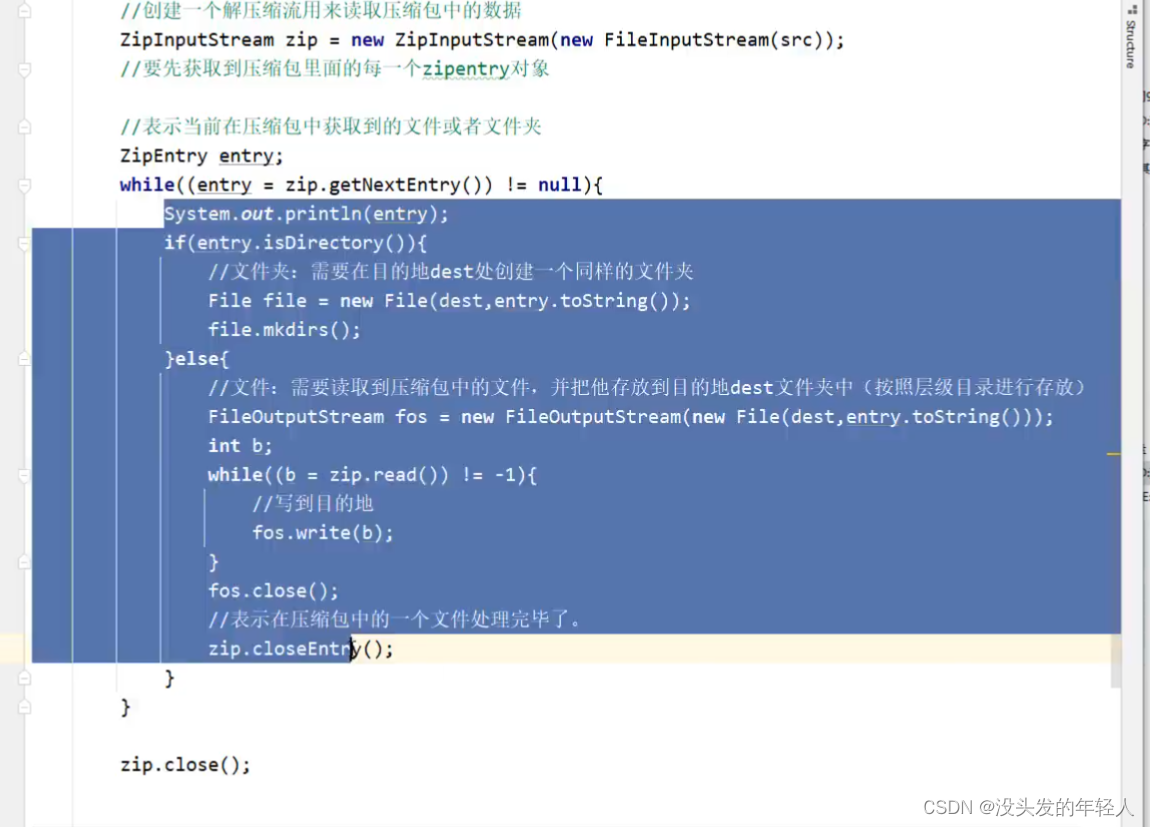
压缩流

常用工具
Commons-io

使用步骤

常见方法


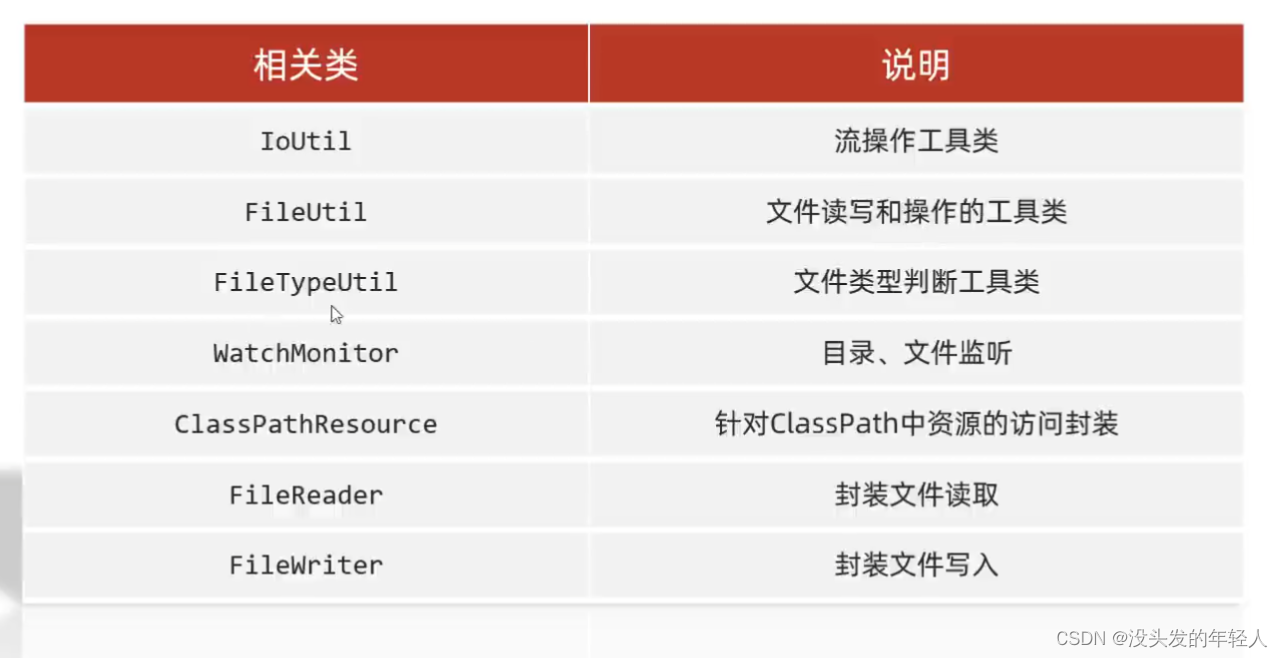
Hutool















 3454
3454











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









