






爬取亚马逊的差评数据(能跑,但是有错误,还在完善中)
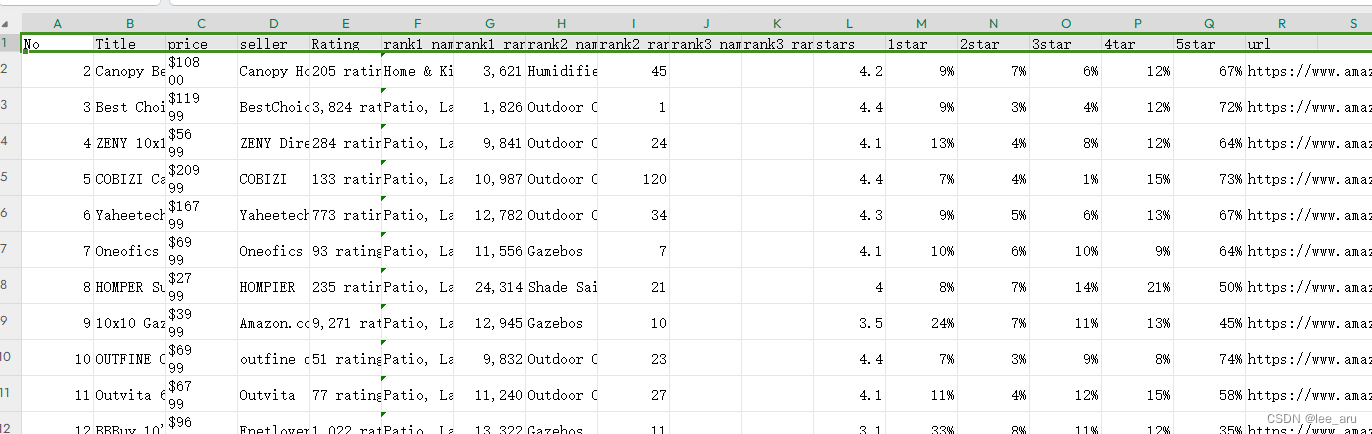
评论数据
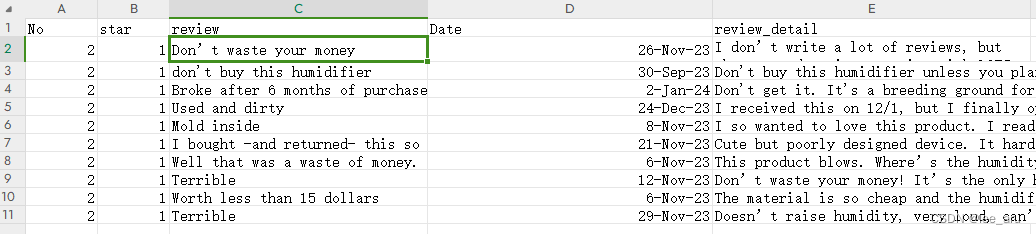
能拿到数据就行~~~~
import csv
import time
import re
import random
from datetime import datetime
from bs4 import BeautifulSoup
from pyquery import PyQuery as pq
import openpyxl
import pandas as pd
from selenium import webdriver
from selenium.common.exceptions import UnexpectedAlertPresentException
from selenium.webdriver import DesiredCapabilities, ActionChains
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
file_no=72
star1=''
star2=''
def is_element_exist(driver,xpath):
try:
driver.find_element(By.XPATH,xpath)
return True
except:
return False
#更换邮编
def change_address(postal):
while True:
try:
#driver.find_element_by_id('glow-ingress-line2').click()
driver.find_element(By.ID,"glow-ingress-line2").click()
time.sleep(2)
except Exception as e:
driver.refresh()
time.sleep(10)
continue
try:
#driver.find_element_by_id("GLUXChangePostalCodeLink").click()
driver.find_element(By.ID,"GLUXChangePostalCodeLink").click()
time.sleep(2)
except:
pass
try:
#driver.find_element_by_id('GLUXZipUpdateInput').send_keys(postal)
driver.find_element(By.ID, "GLUXZipUpdateInput").send_keys(postal)
time.sleep(1)
break
except Exception as NoSuchElementException:
try:
driver.find_element_by_id('GLUXZipUpdateInput_0').send_keys(postal.split('-')[0])
time.sleep(1)
driver.find_element_by_id('GLUXZipUpdateInput_1').send_keys(postal.split('-')[1])
time.sleep(1)
break
except Exception as NoSuchElementException:
driver.refresh()
time.sleep(10)
continue
print("重新选择地址")
#driver.find_element_by_id('GLUXZipUpdate').click()
driver.find_element(By.ID,"GLUXZipUpdate").click()
time.sleep(1)
driver.refresh()
time.sleep(3)
def parse_detail(page_source):
global star1
global star2
html = pq(page_source)
html_text=html.text()
attr_list = []
price=''
seller=''
Title=''
Rating=''
stars=''
star1 = ''
star2 = ''
star3=''
star4=''
star5=''
rank1_rank =''
rank2_rank = ''
rank3_rank = ''
rank1_name = ''
rank2_name = ''
rank3_name = ''
#评分数据
if "Product information" in html_text:
print("Product information")
tr_list = html("#productDetails_detailBullets_sections1 tr").items()
for tr in tr_list:
if "Rank" in tr("th").text():
rank1 = tr("td > span > span:nth-child(1)").text().strip()
if (rank1 !=""):
rank1 = rank1.split('(')[0]
rank1_rank = rank1.split(" in ")[0].split('#')[1]
rank1_name = rank1.split(" in ")[1]
rank2 = tr("td > span > span:nth-child(3)").text().strip()
if (rank2!=""):
rank2_rank = rank2.split(" in ")[0].split('#')[1]
rank2_name = rank2.split(" in ")[1]
rank3 = tr("td > span > span:nth-child(5)").text().strip()
if (rank3 !=""):
rank3_rank = rank3.split(" in ")[0].split('#')[1]
rank3_name = rank3.split(" in ")[1]
break
if "Product details" in html_text:
print("Product details")
rank_xpath='//*[@id="detailBulletsWrapper_feature_div"]/ul[1]/li/span'
rank_pre=driver.find_element(By.XPATH,rank_xpath).text
rank_list = rank_pre.split('#')
rank_list.pop(0)
# 对第一个元素进行操作
rank1_rank = rank_list[0].split("(")[0].split(" in ")[0]
rank1_name = rank_list[0].split("(")[0].split(" in ")[1]
# 对第二个元素进行操作
rank2_rank = rank_list[1].split(" in ")[0]
rank2_name = rank_list[1].split(" in ")[1]
# 对第三个元素进行操作(不一定有第三个rank)
if (len(rank_list) == 3):
rank3_rank = rank_list[2].split(" in ")[0]
rank3_name = rank_list[2].split(" in ")[1]
if ('Item details'in html_text ):
print("Item details")
tr_list=html("#productDetails_expanderTables_depthLeftSections tr").items()
for tr in tr_list:
if "Rank" in tr("th").text():
rank1 = tr("td > span > span:nth-child(1)").text().strip()
if (rank1 !=""):
rank1 = rank1.split('(')[0]
rank1_rank = rank1.split(" in ")[0].split('#')[1]
rank1_name = rank1.split(" in ")[1]
rank2 = tr("td > span > span:nth-child(3)").text().strip()
if (rank2!=""):
rank2_rank = rank2.split(" in ")[0].split('#')[1]
rank2_name = rank2.split(" in ")[1]
rank3 = tr("td > span > span:nth-child(5)").text().strip()
if (rank3 !=""):
rank3_rank = rank3.split(" in ")[0].split('#')[1]
rank3_name = rank3.split(" in ")[1]
break
# 其他数据
time.sleep(random.randint(1,3))
Title=driver.find_element(By.ID,'productTitle').text
try:
price=driver.find_element(By.XPATH,'//*[@id="corePriceDisplay_desktop_feature_div"]/div[1]/span[2]/span[2]').text
except Exception as e:
try:
price = driver.find_element(By.XPATH,'//*[@id="corePriceDisplay_desktop_feature_div"]/div[1]/span[3]/span[2]').text
except Exception as e:
try:
price=driver.find_element(By.ID,'corePrice_feature_div').text
except Exception as e:
print('无price')
try:
seller=driver.find_element(By.XPATH,'//*[@id="merchantInfoFeature_feature_div"]/div[2]/div/span').text
except Exception as e:
print('无seller')
if(is_element_exist(driver,'//*[@id="acrCustomerReviewText"]')):
Rating=driver.find_element(By.ID,'acrCustomerReviewText').text
stars=driver.find_element(By.XPATH,'//*[@id="acrPopover"]/span[1]/a/span').text
customer_reviews=driver.find_element(By.XPATH,'//*[@id="cm_cr_dp_d_rating_histogram"]/div[1]/h2')
driver.execute_script("arguments[0].scrollIntoView(true);",customer_reviews)
driver.implicitly_wait(10)
time.sleep(random.randint(1, 3))
if(is_element_exist(driver,'//*[@id="histogramTable"]/tbody/tr[5]/td[3]/a')):
star1=driver.find_element(By.XPATH,'//*[@id="histogramTable"]/tbody/tr[5]/td[3]/a').text
else:
star1='0%'
if(is_element_exist(driver,'//*[@id="histogramTable"]/tbody/tr[4]/td[3]/a')):
star2=driver.find_element(By.XPATH,'//*[@id="histogramTable"]/tbody/tr[4]/td[3]/a').text
else:
star2='0%'
if (is_element_exist(driver, '//*[@id="histogramTable"]/tbody/tr[3]/td[3]/a')):
star3 = driver.find_element(By.XPATH, '//*[@id="histogramTable"]/tbody/tr[3]/td[3]/a').text
else:
star3 = '0%'
if(is_element_exist(driver,'//*[@id="histogramTable"]/tbody/tr[2]/td[3]/a')):
star4=driver.find_element(By.XPATH,'//*[@id="histogramTable"]/tbody/tr[2]/td[3]/a').text
else:
star4='0%'
if(is_element_exist(driver,'//*[@id="histogramTable"]/tbody/tr[1]/td[3]/a')):
star5=driver.find_element(By.XPATH,'//*[@id="histogramTable"]/tbody/tr[1]/td[3]/a').text
else:
star5='0%'
attr_list.append(file_no)
attr_list.append(Title)
attr_list.append(price)
attr_list.append(seller)
attr_list.append(Rating)
attr_list.append(rank1_name)
attr_list.append(rank1_rank)
attr_list.append(rank2_name)
attr_list.append(rank2_rank)
attr_list.append(rank3_name)
attr_list.append(rank3_rank)
attr_list.append(stars)
attr_list.append(star1)
attr_list.append(star2)
attr_list.append(star3)
attr_list.append(star4)
attr_list.append(star5)
return attr_list
def Openreviews(star1,star2):
more=''
if(is_element_exist(driver,'//*[@id="cr-pagination-footer-0"]/a')):
more='//*[@id="cr-pagination-footer-0"]/a'
if(is_element_exist(driver,'//*[@id="reviews-medley-footer"]/div[2]/a')):
more='//*[@id="reviews-medley-footer"]/div[2]/a'
if (more==''):
return
more_button=driver.find_element(By.XPATH,more)
driver.execute_script("arguments[0].scrollIntoView(false);",more_button)
driver.implicitly_wait(10)
time.sleep(random.randint(2,5))
# 使用 ActionChains 模拟点击操作
action = ActionChains(driver)
action.move_to_element(more_button).click().perform()
driver.implicitly_wait(10)
time.sleep(random.randint(2, 5))
if(star1!='0%'):
onestar=driver.find_element(By.XPATH,'//*[@id="histogramTable"]/tbody/tr[5]/td[2]/a')
action.move_to_element(onestar).click().perform()
driver.implicitly_wait(10)
time.sleep(random.randint(2, 5))
star=1
Reviews(star)
if(star2!='0%'):
twostar=driver.find_element(By.XPATH,'//*[@id="histogramTable"]/tbody/tr[4]/td[2]/a')
action.move_to_element(twostar).click().perform()
driver.implicitly_wait(10)
time.sleep(random.randint(2, 5))
star=2
Reviews(star)
def Reviews(star):
R=driver.find_element(By.XPATH,'//*[@id="filter-info-section"]/div[2]').text
R_len=int(R.split(' ')[3].replace(',',''))
# amazon最多只能爬取100条数据
if R_len>100:
R_len=100
print(R)
page=0
print('R_len',R_len)
while page<=R_len:
for i in range(2,12):
review = ''
review_detail = ''
review_date = ''
page=page+1
if(page>R_len):
break
try:
review=driver.find_element(By.XPATH,'/html/body/div[1]/div[2]/div/div[1]/div/div[1]/div[5]/div[3]/div/div[{}]/div/div/div[2]/a/span[2]'.format(i)).text
review_date=driver.find_element(By.XPATH,'/html/body/div[1]/div[2]/div/div[1]/div/div[1]/div[5]/div[3]/div/div[{}]/div/div/span'.format(i)).text
review_detail=driver.find_element(By.XPATH,'/html/body/div[1]/div[2]/div/div[1]/div/div[1]/div[5]/div[3]/div/div[{}]/div/div/div[4]/span/span'.format(i)).text
print(review)
data={'No':file_no,'star':star,'review':review,'Date':review_date,'review_detail':review_detail}
reviews_writer.writerow(data)
except Exception as e:
print('review获取失败')
if (page ==R_len):
break
try:
next_button=driver.find_element(By.XPATH,'//*[@id="cm_cr-pagination_bar"]/ul/li[2]/a')
driver.execute_script("arguments[0].scrollIntoView(false);",next_button)
driver.implicitly_wait(10)
time.sleep(random.randint(2,4))
action = ActionChains(driver)
action.move_to_element(next_button).click().perform()
driver.implicitly_wait(10)
time.sleep(random.randint(2, 4))
except Exception as e:
print('Next page error')
time.sleep(10)
if __name__ == '__main__':
df = pd.read_csv(r"C:\Users\admin\Desktop\python_file\amazon\gazebos\output_Url.csv")
url_list= df['url'].to_list()
print(len(url_list))
f=open(r"C:\Users\admin\Desktop\python_file\amazon\gazebos\output.csv",'a', encoding='utf-8-sig', newline="")
f_writer=csv.DictWriter(f,fieldnames=['No','Title','price','seller','Rating','rank1_name','rank1_rank','rank2_name','rank2_rank','rank3_name','rank3_rank','stars','1star','2star','3star','4tar','5star','url'])
f_writer.writeheader()
reviews_file=open(r"C:\Users\admin\Desktop\python_file\amazon\gazebos\output_review.csv",'a', encoding='utf-8-sig', newline="")
#表头
reviews_writer=csv.DictWriter(reviews_file,fieldnames=['No','star','review','Date','review_detail'])
reviews_writer.writeheader()
# print("keyword_list=",url_list)
options = webdriver.ChromeOptions()
# #options.page_load_strategy='none'
# options.add_argument("--proxy-server='direct://'") #new 加快运行速度
# options.add_argument("--proxy-bypass-list=*") #new 加快运行速度
# options.add_argument('--disable-infobars') # 禁用浏览器正在被自动化程序控制的提示 new
options.add_argument('--disable-gpu') #禁止gpu渲染
options.add_argument("disable-web-security")
options.add_experimental_option('excludeSwitches', ['enable-automation'])
driver = webdriver.Chrome(options=options)
wait = WebDriverWait(driver, 20)
driver.maximize_window()
#driver.set_window_size(1366,768)
row = 2
postal = "90003"
url='https://www.amazon.com'
driver.get(url)
#改变邮编90003
change_address(postal)
# i 表示当前找的是第几个keywords
while file_no < len(url_list):
driver.get(url_list[file_no])
time.sleep(2)
file_no = file_no + 1
info_list = parse_detail(driver.page_source)
info_list.append(url_list[file_no-1])
print(info_list)
data={'No':info_list[0],'Title':info_list[1],'price':info_list[2],'seller':info_list[3],'Rating':info_list[4],'rank1_name':info_list[5],'rank1_rank':info_list[6],'rank2_name':info_list[7],'rank2_rank':info_list[8],'rank3_name':info_list[9],'rank3_rank':info_list[10],'stars':info_list[11],'1star':info_list[12],'2star':info_list[13],'3star':info_list[14],'4tar':info_list[15],'5star':info_list[16],'url':info_list[17]}
f_writer.writerow(data)
if (star1 != '0%' or star2 != '0%'):
Openreviews(star1, star2)
driver.quit()
reviews_file.close()
f.close()
print("爬取结束")















 851
851











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









