







 本文介绍了如何使用Python分析亚马逊评论请求,获取评论内容并进行处理。通过分析XHR请求获取真实的评论数据,使用代理确保稳定访问,并通过while循环实现自动翻页。最终,作者提供了完整的代码整合,包括代理设置和翻页逻辑,总结了评论获取的关键点。
本文介绍了如何使用Python分析亚马逊评论请求,获取评论内容并进行处理。通过分析XHR请求获取真实的评论数据,使用代理确保稳定访问,并通过while循环实现自动翻页。最终,作者提供了完整的代码整合,包括代理设置和翻页逻辑,总结了评论获取的关键点。
文章目录
上次亚马逊的商品信息都获取到了,自然要看一下评论的部分。用户的评论能直观的反映当前商品值不值得购买,亚马逊的评分信息也能获取到做一个评分的权重。

亚马逊的评论区由用户ID,评分及评论标题,地区时间,评论正文这几个部分组成,本次获取的内容就是这些。
测试链接:https://www.amazon.it/product-reviews/B08GHGTGQ2/ref=cm_cr_arp_d_paging_btm_14?ie=UTF8&pageNumber=14&reviewerType=all_reviews&pageSize=10&sortBy=recent
一、分析亚马逊的评论请求
首先打开开发者模式的Network,Clear清屏做一次请求:

你会发现在Doc中的get请求正好就有我们想要的评论信息。
可是真正的评论数据可不是全部都在这里的,页面往下翻,有个翻页的button:
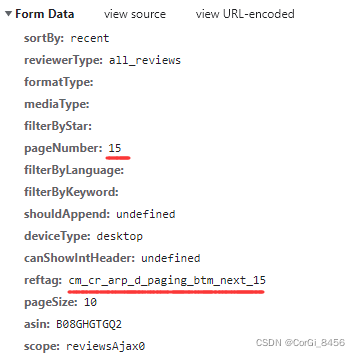
点击翻页请求下一页,在Fetch/XHR选项卡中多了一个新的请求,刚才的Doc选项卡中并无新的get请求。这下发现了所有的评论信息是XHR类型的请求。

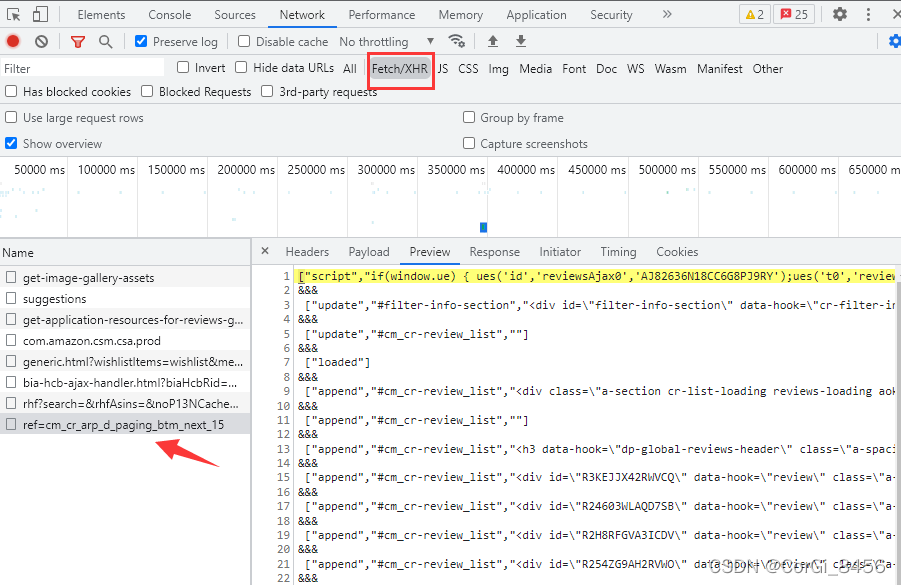
获取到post请求的链接和payload数据,里面含有控制翻页的参数,真正的评论请求已经找到了。
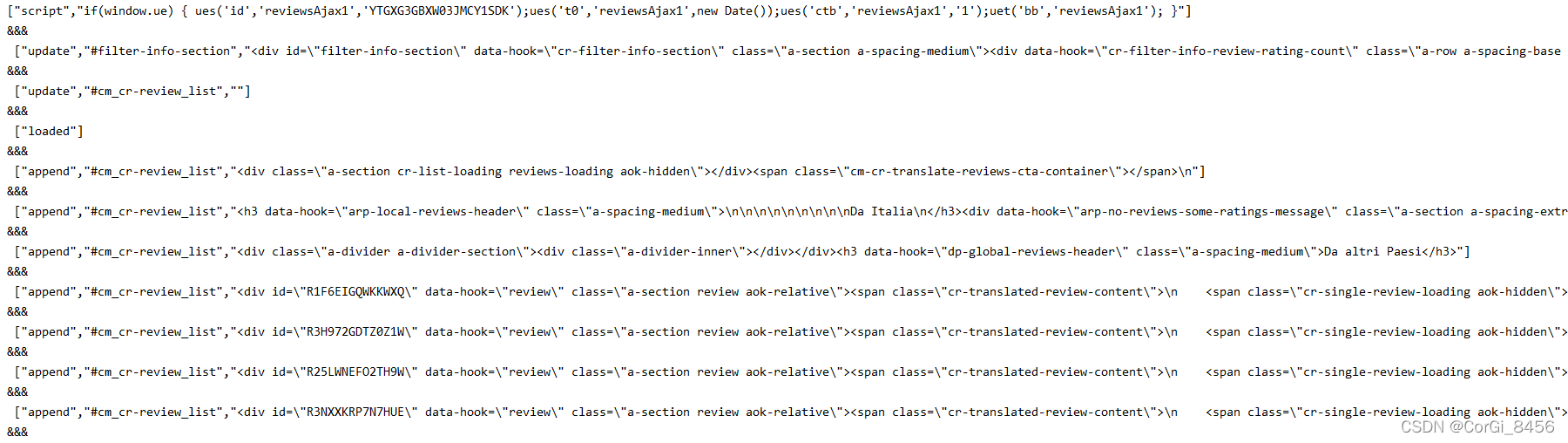
这一堆就是未处理的信息,这些请求未处理的信息里面,带有data-hook=\"review\"的就是带有评论的信息。分析完毕,下面开始一步一步去写请求。
二、获取亚马逊评论的内容
首先拼凑请求所需的post参数,请求链接,以便之后的自动翻页,然后带参数post请求链接:
headers = {
'authority': 'www.amazon.it',
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,\*/\*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36",
}
page = 1
post\_data = {
"sortBy": "recent",
"reviewerType": "all\_reviews",
"formatType": "",
"mediaType": "",
"filterByStar": "",
"filterByLanguage": "",
"filterByKeyword": "",
"shouldAppend": "undefined",
"deviceType": "desktop",
"canShowIntHeader": "undefined",
"pageSize": "10",
"asin": "B08GHGTGQ2",
}
# 翻页关键payload参数赋值
post\_data\["pageNumber"\] = page,
post\_data\["reftag"\] = f"cm\_cr\_getr\_d\_paging\_btm\_next\_{page}",
post\_data\["scope"\] = f"reviewsAjax{page}",
# 翻页链接赋值
spiderurl=f'https://www.amazon.it/hz/reviewsrender/ajax/reviews/get/ref=cm\_cr\_getr\_d\_paging\_btm\_next\_{page}'
res = requests.post(spiderurl,headers=headers,data=post\_data)
if res and res.status\_code == 200:
res = res.content.decode('utf-8')
print(res)
现在已经获取到了这一堆未处理的信息,接下来开始对这些数据进行处理。
三、亚马逊评论信息的处理
上图的信息会发现,每一段的信息都由“&&&”进行分隔,而分隔之后的每一条信息都是由’“,”'分隔开的:

所以用python的split方法进行处理,把字符串分隔成list列表:
\# 返回值字符串处理
contents = res.split('&&&')
for content in contents:
infos = content.split('","')
由’“,”'分隔的数据通过split处理生成新的lis
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1137
1137

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









