







Stanford Parser
1 处理一个中文的句子:
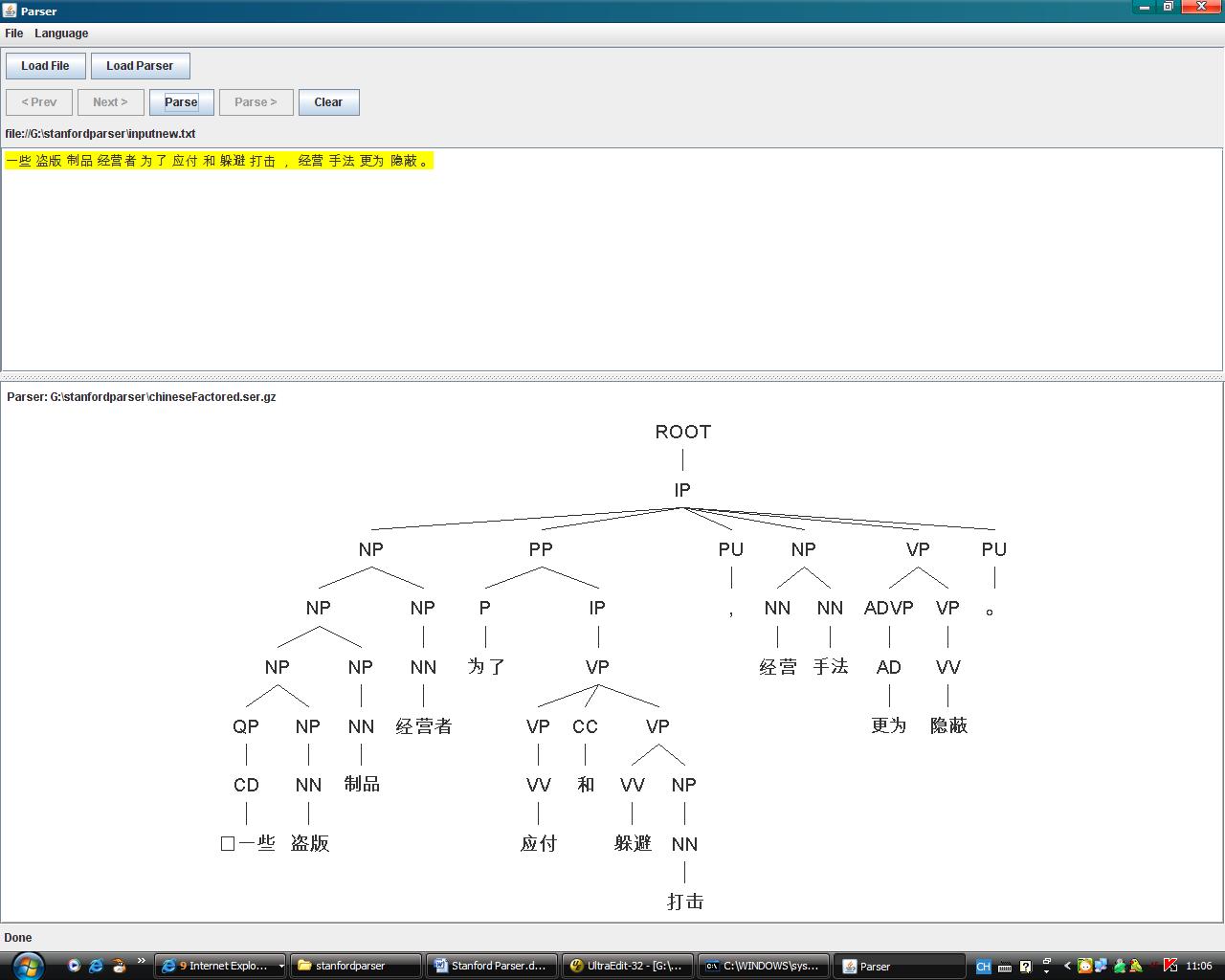
例如:一些盗版制品经营者为了应付和躲避打击,经营手法更为隐蔽。
首先, 使用Chinese segment 进行词语的切分。
调用的命令:
G:/chinesesegmenter>segment.bat pk input.txt gb18030 > out.txt
其中 pk 是词典 还有一个词典是ctb (没有比较过两个词典的优劣)
input.txt 是输入文件.里面包含该句子
gb18030 是文件编码 还支持GB utf-8
out.txt 是输出的文件
结果:一些 盗版 制品 经营者 为了 应付 和 躲避 打击 , 经营 手法 更为 隐蔽 。
2 词性标注 和 生成 依存关系
这里为方便生成一个批处理文件:lexparserCh.bat
文件内容:
@echo off
:: Runs the Chinese PCFG parser on one or more files, printing trees only
:: usage: lexparser fileToparse
java -server -mx800m -cp "stanford-parser.jar;" edu.stanford.nlp.parser.lexparser.LexicalizedParser -outputFormat "penn,typedDependenciesCollapsed" chineseFactored.ser.gz %1
---------------------------------------------------------------------------------------------------------------------------
调用的命令:
G:/stanfordparser>lexparserCh.bat input.txt>outputch.txt
Loading parser from serialized file chineseFactored.ser.gz ... done [30.2 sec].
Parsing file: input.txt with 1 sentences.
Parsing [sent. 1 len. 15]: 一些 盗版 制品 经营者 为了 应付 和 躲避 打击 , 经营
手法 更为 隐蔽 。
Parsed file: input.txt [1 sentences].
Parsed 15 words in 1 sentences (3.35 wds/sec; 0.22 sents/sec).
其中,chineseFactored.ser.gz 是用于中文的parser。
结果:outputch.txt 文件
ROOT
(IP
(NP
(NP
(QP (CD 一些))
(NP (NN 盗版) (NN 制品)))
(NP (NN 经营者)))
(PP (P 为了)
(IP
(VP
(VP (VV 应付))
(CC 和)
(VP (VV 躲避)
(NP (NN 打击))))))
(PU ,)
(NP (NN 经营) (NN 手法))
(VP
(ADVP (AD 更为))
(VP (VV 隐蔽)))
(PU 。)))
numod(制品-3, 一些-1)
nmod(制品-3, 盗版-2)
nmod(经营者-4, 制品-3)
nsubj(隐蔽-14, 经营者-4)
prep(隐蔽-14, 为了-5)
clmpd(为了-5, 应付-6)
cc(应付-6, 和-7)
ccomp(应付-6, 躲避-8)
dobj(躲避-8, 打击-9)
nmod(手法-12, 经营-11)
nsubj(隐蔽-14, 手法-12)
advmod(隐蔽-14, 更为-13)
3、图形工具界面
运行命令:lexparser-gui.bat
首先load parser
然后选择文件,必须是utf-8编码的,而且是分词过后的。
Language 选择中文。
最后 parser 得到结果的树形表示。















 7070
7070

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









