









从暴力算法一步步走到KMP算法
学习kmp算法时,总是不理解为什么应该这样,next数组的提出和初始化实在是把人绕的头晕。我觉得,不是自己太愚笨,理解不了如此高深莫测的kmp,而是说,很多教程都是站在巨人的肩膀上告诉我们应该怎样云云,而不是指引我们一步步爬到高处,毕竟没有经历过程的洗礼,一蹴而就的理解自然是很困难的事情。因此本文就从Brute Force开始,经过不断的分析、消除不必要的回溯,来最终得到并真正地理解kmp算法。
逼近kmp算法
问题如下:对于字符串 t e x t text text,想要判定其中是否含有字符串 p a t t e r n pattern pattern,如果有,返回它在 t e x t text text中第一次出现的位置,否则返回 − 1 -1 −1。
自然而然,我们会想到以下解法:
int match(string text, string pattern) {
int n = text.length(), m = pattern.length();
for (int k = 0; k < n - m + 1; k+=1) {
if (text.substr(k, m) == pattern) {
return k;
}
}
return -1;
}
这种BF解法所作的字符比较次数最坏情况下为 ( n − m + 1 ) × m (n-m+1)\times m (n−m+1)×m次,其复杂度为 O ( n m ) O(nm) O(nm)。
但 O ( m n ) O(mn) O(mn)未免也太大了些,我们希望把比较次数拉低。
举个例子: t e x t = a a a a a a b text=aaaaaab text=aaaaaab, p a t t e r n = a a a a b pattern=aaaab pattern=aaaab,显而易见, k k k每次值为 1 1 1的增幅限制了我们的比较速度,但是,如果增幅过大,我们又可能刚好错过恰好比较成功的位置。
那问题来了,我们该怎样确定增幅?显然,增幅为固定值是不可以的,把k+=1换成k+=2会让我们有可能错过正确答案,返回-1的结果。
大家可能会想到动态规划,毕竟动态规划在时间复杂度上可谓是无往而不利,但动态规划的本质思想,其实就是尽可能多的利用已知信息推理未知信息,这种思想不仅存在于动态规划,它在我们的优化过程中也可以起到很重大的作用。
首先,我们先对代码进行一次简单的变形,因为substr函数过于封闭,限制了我们的操作自由度,阻碍了优化进程。
int match(string t, string p) {
int n = t.length(), m = p.length();
int i = 0, j = 0;
while (i < n && j < m) {
if (t[i] == p[j]) {
i++;
j++;
} else {
i = i-j+1; // i回溯
j = 0; // j回溯
}
}
if (j == m) {
return i - j;
} else {
return -1;
}
}
我们可以看出,k+=1被更替成了i=i-j+1,j=0。k的增长也就变成了i和j的回溯。
下面就到了重点,发现低效率并抹除低效率。看图说话。
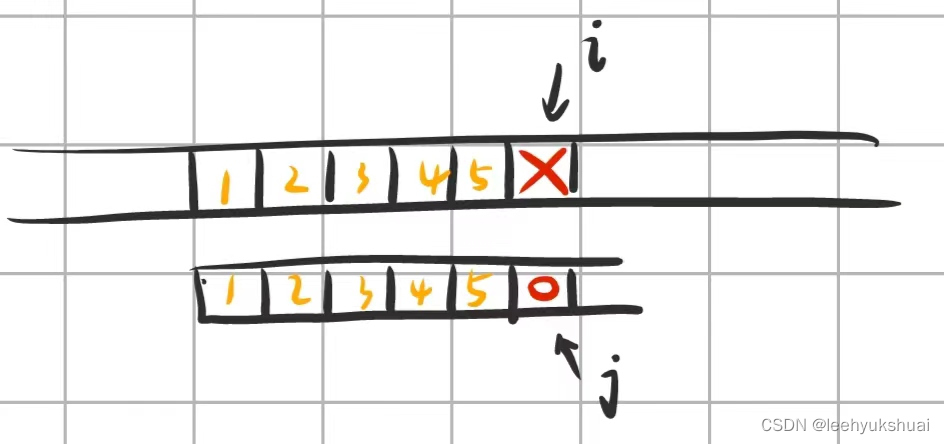
比较的前五个数均相等,当
j
=
=
5
j==5
j==5时,
t
[
i
]
!
=
p
[
j
]
t[i]!=p[j]
t[i]!=p[j],我们需要进行回溯,也就是i=i-j+1,j=0。
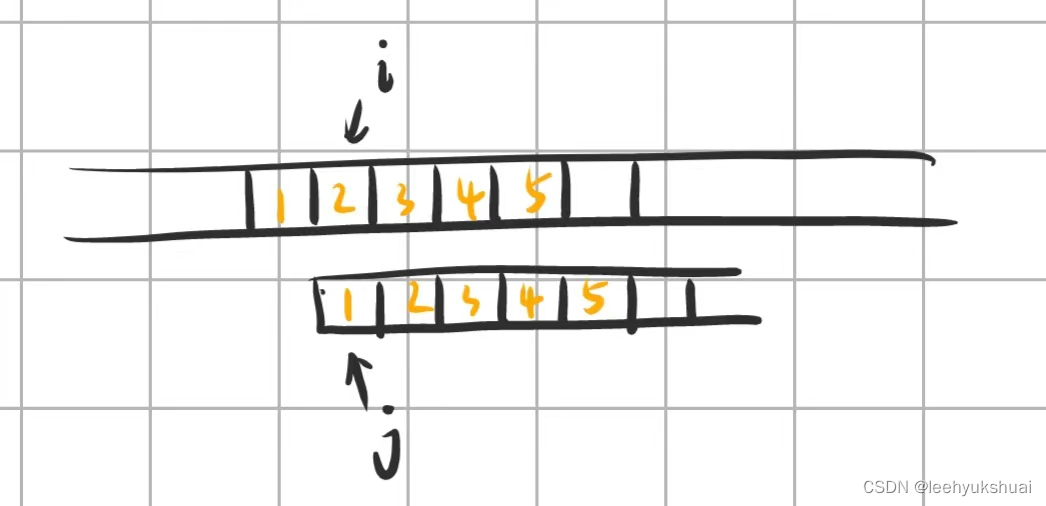
容易发现,在此次回溯的时候, t [ 2345 ] = = p [ 1234 ] t[2345]==p[1234] t[2345]==p[1234]是此次回溯能匹配成功的必要条件,因为如果 t [ 2345 ] t[2345] t[2345]不等于 p [ 1234 ] p[1234] p[1234],那么 t [ 2345... ( m + 1 ) ] t[2345...(m+1)] t[2345...(m+1)]就不可能等于 p [ 1234... m ] p[1234...m] p[1234...m],直接进行下一次回溯就行。
那如何判断这部分是否相等呢?注意由于上次比较时, t [ 12345 ] = = p [ 12345 ] t[12345]==p[12345] t[12345]==p[12345],所以 t [ 2345 ] = = p [ 2345 ] t[2345]==p[2345] t[2345]==p[2345],因此此次回溯成功的必要条件就是 p [ 1234 ] = = p [ 2345 ] p[1234]==p[2345] p[1234]==p[2345]。而且,当 p [ 1234 ] = = p [ 2345 ] p[1234]==p[2345] p[1234]==p[2345]满足时, i i i可以直接跳过 t [ 2345 ] t[2345] t[2345]的部分,同时 j j j也跳过 p [ 1234 ] p[1234] p[1234]的部分,毕竟我们已经确定这一部分是相等的,然后我们接着进行比较就可以。
当 p [ 1234 ] ! = p [ 2345 ] p[1234]!=p[2345] p[1234]!=p[2345]时,我们直接进行下一次回溯:
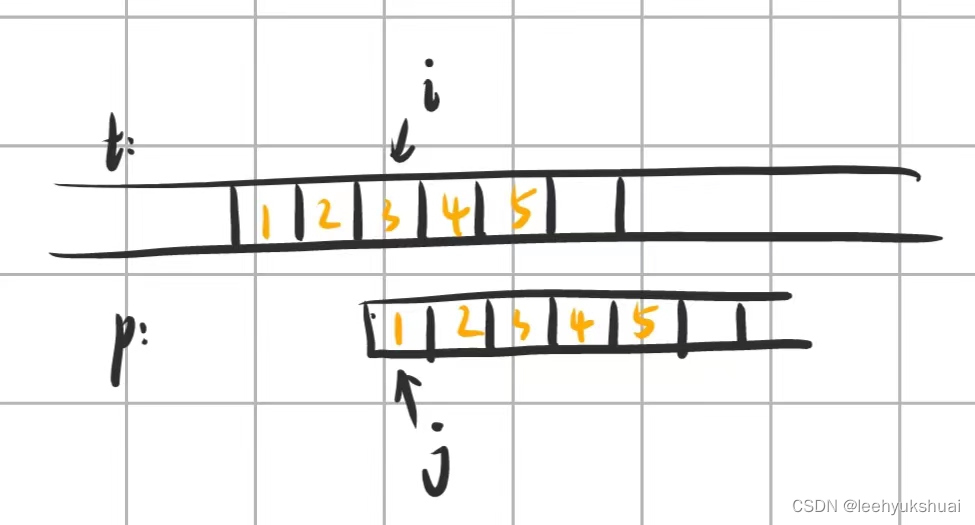
根据上一次的经验,我们很快得出,此次回溯能够匹配成功的必要条件是 t [ 345 ] = = p [ 123 ] t[345]==p[123] t[345]==p[123],也就是 p [ 123 ] = = p [ 345 ] p[123]==p[345] p[123]==p[345]。若满足,则 i i i跳过 t [ 345 ] t[345] t[345], j j j跳过 p [ 123 ] p[123] p[123]继续比较;否则,我们进行下一次回溯。
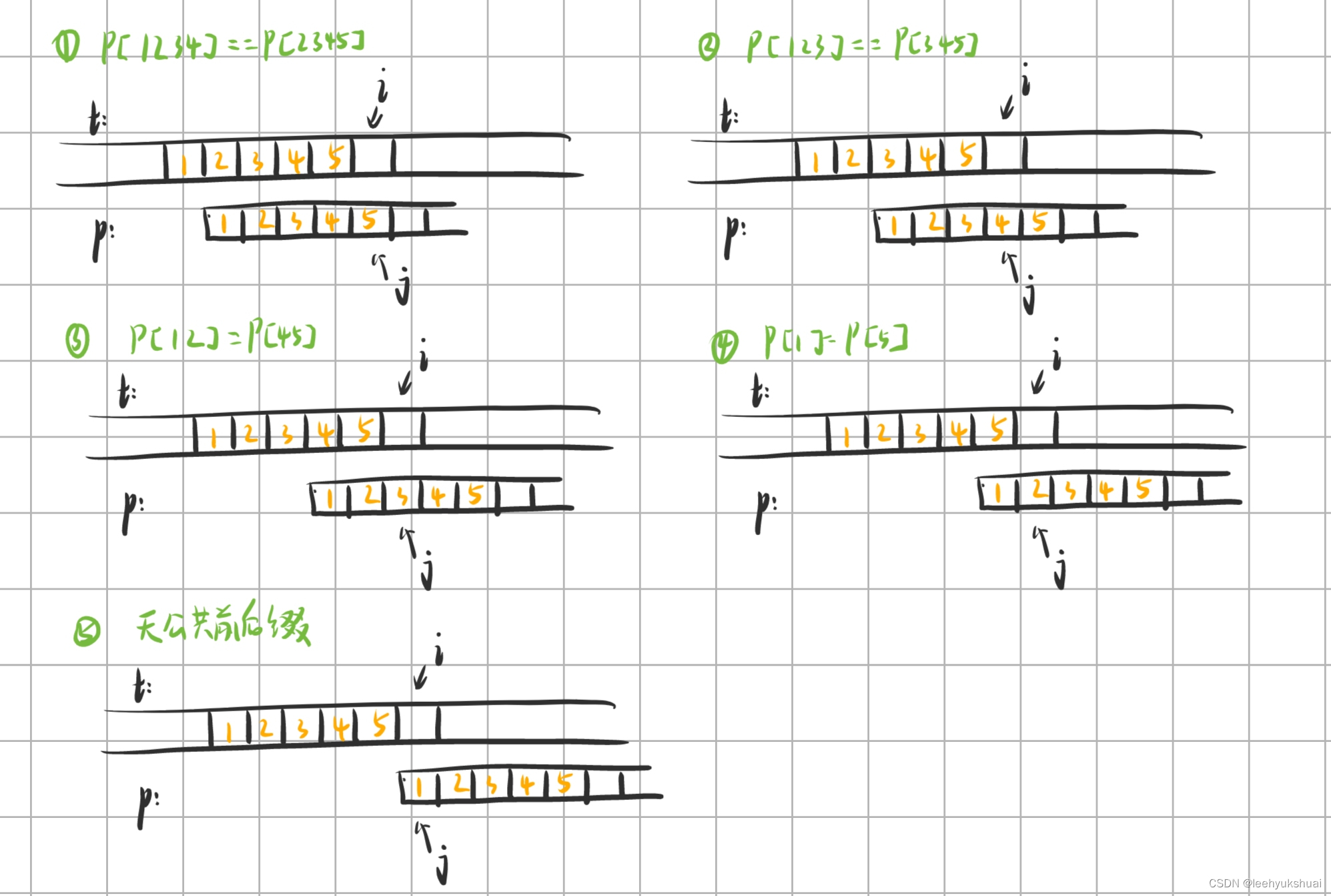
看上面这张大图可能会更能加深理解。每次回溯, i i i不用动, j j j也不用动,只需要把 p a t t e r n pattern pattern右移一定长度即可。不过根据相对运动, p a t t e r n pattern pattern右移也就相当于 j j j左移,而且 j j j左移的长度与 p a t t e r n pattern pattern的前j个字符的最长公共前后缀长度是有关系的。还是按照这个例子来,在发现 t [ i ] ! = p [ j ] t[i]!=p[j] t[i]!=p[j]时, j = = 5 j==5 j==5,回溯时,只需令 j j j等于前5个字符的最长公共前后缀长度。
现在,我们设一个数组 n e x t next next,用它来保存 p a t t e r n pattern pattern前 j j j个字符的最长公共前后缀长度。
n e x t [ j ] = m a x l e n ( p a t t e r n . s u b s t r ( 0 , j ) ) next[j] = maxlen(pattern.substr(0,j)) next[j]=maxlen(pattern.substr(0,j)),其中maxlen(str)返回str的最长公共前后缀的长度。
让我们重写一遍match函数。
int match(string t, string p) {
int n = t.length(), m = p.length();
int i = 0, j = 0;
while (i < n && j < m) {
if (t[i] == p[j]) {
i++;
j++;
} else {
j = next[j];
}
}
if (j == m) {
return i - j;
} else {
return -1;
}
}
当然,这里面还存在很多小问题,比如
j
=
0
j=0
j=0时,
n
e
x
t
[
j
]
next[j]
next[j]返回值也为
0
0
0,那么便出现死循环。因此,在遇到
t
[
i
]
!
=
p
[
j
]
t[i]!=p[j]
t[i]!=p[j]且
j
=
=
0
j==0
j==0时,我们应当控制
j
j
j不动,把
i
i
i加一。整合一下,我们不妨设**next[0]=-1**,再次改写match函数:
int match(string t, string p) {
int n = t.length(), m = p.length();
int i = 0, j = 0;
while (i < n && j < m) {
if (j == -1 || t[i] == p[j]) {
i++;
j++;
} else {
j = next[j];
}
}
if (j == m) {
return i - j;
} else {
return -1;
}
}
奈斯,改得干净漂亮~
好了,我们已经历经千辛万苦得出了 k m p kmp kmp算法的主干,那下面的主要问题就是 n e x t next next数组的计算。
计算Next数组
还是显而易见,暴力算法无往而不利:
void initNext(const string& p, int next[])
{
int m = p.length();
next[0] = -1;
for (int k = 1; k < m; ++k) {
// 寻找前k个字符的最大公共前后缀长度
for (int l = k - 1; l >= 0; --l) {
// i,j分别为前后缀的指标
int i = 0, j = k - l;
while (i < l) {
if (p[i] != p[j]) {
break;
} else {
i++;
j++;
}
}
// l为前k个字符的最大公共前后缀长度
if (i == l) {
next[k] = l;
break;
}
}
}
}
时间复杂度分析:对于每一个 k ∈ { 1 , 2 , . . . , m − 1 } k\in \{1,2,...,m-1\} k∈{1,2,...,m−1},都有 l ∈ { 0 , 1 , . . . , k − 1 } l\in\{0,1,...,k-1\} l∈{0,1,...,k−1},对于每一个 l l l,最糟糕情况下需要进行 l l l次比较,因此是一个三阶复杂度函数,其时间复杂度为 O ( m 3 ) O(m^3) O(m3)。太浪费了,我们希望尽可能多的利用已知信息推理未知信息,因此,上图分析!看看是否存在一些可以利用的信息帮助我们消除不必要的比较。
假设我们已经算出了 n e x t [ 12... k ] next[12...k] next[12...k],那么我们是否可以根据这些信息快速得出 n e x t [ ( k + 1 ) ] next[(k+1)] next[(k+1)]?
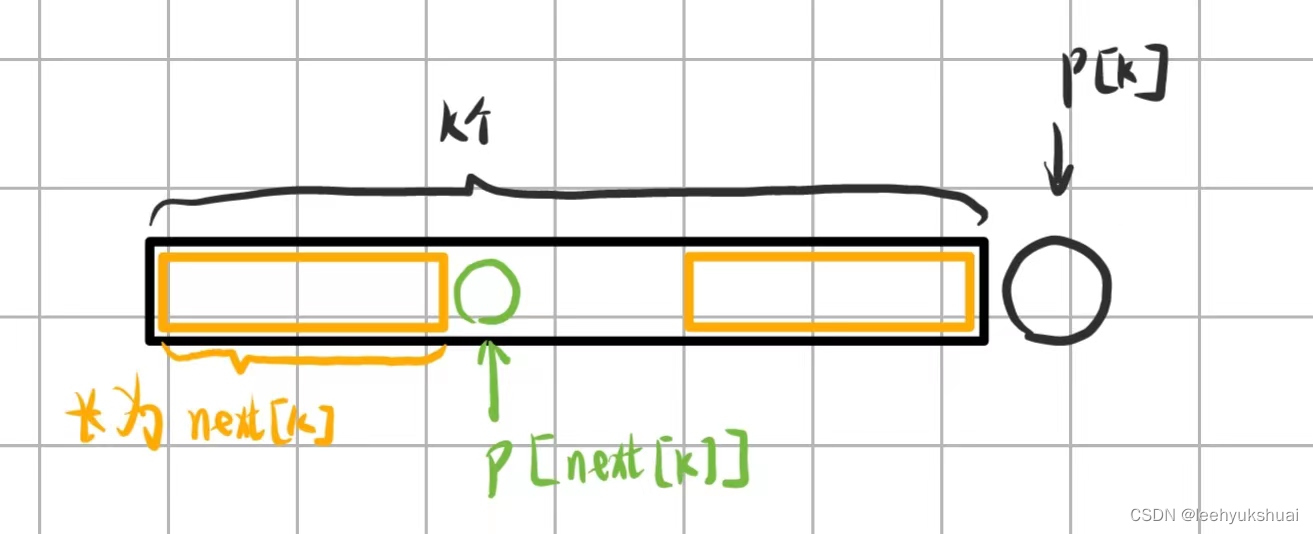
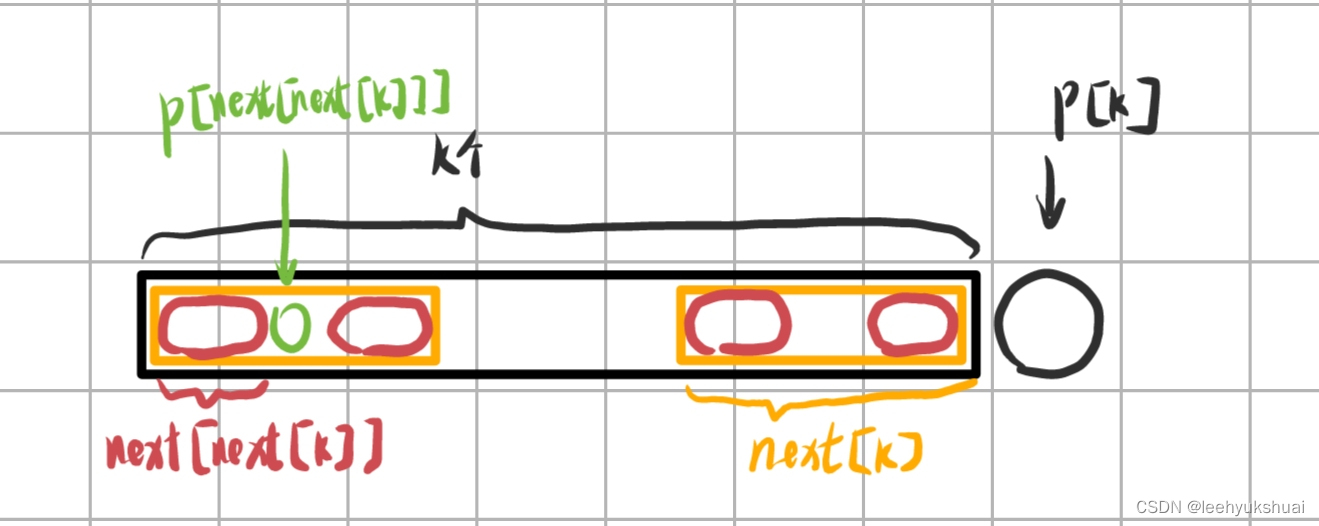
由于 n e x t [ k ] next[k] next[k]我们已经求出,所以黄色部分就是前k个字符的最长公共前后缀,那么,如果 p [ k ] = = p [ n e x t [ k ] ] p[k]==p[next[k]] p[k]==p[next[k]],我们就可以得出前 k + 1 k+1 k+1个字符的最长公共前后缀长度为next[k]+1(前k+1个字符的最长公共前后缀长度不可能超过 n e x t [ k ] + 1 next[k]+1 next[k]+1,自行证明)。而如果 p [ k ] ! = p [ n e x t [ k ] ] p[k]!=p[next[k]] p[k]!=p[next[k]],则我们退而求其次,比较 p [ n e x t [ n e x t [ k ] ] ] = = p [ k ] p[next[next[k]]]==p[k] p[next[next[k]]]==p[k],如果相等,则前 k + 1 k+1 k+1个字符的最长公共前后缀长度为 n e x t [ n e x t [ k ] ] + 1 next[next[k]]+1 next[next[k]]+1。
根据以上分析,我们可以得到求出 n e x t next next的优化代码:
void initNext(const string& p, int next[])
{
int m = p.length();
next[0] = -1;
for (int k = 1; k < m; ++k) {
int t = next[k - 1];
while (t != -1 && p[t] != p[k-1]) {
t = next[t];
}
next[k] = t + 1;
}
}
最后,再把match和initNext两个函数合并在一起,已经完成了!Congratulations!
最后一些优化
(小声嘀咕,其实是还可以再优化的,不过这一步优化其实意义不大)让我们继续优化吧!
考虑以下情况:
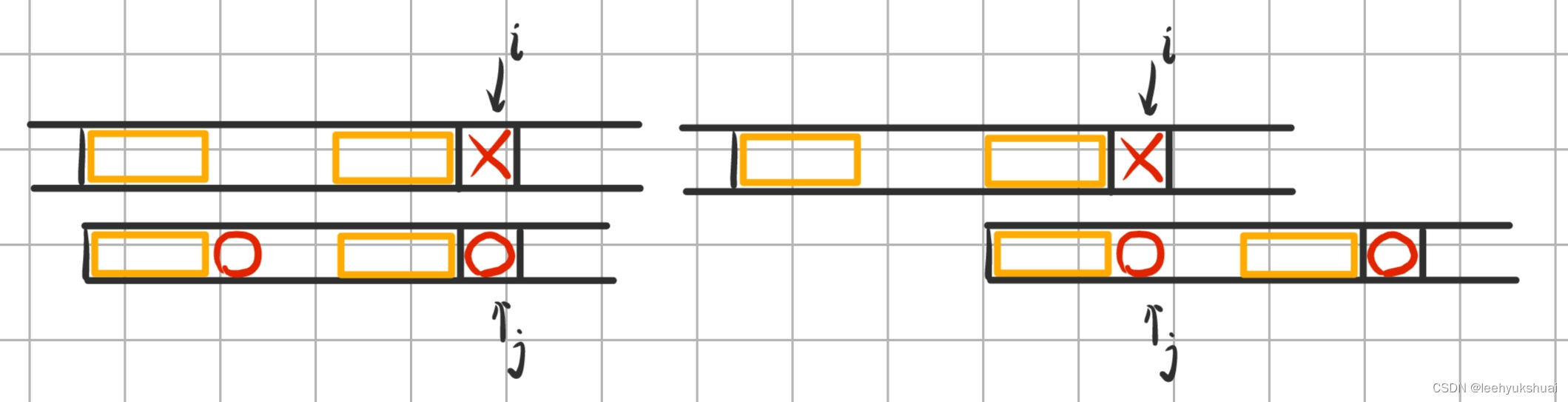
这一步优化运用的是一样的思想,也是尽可能多的利用已知信息推理未知信息。既然 t [ i ] ! = t [ j ] t[i]!=t[j] t[i]!=t[j],而且 p [ j ] = = p [ n e x t [ j ] ] p[j]==p[next[j]] p[j]==p[next[j]],那么下一次的回溯中, t [ i ] ! = p [ n e x t [ j ] ] t[i]!=p[next[j]] t[i]!=p[next[j]]也一定成立,所以这一次回溯是没有意义的。我们希望直接跳过这一种无意义的回溯,进行下一次回溯。因此,我们可以得到优化版 n e x t next next数组:
void initNext(const string& p, int next[])
{
int m = p.length();
next[0] = -1;
for (int k = 1; k < m; ++k) {
int t = next[k - 1];
while (t != -1 && p[t] != p[k-1]) {
t = next[t];
}
next[k] = t + 1;
while (next[k] != -1 && p[k] == p[next[k]]) {
next[k] = next[next[k]];
}
}
}
优化之后,就不会再出现无意义的回溯了,自然,效率也就进一步提高了。















 827
827











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









