









1.案例题
题目描述
给出两个字符串 s1和s2,其中s2为 s1的子串,求出 s2在 s1中所有出现的位置。
为了减少骗分的情况,接下来还要输出子串的前缀数组 next。
(如果你不知道这是什么意思也不要问,去百度搜 kmp算法 学习一下就知道了。)
输入格式
第一行为一个字符串,即为s1。
第二行为一个字符串,即为s2。
输出格式
若干行,每行包含一个整数,表示s2在s1中出现的位置
接下来 1 行,包括 |s2|个整数,表示前缀数组 next[i] 的值。
输入输出样例
输入
abababC
aba
输出
1
3
0 0 1
2.固用思维——暴力法(无Next数组)
2.1算法设计
- 从s1字符串的第一个字符开始,然后从s2第一个字符开始往后匹配;
- 如果出现不一致的字符,从s1下一个字符开始重新匹配;
- 如果匹配的与s2全部一致,则输出此次匹配对应的位置,再继续从s1下 一个字符开始重新匹配;
- 直到匹配到s1最后一个字符结束匹配。
2.2算法可视化流程

2.3算法时间复杂度分析
- 假设主串s1长度为m,模式串s2长度为n,那么在最坏条件下,就是从s1的每一个字符开始的匹配都会匹配到s2的最后一个字符,以此可以计算出暴力法的时间复杂度为O(m*n)。
2.4程序代码
#include<iostream>
#define MAX1 10000
#define MAX2 10000
using namespace std;
int main()
{
char s1[MAX1];
char s2[MAX2];
cin >> s1;//输入s1
cin >> s2;//输入s2
int m = 0;
int n = 0;
for (;;m++)//计算s1长度
{
if (s1[m] == '\0')
break;
}
for (;;n++)//计算s2长度
{
if (s2[n] == '\0')
break;
}
for (int i = 0;i < m;i++)//暴力匹配
{
for (int j = 0;j < n;j++)
{
if (s1[i + j] == s2[j])
{
if (j == n - 1)//匹配到s2的最后一个元素也一致,输出结果
{
cout << i + 1 << endl;
}
}
else//出现不一致的元素直接退出,s2向后移一个单位重新开始匹配
break;
}
}
return 0;
}
2.5程序测试
测试输入:
s1为aabcababbabcabcabcb
s2为abcab
预期结果应为:
2
10
13
运行结果如下:
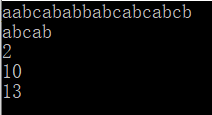
测试结果正确。
2.6结果分析
- 暴力法的思路较为简单,条理较为清晰。不足之处就是做了很多重复的匹配,导致算法的效率较低,时间复杂度太高。
- 所以在暴力法的基础上进行优化,解决重复匹配的问题,使算法的效率提高。
3.优化算法——KMP算法
3.1算法设计
- Next[]数组
- Next数组主要用来存放最大公共前后缀的长度值,此值定义为k值,即Next[]数组存储一组k值

- KMP算法的关键之处
假如匹配到如下的情况:

如果用暴力算法,下一步应为:

如果用KMP算法,下一步应为:
此时j=5,匹配失败,S[i]=“c”, T[5]=“a”,S[i]!=T[5]。
接下来继续匹配时,需要主串中S[i]位置不变,模式串位置变为T[k],现在需要求k值。根据公式k=next[j-1],需要取模式串”ABABAA”的next[]数组的第j-1=5-1=4位的数组值,此时Next[]={0,0,1,2,3,1}“,在此next[]数组中,next[4]=3,即k=3(j前面字符串”ABABA”的最长公共前后缀为"ABA”,它的长度值为3,即k=3);此时,根据KMP算法,主串i不变,模式串T向右滑动m=j-k=5-3=2位,模式串新的j值为j=k=3,见下:

这样匹配速率就快了很多。
3.2可视化流程


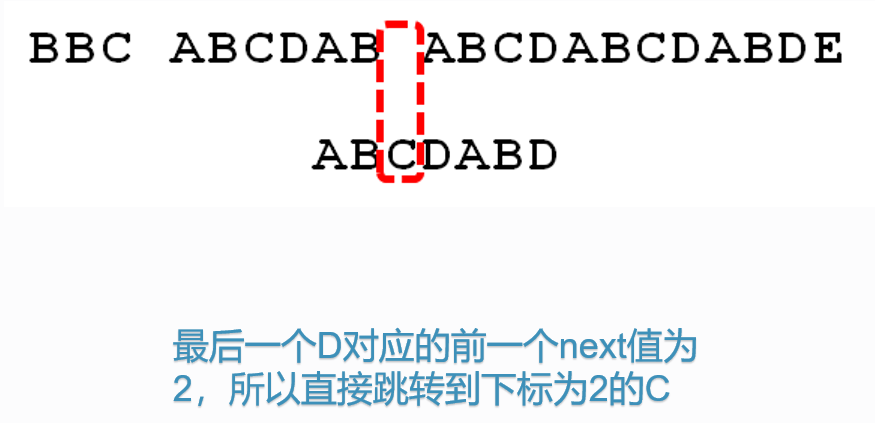


3.3算法时间复杂度分析
- 假设S主串的长度为m,T模式串的长度为n。
- 计算next数组需要将T模式串的每一个元素都求值,即时间复杂度为O(n)。
- 匹配时S中每一个元素匹配时只需要调用T相对应元素的next值来进行匹配,所以时间复杂度为O(m)。
- 算法总复杂度为O(m+n)。
3.4程序代码
#include<iostream>
#define MAX1 10000
#define MAX2 10000
using namespace std;
int main()
{
char s1[MAX1];
char s2[MAX2];
cin >> s1;//输入s1
cin >> s2;//输入s2
int m = 0;
int n = 0;
for (;;m++)//计算s1长度
{
if (s1[m] == '\0')
break;
}
for (;;n++)//计算s2长度
{
if (s2[n] == '\0')
break;
}
//建立next数组
int* next = new int[n];
next[0] = 0;
int k = 0;
int t = 1;
while (t != n)
{
if (s2[t] == s2[k])//相等时next值即为上一个元素next值加1
{
next[t] = ++k;
t++;
}
else if (k > 0)
{
k = next[k - 1];//k往前跳到上一个最大前缀序列的后一个字符
}
else
{
next[t] = 0;//k调到0位置时
t++;
}
}
//开始匹配
for (int i = 0, j = 0; i < m; i++)
{
while (j > 0 && s1[i] != s2[j])//s2下一个匹配位为next数组的第j-1位,直至j=0结束
{
j = next[j - 1];
}
if (s1[i] == s2[j])
{
j++;//主串通过i进行加1,模式串通过j加1
}
if (j == n)//s2最后一个字符匹配完成,输出,开始接下来的匹配
{
cout << i - j + 1 << endl;
j = next[j - 1];
}
}
//输出next数组
for (int i = 0;i < n;i++)
cout << next[i] << " ";
cout << endl;
return 0;
}
3.5程序测试
- 测试1
测试输入:
s1为bbcxabcdabxabcdabcdabde
s2为abcdabd
预期结果为:
16
0 0 0 0 1 2 0
运行结果如下:
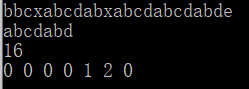
测试正确。
- 测试2
测试输入:
s1为abcabcbabcabc
s2为abcab
预期结果为:
1
8
0 0 0 1 2
运行结果为:

结果正确。
- OJ结果
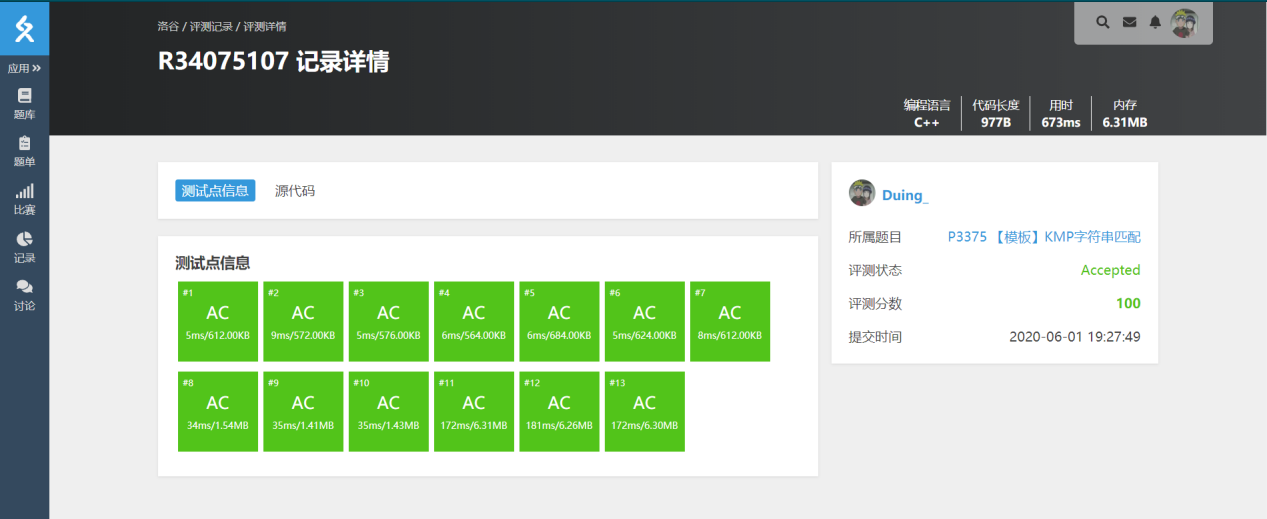
3.6结果分析
- KMP算法通过next数组存储字符串每一个元素的最大公共前后缀,根据最大公共前后缀来进行失配时的下一步匹配操作,从而巧妙地解决了暴力法在匹配时来回重复匹配的问题,大大提高了算法的效率,降低了时间复杂度。















 1517
1517











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









