







线性表(亦作顺序表)是最基本、最简单、也是最常用的一种数据结构。线性表中数据元素之间的关系是一对一的关系,即除了第一个和最后一个数据元素之外,其它数据元素都是首尾相接的。线性表有两种存储结构:
①顺序存储结构,即存储单元在一段连续的地址上存储,常见的数组就是顺序存储结构的线性表;
②链式存储结构,即存储单元在不连续的地址上存储。因为其不连续性,除了要存数据元素信息(数据域)外,还要存储它后继元素(结点)的地址(指针域,链)。学习链式结构最好将结点结构牢记于心,如下图:
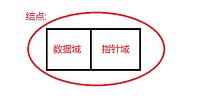
链表的每个结点只含有一个指针域就叫做单链表,单链表是其他形式链表以及其他数据结构的基础,所以是这篇文章着重讲的地方。
在这里还要先提前补充一点知识,时间复杂度与大O计法,正是因为有了这些指标,不同情况下不同数据结构有各自的优越之处。时间复杂度,记作:T(n) = O(f(n)),表示随问题规模n的增大,算法执行时间的增长率和f(n)的增长率相同,f(n)是问题规模(代码运行次数)的函数。大O阶计算方法:
①用常数1取代时间中所有的加法常数;
②修改后的运行次数函数f(n)中,只保留最高阶,并去除最高阶前面相乘的常数。
举个例子:
在数组中我们存取数据时,都只需要执行一条语句,f(n)=1,则时间复杂度为O(1);
如果需要插入或删除时,最坏情况(一般都是考虑最坏情况)是在第一个元素插入,则需要把所有元素都向后挪动一位,这样需要作n次处理则f(n)=n,时间复杂度为O(n)。
最后再介绍两个函数,就可以开始举实例了。
①void *malloc(unsigned int num_bytes)
动态分配内存指针函数,如果分配成功则返回指向被分配内存的指针(此存储区中的初始值不确定),否则返回空指针NULL。需要进行强制类型转换。
②void free(void *ptr)
释放ptr指向的存储空间。被释放的空间通常被送入可用存储区池,以后可在调用malloc等函数来再分配。
实例:单链表的各种操作,原本想分类一个函数一个函数讲,太乱了,一起摆又太长了,就当是给那些找Demo的人吧!全都是自己写的,后面的也没注释,真的很糟糕~~
#include "stdio.h"
#include "malloc.h"
#include "stdlib.h"
// 一个结点结构体
typedef struct node
{
int data; // 数据域,存放数据
struct node *next; // 指针域,存放后继结点的地址
}node;
/*
* 功能:创建一个单链表
* 输入:链表长度
* 输出:头结点的地址
*/
node *createList(int n)
{
node *h,*p,*s; // 三个结点指针,指向头结点,前驱结点,当前结点
h = (node *)malloc(sizeof(node)); // 头结点分配内存空间,返回指针强制转换为结构体指针
h->data = 0; // 头结点数据域一般不用来存放数据,它的存在意义是为了链表增加删除操作的一致性
p = h; // 前驱结点设为头结点
for(int i = 0; i < n; i++)
{
s = (node *)malloc(sizeof(node)); // 分配内存给第一个结点,而后循环
printf("输入第%d个元素:",i+1);
scanf("%d",&(s->data));
p->next = s; // 将当前结点地址赋给前驱结点的指针域,可以画个图看下
s->next = NULL; // 当前结点为最后一个结点,指针域赋给NULL
p = s; // 前驱结点变为当前结点,即当新建一个结点时,当前结点都会变为他的前驱结点
}
return h; // 返回头结点指针
}
/*
* 功能:得到链表长度
* 输入:链表的头结点
* 输出:整形
*/
int getSize(node *head)
{
int size = 0;
node *p;
p = head; // 前驱结点赋为头结点
while(p->next!=NULL) // 当前驱结点的指针域存放地址,即当前结点,不为NULL时,长度+1
{
size++;
p = p->next; // 前驱结点要向后移动一位了
}
return size;
}
/*
* 功能:得到链表特定位置的数据
* 输入:链表的头结点,获取数据的位置
* 输出:整形
*/
int get(node *h,int position)
{
int result = -1;
node *s,*p;
p = h;
s = p->next;
p = s;
for(int i = 0 ; i < position; i++)
{
s = p->next;
p = s;
}
result = s->data;
return result;
}
/*
* 功能:插入数据
* 输入:链表的头结点,插入的位置,插入的数据
* 输出:无
*/
void insert(node *h,int position,int data)
{
node *s,*p;
s = (node *)malloc(sizeof(node));
s->data = data;
s->next = NULL;
p = h;
for(int i = 0; i < position; i++)
{
p = p->next;
}
s->next = p->next;
p->next = s;
}
/*
* 功能:动态插入数据在最后一项
* 输入:链表的头结点,插入的数据
* 输出:无
*/
void insertAtLast(node *h,int data)
{
node *s,*p;
s = (node *)malloc(sizeof(node));
s->data = data;
s->next = NULL;
p = h;
while(p->next!=NULL)
{
p = p->next;
}
p->next = s;
}
/*
* 功能:删除数据
* 输入:链表的头结点,删除数据的位置
* 输出:无
*/
void remove(node *h,int position)
{
node *p,*s;
p = h;
for(int i = 0; i < position; i++)
{
p = p->next;
}
s = p->next;
p->next = s->next;
free(s);
}
/*
* 功能:寻找查找数据的第一个地址
* 输入:链表的头结点,所查数据
* 输出:结点指针
*/
node *search(node *h,int data)
{
node *p,*s;
p = h;
while(p->next->data!=data)
{
p = p->next;
}
s = p->next;
return s;
}
/*
* 功能:在特定的结点后面插入数据
* 输入:链表的头结点,插入的数据
* 输出:无
*/
void insertAfterPoint(node *point,int data)
{
node *s,*temp;
s = (node *)malloc(sizeof(node));
s->data = data;
temp = point->next;
s->next = temp;
point->next = s;
}
/*
* 功能:删除整个链表
* 输入:链表的头结点
* 输出:无
*/
void deleteList(node *h)
{
node *p,*s;
p = h->next;
while(p != NULL)
{
s = p->next;
free(p);
p = s;
}
h->next = NULL;
}
/*
* 功能:打印所有元素的值
* 输入:链表的头结点,链表长度
* 输出:无
*/
void printAll(node *h,int n)
{
for(int i = 0 ; i < n; i++)
{
printf("%d ",get(h, i)); // 打印链表的每一个值,参数是链表长度
}
}
void main(int argc, char* argv[])
{
node *head;
head = createList(4); // 创建一个四个结点的单链表,输入数据1,2,3,4
printAll(head,getSize(head)); // 1 2 3 4
printf("\n");
insert(head,1,101); // 在第二个结点插入101,0对应的是第一个结点
insertAtLast(head,102); // 最后插入102
printAll(head,getSize(head)); // 1 101 2 3 4 102
printf("\n");
remove(head,1); // 移除最后第二个结点
printAll(head,getSize(head)); // 1 2 3 4 102
printf("\n");
node *searchPoint = search(head,2); // 找到数据为2结点的地址
insertAfterPoint(searchPoint,103); // 在其后面插入103
printAll(head,getSize(head)); // 1 2 103 3 4 102
printf("\n");
deleteList(head); // 释放链表
printf("%d",getSize(head)); // 0
printf("\n");
}

如果在我们不知道第i个结点的指针位置,单链表数据结构在插入和删除操作上的时间复杂度也为O(n),但是如果要插入10个数据时,我们找到了i个结点的指针位置,插入第一个数据的算法复杂度是O(n),后面的都是O(1),而数组操作则每次都是O(n)。可见:对于插入或删除数据越频繁的操作,单链表的效率优势就越明显。
总而言之,对于单链表的操作,就是操作头结点,前驱结点,当前结点;前驱结点的指针域数据就是当前结点的指针。
除了单链表外还有循环链表(终端结点的指针域指向头结点)和双向链表(增加一个前驱结点的指针域),以后有需要时再作深入学习。















 498
498

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









