







Spark并行度原理
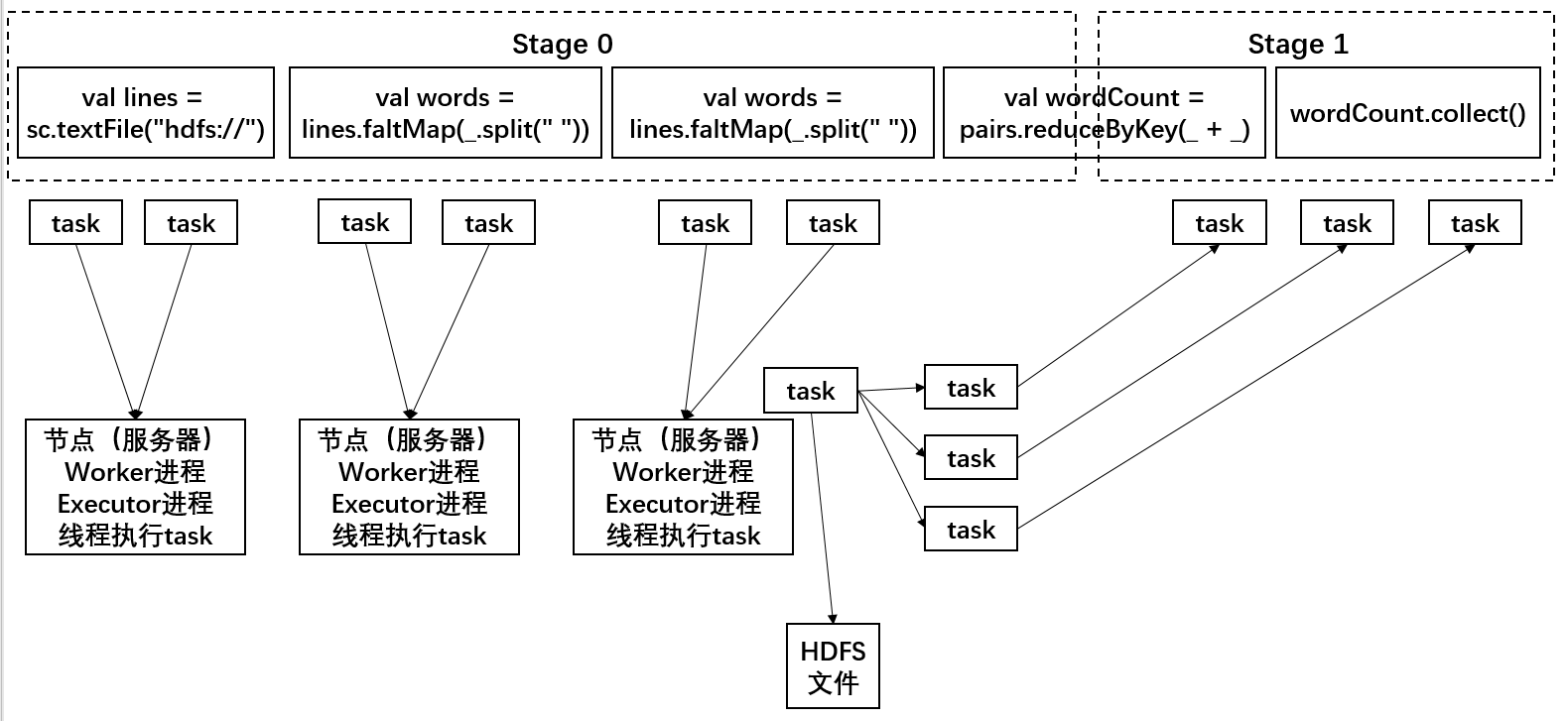
以 Spark 中的 WordCount 作业为例,每个Spark作业其实都是一个 Application,每个 Application 对应多个 Jobs,一个 action 操作(比如 collect)触发一个 job,在WordCount程序中有一个 job,每个 job 拆成多个 stage(发生 shuffle 的时候回拆分出一个 stage),reduceByKey 处会发生 shuffle。
reduceByKey 这里,相当于 stage0 的task在最后执行到 reduceByKey 的时候会为每个 stage1 的task都创建一份文件(也可能是合并在少量的文件里面),每个 stage1 的 task会去各个节点上的各个 task 创建的属于自己的那一份文件里面拉取数据,每个 stage1 的 task 拉取到的数据一定是相同 key 对应的数据。对相同的key,对应的values,才能去执行我们自定义的function操作(_ + _)。
task会找到 HDFS 上属于自己的对应数据,每个 task 处理一小块数据 HDFS block,然后依次去执行算子操作。task 默认会创建三份文件,每一个文件里面,一定是存放相同的key对应的values;但是一个文件里面可能有多个key,以及其对应的values;相同key的values一定是进入同一个文件。
下一个 stage 的每个 task 都会去上一个 stage 的 task 里拉去属于自己的那份文件。
并行度设置
(1)Spark的并行度指的是什么?
并行度其实就是指的是spark作业中,各个stage的task的数量,也就代表了spark作业在各个阶段stage的并行度!
(2)如果不调节并行度,导致并行度过低会怎么样?
假设现在已经在spark-submit脚本里面,给我们的spark作业分配了足够多的资源,比如有50个 executor,每个executor 有10G内存,每个 executor 有3个cpu core,基本已经达到了集群或者yarn队列的资源上限。
如果 task 没有设置,或者设置的很少,比如就设置了100个 task。现在50个 executor,每个executor 有3个cpu core,也就是说,你的Application任何一个 stage 运行的时候都有总数在150个 cpu core,可以并行运行。但是你现在只有100个task,平均分配一下,每个executor 分配到2个task,那么同时在运行的task只有100个,每个executor只会并行运行2个task,每个executor剩下的一个 cpu core 就浪费掉了。
你的资源虽然分配足够了,但是问题是,并行度没有与资源相匹配,导致你分配下去的资源都浪费掉了。
合理的并行度的设置,应该是要设置的足够大,大到可以完全合理的利用你的集群资源。比如上面的例子,总共集群有150个cpu core,可以并行运行150个task。那么就应该将你的Application 的并行度至少设置成150才能完全有效的利用你的集群资源,让150个task并行执行,而且task增加到150个以后,既可以同时并行运行,还可以让每个task要处理的数据量变少。比如总共150G的数据要处理,如果是100个task,每个task计算1.5G的数据,现在增加到150个task可以并行运行,而且每个task主要处理1G的数据就可以。
很简单的道理,只要合理设置并行度,就可以完全充分利用你的集群计算资源,并且减少每个task要处理的数据量,最终,就是提升你的整个Spark作业的性能和运行速度。
(3)如何去提高并行度?
1、task数量,至少设置成与spark Application 的总cpu core 数量相同(最理性情况,150个core,分配150task,一起运行,差不多同一时间运行完毕)
官方推荐,task数量,设置成spark Application 总cpu core数量的2~3倍 ,比如150个cpu core ,基本设置 task数量为 300~ 500, 与理性情况不同的,有些task 会运行快一点,比如50s 就完了,有些task 可能会慢一点,要一分半才运行完,所以如果你的task数量,刚好设置的跟cpu core 数量相同,可能会导致资源的浪费,因为 比如150task ,10个先运行完了,剩余140个还在运行,但是这个时候,就有10个cpu core空闲出来了,导致浪费。如果设置2~3倍,那么一个task运行完以后,另外一个task马上补上来,尽量让cpu core不要空闲。同时尽量提升spark运行效率和速度。提升性能。
2、如何设置一个Spark Application的并行度?
spark.default.parallelism 默认是没有值的,如果设置了值比如说10,是在shuffle的过程才会起作用
(val rdd2 = rdd1.reduceByKey(_+_) //rdd2的分区数就是10,rdd1的分区数不受这个参数的影响)
new SparkConf().set(“spark.default.parallelism”,“500”)
3、如果读取的数据在HDFS上,增加block数,默认情况下split与block是一对一的,而split又与RDD中的partition对应,所以增加了block数,也就提高了并行度。
4、RDD.repartition,给RDD重新设置partition的数量 [repartitions 或者 coalesce]
5、reduceByKey的算子指定partition的数量
val rdd2 = rdd1.reduceByKey(_+_ ,10) val rdd3 = rdd2.map.filter.reduceByKey(_+_)
6、val rdd3 = rdd1.join(rdd2) rdd3里面partiiton的数量是由父RDD中最多的partition数量来决定,因此使用join算子的时候,增加父RDD中partition的数量。
7、spark.sql.shuffle.partitions //spark sql中shuffle过程中partitions的数量

















 799
799

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









