






spark概述
什么是spark
大数据时代的计算引擎
在大数据时代中,程序需要处理的数据量可以多达TB(1024GB)甚至PB维度(1024TB),这么大的数据量使用单台服务器无法处理,一是单台服务器内存空间有限,二是单台服务器处理时间过长。所以需要将数据分布式的送入多台服务器处理,而如何管理多台服务器,如何拿到运算结果,就是大数据计算引擎需要处理的事情,Spark就是一种大数据计算引擎。
Spark的历史
Spark诞生于美国加州大学伯克利分校AMP实验室,是一种类Hadoop的计算引擎。不同的是,Hadoop的中间运算结果需要存储HDFS(一种文件系统中),因此有大量的磁盘IO开销,会导致运算速度变慢。而Spark会将中间结果存储于内存中。内存的存取速度是明显快于磁盘的。
Spark目前时Apache软件基金会旗下的项目,其官方地址是:Spark官网
Spark本身是用Scala进行开发的,这是一种面向对象的语言。我们在使用Spark开发的时候,可以选择的语言是Java、Python和Scala,一般推荐Scala,开发效率和运行效率都比较高。
Spark的特点
-
运算速度比
Hadoop快很多:得益于使用了DAG(有向无环图)来控制运算流程,Spark的运算速度比Hadoop快很多。 -
使用简答,
Spark提供了80多种高阶操作,而且支持Python、Java、Scala、R和Shell等多种编程语言。 -
提供了多种工具,
Spark包含了Spark SQL、Spark Streaming、Maching Learning Library、GraphX等适用于不同领域的框架。
Spark的架构
知道Spark是干什么的之后,我们还得知道它是如何实现这些功能的。
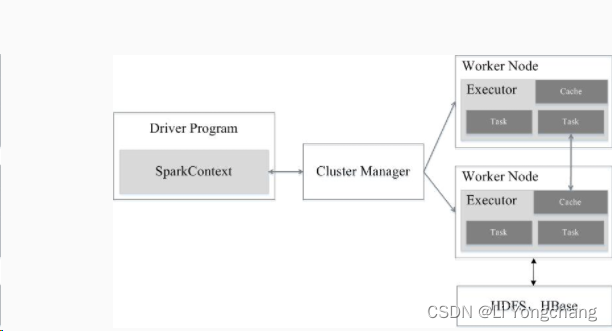
中间的Cluster Manager是集群资源管理器,一般来说,运行Spark程序需要多台服务器,它们被称为一个集群。集群计算管理器就是负责分配、调遣集群中的设备资源,包括内存、CPU等。
Worker Node是工作节点,可以简单的理解为一个服务器(当然实际情况比这个复杂),其中的Executor负责程序的具体执行,Cache是缓存,用于加快计算;Task值具体的任务。
HDFS、HBase是存储系统,HDFS是分布式文件存储系统,HBase是一种分布式的数据库。
Driver Program是应用的任务控制节点,SparkContext是运行过程中的上下文。















 1299
1299











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









