






 在使用SQL查询并限制数据量后进行DAG(有向无环图)操作,如df=hc.sql(...limit1000),后续的join操作可能会因两次limit分别从不同分区选取数据而导致无法匹配,从而返回空结果。理解数据处理中的分区和limit作用至关重要,以避免类似问题。
在使用SQL查询并限制数据量后进行DAG(有向无环图)操作,如df=hc.sql(...limit1000),后续的join操作可能会因两次limit分别从不同分区选取数据而导致无法匹配,从而返回空结果。理解数据处理中的分区和limit作用至关重要,以避免类似问题。
1. df = hc.sql(..... limit 1000) # limit 具有随机性
然后df2 = df.xxx df3 = df2.xxx
经过一系列操作后 df4 = df3.join(df) # join出来会是空置,因为是两条DAG合并,df3是一条DAG,执行了limit , df是一条DAG,也执行了limit,两次limit的可能是从不同的分区各拿的1000条数据,因此join不上,join为空。图示如下:
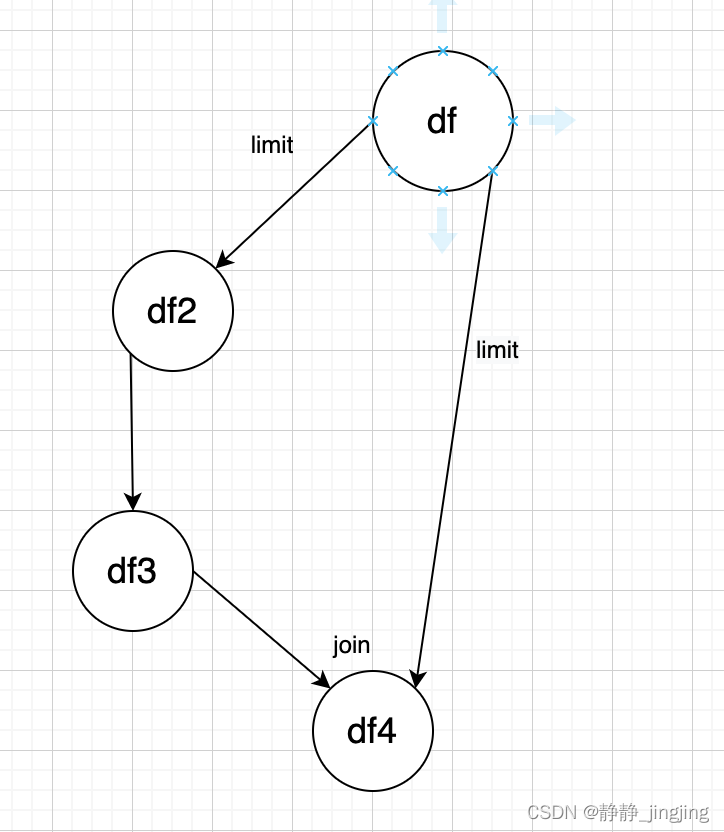

1. df = hc.sql(..... limit 1000) # limit 具有随机性
然后df2 = df.xxx df3 = df2.xxx
经过一系列操作后 df4 = df3.join(df) # join出来会是空置,因为是两条DAG合并,df3是一条DAG,执行了limit , df是一条DAG,也执行了limit,两次limit的可能是从不同的分区各拿的1000条数据,因此join不上,join为空。图示如下:
 731
731

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























