







目录
摘要
最近,基于目标的多轨迹预测方法被证明是有效的,它们首先对过采样的候选目标进行评分,然后从中选择最终集合。然而,这些方法通常涉及基于稀疏预定义锚点和启发式目标选择算法的目标预测。在这项工作中,我们提出了一种名为 DenseTNT 的无锚点和端到端轨迹预测模型,它直接从密集目标候选中输出一组轨迹。此外,我们引入了一种基于离线优化的技术,为最终在线模型提供多个未来的伪标签。
1 前言
动机:
方法:
为了模拟这种高度的不确定性,一些方法通过从潜在变量表示的分布中采样来预测多个未来轨迹,例如VAE [19, 37] 和 GAN [14]。 其他方法生成一组轨迹,但仅在训练期间对最接近的轨迹执行回归 [14,21,8],即使用多样性损失。然而,基于抽样的方法无法输出未来预测的可能性,并且品种损失在输出上缺乏可解释性。
目前最先进的方法就是基于目标的方法。他们的主要观察是目标(端点)承载了轨迹的大部分不确定性,因此他们首先预测智能体的目标,然后进一步完成每个目标的相应完整轨迹。最终的目标位置是通过对预定义的稀疏锚点进行分类和回归得到的,如图 1 的左下部分所示。例如,TNT [40] 将锚点定义为在车道中心线上采样的点;其他一些人[38]将车道段作为锚点,并为每个车道段预测一个目标。这些方法通常采用的另一种技术是应用基于规则的算法来选择最终的少量目标。最值得注意的算法是非极大值抑制 (NMS) [40],其中仅选择局部高分目标。
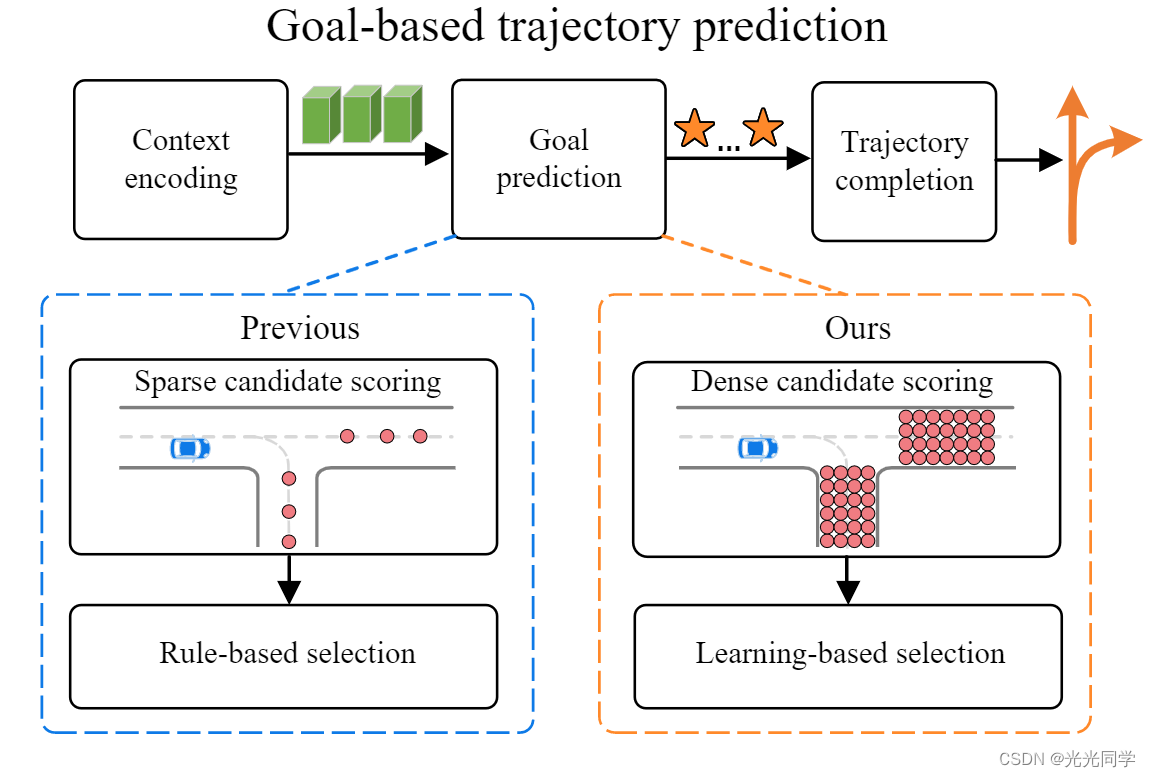
图1 典型的基于目标的轨迹预测流水线如图上部所示。现有的目标预测方法(左下)首先启发式地定义稀疏目标anchors,并对这些anchors进行回归和分类以估计目标;然后使用非最大抑制(NMS)等规则进行目标选择。相比之下,我们的方法(右下)在不依赖启发式锚(无锚)的情况下估计密集目标候选者的概率。它通过以端到端方式生成一组目标来摆脱基于规则的后处理。最近,基于目标的方法 [40, 32, 38] 得到了普及并取得了最先进的性能。他们的主要观察是目标(端点)承载了轨迹的大部分不确定性,因此他们首先预测代理的目标,然后进一步完成每个目标的相应完整轨迹。最终的目标位置是通过对预定义的稀疏锚点进行分类和回归得到的,如图 1 的左下部分所示。例如,TNT [40] 将锚点定义为在车道中心线上采样的点;其他一些人[38]将车道段作为锚点,并为每个车道段预测一个目标。这些方法通常采用的另一种技术是应用基于规则的算法来选择最终的少量目标。最值得注意的算法是非极大值抑制 (NMS) [40],其中仅选择局部高分目标。
这些方法的局限性有两个。首先,这些方法的预测性能在很大程度上取决于目标锚的质量。模型不能围绕一个锚点进行多个轨迹预测。此外,基于稀疏锚的方法无法捕获细粒度信息,即同一车道段上的不同位置包含不同的局部信息,例如到最近车道边界的相对距离。此外,在估计稀疏目标的概率后,NMS 用于启发式选择目标集,这是一种贪心算法,鉴于问题的多模态性质,不能保证找到最优解。
DenseTNT 首先从场景上下文中生成具有概率的密集目标候选;根据目标概率,它进一步使用目标集预测器来生成最终的轨迹目标集。与以前的方法相比,DenseTNT 更好地对候选目标进行建模并摆脱了后处理。
DenseTNT 中的目标集预测是一个多标签预测问题,需要多个标签作为训练目标。为了解决这个问题,我们设计了一个离线模型来为我们的在线模型提供多个未来的伪标签。与上述在线模型相比,离线模型使用优化算法代替目标集预测器进行目标集预测。优化算法从目标的概率分布中寻找最优目标集;然后将目标集用作训练在线模型的伪标签。
2 相关工作
地图编码
两大类,光栅化编码和向量化编码。
光栅化编码:将高清地图元素与代理一起光栅化为图像,并使用 CNN 对图像进行编码。
矢量化编码:他们将每个实体(车道或代理)视为一组稀疏元素,并使用图神经网络来提取实体的特征和不同实体之间的交互。
与这些仅考虑高清地图的车道中心线或车道边界的矢量化方法不同,本文对道路上的密集空间位置进行建模。
基于目标的轨迹预测
[25] 将行人的目标作为潜在变量引入,从而将预测问题转化为规划问题。
[40]首先从路线图中采样锚点并生成以这些锚点为条件的轨迹。然后对轨迹进行评分,并使用非最大抑制(NMS)来选择最终的一组轨迹。
LaneRCNN [38] 的解码管道将车道段视为锚点并输出每个锚点的概率,然后如果两个预测太接近,则使用 NMS 去除重复目标
DROGON [7] 专注于一个不同的任务,即给定个体代理的有意目的地。
他们创建了一个轨迹预测数据集来研究面向目标的行为,并使用条件 VAE 框架来预测多个可能的轨迹。
与之前的作品相比,DenseTNT 是一种基于目标的无锚模型,可以端到端的方式学习。使用 CNN 生成热图并设计用于目标采样的贪心算法的并行工作 HOME [12] 与我们的密集概率估计非常相似。
3 方法
DenseTNT首先利用稀疏(矢量化)编码方法来提取特征,该方法捕获高清地图的结构特征(第 3.1 节)。然后使用密集的目标编码器来生成目标的概率分布(第 3.2 节)。最后,目标集预测器将目标的概率分布作为输入,并直接生成一组目标(第 3.3 节)。为了训练模型,更具体地说是目标集预测器,设计一个基于优化的离线模型,它产生用于监督的伪标签
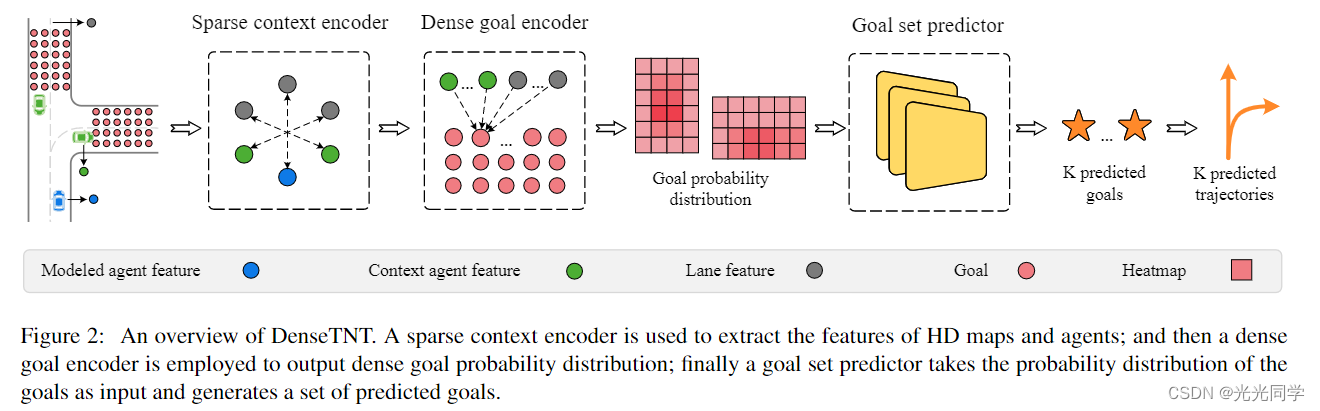
3.1稀疏上下文编码
提取车道和智能体的特征并捕获它们之间的交互。最近提出了稀疏编码方法 [11, 21](也称为矢量化方法)。与将车道和代理光栅化成图像并使用 CNN 提取特征的光栅化编码方法相比,稀疏编码方法将所有地理实体(例如车道、交通信号灯)和车辆抽象为折线,并更好地捕捉道路的结构特征。
使用VectorNet对高清地图进行编码,得到一个二维特征矩阵 L,其中每一行 Li 表示第 i 个地图元素(即车道或代理)的特征。
3.2.密集目标概率估计
TNT [40] 在道路上定义离散的稀疏锚点,然后为其分配概率值,但稀疏锚点并不是道路上真实概率分布的完美近似,因为(1)一个锚点只能生成一个目标,不能围绕一个锚点进行多个轨迹预测; (2) 基于稀疏锚点的方法无法捕获细粒度信息,即同一车道段上的不同位置包含不同的局部信息,例如到最近车道边界的相对距离。
本文改为在地图上执行密集目标概率估计,以便目标预测是无锚定的。
车道分数
在计算目标概率之前,先进行车道评分来建模车辆未来选择的车道,这样可以减少候选目标的数量。作为更高层次的抽象,每条车道上有数十个目标。通过对车道进行评分,我们可以过滤掉不在候选车道上的目标候选,从而减少后期的计算。
车道的评分被建模为分类问题,二元交叉熵损失 Llane 用于训练。离ground truth目标最近的车道的ground truth得分为1,其他为0。
![]()
概率估计
密集目标编码器使用注意机制来提取目标和车道之间的局部信息。我们首先通过使用 MLP 编码目标的 2D 坐标来获得目标的初始特征矩阵 F。目标和车道之间的局部信息可以通过注意力机制获得:
![]()
![]()
![]() 是线性投影的参数矩阵,dk 是查询/键/值向量的维度,F、L 分别是密集目标候选和所有地图元素(即车道或代理)的特征矩阵。
是线性投影的参数矩阵,dk 是查询/键/值向量的维度,F、L 分别是密集目标候选和所有地图元素(即车道或代理)的特征矩阵。
第 i 个目标的预测得分可以写成:

其中可训练函数 g(·) 也使用 2 层 MLP 实现。用于训练稀疏上下文编码器和密集概率估计的损失项是预测目标得分 φ 和地面实况目标得分 ψ 之间的二元交叉熵损失:
![]()
离最终位置最近的目标的ground truth score为1,其他为0
3.3 目标集预测
通过上面的密集概率估计,我们获得了一个热图,指示轨迹的最终位置的概率分布。
我们的目标是在不同的模式中选择最有可能的目标,即热图中的一些独特的峰值。典型的基于目标的轨迹预测管道采用非最大抑制(NMS)进行目标选择。然而,NMS 无法灵活处理各种情况,因为不同的热图具有不同的最佳 NMS 阈值,如图 4 所示。
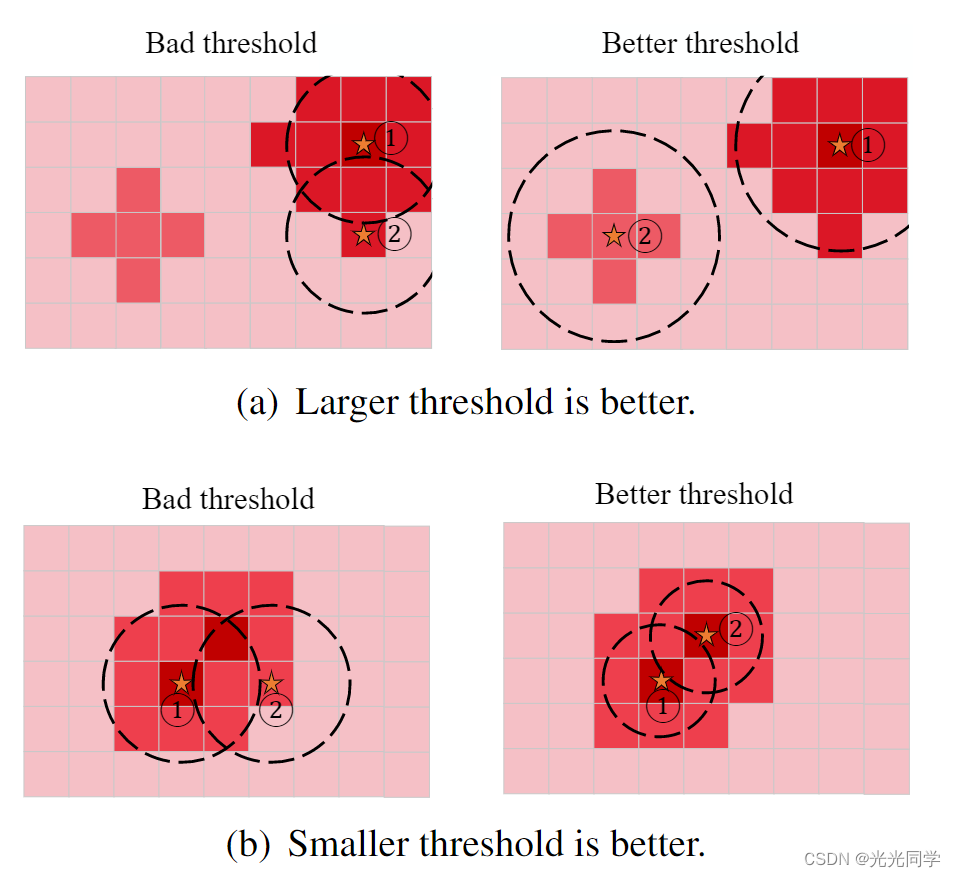
图 4:NMS 导致目标选择不理想。上例需要较大的阈值,而下例需要较小的阈值。橙色星星表示不同热图的不同 NMS 阈值的选定目标 (K = 2),NMS 阈值被描述为圆的半径。
我们的发现是目标选择可以建模为一个集合预测任务,因此我们设计了一个目标集合预测器,以这个热图作为输入并以端到端的方式生成目标集合。然而,与具有多个标签框 [2] 的目标检测不同,在轨迹预测问题中,我们只能从许多可能的未来中观察到一个真实的未来。为了解决这个问题,我们设计了一个离线模型来为我们的在线模型(更具体地说,目标集预测器)提供多个未来的伪标签。离线模型由与在线模型相同的编码模块组成,但使用优化算法代替目标集预测器。下面,我们首先介绍优化算法,然后详细介绍我们的目标集预测器。目标集预测器的训练过程如图 3 所示。
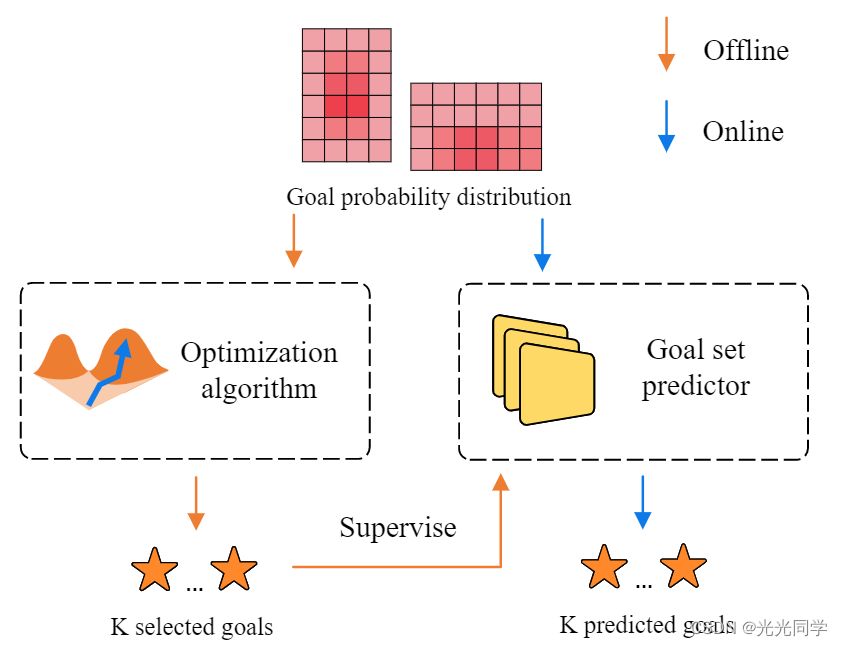
图 3:目标集预测器的两阶段训练。在第一阶段,我们使用地面实况目标来训练除目标集预测器之外的所有模块。在第二阶段,我们只训练目标集预测器,使用优化算法生成的伪标签。
优化(离线)

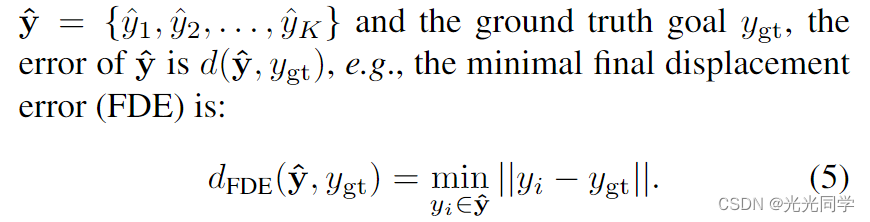

优化算法是通过比较各种解决方案迭代执行的过程,直到找到最佳或满意的解决方案。我们在本文中采用了爬山算法,这是一种迭代算法,每一步都试图对当前解决方案进行增量更改。该算法的细节在算法 1 中描述。

![]()

目标集预测器(在线)
集合预测器是由 DETR [2] 引入的,它将对象检测视为一个集合预测问题,并基于匈牙利匹配设计了一个损失。在这个多未来预测问题中,这是个多未来预测的问题,可以当作一个集合预测的问题,使用离线模型的输出作为为标签来训练在线模型的目标集预测器。 但不是在预测目标和伪标签集之间执行匈牙利匹配,而是在训练期间执行离线优化,使用每个优化的伪标签来监督其相应的预测目标。
将目标集预测器在当前训练步骤生成的 K 个预测目标集表示为![]() ,然后使用上面的优化算法为这个训练步骤生成伪标签
,然后使用上面的优化算法为这个训练步骤生成伪标签![]() 。优化算法的初始目标集设置为预测目标集
。优化算法的初始目标集设置为预测目标集 ![]() ,优化算法只搜索其局部最优。在运行时,随机扰动 L(L = 100) 次以获得 L 个目标集。当前训练步骤中目标集预测器的伪标签 y 是具有最低预期误差的目标集。
,优化算法只搜索其局部最优。在运行时,随机扰动 L(L = 100) 次以获得 L 个目标集。当前训练步骤中目标集预测器的伪标签 y 是具有最低预期误差的目标集。
损失项是预测目标集 ![]() 和伪标签
和伪标签 ![]() 之间的偏移量:
之间的偏移量:
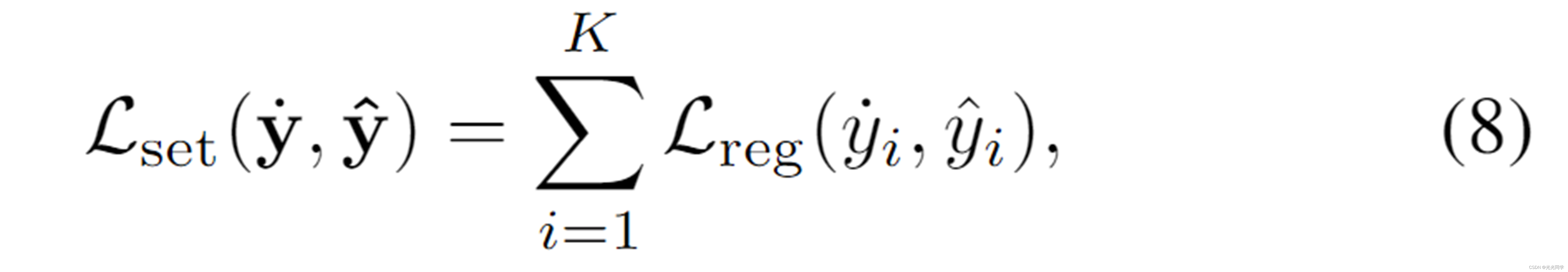
![]() 是两个目标之间的标准
是两个目标之间的标准![]() 损失。
损失。
由于热图指示的概率分布是多样的,单个回归量很难处理。目标集预测器有多个头来同时预测 N 个目标集。具体来说,每个head会预测2K+1个值,包括K个目标的2D坐标和这个head的置信度。每个head都由热图编码器和解码器组成。热图编码器是一层自注意力,后跟一个最大池,解码器是一个输出 2K + 1 个值的两层 MLP。共享所有head的热图编码器的参数以减少计算量。
在训练期间,优化算法只为具有最低预期误差的head生成伪标签,并且目标集预测器只对这个head部执行回归。为了预测多个head的置信度,我们使用二元交叉熵损失:
![]()
其中 μ 是头部的预测置信度,ν 是置信度标签
对于具有最低预期误差的head,νi = 1,对于其他磁头,νi = 0.
在推理期间,我们将置信度最高的头部作为目标集预测器的输出。
3.4.轨迹完成
最后一步是完成以预测目标为条件的每条轨迹,我们首先计算类似于上述密集目标编码的每个目标的特征,然后将其传递给作为 2 层 MLP 的解码器。解码器的输出是整个轨迹![]()
我们只有一个地面真实轨迹,因此我们通过在训练期间提供地面真实目标来应用教师强制技术 [33]。损失项是预测轨迹![]() 与真实轨迹 s 之间的偏移量:
与真实轨迹 s 之间的偏移量:
![]()
![]() 是两个目标之间的平滑
是两个目标之间的平滑![]() 损失,在推理过程中,该轨迹完成模块用于同时生成 K 个目标的 K 个轨迹。
损失,在推理过程中,该轨迹完成模块用于同时生成 K 个目标的 K 个轨迹。
3.5.学习
我们方法的训练过程有两个阶段。在第一阶段,我们使用地面实况轨迹来训练除目标集预测器之外的所有模块:
![]()
在第二阶段,我们在训练集上训练目标集预测器,由离线模型生成的伪标签监督(编码+优化算法):
![]()


















 1883
1883

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









