







SparkML中BlockMatrix内部原理
下面通过阅读源码,同时结合下面矩阵来说明一下BlockMatrix内部的原理
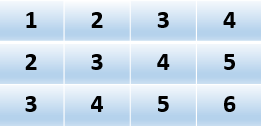
1.CoordinateMatrix
中文的理解意思是坐标矩阵,他的存储形式是COO(具体的存储可以查看文献1),存储的函数:
MatrixEntry(i: Long, j: Long, value: Double),CoordinateMatrix源码的定义:
class CoordinateMatrix @Since("1.0.0") ( @Since("1.0.0") val entries: RDD[MatrixEntry], private var nRows: Long, private var nCols: Long) extends DistributedMatrix {/*集合体*/}它通过辅助构造器:
def this(entries: RDD[MatrixEntry]) = this(entries, 0L, 0L)
可以转换为MatrixEntry类型的RDD.那么对于上面所给矩阵CoordinateMatrix内部RDD存储数据如下:
2.BlockMatrix
分块矩阵的定义可以参考线性代数方面的书籍,在此不赘述。下面通过CoordinateMatrix转换为BlockMatrix来阐述矩阵的分块原理。源码如下:
def toBlockMatrix(rowsPerBlock: Int, colsPerBlock: Int): BlockMatrix = { require(rowsPerBlock > 0, s"rowsPerBlock needs to be greater than 0. rowsPerBlock: $rowsPerBlock") require(colsPerBlock > 0, s"colsPerBlock needs to be greater than 0. colsPerBlock: $colsPerBlock") val m = numRows() val n = numCols() val numRowBlocks = math.ceil(m.toDouble / rowsPerBlock).toInt val numColBlocks = math.ceil(n.toDouble / colsPerBlock).toInt val partitioner = GridPartitioner(numRowBlocks, numColBlocks, entries.partitions.length) val blocks: RDD[((Int, Int), Matrix)] = entries.map { entry => val blockRowIndex = (entry.i / rowsPerBlock).toInt val blockColIndex = (entry.j / colsPerBlock).toInt val rowId = entry.i % rowsPerBlock val colId = entry.j % colsPerBlock ((blockRowIndex, blockColIndex), (rowId.toInt, colId.toInt, entry.value)) }.groupByKey(partitioner).map { case ((blockRowIndex, blockColIndex), entry) => val effRows = math.min(m - blockRowIndex.toLong * rowsPerBlock, rowsPerBlock).toInt val effCols = math.min(n - blockColIndex.toLong * colsPerBlock, colsPerBlock).toInt ((blockRowIndex, blockColIndex), SparseMatrix.fromCOO(effRows, effCols, entry)) } new BlockMatrix(blocks, rowsPerBlock, colsPerBlock, m, n) }第一步:根据自己想把矩阵分成什么样的形式,比如我想子矩阵是2x2的形式,那么分块为:
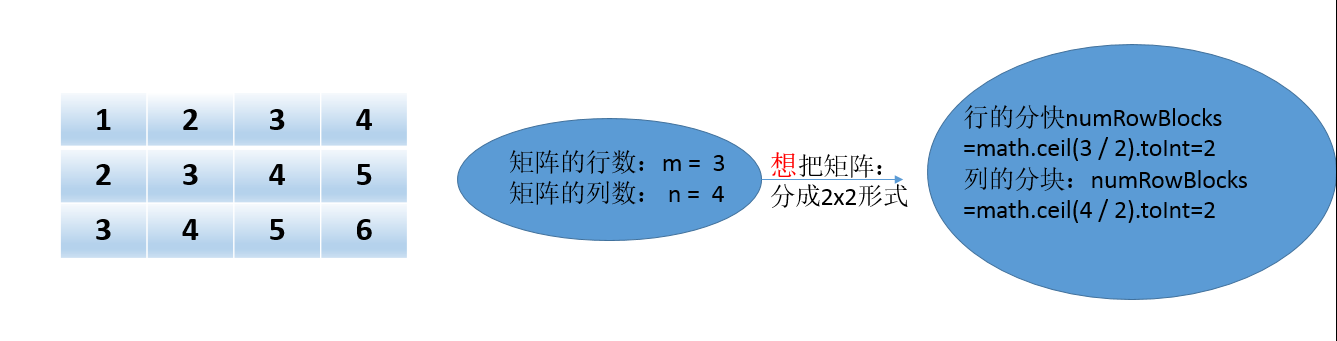
第二步:矩阵是分成2x2的形式,那么子矩阵的元素分类情况如下:

第三步:得到一个blocks为((blockRowIndex, blockColIndex), SparseMatrix.fromCOO(effRows, effCols, entry))的形式
比如右下角元素6(2,3) 存储为((1,1),Sparse.Matrix.from(0,1,6))
第四步:返回BlockMatrix(blocks, rowsPerBlock, colsPerBlock, m, n)這样形式的分块矩阵,其中blocks就是第三步的blocks,rowsPerBlock和colsPerBlock就是自己想要分成矩阵的行和列,m,和n就是原始矩阵的行和列(m=3,n=4)
3.转换为BlockMatrix实验
package Basic import org.apache.spark.mllib.linalg.distributed._ import org.apache.spark.SparkContext import org.apache.spark.mllib.linalg.Vectors import org.apache.spark.SparkConf object BlocKMatrix { def main(args: Array[String]) { val sparkConf = new SparkConf().setAppName("BlocKMatrix").setMaster("local") val sc = new SparkContext(sparkConf) val rdd1= sc.parallelize( Array( Array(1.0,2.0,3.0,4.0), Array(2.0,3.0,4.0,5.0), Array(3.0,4.0,5.0,6.0) ) ).map(f => Vectors.dense(f)) //创建RowMatrix //http://spark.apache.org/docs/latest/api/scala/index.html#org.apache.spark.mllib.linalg.distributed.RowMatrix val rowMatrix = new RowMatrix(rdd1) val coordinateMatrix:CoordinateMatrix= rowMatrix.columnSimilarities() val blockMatrix1:BlockMatrix=coordinateMatrix.toBlockMatrix(2, 2) blockMatrix1.blocks.collect.foreach(println) //IndexedRowMatrix转换为BlockMatrix implicit def double2long(x:Double)=x.toLong val rdd2= sc.parallelize( Array( Array(1.0,2.0,3.0,4.0), Array(2.0,3.0,4.0,5.0), Array(3.0,4.0,5.0,6.0) ) ).map(f => IndexedRow(f.take(1)(0),Vectors.dense(f.drop(1)))) val indexRowMatrix = new IndexedRowMatrix(rdd2) //将IndexedRowMatrix转换成BlockMatrix,指定每块的行列数 val blockMatrix2:BlockMatrix=indexRowMatrix.toBlockMatrix(2, 2) blockMatrix2.blocks.collect.foreach(println) /**((0,0),2 x 2 CSCMatrix (1,0) 2.0 (1,1) 3.0) ((1,1),2 x 1 CSCMatrix (0,0) 5.0 (1,0) 6.0) ((1,0),2 x 2 CSCMatrix (0,0) 3.0 (1,0) 4.0 (0,1) 4.0 (1,1) 5.0) ((0,1),2 x 1 CSCMatrix (1,0) 4.0) * 分析:第一列元素1,2,3因为做index了所以分块矩阵没有它们 * */ sc.stop() } }
完毕
参考文献:
http://www.cnblogs.com/xbinworld/p/4273506.html?utm_source=tuicool&utm_medium=referral
感谢















 3434
3434

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









