







相关性分析
得到: corOfHW = 0.6124
Spearman等级相关系数:
具体函数的定义,可以参考文献1。下面对思想进行简单阐述:A 的身高149,在身高這一列秩为1(最矮)。同理后面的参数就是所说变量的秩。Spearman等级相关系数(rho)如下:
相关性分析是考察两个变量之间的线性关系的一种统计方法,用于衡量两个变量因数的相关程度。但是,请记住,相关性不等于因果性。接下来结合下图的txt格式的文件来对相关性分析进行了解。
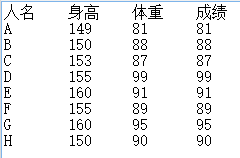
两个重要的要素
从非常直观的分析思路来说,比如分析身高和体重,我们会问个问题:.身高越高,体重是不是越重?问题细分为两个方向:1,身高越高,体重越重还是越轻。2,身高每增加 1 ,体重又是增加多少或减少多少。這就是相关性的两个重要要素:相关的方向和相关的强度。对于相关的方向很好理解,就是正相关、负相关还是无关。对于问题2,有不同的人产生了不同的 定义相关性强度的思想。
皮尔逊相关系数
皮尔逊相关系数全称为:皮尔逊积矩相关系数(Pearson product-moment correlation coefficient).该系数广泛用于度量两个变量之间的相关程度。它是由卡尔·皮尔逊从弗朗西斯·高尔顿在19世纪80年代提出的一个相似却又稍有不同的想法演变而来.定义的公式如下:

下面通过Matlab代码来计算身高和体重的pearson系数:
<pre name="code" class="python"><pre name="code" class="plain">function coeff = pearsoncoeff(x,y)
%目的:计算数值序列x和y的皮尔逊相关系数
%
%输入:计算数值序列x和y
%输出:coeff数值序列x和y的皮尔逊相关系数
if length(x)~=length(y)
error('输入的序列长度不一')
end
a = sum((x-mean(x)).*(y-mean(y)));%分子
b=sqrt(sum((x-mean(x)).^2)*sum((y-mean(y)).^2));%分母
coeff = a/b;
end
function processing
filename = 'C:\Users\andrew\Desktop\child.txt';
delimiter = '\t';
formatSpec = '%s%f%f%f%[^\n\r]';
fileID = fopen(filename,'r');
dataArray = textscan(fileID, formatSpec, 'Delimiter', delimiter, 'ReturnOnError', false);
fclose(fileID);
%A = dataArray{:, 1};%name
high = dataArray{:, 2};
weight = dataArray{:, 3};
%score = dataArray{:, 4};
%计算身高和体重的相关系数
corOfHW = pearsoncoeff(high,weight)
end
得到: corOfHW = 0.6124
Spearman等级相关系数:
具体函数的定义,可以参考文献1。下面对思想进行简单阐述:A 的身高149,在身高這一列秩为1(最矮)。同理后面的参数就是所说变量的秩。Spearman等级相关系数(rho)如下:
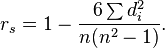
其中累加di平方就是A身高的秩减去体重的秩平方加上B身高的秩减去体重的秩平方。。。。。。。发现spearman等级相关系数,和具体的数值无关,之和其中的秩有关系,它适用于不能准确测量指标值而只能以严重程度,名词先后等等级参数来确定之间的相关程度。
通过计算可以得到:0.7395
SparkMLlib计算相关系数:
package Basic import org.apache.spark.mllib.linalg.Vectors import org.apache.spark.mllib.stat.Statistics import org.apache.spark.{SparkConf, SparkContext} /** * Created by legotime on 2016/4/8. */ object Correlations { def main(args: Array[String]) { val sparkConf = new SparkConf().setAppName("Correlations").setMaster("local") val sc = new SparkContext(sparkConf) val rdd1= sc.parallelize( Array( Array(1.0,2.0,3.0,4.0), Array(2.0,3.0,4.0,5.0), Array(3.0,4.0,5.0,6.0) ) ).map(f => Vectors.dense(f)) //package org.apache.spark.mllib.stat下的一些基本操作 val summary = Statistics.colStats(rdd1) println(summary.mean) // a dense vector containing the mean value for each column每列的平均值 println(summary.variance) // column-wise variance,列方差 println(summary.numNonzeros) // number of nonzeros in each column每列非零个数 println(summary.normL2)//二范数 println(summary.max)//每列最大 //==================================计算相关性系数=================================== //val rdd2 = sc.parallelize(Array(1.0,2.0,3.0,4.0)) //val rdd3 = sc.parallelize(Array(2.0,3.0,4.0,5.0)) val rdd2 = sc.parallelize(Array(149.0,150.0,153.0,155.0,160.0,155.0,160.0,150.0)) val rdd3 = sc.parallelize(Array(81.0,88.0,87.0,99.0,91.0,89.0,95.0,90.0)) println("rdd2:"+rdd2) rdd2.collect().foreach(println) //val correlation1:Double = Statistics.corr(rdd2, rdd3, "pearson") //省却的情况下,默认的是pearson相关性系数 val correlation1:Double = Statistics.corr(rdd2, rdd3) println("pearson相关系数:"+correlation1) //pearson相关系数:0.6124030566141675 val correlation2:Double = Statistics.corr(rdd2, rdd3, "spearman") println("spearman相关系数:"+correlation2) //spearman相关系数:0.7395161835775294 sc.stop() } }
完毕
参考文献
1:http://blog.csdn.net/wsywl/article/details/5859751
感谢















 641
641

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









