







前面已经陈述过logistic的理论的了,在此就不赘述了(http://blog.csdn.net/legotime/article/details/51312393)
Logistic 函数(分类时有个名字叫Sigmoid函数)如下:
logistic函数早期是用于人口预测的。但随着人们对其的应用扩展,开始慢慢应用于分类问题,而且是神经网络中一个
经常使用的过渡函数,图1是将logistic函数

图1
它的原理是:在分二类的情况下,当h的计算值大于0.5时,让h等于1,h的计算值小于等于于0.5时,让h等于0。這样
对于输入一个X
那么结果就分类 0 或 1,所以达到了分类的效果。当然logistic函数可以应用于多个类的情况。
-----------------------------------------------------------------------------------------------------
spark Logistic模型训练图
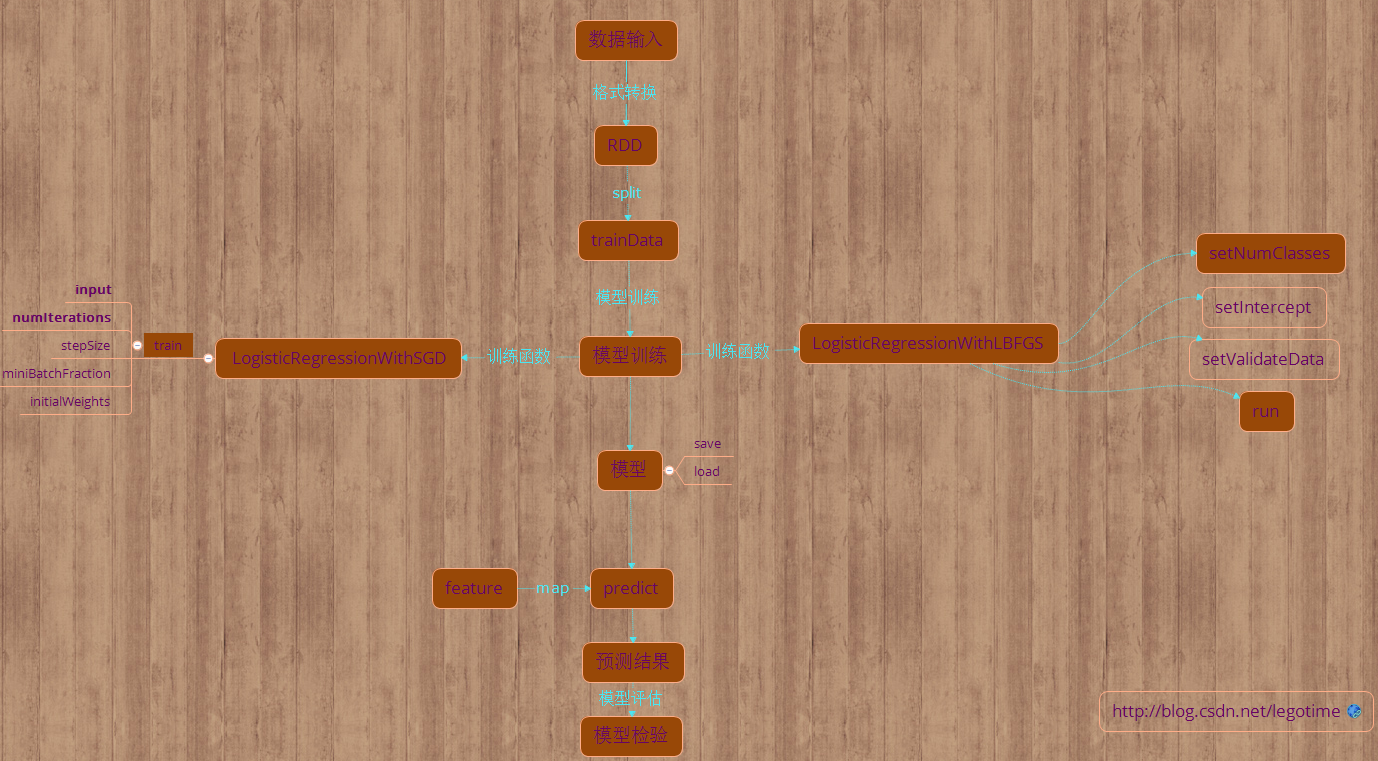
-------------------------------------------------------------------------------------------------------
源码分析
package org.apache.spark.mllib.classification
import org.apache.spark.SparkContext
import org.apache.spark.annotation.Since
import org.apache.spark.ml.util.Identifiable
import org.apache.spark.mllib.classification.impl.GLMClassificationModel
import org.apache.spark.mllib.linalg.{DenseVector, Vector, Vectors}
import org.apache.spark.mllib.linalg.BLAS.dot
import org.apache.spark.mllib.optimization._
import org.apache.spark.mllib.pmml.PMMLExportable
import org.apache.spark.mllib.regression._
import org.apache.spark.mllib.util.{DataValidators, Loader, Saveable}
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SQLContext
import org.apache.spark.storage.StorageLevel
/**
* 利用(Multinomial/Binary)logistic回归来训练分类模型
*
* @param weights 特征的权重
* @param intercept 偏置(二元回归的时候是一个值,在多元回归的时候会和特征融合在一起.)
* @param numFeatures 特征的维度
* @param numClasses 多元回归分析中的类分类问题的可能结果的个数。默认情况下,它是二元Logistic回归,numclasses将被设置为2。
*/
@Since("0.8.0")
class LogisticRegressionModel @Since("1.3.0") (
@Since("1.0.0") override val weights: Vector,
@Since("1.0.0") override val intercept: Double,
@Since("1.3.0") val numFeatures: Int,
@Since("1.3.0") val numClasses: Int)
extends GeneralizedLinearModel(weights, intercept) with ClassificationModel with Serializable
with Saveable with PMMLExportable {
if (numClasses == 2) {
require(weights.size == numFeatures,
s"LogisticRegressionModel with numClasses = 2 was given non-matching values:" +
s" numFeatures = $numFeatures, but weights.size = ${weights.size}")
} else {
val weightsSizeWithoutIntercept = (numClasses - 1) * numFeatures
val weightsSizeWithIntercept = (numClasses - 1) * (numFeatures + 1)
require(weights.size == weightsSizeWithoutIntercept || weights.size == weightsSizeWithIntercept,
s"LogisticRegressionModel.load with numClasses = $numClasses and numFeatures = $numFeatures" +
s" expected weights of length $weightsSizeWithoutIntercept (without intercept)" +
s" or $weightsSizeWithIntercept (with intercept)," +
s" but was given weights of length ${weights.size}")
}
private val dataWithBiasSize: Int = weights.size / (numClasses - 1)
private val weightsArray: Array[Double] = weights match {
case dv: DenseVector => dv.values
case _ =>
throw new IllegalArgumentException(
s"weights only supports dense vector but got type ${weights.getClass}.")
}
/**
* 构建一个LogisticRegressionModel,权重和偏置都是二维的。
*/
@Since("1.0.0")
def this(weights: Vector, intercept: Double) = this(weights, intercept, weights.size, 2)
private var threshold: Option[Double] = Some(0.5)
/**
* 设置 阈值,对于二分类情况下。這个阈值用于当y大于它时,就在 positive,当小于它时,就分来negative
* 默认情况之恶个這个阈值设置为 0.5
*/
@Since("1.0.0")
def setThreshold(threshold: Double): this.type = {
this.threshold = Some(threshold)
this
}
/**
*返回的阈值(如果有的话),用于将原始预测分数转换为0 / 1预测。它仅用于二进制分类。
*/
@Since("1.3.0")
def getThreshold: Option[Double] = threshold
/**
* 清除阈值,以便“预测”将输出预测值。
* 它仅用于二进制分类
*/
@Since("1.0.0")
def clearThreshold(): this.type = {
threshold = None
this
}
override protected def predictPoint(
dataMatrix: Vector,
weightMatrix: Vector,
intercept: Double) = {
require(dataMatrix.size == numFeatures)
// 如果 dataMatrix和 weightMatrix 具有相同的维度, 那么它是二分类的logistic回归
if (numClasses == 2) {
val margin = dot(weightMatrix, dataMatrix) + intercept
val score = 1.0 / (1.0 + math.exp(-margin))
threshold match {
case Some(t) => if (score > t) 1.0 else 0.0
case None => score
}
} else {
/**
* Compute and find the one with maximum margins. If the maxMargin is negative, then the
* prediction result will be the first class.
*
* PS, if you want to compute the probabilities for each outcome instead of the outcome
* with maximum probability, remember to subtract the maxMargin from margins if maxMargin
* is positive to prevent overflow.
*/
var bestClass = 0
var maxMargin = 0.0
val withBias = dataMatrix.size + 1 == dataWithBiasSize
(0 until numClasses - 1).foreach { i =>
var margin = 0.0
dataMatrix.foreachActive { (index, value) =>
if (value != 0.0) margin += value * weightsArray((i * dataWithBiasSize) + index)
}
// Intercept is required to be added into margin.
if (withBias) {
margin += weightsArray((i * dataWithBiasSize) + dataMatrix.size)
}
if (margin > maxMargin) {
maxMargin = margin
bestClass = i + 1
}
}
bestClass.toDouble
}
}
@Since("1.3.0")
override def save(sc: SparkContext, path: String): Unit = {
GLMClassificationModel.SaveLoadV1_0.save(sc, path, this.getClass.getName,
numFeatures, numClasses, weights, intercept, threshold)
}
override protected def formatVersion: String = "1.0"
override def toString: String = {
s"${super.toString}, numClasses = ${numClasses}, threshold = ${threshold.getOrElse("None")}"
}
}
@Since("1.3.0")
object LogisticRegressionModel extends Loader[LogisticRegressionModel] {
@Since("1.3.0")
override def load(sc: SparkContext, path: String): LogisticRegressionModel = {
val (loadedClassName, version, metadata) = Loader.loadMetadata(sc, path)
// Hard-code class name string in case it changes in the future
val classNameV1_0 = "org.apache.spark.mllib.classification.LogisticRegressionModel"
(loadedClassName, version) match {
case (className, "1.0") if className == classNameV1_0 =>
val (numFeatures, numClasses) = ClassificationModel.getNumFeaturesClasses(metadata)
val data = GLMClassificationModel.SaveLoadV1_0.loadData(sc, path, classNameV1_0)
// numFeatures, numClasses, weights are checked in model initialization
val model =
new LogisticRegressionModel(data.weights, data.intercept, numFeatures, numClasses)
data.threshold match {
case Some(t) => model.setThreshold(t)
case None => model.clearThreshold()
}
model
case _ => throw new Exception(
s"LogisticRegressionModel.load did not recognize model with (className, format version):" +
s"($loadedClassName, $version). Supported:\n" +
s" ($classNameV1_0, 1.0)")
}
}
}
/**
* 用随机梯度下降算法来训练二分类的logitic回归的分类模型
* 默认情况下用L2正则化,它可以通过[[LogisticRegressionWithSGD.optimizer]].来改变
* note:二分类以上的K分类的logistic回归分类 ,Lables 可以为 {0, 1, ..., k - 1}
*/
@Since("0.8.0")
@deprecated("Use ml.classification.LogisticRegression or LogisticRegressionWithLBFGS", "2.0.0")
class LogisticRegressionWithSGD private[mllib] (
private var stepSize: Double,
private var numIterations: Int,
private var regParam: Double,
private var miniBatchFraction: Double)
extends GeneralizedLinearAlgorithm[LogisticRegressionModel] with Serializable {
private val gradient = new LogisticGradient()
private val updater = new SquaredL2Updater()
@Since("0.8.0")
override val optimizer = new GradientDescent(gradient, updater)
.setStepSize(stepSize)
.setNumIterations(numIterations)
.setRegParam(regParam)
.setMiniBatchFraction(miniBatchFraction)
override protected val validators = List(DataValidators.binaryLabelValidator)
/**
* 构建一个默认情况下的逻辑回归,默认参数是{stepSize: 1.0,numIterations: 100, regParm: 0.01, miniBatchFraction: 1.0}.
*/
@Since("0.8.0")
def this() = this(1.0, 100, 0.01, 1.0)
override protected[mllib] def createModel(weights: Vector, intercept: Double) = {
new LogisticRegressionModel(weights, intercept)
}
}
/**
* 最先用的方法是随机梯度下降
* NOTE: Logistic 回归的label应该是 {0, 1}
*/
@Since("0.8.0")
@deprecated("Use ml.classification.LogisticRegression or LogisticRegressionWithLBFGS", "2.0.0")
object LogisticRegressionWithSGD {
// NOTE(shivaram): We use multiple train methods instead of default arguments to support
// Java programs.
/**
* 给定一个 pair RDD(label, features) 训练一个logistic回归模型。我们通过特定步长来固定迭代次数。
* 每次迭代用miniBatchFraction来计算梯度。
* NOTE: Labels used in Logistic Regression should be {0, 1}
*
* @param input RDD of (label, array of features) pairs.
* @param numIterations Number of iterations of gradient descent to run.(迭代次数)
* @param stepSize Step size to be used for each iteration of gradient descent.(步长)
* @param miniBatchFraction Fraction of data to be used per iteration.(一次用于迭代的数据量)
* @param initialWeights Initial set of weights to be used. Array should be equal in size to
* the number of features in the data.
*/
@Since("1.0.0")
def train(
input: RDD[LabeledPoint],
numIterations: Int,
stepSize: Double,
miniBatchFraction: Double,
initialWeights: Vector): LogisticRegressionModel = {
new LogisticRegressionWithSGD(stepSize, numIterations, 0.0, miniBatchFraction)
.run(input, initialWeights)
}
/**
/**
* 给定一个 pair RDD(label, features) 训练一个logistic回归模型。我们通过特定步长来固定迭代次数。
* 每次迭代用miniBatchFraction来计算梯度。
* NOTE: Labels used in Logistic Regression should be {0, 1}
*
* @param input RDD of (label, array of features) pairs.
* @param numIterations Number of iterations of gradient descent to run.
* @param stepSize Step size to be used for each iteration of gradient descent.
* @param miniBatchFraction Fraction of data to be used per iteration.
*/
@Since("1.0.0")
def train(
input: RDD[LabeledPoint],
numIterations: Int,
stepSize: Double,
miniBatchFraction: Double): LogisticRegressionModel = {
new LogisticRegressionWithSGD(stepSize, numIterations, 0.0, miniBatchFraction)
.run(input)
}
/**
/**
* 给定一个 pair RDD(label, features) 训练一个logistic回归模型。我们通过特定步长来固定迭代次数。
* 每次迭代用miniBatchFraction来计算梯度。
* NOTE: Labels used in Logistic Regression should be {0, 1}
*
* @param input RDD of (label, array of features) pairs.
* @param stepSize Step size to be used for each iteration of Gradient Descent.
* @param numIterations Number of iterations of gradient descent to run.
* @return a LogisticRegressionModel which has the weights and offset from training.
*/
@Since("1.0.0")
def train(
input: RDD[LabeledPoint],
numIterations: Int,
stepSize: Double): LogisticRegressionModel = {
train(input, numIterations, stepSize, 1.0)
}
/**
/**
* 给定一个 pair RDD(label, features) 训练一个logistic回归模型。我们通过特定步长来固定迭代次数。
* 每次迭代用miniBatchFraction来计算梯度。
* NOTE: Labels used in Logistic Regression should be {0, 1}
*
* @param input RDD of (label, array of features) pairs.
* @param numIterations Number of iterations of gradient descent to run.
* @return a LogisticRegressionModel which has the weights and offset from training.
*/
@Since("1.0.0")
def train(
input: RDD[LabeledPoint],
numIterations: Int): LogisticRegressionModel = {
train(input, numIterations, 1.0, 1.0)
}
}
/**
* 用Limited-memory BFGS算法来训练二分类/K分类的logitic回归的分类模型,默认情况下是用L2正则化
* note:二分类以上的K分类的logistic回归分类 ,Lables 可以为 {0, 1, ..., k - 1}
* 早期是用 LogisticRegressionWithLBFGS来实现正则化,包括偏置。如果updates是(L1Updater, or SquaredL2Updater) ,
* 那么它应该是来自 ml.LogisticRegression
* 否则就是现在的 mllib下的广义线性算法(GeneralizedLinearAlgorithm)来训练,
*/
@Since("1.1.0")
class LogisticRegressionWithLBFGS
extends GeneralizedLinearAlgorithm[LogisticRegressionModel] with Serializable {
this.setFeatureScaling(true)
@Since("1.1.0")
override val optimizer = new LBFGS(new LogisticGradient, new SquaredL2Updater)
override protected val validators = List(multiLabelValidator)
private def multiLabelValidator: RDD[LabeledPoint] => Boolean = { data =>
if (numOfLinearPredictor > 1) {
DataValidators.multiLabelValidator(numOfLinearPredictor + 1)(data)
} else {
DataValidators.binaryLabelValidator(data)
}
}
/**
* 在多分类(k)的logistic回归中,设置用于类分类问题的可能结果的数量。默认情况下k = 2
*/
@Since("1.3.0")
def setNumClasses(numClasses: Int): this.type = {
require(numClasses > 1)
numOfLinearPredictor = numClasses - 1
if (numClasses > 2) {
optimizer.setGradient(new LogisticGradient(numClasses))
}
this
}
override protected def createModel(weights: Vector, intercept: Double) = {
if (numOfLinearPredictor == 1) {
new LogisticRegressionModel(weights, intercept)
} else {
new LogisticRegressionModel(weights, intercept, numFeatures, numOfLinearPredictor + 1)
}
}
/**
* Run Logistic Regression with the configured parameters on an input RDD
* of LabeledPoint entries.
*
*
* 如果在之前声明了更新的方法是 ml包下面的,那么就是,如果不是那么选择的是mllib包下的更新方法
*/
override def run(input: RDD[LabeledPoint]): LogisticRegressionModel = {
run(input, generateInitialWeights(input), userSuppliedWeights = false)
}
/**
* Run Logistic Regression with the configured parameters on an input RDD
* of LabeledPoint entries.
*
*
* 如果在之前声明了更新的方法是 ml包下面的,那么就是,如果不是那么选择的是mllib包下的更新方法
*/
*note:因为在ml包下没有配置LBFGS更新方法,所以optimizer.setNumCorrections()是无效的
*/
override def run(input: RDD[LabeledPoint], initialWeights: Vector): LogisticRegressionModel = {
run(input, initialWeights, userSuppliedWeights = true)
}
private def run(input: RDD[LabeledPoint], initialWeights: Vector, userSuppliedWeights: Boolean):
LogisticRegressionModel = {
// ml's Logistic regression only supports binary classification currently.
if (numOfLinearPredictor == 1) {
def runWithMlLogisitcRegression(elasticNetParam: Double) = {
// Prepare the ml LogisticRegression based on our settings
val lr = new org.apache.spark.ml.classification.LogisticRegression()
lr.setRegParam(optimizer.getRegParam())
lr.setElasticNetParam(elasticNetParam)
lr.setStandardization(useFeatureScaling)
if (userSuppliedWeights) {
val uid = Identifiable.randomUID("logreg-static")
lr.setInitialModel(new org.apache.spark.ml.classification.LogisticRegressionModel(
uid, initialWeights.asML, 1.0))
}
lr.setFitIntercept(addIntercept)
lr.setMaxIter(optimizer.getNumIterations())
lr.setTol(optimizer.getConvergenceTol())
// Convert our input into a DataFrame
val sqlContext = new SQLContext(input.context)
import sqlContext.implicits._
val df = input.map(_.asML).toDF()
// Determine if we should cache the DF
val handlePersistence = input.getStorageLevel == StorageLevel.NONE
// Train our model
val mlLogisticRegresionModel = lr.train(df, handlePersistence)
// convert the model
val weights = Vectors.dense(mlLogisticRegresionModel.coefficients.toArray)
createModel(weights, mlLogisticRegresionModel.intercept)
}
optimizer.getUpdater() match {
case x: SquaredL2Updater => runWithMlLogisitcRegression(0.0)
case x: L1Updater => runWithMlLogisitcRegression(1.0)
case _ => super.run(input, initialWeights)
}
} else {
super.run(input, initialWeights)
}
}
}
SparkML实验
import org.apache.spark.mllib.classification.{LogisticRegressionModel, LogisticRegressionWithLBFGS} import org.apache.spark.mllib.evaluation.MulticlassMetrics import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.mllib.regression.LabeledPoint import org.apache.spark.mllib.util.MLUtils object LinearRegressionWithSGDExample { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("LinearRegressionWithSGDExample").setMaster("local") val sc = new SparkContext(conf) val data = MLUtils.loadLibSVMFile(sc, "C:\\Users\\alienware\\IdeaProjects\\sparkCore\\data\\mllib\\sample_libsvm_data.txt") // Split data into training (60%) and test (40%). val splits = data.randomSplit(Array(0.6, 0.4), seed = 11L) val training = splits(0).cache() val test = splits(1) // Run training algorithm to build the model val model = new LogisticRegressionWithLBFGS() .setNumClasses(2) .run(training) // Compute raw scores on the test set. val predictionAndLabels = test.map { case LabeledPoint(label, features) => val prediction = model.predict(features) (prediction, label) } predictionAndLabels.foreach(println) // Get evaluation metrics. val metrics = new MulticlassMetrics(predictionAndLabels) val precision = metrics.precision println("Precision = " + precision) // Save and load model model.save(sc, "target/tmp/scalaLogisticRegressionWithLBFGSModel") val sameModel = LogisticRegressionModel.load(sc, "target/tmp/scalaLogisticRegressionWithLBFGSModel") sc.stop() } } //预测数据和实际数据(1.0,1.0)
(1.0,1.0)
(0.0,0.0)
(1.0,1.0)
(0.0,0.0)
(0.0,0.0)
(1.0,1.0)
(1.0,1.0)
(1.0,1.0)
(0.0,0.0)
(1.0,1.0)
(1.0,1.0)
(0.0,0.0)
(1.0,1.0)
(0.0,0.0)
(0.0,0.0)
(1.0,1.0)
(1.0,1.0)
(1.0,1.0)
(1.0,1.0)
(0.0,0.0)
(1.0,1.0)
(1.0,1.0)
(1.0,1.0)
(1.0,1.0)
(0.0,0.0)
(1.0,1.0)
(0.0,0.0)
(1.0,1.0)
(1.0,1.0)
(1.0,1.0)
(1.0,1.0)
(1.0,1.0)
(0.0,0.0)
Precision = 1.0















 423
423

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









