







1、Accumulators和Broadcast基础理解
共享变量
共享变量目的是将一个变量缓存在每台机器上,而不用在任务之间传递。在SparkCore中经常广播一些环境变量,
目的是使得在同一时间集群中的每台机器的环境变量都更新。它的功能是用于有效地给每个节点输入一个环境变量
或者数据集副本,這样可以减少通信的开销。這样使得我们在多个任务之间使用相同数据的时候,创建广播变量结
合并行处理,這样可以加快处理。下面通过源码来分析一下Accumulators和Broadcast
广播变量(Broadcast)
package org.apache.spark.broadcast
import java.io.Serializable
import scala.reflect.ClassTag
import org.apache.spark.SparkException
import org.apache.spark.internal.Logging
import org.apache.spark.util.Utils
/**
* A broadcast variable. Broadcast variables allow the programmer to keep a read-only variable
* cached on each machine rather than shipping a copy of it with tasks. They can be used, for
* example, to give every node a copy of a large input dataset in an efficient manner. Spark also
* attempts to distribute broadcast variables using efficient broadcast algorithms to reduce
* communication cost.
* 广播变量允许程序员将一个只读的变量缓存在每台机器上,而不是复制一份数据在task运行。它可以被允许有效
* 的给每个节点一个大数据集的副本。Spark还尝试高效的算法来广播变量,以减少通宵消耗
* Broadcast variables are created from a variable `v` by calling
* [[org.apache.spark.SparkContext#broadcast]].
* The broadcast variable is a wrapper around `v`, and its value can be accessed by calling the
* `value` method. The interpreter session below shows this:
*
* {{{
* scala> val broadcastVar = sc.broadcast(Array(1, 2, 3))
* broadcastVar: org.apache.spark.broadcast.Broadcast[Array[Int]] = Broadcast(0)
*
* scala> broadcastVar.value
* res0: Array[Int] = Array(1, 2, 3)
* }}}
*
* After the broadcast variable is created, it should be used instead of the value `v` in any
* functions run on the cluster so that `v` is not shipped to the nodes more than once.
* In addition, the object `v` should not be modified after it is broadcast in order to ensure
* that all nodes get the same value of the broadcast variable (e.g. if the variable is shipped
* to a new node later).
* 广播变量之后,它可以应用在集群中的任何函数,为了保证所有节点得到相同的广播值,它的数值是不可以改变的
* @param id A unique identifier for the broadcast variable.
* @tparam T Type of the data contained in the broadcast variable.
*/
abstract class Broadcast[T: ClassTag](val id: Long) extends Serializable with Logging {
/**
* Flag signifying whether the broadcast variable is valid
* (that is, not already destroyed) or not.
*/
@volatile private var _isValid = true
private var _destroySite = ""
/** Get the broadcasted value. */
def value: T = {
assertValid()
getValue()
}
/**
* Asynchronously delete cached copies of this broadcast on the executors.
* If the broadcast is used after this is called, it will need to be re-sent to each executor.
*/
def unpersist() {
unpersist(blocking = false)
}
/**
* Delete cached copies of this broadcast on the executors. If the broadcast is used after
* this is called, it will need to be re-sent to each executor.
* @param blocking Whether to block until unpersisting has completed
*/
def unpersist(blocking: Boolean) {
assertValid()
doUnpersist(blocking)
}
/**
* Destroy all data and metadata related to this broadcast variable. Use this with caution;
* once a broadcast variable has been destroyed, it cannot be used again.
* This method blocks until destroy has completed
*/
def destroy() {
destroy(blocking = true)
}
/**
* Destroy all data and metadata related to this broadcast variable. Use this with caution;
* once a broadcast variable has been destroyed, it cannot be used again.
* @param blocking Whether to block until destroy has completed
*/
private[spark] def destroy(blocking: Boolean) {
assertValid()
_isValid = false
_destroySite = Utils.getCallSite().shortForm
logInfo("Destroying %s (from %s)".format(toString, _destroySite))
doDestroy(blocking)
}
/**
* Whether this Broadcast is actually usable. This should be false once persisted state is
* removed from the driver.
*/
private[spark] def isValid: Boolean = {
_isValid
}
/**
* Actually get the broadcasted value. Concrete implementations of Broadcast class must
* define their own way to get the value.
*/
protected def getValue(): T
/**
* Actually unpersist the broadcasted value on the executors. Concrete implementations of
* Broadcast class must define their own logic to unpersist their own data.
*/
protected def doUnpersist(blocking: Boolean)
/**
* Actually destroy all data and metadata related to this broadcast variable.
* Implementation of Broadcast class must define their own logic to destroy their own
* state.
*/
protected def doDestroy(blocking: Boolean)
/** Check if this broadcast is valid. If not valid, exception is thrown. */
protected def assertValid() {
if (!_isValid) {
throw new SparkException(
"Attempted to use %s after it was destroyed (%s) ".format(toString, _destroySite))
}
}
override def toString: String = "Broadcast(" + id + ")"
}
累加器(Accumulators)
package org.apache.spark
/**
* A simpler value of [[Accumulable]] where the result type being accumulated is the same
* as the types of elements being merged, i.e. variables that are only "added" to through an
* associative and commutative operation and can therefore be efficiently supported in parallel.
* They can be used to implement counters (as in MapReduce) or sums. Spark natively supports
* accumulators of numeric value types, and programmers can add support for new types.
* 1、累加器仅仅支持累加操作(added),目的是有效的支持并行
2、他们可以用来进行计数和累加,spark天生支持数值类型的累加,同时程序员也可以自己定义类型
* An accumulator is created from an initial value `v` by calling
* [[SparkContext#accumulator SparkContext.accumulator]].
* Tasks running on the cluster can then add to it using the [[Accumulable#+= +=]] operator.
* However, they cannot read its value. Only the driver program can read the accumulator's value,
* using its [[#value]] method.
*
* The interpreter session below shows an accumulator being used to add up the elements of an array:
*
* {{{
* scala> val accum = sc.accumulator(0)
* accum: org.apache.spark.Accumulator[Int] = 0
*
* scala> sc.parallelize(Array(1, 2, 3, 4)).foreach(x => accum += x)
* ...
* 10/09/29 18:41:08 INFO SparkContext: Tasks finished in 0.317106 s
*
* scala> accum.value
* res2: Int = 10
* }}}
*
* @param initialValue initial value of accumulator
* @param param helper object defining how to add elements of type `T`
* @param name human-readable name associated with this accumulator
* @param countFailedValues whether to accumulate values from failed tasks
* @tparam T result type
*/
@deprecated("use AccumulatorV2", "2.0.0")
class Accumulator[T] private[spark] (
// SI-8813: This must explicitly be a private val, or else scala 2.11 doesn't compile
@transient private val initialValue: T,
param: AccumulatorParam[T],
name: Option[String] = None,
countFailedValues: Boolean = false)
extends Accumulable[T, T](initialValue, param, name, countFailedValues)
/**
* A simpler version of [[org.apache.spark.AccumulableParam]] where the only data type you can add
* in is the same type as the accumulated value. An implicit AccumulatorParam object needs to be
* available when you create Accumulators of a specific type.
*
* @tparam T type of value to accumulate
*/
@deprecated("use AccumulatorV2", "2.0.0")
trait AccumulatorParam[T] extends AccumulableParam[T, T] {
def addAccumulator(t1: T, t2: T): T = {
addInPlace(t1, t2)
}
}
@deprecated("use AccumulatorV2", "2.0.0")
object AccumulatorParam {
// The following implicit objects were in SparkContext before 1.2 and users had to
// `import SparkContext._` to enable them. Now we move them here to make the compiler find
// them automatically. However, as there are duplicate codes in SparkContext for backward
// compatibility, please update them accordingly if you modify the following implicit objects.
@deprecated("use AccumulatorV2", "2.0.0")
implicit object DoubleAccumulatorParam extends AccumulatorParam[Double] {
def addInPlace(t1: Double, t2: Double): Double = t1 + t2
def zero(initialValue: Double): Double = 0.0
}
@deprecated("use AccumulatorV2", "2.0.0")
implicit object IntAccumulatorParam extends AccumulatorParam[Int] {
def addInPlace(t1: Int, t2: Int): Int = t1 + t2
def zero(initialValue: Int): Int = 0
}
@deprecated("use AccumulatorV2", "2.0.0")
implicit object LongAccumulatorParam extends AccumulatorParam[Long] {
def addInPlace(t1: Long, t2: Long): Long = t1 + t2
def zero(initialValue: Long): Long = 0L
}
@deprecated("use AccumulatorV2", "2.0.0")
implicit object FloatAccumulatorParam extends AccumulatorParam[Float] {
def addInPlace(t1: Float, t2: Float): Float = t1 + t2
def zero(initialValue: Float): Float = 0f
}
// Note: when merging values, this param just adopts the newer value. This is used only
// internally for things that shouldn't really be accumulated across tasks, like input
// read method, which should be the same across all tasks in the same stage.
@deprecated("use AccumulatorV2", "2.0.0")
private[spark] object StringAccumulatorParam extends AccumulatorParam[String] {
def addInPlace(t1: String, t2: String): String = t2
def zero(initialValue: String): String = ""
}
}
import org.apache.spark.{SparkConf, SparkContext}
object broadCastTest {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("broadCastTest").setMaster("local")
val sc = new SparkContext(conf)
val RDD = sc.parallelize(List(1,2,3))
//broadcast
val broadValue1 = sc.broadcast(2)
val data1 = RDD.map(x => x*broadValue1.value)
data1.foreach(x => println("broadcast value:"+x))
//accumulator
var accumulator = sc.accumulator(2)
//错误
val RDD2 = sc.parallelize(List(1,1,1)).map{ x=>
if(x<3){
accumulator+=1
}
x*accumulator.value
}//(x => x*accumulator.value)
//此处还没有报错
println(RDD2)
//此处开始报错
//RDD2.foreach(println)
// 這里报错:Can't read accumulator value in task
//這个操作没有报错
RDD.foreach{x =>
if(x<3){
accumulator+=1
}
}
println("accumulator is "+accumulator.value)
// accumulator 说明了两点:
//(1): 累加器只有在执行Action的时候,才被更新
//(2):我们在task的时候不能读取它的值,只有驱动程序才可以读取它的值
sc.stop()
}
}从Accumulator源码中可以看到,我们可以用AccumulatorParam接口实现自己的累加器
它有两个方法,
def addInPlace(t1: T, t2: T): T = t1 + t2
def zero(initialValue: T): T = 0.0
下面按照自己定义的类型,写一个
import org.apache.spark.{AccumulatorParam, SparkConf, SparkContext}
object listAccumulatorParam extends AccumulatorParam[List[Double]] {
def zero(initialValue: List[Double]): List[Double] = {
Nil
}
def addInPlace(v1: List[Double], v2: List[Double]): List[Double] = {
v1:::v2
}
}
object broadCastTest {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("broadCastTest").setMaster("local")
val sc = new SparkContext(conf)
val myAccumulator = sc.accumulator[List[Double]](List(0.1,0.2,0.3))(listAccumulatorParam)
println("my accumulator is "+myAccumulator.value)
//my accumulator is List(0.1, 0.2, 0.3)
sc.stop()
}
}通过对一些特有的字符串广播,然后进行过滤,比如我们可以把一些人的名字给过滤掉,也就是黑名单的过滤,如下实现过滤三个字符串 a,b,c.从下面的数据中每秒产生一个字母
a
b
c
d
e
f
g
h
i
过滤的SparkStreaming程序如下:
import org.apache.log4j.{Level, Logger}
import org.apache.spark.{Accumulator, SparkConf}
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.streaming.{Seconds, StreamingContext}
object broadCastTest {
@volatile private var broadcastValue: Broadcast[Seq[String]] = null
@volatile private var accumulatorValue:Accumulator[Int] = null
def main(args: Array[String]) {
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
Logger.getLogger("org.eclipse.jetty.Server").setLevel(Level.OFF)
val conf = new SparkConf().setAppName("broadCastTest").setMaster("local[2]")
val ssc = new StreamingContext(conf, Seconds(2))
broadcastValue = ssc.sparkContext.broadcast(Seq("a","b","c"))
accumulatorValue = ssc.sparkContext.accumulator(0, "OnlineBlacklistCounter")
val linesData = ssc.socketTextStream("master",9999)
val wordCount = linesData.map(x =>(x,1)).reduceByKey(_+_)
val counts = wordCount.filter{ case (word,count) =>
if(broadcastValue.value.contains(word)){
accumulatorValue += count
//println("have blocked "+accumulatorValue+" times")
false
}else{
//println("have blocked "+accumulatorValue+" times")
true
}
}
//println("broadcastValue:"+broadcastValue.value)
counts.print()
//wordCount.print()
ssc.start()
ssc.awaitTermination()
}
}
得到的结果如下:
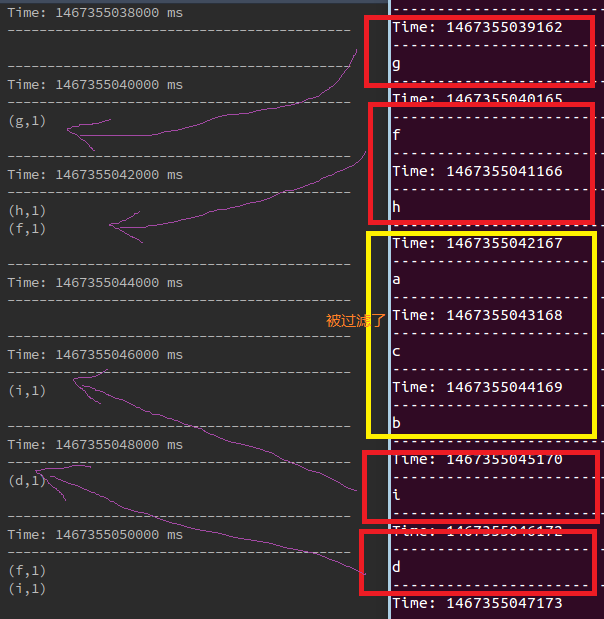















 1998
1998

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









