







本博文主要包括:
1、Spark Streaming与Broadcast、Accumulator联合
2、在线黑名单过滤和计数实战
一、Spark Streaming与Broadcast、Accumulator联合:
在企业实战中,广播本身广播到集群的时候,联合上计数器的话就有很大杀伤力,这时候你可以自定义,例如自定义广播中的内容,可以实现非常复杂的内容。
之所以广播和计数器特别重要,一方面鉴于广播和计数器本身的特性,另一方面广播和计数器可以说实现非常复杂的操作。在线黑名单过滤实战中,将黑名单放在广播中,有Accumulator你可以计数黑名单。
二、在线黑名单过滤和计数实战:
1、代码如下:
import org.apache.spark.Accumulator;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.broadcast.Broadcast;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.Time;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import scala.Tuple2;
import java.util.Arrays;
import java.util.List;
/**
* Created by zpf on 2016/8/31.
*/
public class SparkStreamingBroadcastAccumulator {
private static volatile Broadcast<List<String>> broadcastList = null;
private static volatile Accumulator<Integer> accumulator = null;
public void main(String[] args) throws InterruptedException {
SparkConf conf = new SparkConf().setMaster("local[2]").
setAppName("SparkStreamingBroadcastAccumulator");
JavaStreamingContext jsc = new JavaStreamingContext(conf, Durations.seconds(15));
//实例化我们的broadcast,使用Broadcast广播黑名单到每个Executor中
broadcastList = jsc.sparkContext().broadcast(Arrays.asList("Hadoop","Mahout","Hive"));
/*全局计数器,用于统计在线过滤多少黑名单
* */
accumulator = jsc.sparkContext().accumulator(0,"OnlineBlacklistCount");
JavaReceiverInputDStream lines = jsc.socketTextStream("Master",9999);
JavaPairDStream<String,Integer> pairs = lines.mapToPair(new PairFunction<String,String,Integer>() {
public Tuple2<String,Integer> call(String word) throws Exception {
return new Tuple2<String, Integer>(word,1);
}
});
JavaPairDStream<String,Integer> wordsCount = pairs.reduceByKey(new Function2<Integer, Integer, Integer>() {
public Integer call(Integer v1, Integer v2) throws Exception {
return v1+v2;
}
});
/*过滤黑明单我们一般把内容写在foreach中*/
wordsCount.foreachRDD(new Function2<JavaPairRDD<String,Integer>, Time, Void>(){
public Void call(JavaPairRDD<String, Integer> rdd, Time time) throws Exception {
rdd.filter(new Function<Tuple2<String, Integer>, Boolean>() {
public Boolean call(Tuple2<String, Integer> wordPair) throws Exception {
if(broadcastList.value().contains(wordPair._1)){
accumulator.add(wordPair._2);
return false;
}else{
return true;
}
}
}).collect();
// System.out.println(broadcastList.value().toString() + ":" + accumulator.value());
System.out.println("BlackList append : " + ":" + accumulator.value() + "times");
return null;
}
});
jsc.start();
jsc.awaitTermination();
jsc.close();
}
}
2、在命令端输入数据
nc -lk 99993、观察结果
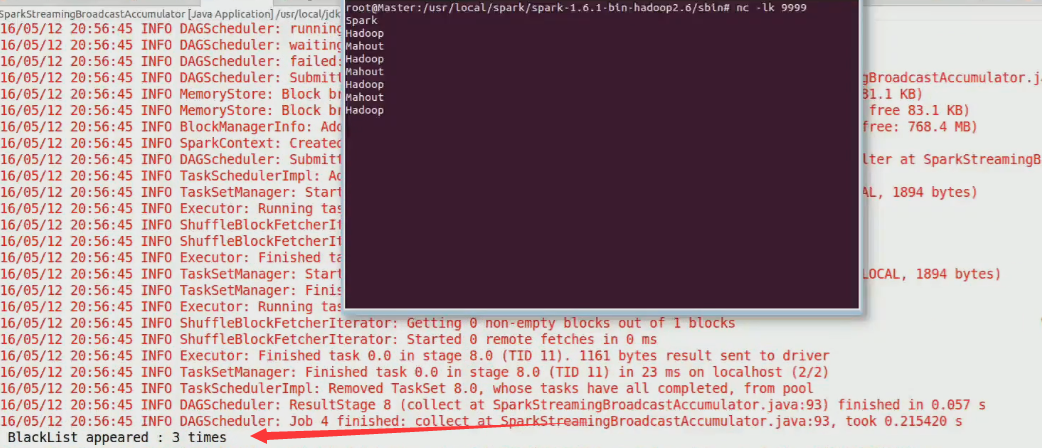















 1993
1993











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









