







有时候,我们需要将我们Flink程序的计算结果输出到文件中(本地文件/HDFS)文件
Flink程序本身便支持这种操作
(1)方式一 writeAsText
核心语法:
dataStreamSource.writeAsText("本地/HDFS的path(必填参数)",覆盖类型(选填参数)).setParallelism(并行度)
注:.setParallelism(并行度) 当并行度为1时,fink会将path视为文件,我们的计算数据会全部写入此文件中,当并行度不设置或者大于1时,Flink会将path视为文件夹
由于我们当前开发服务器未搭建HDFS,所以只能输出到本地了
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
DataStreamSource<Long> dataStreamSource = env.fromSequence(1L, 10L);
String filePath = "E:\\aa\\flink-learn-1.12\\flink-learn-4-sink\\src\\main\\resources\\file";
dataStreamSource.writeAsText(filePath);
env.execute();
}
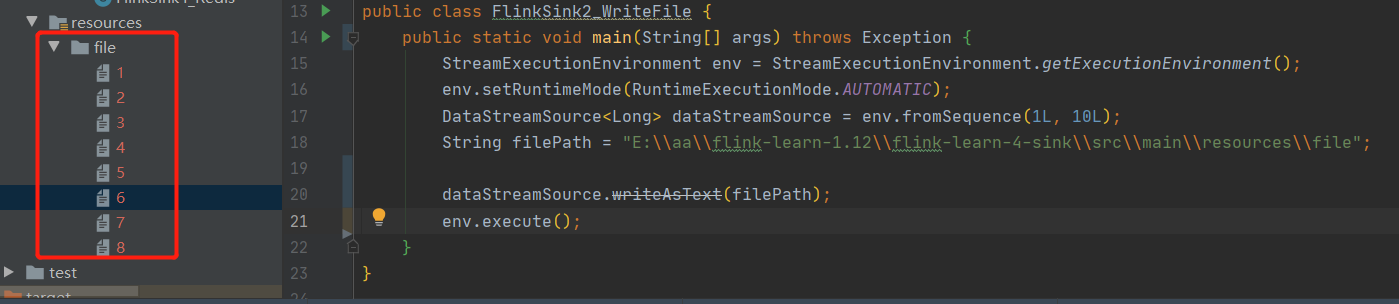
未指定并行度,程序执行后我们指定的path,变成了一个文件夹,下边出现了多个文件,文件中内容不均匀的分散到了8个文件中
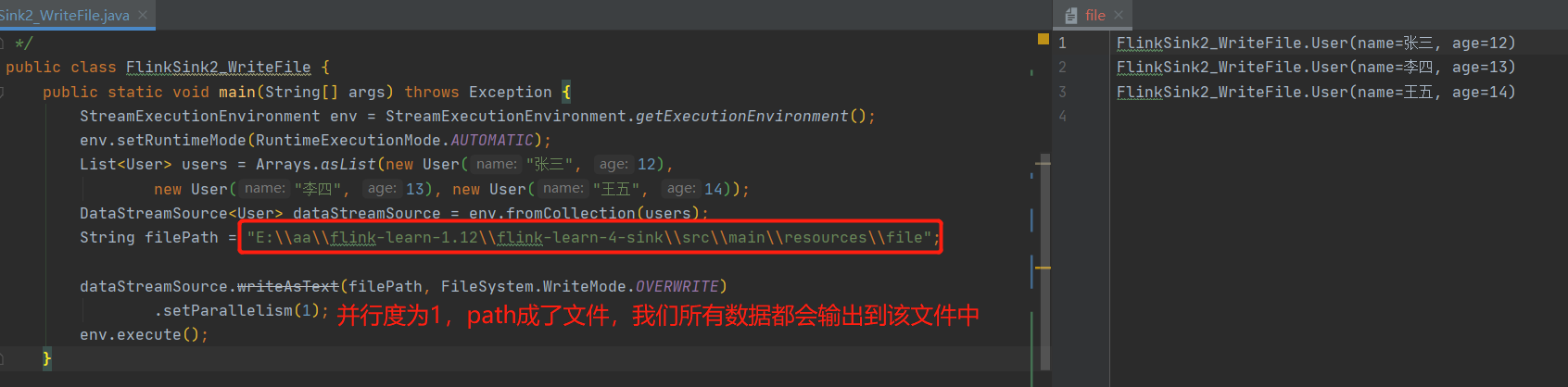
setParallelism(1) 设置后,我们指定的path,变成了一个文件
上边,便完成了Flink数据输出到文件了,但是呢,我们可以看到writeAsText,被打上了删除符,表示当前方法过时了(1.12),我们来看看1.12推荐写法呢!

(2)方式二 StreamingFileSink
StreamingFileSink是Flink1.12中 推荐的数据sink到文件的姿势。
static String filePath = "E:\\aa\\flink-learn-1.12\\flink-learn-4-sink\\src\\main\\resources\\file";
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
List<User> users = Arrays.asList(new User("张三", 12),
new User("李四", 13), new User("王五", 14));
DataStreamSource<User> dataStreamSource = env.fromCollection(users);
//writeAsText 已过时,推荐使用StreamingFileSink
dataStreamSource.addSink(StreamingFileSink.forRowFormat(new Path(filePath),
new SimpleStringEncoder<User>("UTF-8"))
.withRollingPolicy(
DefaultRollingPolicy.builder()
//文件滚动间隔 每隔多久(指定)时间生成一个新文件
.withRolloverInterval(TimeUnit.SECONDS.toMillis(5))
//数据不活动时间 每隔多久(指定)未来活动数据,则将上一段时间(无数据时间段)也生成一个文件
.withInactivityInterval(TimeUnit.MINUTES.toMillis(5))
// 文件最大容量
.withMaxPartSize(1024 * 1024 * 1024)
.build())
.build());
env.execute();
}
附上一个完整的FileSink配置
StreamingFileSink<User> sink2 = StreamingFileSink
.forRowFormat(
new Path(filePath),
new SimpleStringEncoder<User>("UTF-8"))
/**
* 设置桶分配政策
* DateTimeBucketAssigner --默认的桶分配政策,默认基于时间的分配器,每小时产生一个桶,格式如下yyyy-MM-dd--HH
* BasePathBucketAssigner :将所有部分文件(part file)存储在基本路径中的分配器(单个全局桶)
*/
.withBucketAssigner(new DateTimeBucketAssigner<>())
/**
* 有三种滚动政策
* CheckpointRollingPolicy
* DefaultRollingPolicy
* OnCheckpointRollingPolicy
*/
.withRollingPolicy(
/**
* 滚动策略决定了写出文件的状态变化过程
* 1. In-progress :当前文件正在写入中
* 2. Pending :当处于 In-progress 状态的文件关闭(closed)了,就变为 Pending 状态
* 3. Finished :在成功的 Checkpoint 后,Pending 状态将变为 Finished 状态
*
* 观察到的现象
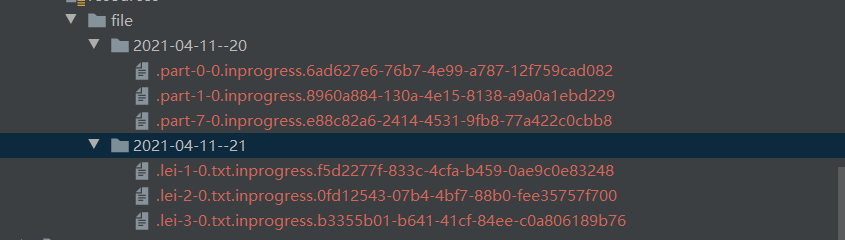
* 1.会根据本地时间和时区,先创建桶目录
* 2.文件名称规则:part-<subtaskIndex>-<partFileIndex>
* 3.在macos中默认不显示隐藏文件,需要显示隐藏文件才能看到处于In-progress和Pending状态的文件,因为文件是按照.开头命名的
*
*/
DefaultRollingPolicy.builder()
//每隔多久(指定)时间生成一个新文件
.withRolloverInterval(TimeUnit.SECONDS.toMillis(2))
//数据不活动时间 每隔多久(指定)未来活动数据,则将上一段时间(无数据时间段)也生成一个文件
.withInactivityInterval(TimeUnit.SECONDS.toMillis(1))
//每个文件大小
.withMaxPartSize(1024 * 1024 * 1024)
.build())
/**
* 设置sink的前缀和后缀
* 文件的头和文件扩展名
*/
.withOutputFileConfig(OutputFileConfig
.builder()
.withPartPrefix("lei")
.withPartSuffix(".txt")
.build())
.build();















 2072
2072











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









