







以下内容大多是学习链接,他人整理,个人收藏以便复习,同时归纳分享出来(如有不妥,原作者可随时联系本人删除,感谢!)
一、Java基础
1、Java使用Lombok的优缺点:
新来个技术总监,禁止我们使用Lombok!_HollisChuang's Blog-CSDN博客
2、Java String类为什么是final的?
3、jdk8动态代理源码:
4、动态代理为什么是面向接口的?
动态代理实际上是程序在运行中,根据被代理的接口来动态生成代理类的class文件,并加载class文件运行的过程,通过反编译被生成的$Proxy0.class文件发现,
生成的代理类,必须要继承Proxy类,而且java是单继承,所以只能实现接口了,所以只能面向接口:
public final class $Proxy0 extends Proxy implements Interface {
public $Proxy0(InvocationHandler paramInvocationHandler) {
super(paramInvocationHandler);
}jdk的动态代理及为什么需要接口_zxysshgood的博客-CSDN博客_jdk动态代理为什么必须实现接口
5、为什么wait()和notify()需要搭配synchonized关键字使用
(假设没有应用Synchronized关键字,当消费者线程执行wait操作的同时,生产线程如果先执行notify,生产者线程可能在等待队列中找不到消费者线程。导致消费者线程一直处于wait阻塞状态。那么这个模型就要失败了。所以必须要加Synchronized关键字。 )
阿里巴巴面试题: 为什么wait()和notify()需要搭配synchonized关键字使用_萧萧的专栏-CSDN博客
6、五种IO模式
7、Java NIO 浅析
Java NIO浅析 - 美团技术团队(美团技术博客)
https://zhuanlan.zhihu.com/p/83597838
几种IO对比:Java面试常考的 BIO,NIO,AIO 总结_小树的博客-CSDN博客_bio nio(附代码demo)
8、Java ConcurrentModificationException异常原因和解决方法
(1)、 for each循环,删除list元素,报错问题 ConcurrentModificationException, 原来for each 循环还是利用了迭代器来遍历集合的
(Map也会出现类似这个ConcurrentModificationException问题)
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();如下,deleteMethod2不会报错,但是deleteMethod3会报错:
private static void deleteMethod2(List<String> list) {
for(Iterator<String> it=list.iterator();it.hasNext();){
String str=it.next();
if("bbb".equals(str)){
it.remove();
}
}
}
private static void deleteMethod3(List<String> list) {
for (String str : list) {
System.out.println(str);
if("bbb".equals(str)){
list.remove(str);
}
}
}(2)、这个快速失败的意思是无论当前是否有并发的情况或问题,只要发现了修改读取不一致就抛异常;
如果是ArrayList遍历读取时不加锁,这时其他线程修改了ArrayList(增加或删除),
会抛出ConcurrentModificationException,这就是failfast机制, 通过fastfail来保证集合的正确性;
(我们这里只讨论Iterator遍历,如果是普通for循环可能会数组越界)
(3)、 多线程解决方案:
CopyOnWriteArrayList 调用iterator时生成的是一个新的数组快照,遍历时读取的是快照,所以永远不会报错(即使读取后修改了列表),并且在CopyOnWriteArrayList是没有fastfail机制的,原因就在于Iterator的快照实现以及CopyOnWrite已经不需要通过fastfail来保证集合的正确性
CopyOnWriteArrayList的CopyOnWrite即修改数组集合时,会重新创建一个数组并对新数据进行调整,调整完成后将新的数组赋值给老的数组
Java ConcurrentModificationException异常原因和解决方法 - Matrix海子 - 博客园
9、Java中StringBuffer的缓冲区为什么是16?
Java中StringBuffer的缓冲区为什么是16? - 知乎
10、WeakHashMap工作原理
https://www.haoid.cn/post/13124
11、ThreadLocal详解,和使用可能出现的问题:
(1)、Threadlocal为什么会存在内存泄露:
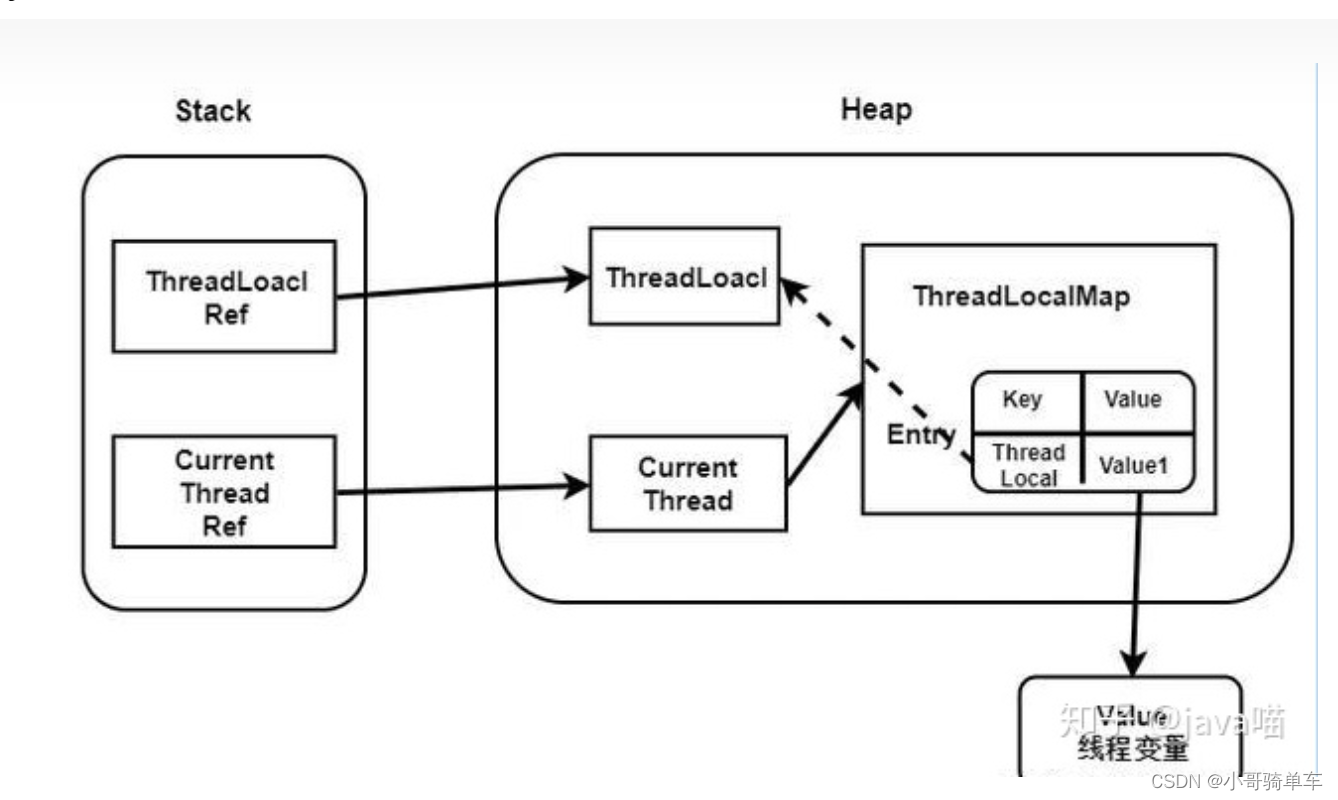
ThreadLocalMap使用ThreadLocal的弱引用作为key,如果一个ThreadLocal不存在外部强引用时,Key(ThreadLocal)势必会被GC回收,这样就会导致ThreadLocalMap中key为null, 而value还存在着强引用,只有thead线程退出以后,value的强引用链条才会断掉。
但如果当前线程再迟迟不结束的话,这些key为null的Entry的value就会一直存在一条强引用链:
Thread Ref -> Thread -> ThreaLocalMap -> Entry -> value
永远无法回收,造成内存泄漏。
来自:ThreadLocal的内存泄露?什么原因?如何避免? - 知乎 (zhihu.com)
(2)什么是弱引用:
WeakReference是Java语言规范中为了区别直接的对象引用(程序中通过构造函数声明出来的对象引用)而定义的另外一种引用关系。WeakReference标志性的特点是:reference实例不会影响到被应用对象的GC回收行为(即只要对象被除WeakReference对象之外所有的对象解除引用后,该对象便可以被GC回收),只不过在被对象回收之后,reference实例想获得被应用的对象时程序会返回null。
只具有弱引用的对象拥有更短暂的生命周期,在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。不过,由于垃圾回收器是一个优先级很低的线程,因此不一定会很快发现那些只具有弱引用的对象。
(3)、为什么要用弱引用:
当ThreadLocalMap的key为弱引用回收ThreadLocal时,由于ThreadLocalMap持有ThreadLocal的弱引用,即使没有手动删除,ThreadLocal也会被回收。当key为null,在下一次ThreadLocalMap调用set(),get(),remove()方法的时候会被清除value值。多了一层保障,但是不能完全保证内存泄露问题;
(4)、ThreadLocal正确的使用方法:
ThreadLocal为每个线程的中并发访问的数据提供一个副本,通过访问副本来运行业务,这样的结果是耗费了内存,单大大减少了线程同步所带来性能消耗,也减少了线程并发控制的复杂度。ThreadLocal不能使用基本数据类型,只能使用Object类型。
每次使用完ThreadLocal都调用它的remove()方法清除数据;
(5)、项目组应用场景:
a、spring的bean在默认是单例模式的时候,比如controller请求的时候,要是因为当多个线程操作同一个对象的时候,对这个对象的非静态成员变量的写操作会存在线程安全问题。
在类中定义一个ThreadLocal成员变量,将需要的可变成员变量保存在ThreadLocal中;
b、使用ThreadLocal来解决SimpleDateFormat线程安全问题
public class TestThreadLocalSimpleDateFormat {
public static void main(String[] args) {
try {
System.out.println(TestThreadLocalSimpleDateFormat.parse("2019-09-01 18:00:11"));
System.out.println(TestThreadLocalSimpleDateFormat.format(new Date()));
} catch (Exception e) {
}
}
private static ThreadLocal<SimpleDateFormat> formatter = new ThreadLocal<SimpleDateFormat>(){
@Override
protected SimpleDateFormat initialValue() {
return new SimpleDateFormat("yyyy-MM-dd hh:mm:ss");
}
};
public static Date parse(String dateStr) throws Exception{
Date date = formatter.get().parse(dateStr);
formatter.remove();
return date;
}
public static String format(Date date) throws Exception{
String strDate = formatter.get().format(date);
formatter.remove();
return strDate;
}
}c、解决线程安全问题
在Spring的Web项目中,我们通常会将业务分为Controller层,Service层,Dao层, 我们都知道@Autowired注解默认使用单例模式,那么不同请求线程进来之后,由于Dao层使用单例,那么负责数据库连接的Connection也只有一个, 如果每个请求线程都去连接数据库,那么就会造成线程不安全的问题,Spring是如何解决这个问题的呢?
在Spring项目中Dao层中装配的Connection肯定是线程安全的,其解决方案就是采用ThreadLocal方法,当每个请求线程使用Connection的时候, 都会从ThreadLocal获取一次,如果为null,说明没有进行过数据库连接,连接后存入ThreadLocal中;
这样每个事务的上下文都应该是独立拥有数据库的connection连接的,否则在数据提交回滚过程中就会产生冲突。如此一来,每一个请求线程都保存有一份 自己的Connection。于是便解决了线程安全问题;
ThreadLocal在设计之初就是为解决并发问题而提供一种方案,每个线程维护一份自己的数据,达到线程隔离的效果。
详解:由浅入深,全面解析ThreadLocal_LeslieGuGu的博客-CSDN博客_.net threadlocal
视频:07-ThreadLocal的内部结构_哔哩哔哩_bilibili
12、TreeMap和TreeSet在排序时如何比较元素,Collections工具类中的sort()方法如何比较元素
https://www.cnblogs.com/qf123/p/8483744.html
(如果要实现TreeSet 或者TreeMap的 排序(或者说让一个TreeSet可用),必须让加入的对象具有可排序性,否则就会报错 java.lang.ClassCastException。)
13、图解LinkedHashMap原理
14、序列化和反序列化(美团技术博客)
15、如何实现 Array 和 List 之间的转换?
Array 转 List: Arrays. asList(array) ;
public static <T> List<T> asList(T... a) {
return new ArrayList<>(a);
}List 转 Array:List 的 toArray() 方法。
public Object[] toArray() {
return Arrays.copyOf(elementData, size);
}
16、数组(Array)和列表(ArrayList)有什么区别?什么时候应该使用Array而不是ArrayList?
数组(Array)和列表(ArrayList)有什么区别?什么时候应该使用Array而不是ArrayList? - 割肉机 - 博客园
17、面经手册 · 第8篇《LinkedList插入速度比ArrayList快?你确定吗?》
面经手册 · 第8篇《LinkedList插入速度比ArrayList快?你确定吗?》 - 小傅哥 - 博客园
18、String,StringBuilder,StringBuffer 实现原理解析
(StringBuffer内部用synchronized关键字控制线程安全,在toString()方法中讲字符串缓存到toStringCache提高访问性能)
String,StringBuilder,StringBuffer 实现原理解析 - 简书
19、Comparable与Comparator的区别:
两种方法各有优劣, 用Comparable 简单, 只要实现Comparable 接口的对象直接就成为一个可以比较的对象,但是需要修改源代码,
用Comparator 的好处是不需要修改源代码, 而是另外实现一个比较器, 当某个自定义的对象需要作比较的时候,把比较器和对象一起传递过去就可以比大小了, 并且在Comparator 里面用户可以自己实现复杂的可以通用的逻辑,使其可以匹配一些比较简单的对象,那样就可以节省很多重复劳动了。
用 Comparator 是策略模式(strategy design pattern),就是不改变对象自身,而用一个策略对象(strategy object)来改变它的行为。
Comparable与Comparator的区别_小帅的专栏-CSDN博客_comparator和comparable的区别
https://www.cnblogs.com/KingIceMou/p/7239668.html
使用native关键字说明这个方法是原生函数,也就是这个方法是用C/C++语言实现的,并且被编译成了DLL,由java去调用。
这些函数的实现体在DLL中,JDK的源代码中并不包含,你应该是看不到的。对于不同的平台它们也是不同的。这也是java的底层机制,实际上java就是在不同的平台上调用不同的native方法实现对操作系统的访问的。
Java不是完美的,Java的不足除了体现在运行速度上要比传统的C++慢许多之外,Java无法直接访问到操作系统底层(如系统硬件等),为此Java使用native方法来扩展Java程序的功能。
JAVA本地方法适用的情况
(1)为了使用底层的主机平台的某个特性,而这个特性不能通过JAVA API访问
(2)为了访问一个老的系统或者使用一个已有的库,而这个系统或这个库不是用JAVA编写的
(3)为了加快程序的性能,而将一段时间敏感的代码作为本地方法实现。
(跟StringUtils.split 对比)
https://segmentfault.com/a/1190000016901608
22、JDK11变化详解,JDK8升级JDK11详细指南
JDK11变化详解,JDK8升级JDK11详细指南 - 简书
23、Java8新特性(一)_interface中的static方法和default方法
Java8新特性(一)_interface中的static方法和default方法 - Kevin_zheng - 博客园
24、jdk8新语法Lambda表达式用处
Lambda 表达式有何用处?如何使用? - 知乎 (Mingqi回答)
25、jdk8新特性
JDK1.8 新特性(全)_随波的博客-CSDN博客_jdk1.8的新特性有哪些
26、JDK8新特性:接口的静态方法和默认方法
JDK8新特性:接口的静态方法和默认方法_aty-CSDN博客_接口的静态方法
27、java 8的java.time包(非常值得推荐)
(
用过java1.8之前原生的日期处理api,你就会知道用起来非常麻烦,而且要注意的地方有点多
(例如月份是由0开始,而且api使用有的不统一,线程不安全等等...),
所以在java1.8之前的日期api都不值得去使用,虽然说现在都有强大的日期处理的第三方库,
但是会有兼容性问题,那么现在jdk8有了新的时间处理类,为何不去尝试一下;
* 之前使用的java.util.Date月份从0开始,我们一般会+1使用,很不方便,java.time.LocalDate月份和星期都改成了enum
* java.util.Date和SimpleDateFormat都不是线程安全的,而LocalDate和LocalTime和最基本的String一样,是不变类型,不但线程安全,而且不能修改。
* java.util.Date是一个“万能接口”,它包含日期、时间,还有毫秒数,更加明确需求取舍
* 新接口更好用的原因是考虑到了日期时间的操作,经常发生往前推或往后推几天的情况。用java.util.Date配合Calendar要写好多代码,而且一般开发人员还不一定能写对。
)
java 8的java.time包(非常值得推荐) - 简书 (jianshu.com)
28、ArrayList中elementData为什么被transient修饰?
ArrayList在序列化的时候会调用writeObject,直接将size和element写入ObjectOutputStream;反序列化时调用readObject,从ObjectInputStream获取size和element,再恢复到elementData。
为什么不直接用elementData来序列化,而采用上诉的方式来实现序列化呢?原因在于elementData是一个缓存数组,它通常会预留一些容量,等容量不足时再扩充容量,那么有些空间可能就没有实际存储元素,采用上诉的方式来实现序列化时,就可以保证只序列化实际存储的那些元素,而不是整个数组,从而节省空间和时间。
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException{
// Write out element count, and any hidden stuff
int expectedModCount = modCount;
s.defaultWriteObject();
// Write out size as capacity for behavioural compatibility with clone()
s.writeInt(size);
// Write out all elements in the proper order.
for (int i=0; i<size; i++) {
s.writeObject(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}ArrayList中elementData为什么被transient修饰?_ZERO-CSDN博客_arraylist transient
29、为什么 String hashCode 方法选择数字31作为乘子
为什么 String hashCode 方法选择数字31作为乘子?_Java笔记虾-CSDN博客
为什么 String hashCode 方法选择数字31作为乘子_JavaZWT的博客-CSDN博客(同上)
快来,我悄悄的给你说几个HashCode的破事。 - why技术 - 博客园提到,新老版本:
而为什么从 37 变成 31 ,作者在第二版里面解释了,也就是我用下划线标注的部分。31 有个很好的特许,即用位移和减法来代替乘法,可以得到更好的性能:
31*i==(i<<5)-1。现代的虚拟机可以自动完成这种优化。从 37 变成 31,一个简单的数字变化,就能带来性能的提升。

30、Integer
Integer中有一段静态内部类代码块,该部分内容会在Integer类被加载的时候就执行,当Integer被加载时,就新建了-128到127的所有数字并存放在Integer数组cache中。
再回到valueOf代码,可以得出结论。当调用valueOf方法(包括后面会提到的重载的参数类型包含String的valueOf方法)时,如果参数的值在-127到128之间,则直接从缓存中返回一个已经存在的对象。如果参数的值不在这个范围内,则new一个Integer对象返回。
所以,当把一个int变量转成Integer的时候(或者新建一个Integer的时候),建议使用valueOf方法来代替构造函数。或者直接使用Integer i = 100;编译器会转成Integer s = Integer.valueOf(100);
String转成Integer时候,parseInt方法返回的是基本类型int,其他的方法返回的是Integer;
下面结果,第一个为true,第二个为true,第三个为false:
public class TestInteger {
public static void main(String[] args) {
//jdk1.5以后,自动装箱、拆箱功能。基本数据类型与包装数据类型转换
//下面编译后是 Integer integer0 = Integer.valueOf(88),自动装箱;
Integer integer0=88;
//下面编译后是 int a = integer0.intValue() 自动拆箱;
int a = integer0;
Integer integer1 = Integer.valueOf(88);
Integer integer2 = Integer.valueOf(88);
Integer integer3 = Integer.valueOf(888);
Integer integer4 = Integer.valueOf(888);
//两个缓存值比较,true
System.out.println(integer0==integer2);
//两个缓存值比较,true
System.out.println(integer1==integer2);
//超过了 -128~127 缓存值范围,为false
System.out.println(integer3==integer4);
}
}源码讲解,参考链接地址:java Integer 源码学习 - VinoZhu - 博客园
31、深入理解java异常处理机制
java(3)-深入理解java异常处理机制_黄规速博客:学如逆水行舟,不进则退-CSDN博客_java 异常类
结论:
(1)、finally覆盖catch(开头引子的例子):
a)如果finally有return会覆盖catch里的throw,同样如果finally里有throw会覆盖catch里的return。
b) 如果catch里和finally都有return, finally中的return会覆盖catch中的。throw也是如此。
(2)、catch有return而finally没有:
当 try 中抛出异常且catch 中有 return 语句,finally 中没有 return 语句, java 先执行 catch 中非 return 语句,再执行 finally 语句,最后执行 catch 中 return 语句。
(3)、try有return语句,后续还有return语句,分为以下三种情况:
情况一:如果finally中有return语句,则会将try中的return语句”覆盖“掉,直接执行finally中的return语句,得到返回值,这样便无法得到try之前保留好的返回值。
情况二:如果finally中没有return语句,也没有改变要返回值,则执行完finally中的语句后,会接着执行try中的return语句,返回之前保留的值。
情况三:如果finally中没有return语句,但是改变了要返回的值,这里有点类似与引用传递和值传递的区别,分以下两种情况,:
a)如果return的数据是基本数据类型或文本字符串,则在finally中对该基本数据的改变不起作用,try中的return语句依然会返回进入finally块之前保留的值。
b)如果return的数据是引用数据类型,而在finally中对该引用数据类型的属性值的改变起作用,try中的return语句返回的就是在finally中改变后的该属性的值。
32、java序列化:
Java对象的序列化(Serialization)和反序列化详解_明洋的专栏-CSDN博客_java序列化和反序列化
33、Java serialVersionUID 有什么作用?
serialVersionUID 就是控制版本是否兼容的,serialVersionUID 就是控制版本是否兼容的,若我们认为修改的 Object 是向后兼容的,则不修改 serialVersionUID;反之,则提高 serialVersionUID的值,这时候再反序列化就会报错,提升版本不兼容!
Java serialVersionUID 有什么作用? - 简书
34、java Logger日志使用占位符打印
java Logger日志使用占位符打印_感冒石头的博客-CSDN博客_java logger 占位符
浅谈LOG日志的写法_xiangnideshen的专栏-CSDN博客_日志log
优先使用参数,减少字符串拼接,提高性能;
打印日志:
logger.info("线程ID: {}, 方法描述: {}, 调用参数: {}, 返回结果: {}", "1", "2", "3", "4");
执行后:
线程ID: 1, 方法描述: 2, 调用参数: 3, 返回结果: 4
35、SimpleDateFormat线程不安全及解决办法
SimpleDateFormat线程不安全及解决办法_默默前行,勿喜、勿悲、一切随缘!-CSDN博客_simpledateformat线程不安全
36、synchronized方法抛出异常后,会释放锁吗
方法抛出异常后,会释放锁(synchronized)_绅士jiejie的博客-CSDN博客
37、sleep() 和 wait() 的区别:
调用sleep方法的线程不会释放对象锁,而调用wait() 方法会释放对象锁
sleep() 和 wait() 的区别_yinhuanxu-CSDN博客_sleep和wait
38、ArrayList、LinkedList 源码:
Arraylist:底层是基于动态数组,根据下表随机访问数组元素的效率高,向数组尾部添加元素的效率高;但是,删除数组中的数据以及向数组中间添加数据效率低,因为需要移动数组。例如最坏的情况是删除第一个数组元素,则需要将第2至第n个数组元素各向前移动一位。而之所以称为动态数组,是因为Arraylist在数组元素超过其容量大,Arraylist可以进行扩容(针对JDK1.8 数组扩容后的容量是扩容前的1.5倍),Arraylist源码中最大的数组容量是Integer.MAX_VALUE-8,对于空出的8位,目前解释是 :①存储Headerwords;②避免一些机器内存溢出,减少出错几率,所以少分配③最大还是能支持到Integer.MAX_VALUE(当Integer.MAX_VALUE-8依旧无法满足需求时)。
Linkedlist基于链表的动态数组,数据添加删除效率高,只需要改变指针指向即可,但是访问数据的平均效率低,需要对链表进行遍历。
对于随机访问get和set,ArrayList优于LinkedList,因为LinkedList要移动指针。
对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据。
面试必备:ArrayList源码解析(JDK8)_zxt0601的博客-CSDN博客_arraylist源码解析
面试必备:LinkedList源码解析(JDK8)_zxt0601的博客-CSDN博客
39、char型变量中能不能存贮一个中文汉字?为什么?
* char型变量是用来存储Unicode编码的字符的,unicode编码字符集中包含了汉字,
* 所以,char型变量中当然可以存储汉字啦。不过,如果某个特殊的汉字没有被包含在 unicode编码字符集中,那么,这个char型变量中就不能存储这个特殊汉字。
*补充 说明:unicode编码占用两个字节,所以,char类型的变量也是占用两个字节。(一个字节8bit)
面试题:问题:Java中,char型变量中能不能存储一个中文汉字,为什么?_绝地反击T的博客-CSDN博客_char型变量中能不能存储一个中文汉字
40、为什么重写equal()时为什么也得重写hashCode()
在对象比较时,重写equals不仅比较对象地址相等,还比较对象内容相等,重写hashcode确保相同对象的索引值相等(也就是键在哈希表中存放的位置)。如果两个相同的对象,只重写hashcode,哈希值也就是key在同一个位置了,但是这里把两个对象都存储了。只重写equals,确实存储会变成一个对象,但是hashcode计算出的索引就有可能是两个,导致一个对象在两个位置存储了。
为何重写equals方法就得重写hashCode方法 - 知乎 (zhihu.com)
Object中的equals方法:
public boolean equals(Object obj) {
return (this == obj);
}User对象,包含name和age字段,重写后如下
@Override
public boolean equals(Object obj) {
if(this == obj) {
return true;
}
if(null == obj) {
return false;
}
if(this.getClass() != obj.getClass()) {
return false;
}
User user = (User) obj;
if(this.name.equals(user.name)&&this.age == user.age) {
return true;
}
return false;
}
@Override
public int hashCode() {
int hash = 17;
hash = hash * 31 + getName().hashCode();
hash = hash * 31 + getAge();
return hash;
}41、CopyOnWriteArrayList的原理和使用方法
CopyOnWriteArrayList 底层实现添加的原理是先copy出一个容器(可以简称副本),再往新的容器里添加这个新的数据,最后把新的容器的引用地址赋值给了之前那个旧的的容器地址,但是在添加这个数据的期间,其他线程如果要去读取数据,仍然是读取到旧的容器里的数据。保证同一时间只能有一个线程在添加或者删除元素;
优点:
(1).解决的开发工作中的多线程的并发问题。
缺点:
(1).内存占有问题:很明显,两个数组同时驻扎在内存中,如果实际应用中,数据比较多,而且比较大的情况下,占用内存会比较大,针对这个其实可以用ConcurrentHashMap来代替。
(2).数据一致性:CopyOnWrite容器只能保证数据的最终一致性,不能保证数据的实时一致性。所以如果你希望写入的的数据,马上能读到,请不要使用CopyOnWrite容器
CopyOnWriteArrayList的原理和使用方法_蹦跶的小码哥-CSDN博客_copyonwritearraylist原理
42、HashMap知识点与系列问题
(1)、源码通读:Java 8系列之重新认识HashMap(美团技术博客)
https://segmentfault.com/a/1190000023308658
(3)、HashMap的hash值,存储下标位置是怎么计算的
jdk1.8:
计算hash值:优化了高位运算的算法,将 hashCode 的高 16 位与 hashCode本身 进行异或运算,主要是为了在 table 的 length 较小的时候,让高位也参与运算,并且不会有太大的开销,使得hash分别更均匀:
(在计算hash值的时候,JDK1.7用了9次扰动处理=4次位运算+5次异或,而JDK1.8只用了2次扰动处理=1次位运算+1次异或)
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}计算下标值:将计算出来的 hash 值与 (table.length - 1) 进行 & 运算,确定下标;我们本来首先想到的就是把 hash 值对 table 长度取模运算,这样一来,元素的分布相对来说是比较均匀的。但是模运算消耗还是比较大的,我们知道计算机比较快的运算为位运算,因此 JDK 团队对取模运算进行了优化,使用上面代码2的位与运算来代替模运算。这个方法非常巧妙,它通过 “(table.length -1) & hash” 来得到该对象的索引位置,这个优化是基于以下公式:x mod 2^n = x & (2^n - 1)。我们知道 HashMap 底层数组的长度总是 2 的 n 次方,并且取模运算为 “h mod table.length”,对应上面的公式,可以得到该运算等同于“hash & (table.length - 1)”。这是 HashMap 在速度上的优化,因为 & 比 % 具有更高的效率。
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);(4)、为什么在JDK1.7的时候是先进行扩容后进行插入,而在JDK1.8的时候则是先插入后进行扩容的呢?
在JDK1.7中的话,是先进行扩容后进行插入的,就是当你发现你插入的桶是不是为空,如果不为空说明存在值就发生了hash冲突,那么就必须得扩容,但是如果不发生Hash冲突的话,说明当前桶是空的(后面并没有挂有链表),那就等到下一次发生Hash冲突的时候在进行扩容,但是当如果以后都没有发生hash冲突产生,那么就不会进行扩容了,减少了一次无用扩容,也减少了内存的使用
(5)、为什么在JDK1.8中进行对HashMap优化的时候,把链表转化为红黑树的阈值是8,而不是7或者不是20呢
如果选择6和8(如果链表小于等于6树还原转为链表,大于等于8转为树),中间有个差值7可以有效防止链表和树频繁转换。假设一下,如果设计成链表个数超过8则链表转换成树结构,链表个数小于8则树结构转换成链表,如果一个HashMap不停的插入、删除元素,链表个数在8左右徘徊,就会频繁的发生树转链表、链表转树,效率会很低。
还有一点重要的就是由于treenodes的大小大约是常规节点的两倍,因此我们仅在容器包含足够的节点以保证使用时才使用它们,当它们变得太小(由于移除或调整大小)时,它们会被转换回普通的node节点,容器中节点分布在hash桶中的频率遵循泊松分布,桶的长度超过8的概率非常非常小。所以作者应该是根据概率统计而选择了8作为阀值
JDK1.8引入红黑树大程度优化了HashMap的性能
(6)、哈希表如何解决Hash冲突?
(7)、为什么 HashMap 中 String、Integer 这样的包装类适合作为 key 键

(8)、jdk1.7和jdk1.8扩容时有什么区别
jdk1.8
在扩充HashMap的时候,因为容量是以前两倍,不需要像JDK1.7的实现那样重新计算hash,那么n-1的mask范围在高位多1bit,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+oldCap”;
如果 e 的 hash 值与老表的容量进行位与运算为 0,则说明 e 节点扩容后的索引位置跟老表的索引位置一样;
如果 e 的 hash 值与老表的容量进行位与运算为 1,则说明 e 节点扩容后的索引位置为:老表的索引位置+oldCap;
扩容后,节点重 hash 为什么只可能分布在 “原索引位置” 与 “原索引 + oldCap 位置”;
扩容代码中,使用 e 节点的 hash 值跟 oldCap 进行位与运算,以此决定将节点分布到 “原索引位置” 或者 “原索引 + oldCap 位置” 上;
这个设计确实非常的巧妙,既省去了重新计算hash值的时间,而且同时,由于新增的1bit是0还是1可以认为是随机的,因此resize的过程,均匀的把之前的冲突的节点分散到新的bucket了。这一块就是JDK1.8新增的优化点;
jdk1.7
扩容过程中会将原来的数据,放入到新的数组中,但是会重新计算hash值进行分配,通过key值的hash值和新数组的大小算出在当前数组中的存放位置;
数组扩容之后,最消耗性能的点就出现了:原数组中的数据必须重新计算其在新数组中的位置,并放进去,这个操作是极其消耗性能的。所以如果我们已经预知HashMap中元素的个数,那么预设初始容量能够有效的提高HashMap的性能。
扩容是一个特别耗性能的操作,所以当程序员在使用HashMap的时候,估算map的大小,初始化的时候给一个大致的数值,避免map进行频繁的扩容。
(9)、HashMap为什么容量是2的次方
HashMap的容量为什么是2的n次幂,和这个(n - 1) & hash的计算方法有着千丝万缕的关系,符号&是按位与的计算,这是位运算,计算机能直接运算,特别高效,按位与&的计算方法是,只有当对应位置的数据都为1时,运算结果也为1,当HashMap的容量是2的n次幂时,(n-1)的2进制也就是1111111***111这样形式的,这样与添加元素的hash值进行位运算时,能够充分的散列,使得添加的元素均匀分布在HashMap的每个位置上,减少hash碰撞;
HashMap计算添加元素的位置时,使用的位运算,这是特别高效的运算;另外,HashMap的初始容量是2的n次幂,扩容也是2倍的形式进行扩容,是因为容量是2的n次幂,可以使得添加的元素均匀分布在HashMap中的数组上,减少hash碰撞,避免形成链表的结构,降低查询效率!
HashMap初始容量为什么是2的n次幂及扩容为什么是2倍的形式_Apeopl的博客-CSDN博客_hashmap扩容为啥是2倍
(10)、在多线程添加HashMap的时候,会出现什么问题
jdk1.7 HashMap,多线程添加数据,扩容时候的头插法,出现死循环问题 疫苗:Java HashMap的死循环 | 酷 壳 - CoolShell
jdk1.8 HashMap虽然不会出现死循环,但是也会出现线程安全问题,相同hash数据在同一个点插入丢失。
视频讲解:JDK7的HashMap头插法循环的问题,这么难理解吗?_哔哩哔哩_bilibili
(11)、为什么HashMap要自己实现writeObject和readObject方法?
HashMap中,由于Entry的存放位置是根据Key的Hash值来计算,然后存放到数组中的,对于同一个Key,在不同的JVM实现中计算得出的Hash值可能是不同的。
因为所有的对象,都继承自Object类。Object类中的hashCode()方法如下,是native的,在不同平台的实现不同:
public native int hashCode();String类中重写了hashCode方法:
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}Integer类中重载了hashCode方法:
public static int hashCode(int value) {
return value;
}
所以为了避免这个问题,HashMap采用了下面的方式来解决
将可能会造成数据不一致的元素使用transient关键字修饰,从而避免JDK中默认序列化方法对该对象的序列化操作。不序列化的包括:Entry[] table,size,modCount。
自己实现writeObject方法,从而保证序列化和反序列化结果的一致性。那么,HashMap又是通过什么手段来保证序列化和反序列化数据的一致性的呢?
首先,HashMap序列化的时候不会将保存数据的数组序列化,而是将元素个数以及每个元素的Key和Value都进行序列化。
在反序列化的时候,重新计算Key和Value的位置,重新填充一个数组:
// Called only from writeObject, to ensure compatible ordering.
void internalWriteEntries(java.io.ObjectOutputStream s) throws IOException {
Node<K,V>[] tab;
if (size > 0 && (tab = table) != null) {
for (int i = 0; i < tab.length; ++i) {
for (Node<K,V> e = tab[i]; e != null; e = e.next) {
s.writeObject(e.key);
s.writeObject(e.value);
}
}
}
}为什么HashMap要自己实现writeObject和readObject方法? - 知乎
(12)、HashMap线程安全的替代方案:ConcurrentHashMap
(13)、HashMap的空间利用率问题:

(14)、参考链接:
(1)美团面试题:Hashmap的结构,1.7和1.8有哪些区别,史上最深入的分析_王伟的博客-CSDN博客_hashmap1.7和1.8的区别
史上最详细的 JDK 1.8 HashMap 源码解析_程序员囧辉-CSDN博客_hashmap详解
43、LinkedHashMap 源码详细分析(JDK1.8)以及简单的LRU算法实现
LinkedHashMap 源码详细分析(JDK1.8)_慕课手记
44、几种Map类型数据结构对比:
下面针对各个实现类的特点做一些说明:
(1) HashMap:它根据键的hashCode值存储数据,大多数情况下可以直接定位到它的值,因而具有很快的访问速度,但遍历顺序却是不确定的。 HashMap最多只允许一条记录的键为null,允许多条记录的值为null。HashMap非线程安全,即任一时刻可以有多个线程同时写HashMap,可能会导致数据的不一致。如果需要满足线程安全,可以用 Collections的synchronizedMap方法使HashMap具有线程安全的能力,或者使用ConcurrentHashMap。
(2) Hashtable:Hashtable是遗留类,很多映射的常用功能与HashMap类似,不同的是它承自Dictionary类,并且是线程安全的,任一时间只有一个线程能写Hashtable,并发性不如ConcurrentHashMap,因为ConcurrentHashMap引入了分段锁。Hashtable不建议在新代码中使用,不需要线程安全的场合可以用HashMap替换,需要线程安全的场合可以用ConcurrentHashMap替换。
(3) LinkedHashMap:LinkedHashMap 在HashMap上面结构的基础上,增加了一条双向链表,使得结构可以保持键值对的插入顺序,初始情况下,让 LinkedHashMap 的 head 和 tail 引用同时指向新节点,链表就算建立起来了。随后不断有新节点插入,通过将新节点接在 tail 引用指向节点的后面,即可实现链表的更新。默认情况下,LinkedHashMap 是按插入顺序维护链表。不过我们可以在初始化 LinkedHashMap,指定 accessOrder 参数为 true,即可让它按访问顺序维护链表。访问顺序的原理上并不复杂,当我们调用get/getOrDefault/replace等方法时,只需要将这些方法访问的节点移动到链表的尾部即可。
(4) TreeMap:TreeMap实现SortedMap接口,能够把它保存的记录根据键排序,默认是按键值的升序排序,也可以指定排序的比较器,当用Iterator遍历TreeMap时,得到的记录是排过序的。如果使用排序的映射,建议使用TreeMap,TreeMap 的底层就是一颗红黑树。在使用TreeMap时,key必须实现Comparable接口或者在构造TreeMap传入自定义的Comparator,否则会在运行时抛出java.lang.ClassCastException类型的异常。
对于上述四种Map类型的类,要求映射中的key是不可变对象。不可变对象是该对象在创建后它的哈希值不会被改变。如果对象的哈希值发生变化,Map对象很可能就定位不到映射的位置了。
45、解决java读取大文件内存溢出问题:
不要采用 new File(path)的方式,一次性把大文件加载在内存中:
解决方案(1):使用java.util.Scanner类扫描文件
FileInputStream inputStream = null;
Scanner sc = null;
try {
inputStream = new FileInputStream(path);
sc = new Scanner(inputStream, "UTF-8");
while (sc.hasNextLine()) {
String line = sc.nextLine();
// System.out.println(line);
}
// note that Scanner suppresses exceptions
if (sc.ioException() != null) {
throw sc.ioException();
}
} finally {
if (inputStream != null) {
inputStream.close();
}
if (sc != null) {
sc.close();
}
}解决方案(2):Apache Commons IO流,同样也可以使用Commons IO库实现,利用该库提供的自定义LineIterator:
LineIterator it = FileUtils.lineIterator(theFile, "UTF-8");
try {
while (it.hasNext()) {
String line = it.nextLine();
// do something with line
}
} finally {
LineIterator.closeQuietly(it);
}
解决方案(3):在java代码中,把大文件拆分成小文件(也得以上面两种方法为前提,行读取)
解决方案(4):使用Linux命令,split -l 按照行分割大文件,拆分成小文件处理:Linux命令之大文件分割_小哥骑单车-CSDN博客_linux拆分文件
解决java读取大文件内存溢出问题、如何在不重复读取与不耗尽内存的情况下处理大文件_yangguoqi的专栏-CSDN博客
高效读取大文件,再也不用担心 OOM 了!_Java极客技术-CSDN博客
46、深入解析String#intern(美团技术博客)
47、Java内存模型final域的内存语义:
(1)、final域的重排序规则
对于final域,编译器和处理器要遵守两个重排序规则。
1)在构造函数内对一个final域的写入,与随后把这个被构造对象的引用赋值给一个引用变量,这两个操作之间不能重排序。
2)初次读一个包含final域的对象的引用,与随后初次读这个final域,这两个操作之间不能重排序。
(2)、写final域的重排序规则
写final域的重排序规则禁止把final域的写重排序到构造函数之外。这个规则的实现包含下面2个方面。
1)JMM禁止编译器把final域的写重排序到构造函数之外。
2)编译器会在final域的写之后,构造函数return之前,插入一个StoreStore屏障。这个屏障禁止处理器把final域的写重排序到构造函数之外。
JSR-133为什么要增强final的语义
在旧的Java内存模型中,一个最严重的缺陷就是线程可能看到final域的值会改变。比如,一个线程当前看到一个整型final域的值为0(还未初始化之前的默认值),过一段时间之后这个线程再去读这个final域的值时,却发现值变为1(被某个线程初始化之后的值)。最常见的例子就是在旧的Java内存模型中,String的值可能会改变。
为了修补这个漏洞,JSR-133专家组增强了final的语义。通过为final域增加写和读重排序规则,可以为Java程序员提供初始化安全保证:只要对象是正确构造的(被构造对象的引用在构造函数中没有“逸出”),那么不需要使用同步(指lock和volatile的使用)就可以保证任意线程都能看到这个final域在构造函数中被初始化之后的值。
《Java并发编程的艺术》 读书笔记 之 Java内存模型(六)final域的内存语义_小哥骑单车-CSDN博客
48、java反射基本理解:
Java反射机制创建对象_水滴的专栏-CSDN博客_java反射创建对象
49、this关键字与super关键字详解
this关键字与super关键字详解_大同小后生伟的博客-CSDN博客_super关键字
50、Lombok 的 @EqualsAndHashCode(callSuper = false) 的使用
Lombok 的 @EqualsAndHashCode(callSuper = false) 的使用_请叫我大师兄-CSDN博客_equalsandhashcode
51、Java异常处理基础知识笔记
Java异常处理基础知识笔记:异常处理机制、异常继承关系、捕获异常、抛出异常、异常的传播、异常调用栈、自定义异常、第三方日志库
Java异常处理基础知识笔记:异常处理机制、异常继承关系、捕获异常、抛出异常、异常的传播、异常调用栈、自定义异常、第三方日志库 - 古兰精 - 博客园
52、【Java基础-3】吃透Java IO:字节流、字符流、缓冲流
【Java基础-3】吃透Java IO:字节流、字符流、缓冲流_云深不知处-CSDN博客_java缓冲字节流
53、Java中Iterable和Iterator的辨析
Iterable接口中只包含一个方法,就是一个iterator()方法,用来返回一个Iterator类型的对象,或者说返回一个实现了Iterator接口的对象。
Java中Iterable和Iterator的辨析_TangowL-CSDN博客_iterable java
54、反射的优点缺点:
优点:使用场合:在编译时根本无法知道该对象或类可能属于哪些类,程序只依靠运行时信息来发现该对象和类的真实信息。反射提高了Java程序的灵活性和扩展性,降低耦合性,提高自适应能力。它允许程序创建和控制任何类的对象,无需提前硬编码目标类;
缺点:
性能问题:使用反射基本上是一种解释操作,用于字段和方法接入时要远慢于直接代码。因此Java反射机制主要应用在对灵活性和扩展性要求很高的系统框架上,普通程序不建议使用。
使用反射会模糊程序内部逻辑:程序人员希望在源代码中看到程序的逻辑,反射等绕过了源代码的技术,因而会带来维护问题。反射代码比相应的直接代码更复杂。
55、NoClassDefFoundError 和 ClassNotFoundException 有什么区别
56、Java synchronized锁升级过程简述
Synchronized 的锁升级流程是这样:无锁 ----> 偏向锁 ----> 轻量级锁----> 锁自旋 ----> 重量级锁
最开始是无锁状态的;
(1)偏向锁:
为什么要引入偏向锁?偏向锁是单线程下的锁优化;
因为经过HotSpot的作者大量的研究发现,大多数时候是不存在锁竞争的,常常是一个线程多次获得同一个锁,因此如果每次都要竞争锁会增大很多没有必要付出的代价,为了降低获取锁的代价,才引入的偏向锁。
偏向锁的升级
当线程1访问代码块并获取锁对象时,会在java对象头和栈帧中记录偏向的锁的threadID,因为偏向锁不会主动释放锁,因此以后线程1再次获取锁的时候,需要比较当前线程的threadID和Java对象头中的threadID是否一致,如果一致(还是线程1获取锁对象),则无需使用CAS来加锁、解锁;如果不一致(其他线程,如线程2要竞争锁对象,而偏向锁不会主动释放因此还是存储的线程1的threadID),那么需要查看Java对象头中记录的线程1是否存活,如果没有存活,那么锁对象被重置为无锁状态,其它线程(线程2)可以竞争将其设置为偏向锁;如果存活,那么立刻查找该线程(线程1)的栈帧信息,如果还是需要继续持有这个锁对象,那么暂停当前线程1,撤销偏向锁,升级为轻量级锁,如果线程1 不再使用该锁对象,那么将锁对象状态设为无锁状态,重新偏向新的线程。
偏向锁的取消:
偏向锁是默认开启的,而且开始时间一般是比应用程序启动慢几秒,如果不想有这个延迟,那么可以使用-XX:BiasedLockingStartUpDelay=0;
如果不想要偏向锁,那么可以通过-XX:-UseBiasedLocking = false来设置;
(2)轻量级锁
为什么要引入轻量级锁?
轻量级锁考虑的是竞争锁对象的线程不多,而且线程持有锁的时间也不长的情景。因为阻塞线程需要CPU从用户态转到内核态,代价较大,如果刚刚阻塞不久这个锁就被释放了,那这个代价就有点得不偿失了,因此这个时候就干脆不阻塞这个线程,让它自旋这等待锁释放。
轻量级锁什么时候升级为重量级锁?
线程1获取轻量级锁时会先把锁对象的对象头MarkWord复制一份到线程1的栈帧中创建的用于存储锁记录的空间(称为DisplacedMarkWord),然后使用CAS把对象头中的内容替换为线程1存储的锁记录(DisplacedMarkWord)的地址;
如果在线程1复制对象头的同时(在线程1CAS之前),线程2也准备获取锁,复制了对象头到线程2的锁记录空间中,但是在线程2CAS的时候,发现线程1已经把对象头换了,线程2的CAS失败,那么线程2就尝试使用自旋锁来等待线程1释放锁。
但是如果自旋的时间太长也不行,因为自旋是要消耗CPU的,因此自旋的次数是有限制的,比如10次或者100次,如果自旋次数到了线程1还没有释放锁,或者线程1还在执行,线程2还在自旋等待,这时又有一个线程3过来竞争这个锁对象,那么这个时候轻量级锁就会膨胀为重量级锁。重量级锁把除了拥有锁的线程都阻塞,防止CPU空转。
*注意:为了避免无用的自旋,轻量级锁一旦膨胀为重量级锁就不会再降级为轻量级锁了;偏向锁升级为轻量级锁也不能再降级为偏向锁。一句话就是锁可以升级不可以降级,但是偏向锁状态可以被重置为无锁状态。
参考:Java并发——Synchronized关键字和锁升级,详细分析偏向锁和轻量级锁的升级_tongdanping的博客-CSDN博客
57、为什么synchronized演变成重量级锁后性能会下降
Synchronized 是通过对象内部的一个叫做监视器锁(monitor)来实现的。但是监视器锁本质又是依赖于底层的操作系统的 Mutex Lock 来实现的。而操作系统实现线程之间的切换这就需要从用户态转换到核心态,这个成本非常高,状态之间的转换需要相对比较长的时间,这就是为什么Synchronized 效率低的原因。因此,这种依赖于操作系统 Mutex Lock 所实现的锁我们称之为重量级锁。JDK 中对 Synchronized 做的种种优化,其核心都是为了减少这种重量级锁的使用。
JDK1.6 以后,为了减少获得锁和释放锁所带来的性能消耗,提高性能,引入了轻量级锁和偏向锁。
58、TreeMap中如何实现自定义类key值的排序
TreeMap中如何实现自定义类key值的排序_huang_xiao_yu的博客-CSDN博客
59、Java volatile关键字总结
Java volatile关键字最全总结:原理剖析与实例讲解(简单易懂)_夏日清风-CSDN博客_java volatile
60、volatile能保证可见性,为什么不能保证原子性?
简单的说,修改volatile变量分为四步:
1)读取volatile变量到local
2)修改变量值
3)local值写回
4)插入内存屏障,即lock指令,让其他线程可见
这样就很容易看出来,前三步都是不安全的,取值和写回之间,不能保证没有其他线程修改。原子性需要锁来保证。
这也就是为什么,volatile只用来保证变量可见性,但不保证原子性。
首先线程A读取了i的变量的值,这个时候线程切换到了B,线程B同样从主内存中读取i的值,由于线程A没有对i做过任何修改,此时线程B获取到的i仍然是100。线程B工作内存中为i执行了加1的操作,但是没有刷新到主内存中,这个时候又切换到了A线程,A线程直接对工作内存中的100进行加1运输(因为A线程已经读取过i的值了),由于线程B并未写入i的最新值,这个时候A线程的工内存中的100不会失效。 最后,线程A将i=101写入主内存中,线程B也将i=101写入主内存中。 始终需要记住,i++ 的操作是3步骤!这样理解起来就更容易了
volatile为什么不能保证原子性_Blog-CSDN博客_volatile为什么不能保证原子性
61、Java程序比C/C++程序慢的影响因素
1)解释性语言固有开销:java程序在运行时类加载器从类路经中加载相关的类,然后java虚拟机读取该类文件的字节,执行相应操作.而C 编译的时候将程序编译成本地机器码.一般来说java程序执行速度要比C 慢10-30倍.即使采用just-in-time compiling (读取类文件字节后,编译成本地机器码)技术,速度也要比C 慢好多.
2)字节码加载执行开销:java程序要从网络上加载类字节,然后执行,这也是导致java运行速度慢的原因.
3)运行时溢出检测开销:在程序运行过程中,java虚拟机要检测数组是否越界,在C 中则不检测.
4)堆与栈的区别:java中所有的对象都创建在堆中,没有对象被创建在stack中,而C 有的对象和变量是创建在stack中的
5)运行时引用检测开销:java在运行过程中检测对象的引用是否为空,如果引用指向都空指针,且执行某个方法时会抛出空指针异常
6)运行时类型检测开销:java运行时对类型检测,如果类型不正确会抛出ClassCastException异常.
7)GC巨大开销:java的垃圾回收机制较C 由程序员管理内存效率更低.
8)类型转换开销:java中的原始数据类型在每个操作系统平台长度都是相同,而C 这些数据类型长度是随操作系统的不同而不同,所以java在不同操作系统上执行时有个转化过程.
9)String类型开销:在java中String 是UNICODE.当java要操作一个 ASCII string 时,比C 效率上相对要低一些.
10)动态链接开销:java中采用的是动态链接
java 和 C 代码运行效率的比较(整理) - dy9776 - 博客园
62、JAVA 内存泄露详解(原因、例子及解决)
3JAVA 内存泄露详解(原因、例子及解决)_anxpp的博客-CSDN博客_java内存泄漏的原因及解决办法6
63、并发编程中的逃离“996icu”——this引用逃逸 - 云+社区 - 腾讯云
64、深入理解java注解的实现原理(转载)
深入理解java注解的实现原理(转载)_YuZongTao-CSDN博客_java注解的实现原理
并发编程中的逃离“996icu”——this引用逃逸 - 云+社区 - 腾讯云
65、为什么需要base 64编码解码
66、深拷和浅拷贝的区别:
浅拷贝:对基本数据类型进行值传递,对引用数据类型进行引用传递般的拷贝,此为浅拷贝。
深拷贝:对基本数据类型进行值传递,对引用数据类型,创建一个新的对象,并复制其内容,此为深拷贝。
Java深入理解深拷贝和浅拷贝区别_java深拷贝和浅拷贝的区别_老周聊架构的博客-CSDN博客
深拷贝的几种方法:














 269
269











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









