







最基本:增删改查
数据库基本都是弱语法,所以英文大小写,空格自己稍微注意一下就好
创建表格
//最简单的建表
creat table table_name;
drop table table_name;
//顺便创建表中的字段名称、属性和主键,注意要加括号
creat table user_2019 (
user_id int(8) PRIMARY_KEY,
user_name varchar(10),
phone int(11),
pwd varchar(20)
);
插入数据 insert
//这里,如果是包含全行所有要插入的数据,那么可以不加列名,而且如果是字符类型的,一定要加单引号
insert into user_2019 values(2,'xiaoming',13588887777,'abcxxx');
//如果只加入id和name和phone,这里字段名就要识别大小写了,所以这里要注意
insert into user_2019 (user_id,user_name,phone)values(2,'xiaoming',13588887777,'abcxxx');
//还可以转成MD5格式
insert into user_2019 (user_id,user_name,phone)values(2,'xiaoming',13588887777,MD5('abcxxx'));
删除 delete truncate drop
DELETE 是有条件的删除表中的数据,如果不写条件,全表删除,而删除后,表仍然存在,仍可以对表进行操作。具体语法为DELETE FROM TABLE WHERE 条件。
同样,还有一个TRUNCATE TABLE TABLENAME语句,是全表不提交删除,也是删除数据,表仍然存在。
DROP TABLE,是从数据库中删除表。删除后,表结构不在存在,无法再对该表进行任何操作。
举个通俗的例子,比如你有一个水桶,桶里装着水。
而DELETE或者TRUNCATE,只是相当于把水倒掉,而桶仍然存在。
而DROP TABLE,则相当于把桶都扔掉了。
TRUNCATE 和DELETE只删除数据, DROP则删除整个表(结构和数据)
https://www.cnblogs.com/zhizhao/p/7825469.html
//delete from要加条件,不然是一条一条的删除表中所有的数据,可以回滚
delete from user_2019 + where;
删除表中某列
ALTER TABLE 表名 DROP COLUMN column_b
知识点衍生
--A.添加新列
alter table 表名 add 列明 varchar(20);
--B.修改列名
alter table 表名 change 列名 新列名 列类型
--C.更改列的数据类型
alter table 表名 modify column 字段名字 decimal(18,4) //DECIMAL(P,D)其中P表示的是有效数字的位数,D表示是小数的位数,D小于或等于P
修改 update
update要加where,如果没有where,那么受影响的数据会有很多
update user_2019 set (字段名)phone='' where .....;
查询
这里需要重点关注
分组:group by; having;
排序:order by
分页:limit +两个数字 如: limit 0,10;
//最基础的查询
select * from user_2019;
//查询单个字段
select user_name from user_2019;
//按照条件查询 and 和or 按照自己的需要进行组合
select user_name from user_2019 where ... and(or) ...;
//like如查处所有姓张的老师,注意%的位置 %XXX%的意思是只要包含XXX字段即可,不关心是前面还是后面还是中间
select user_name from user_2019 where user_name like 'xx%';
between and
查询条件:
函数 min 最小值 max 最大值 avg 平均值 count 统计 sum 求和
注意想要统计内容的类型,不能用sum去统计所有“名字”的和
select min(score) from user_2019;
//查询所有人的平均分
select avg(scroe) from user_2019(user_score);
复杂一点的查询
1.用avg是求所有人的平均分,但是求每个人的平均分要怎么操作呐?
这里就涉及到一个新的东西,group by
//distinct sname加上了去重这句,只保留一个
select distinct sname , avg(score) from user_2019 group by sname;
select sname , avg(score) from user_2019 group by sname;
这里面也可以不加distinct ,因为我们后面有一个 group by分组的过程,按照什么分组?这里是需要按照姓名分组,这样就可以理解一个学生会有很多课程的成绩,比如说学生甲有3个成绩,学生乙有5个成绩,如果我们不进行分组直接用avg去求成绩的时候,求出来的平均成绩其实是两个人一共8个成绩的平均成绩,这样看起来就没有什么意义,我们需要看的是每个同学的平均成绩,所以进行group by分组,将学生甲相当于单独分为一个组,然后再求这个组的平均成绩,这样就是学生甲的平均成绩
这样也可以引申出我们不求每个人的平均分,我们求单科的平均分,道理是一样的。
注意:group by和order by是不一样的,一个是分组,一个是排序
2.查询平均分大于80分的同学姓名
select sname from user_2019 group by sname having avg(score) > 80;
group by 分组后面只能有having 去过滤这一点是需要牢记的
后面可以加排序的规则order by
注意加排序的字段(按照什么来排序),desc降序 asc升序
select sname from user_2019 group by sname having avg(score) > 80 order by avg(score) desc;
要求以上数据只显示前面几行
limit 0,1 从第几行开始显示,显示几个,如果第一个数字是0的话,可以不写直接写limit 1,如果是 limit 2,1 表示前两个不要,从第三个开始取一条,有多少取多少,没有那么多数据也不会报错就是显示不出来而已
select sname from user_2019 group by sname having avg(score) > 80 order by avg(score) desc limit 0,1;
比较绕的查询
查询出每一科成绩都大于80分的同学
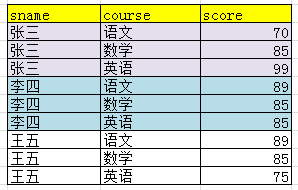
//select sname from t_score where socre<80查出来的是有小于80分的学生姓名
//可以加上group by sname给姓名分个组,这样就不会有重复的姓名
//加上not in,注意where条件
select sname from t_score where sname not in (select sname from t_score where socre<80);
可能会有疑问,为什么不能直接将大于80分的同学都查出来
//这样写为什么不行?
select sname from t_score where score > 80;
原因很简单,上面这条语句我们查询的是score大于80的所有条数,条件只是一个简单的 score > 80,和姓名并没有什么关系
上面的问题还可以用其他的方法,exist 存在同样对应 not exist
//这样运行出来的是什么都没有
select * from t_score where EXIST(select * from t_score where score >100);
//这样就可以得出结果了
select * from t_score t1 where NOT EXIST(select * from t_score t2 where t2.score < 80 and t2.sname = t1.sname);
很多时候用 exists 代替 in 是一个好的选择
cookies
一个简单的存储过程
一切都从insert开始
insert into trans_log
(APP_SNO,
CHANNEL_SNO,
HOST_SNO,
FRONT_SNO,
UPDATED_BY,
UPDATED_DATE,
INCOME_VALUE,
INTEREST_DAYS,
DRAW_TYPE)
values
(app_sno,
channel_sno,
host_sno,
front_sno,
'test_zz',
created_date,
null,
null,
null);
//这里面现在只是插入了一条语句,从sql来看,values中的值可以是变量、可以是字符串、可以为空
但是上面只是有一条记录,我们需要增加多条记录,这样就需要一个循环了。
begin
for i in 1 .. 10 loop
insert into trans_log
(APP_SNO,
CHANNEL_SNO,
HOST_SNO,
FRONT_SNO,
UPDATED_BY,
UPDATED_DATE,
INCOME_VALUE,
INTEREST_DAYS,
DRAW_TYPE)
values
(app_sno,
channel_sno,
host_sno,
front_sno,
'test_zz',
created_date,
null,
null,
null);
if(mod(i,10)=0) then commit;
end if;
end loop ;
end;
循环是加上了,但是里面的变量怎么办,特别是涉及到主键的时候,主键是具有唯一性的,这就需要我们在进入循环之前定义变量
一个declare语句
declare
i Integer := 1;
i_out Integer := 1;
x varchar2(6);
date_str varchar2(8) := '20190103';
channel_sno varchar2(32);
busi_code varchar2(3) := '122';
//后面有“=”的就表示这个busi_code的值是固定的,如最下面的那个122就是busi_code 下面values中可以写122也可以写busi_code
有了声明的变量,就需要设置这些变量以什么样的规则在每次执行insert语句的时候进行变化
所以在循环中还需要设置变量的具体内容
这里变量以什么样的规则去生成具体的值就需要按照要求去设置,比如流水号以什么样的方式进行连接,里面哪些位数有那些固定的含义,是时间还是订单编号等等,这里面就需要我们自己去研究了。
acct_no := '1'||lpad(to_char(i), '10', '0');
prod_batch_no := date_str;
channel_sno := '888885' || date_str || trunc(dbms_random.value(1000000000, 9999999999));
created_date := to_date(date_str, 'yyyyMMdd');
所以,一个简单的存储过程可以这样写:
//定义变量
declare
i Integer := 1;
i_out Integer := 1;
x varchar2(6);
date_str varchar2(8) := '20190103';
channel_sno varchar2(32);
busi_code varchar2(3) := '122';
//进入循环
begin
for i in 1 .. 10 loop
//设置变量的规则
acct_no := '1'||lpad(to_char(i), '10', '0');
prod_batch_no := date_str;
channel_sno := '888885' || date_str || trunc(dbms_random.value(1000000000, 9999999999));
created_date := to_date(date_str, 'yyyyMMdd');
//进行插入操作
insert into trans_log
(APP_SNO,
CHANNEL_SNO,
HOST_SNO,
FRONT_SNO,
UPDATED_BY,
UPDATED_DATE,
INCOME_VALUE,
INTEREST_DAYS,
DRAW_TYPE)
values
(app_sno,
channel_sno,
host_sno,
front_sno,
'test_zz',
created_date,
null,
null,
null);
//最后跳出循环提交,这里需要注意为了提高效率,尽量也不要插入一条数据就提交一次,可以插入多条数据后再进行提交
//循环的时候也可以使用嵌套循环来提高插入的效率
if(mod(i,10)=0) then commit;
end if;
end loop ;
end;
另外扩展一个东西在一个千万级的数据库查寻中,如何提高查询效率?
这里的答案也是各大论坛的大神们总结的
1.数据库设计方面:
a.对查询进行优化,避免全表扫描,考虑在常用的where 和order by涉及的列上建立索引
b.并不是所有的列都适合建立索引,如表中字段sex中 male和female几乎各占一半,所以有大量重复的数据的列中不适合设置索引
c.索引并不是越多越好,索引可以提高相应的select的效率,但同事也降低了insert和update的效率,一个表的索引最好不要超过6个。
d.避免频繁创建和删除临时表,以减少系统表资源的消耗。
少说几条吧,这里一般都是开发的同学需要注意的
2.SQL语句方面
a.应尽量避免在where子句中使用!=或<>操作符,否则将放弃使用索引而进行全表扫描
b.应尽量避免在where子句中使用or来连接条件,否则将放弃使用索引而进行全表扫描
c.in和not in 也要慎用,对于连续的数值,能用 between 就不要用 in 了
d.应尽量避免在 where 子句中对字段进行表达式操作,如: select id from t where num/2=100
e.应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描
我们上面应用到的例子其实就没有考虑到这个因素,因为我们用了avg、sum
f.很多时候用 exists 代替 in 是一个好的选择
g. 任何地方都不要使用 select * from t ,用具体的字段列表代替“*”,不要返回用不到的任何字段。这里也是我们工作中经常忽略的一个问题















 213
213











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









